本文介绍使用BenchmarkSQL5.0 来测试opengauss数据库OLTP性能的步骤,以及htop iostat两个服务器性能监控工具。
本文仅演示了测试的步骤,如果想达到数据库的极致性能,如tpmC达到100万以上,则需要针对服务器硬件、操作系统参数、数据库启动方式、NUMA绑定等做调优配置,详见参见openGauss数据库性能调优
1. 概念介绍
1.1. TPC-C的介绍
TPC-C is an On-Line Transaction Processing Benchmark.
TPC-C is measured in transactions per minute (tpmC).
TPC-C是业界常用的一套benchmark,由TPC委员会制定发布,用于评测数据库的联机交易处理(OLTP)能力。
主要涉及10张表,包含五类业务事务模型(NewOrder–新订单的生成、Payment–订单付款、OrderStatus–最近订单查询、Delivery–配送、StockLevel–库存缺货状态分析)。
TPC-C事务模型
TPC-C需要处理的交易事务主要为以下5种:
- 新订单(New-Order) :客户输入一笔新的订货交易;
- 支付操作(Payment) :更新客户帐户余额以反映其支付状况;
- 发货(Delivery) :发货(模拟批处理交易);
- 订单状态查询(Order-Status) :查询客户最近交易的状态;
- 库存状态查询(Stock-Level) :查询仓库库存状况,以便能够及时补货。
TPC-C通过tpmC值(Transactions per Minute)来衡量系统最大有效吞吐量(MQTh,Max Qualified Throughput),其中Transactions以NewOrder Transaction为准,即最终衡量单位为每分钟处理的新订单数
TPC-C性能衡量指标tpmC
流量指标(Throughput,简称tpmC):按照TPC组织的定义,流量指标描述了系统在执行支付操作、订单状态查询、发货和库存状态查询这4种交易的同时,每分钟可以处理多少个新订单交易。
所有交易的响应时间必须满足TPC-C测试规范的要求,且各种交易数量所占的比例也应该满足TPC-C测试规范的要求。在这种情况下,流量指标值越大说明系统的联机事务处理能力越高。
TPC-C表模型如下:

1.2. BenchmarkSQL
BenchmarkSQL5.0 是TPCC标准测试工具。
benchmark是java语言编写的,并使用ant进行编译,所以需要提前安装并配置好java、ant环境
1.3. htop工具
htop是linux上面一个监控工具,可以认为是加强版的top,tpcc运行过程中,推荐使用htop进行监控资源状态
htop使用yum源一键安装yum install htop
1.4. iostat工具
iostat工具对系统磁盘进行监控,分析磁盘的读写状态
htop使用yum源一键安装yum install sysstat
2. 测试环境准备
2.1. 安装java/ant
安装jdk 1.8.x、ant 1.9.x,并配置好环境变量,用于使用ant编译BenchmarkSQL5.0并执行java程序
2.2. benchmark的安装
2.2.1. benchmark下载
可以从如下两个地址下载
- https://blog.opengauss.org/zh/post/optimize/images/benchmarksql-5.0.zip
- https://sourceforge.net/projects/benchmarksql/
2.2.2. 替换jdbc驱动jar包
进入到解压后的目录benchmarksql-5.0/lib/postgres下
- 从官网下载对应的jdbc驱动包,解压出来后放到该目录下
- 将自带的postgresql驱动jar包备份或删除【否则会报错: 不支援 10 验证类型。请核对您已经组态 pg_hba.conf 文件包含客户端的IP位址或网路区段,以及驱动程序所支援的验证架构模式已被支援。】
2.2.3. 编译
进入benchmarksql-5.0根目录, 输入ant命令进行编译。

3.测试TPC-C性能
3.1.创建tpcc数据库以及数据库用户
create user tpcc identified by 'test@123' profile default;
alter user tpcc sysadmin;
grant all privilege to tpcc;
create database tpccdb encoding 'UTF8' template=template0 ;
3.2.配置props.pg文件
注意:
os_collector_linux.py是采用python2编写的,在python3下会报语法错误的,需要调整如下:
- 将print 调整为print()
- 将
open("/proc/stat", "r", buffering = 0)调整为open("/proc/stat", "r", buffering = 1)
//db指数据库的类型,目前支持postgres、oracle
db=postgres
driver=org.postgresql.Driver
conn=jdbc:postgresql://172.25.xx.xx:16001/tpccdb?prepareThreshold=1&batchMode=on&fetchsize=10
user=tpcc
password=test@123
//仓库数量,每个warehouse大小大概是100MB
warehouses=1000
//用于在数据库中初始化数据的加载进程数量
loadWorkers=200
//终端数,即并发客户端数量。此处设置的是最大并发数量, 跟服务端最大work数对应。
terminals=812
//每个终端(terminal)运行的固定事务数量,
//例如:如果该值设置为10,意味着每个terminal运行10个事务,如果有32个终端,那整体运行320个事务后,测试结束。
//该参数配置为非0值时,下面的runMins参数必须设置为0
runTxnsPerTerminal=0
//要测试的整体时间,单位为分钟,
//如果runMins设置为60,那么测试持续1小时候结束。
//该值设置为非0值时,runTxnsPerTerminal参数必须设置为0。
//这两个参数不能同时设置为正整数,如果设置其中一个,另一个必须为0,
//主要区别是runMins定义时间长度来控制测试时间;runTxnsPerTerminal定义事务总数来控制时间。
runMins=5
//每分钟事务总数限制,该参数主要控制每分钟处理的事务数,事务数受terminals参数的影响,默认是300。
//如果terminals数量大于limitTxnsPerMin值,意味着并发数大于每分钟事务总数,该参数会失效,
//如terminals设置为1000,limitTxnsPerMin设置为300,则有1000个并发同时发起,那每分钟事务数设置为300就没意义了,
//所以要让该参数有效,可以设置数量大于并发数,或者让其失效
limitTxnsPerMin=0
//终端和仓库的绑定模式,设置为true时可以运行4.x兼容模式,意思为每个终端都有一个固定的仓库。
//设置为false时可以均匀的使用数据库整体配置。
//TPCC规定每个终端都必须有一个绑定的仓库,所以一般使用默认值true。
terminalWarehouseFixed=false
//以下五个值相加之和为100。
//默认值为:45, 43, 4, 4 & 4 ,与TPC-C测试定义的比例一致,实际操作过程中,可以调整比重来适应各种场景。
newOrderWeight=45
paymentWeight=43
orderStatusWeight=4
deliveryWeight=4
stockLevelWeight=4
//测试数据生成目录,默认无需修改,默认生成在run目录下面,名字形如my_result_xxxx的文件夹。
//通过注释取消此内容。
resultDirectory=my_result_%tY-%tm-%td_%tH%tM%tS
//操作系统性能收集脚本,默认无需修改,需要操作系统具备有python环境
osCollectorScript=./misc/os_collector_linux.py
//操作系统收集操作间隔,默认为1秒
//osCollectorInterval=1
//操作系统收集所对应的主机,如果对本机数据库进行测试,该参数保持注释即可,
//如果要对远程服务器进行测试,请填写用户名和主机名。
//osCollectorSSHAddr=omm@172.25.xx.xx
//操作系统中被收集服务器的网卡名称和磁盘名称,
//例如:使用ifconfig查看操作系统网卡名称,ens2f1,那么下面网卡名设置为net_ens2f1(net_前缀固定);
//使用df -h或者fdisk -l 查看磁盘挂载目录,如/dev/sdc、/dev/sde,那么下面磁盘名设置为blk_sda1(blk_前缀固定)
//osCollectorDevices=net_ens2f1 blk_nvme0n1 blk_sdc blk_sde
3.3.替换建表SQL
使用如下内容替换benchmarksql-5.0/run/sql.common/tableCreates.sql的内容。
主要增加了两个表空间和一些附加数据属性,便于在测试时增加磁盘的IO
在性能测试过程中,为了增加IO的吞吐量,可以将pg_xlog、tablespace2、tablespace3下的数据分散到不同的存储介质上,并在原有的位置给出指向真实位置的软连接。
pg_xlog位于数据库目录下,tablespace2、tablespace3分别位于数据库目录pg_location下。
CREATE TABLESPACE example2 relative location 'tablespace2';
CREATE TABLESPACE example3 relative location 'tablespace3';
create table bmsql_config (
cfg_name varchar(30),
cfg_value varchar(50)
);
create table bmsql_warehouse (
w_id integer not null,
w_ytd decimal(12,2),
w_tax decimal(4,4),
w_name varchar(10),
w_street_1 varchar(20),
w_street_2 varchar(20),
w_city varchar(20),
w_state char(2),
w_zip char(9)
) WITH (FILLFACTOR=80);
create table bmsql_district (
d_w_id integer not null,
d_id integer not null,
d_ytd decimal(12,2),
d_tax decimal(4,4),
d_next_o_id integer,
d_name varchar(10),
d_street_1 varchar(20),
d_street_2 varchar(20),
d_city varchar(20),
d_state char(2),
d_zip char(9)
) WITH (FILLFACTOR=80);
create table bmsql_customer (
c_w_id integer not null,
c_d_id integer not null,
c_id integer not null,
c_discount decimal(4,4),
c_credit char(2),
c_last varchar(16),
c_first varchar(16),
c_credit_lim decimal(12,2),
c_balance decimal(12,2),
c_ytd_payment decimal(12,2),
c_payment_cnt integer,
c_delivery_cnt integer,
c_street_1 varchar(20),
c_street_2 varchar(20),
c_city varchar(20),
c_state char(2),
c_zip char(9),
c_phone char(16),
c_since timestamp,
c_middle char(2),
c_data varchar(500)
) WITH (FILLFACTOR=80) tablespace example2;
create sequence bmsql_hist_id_seq;
create table bmsql_history (
hist_id integer,
h_c_id integer,
h_c_d_id integer,
h_c_w_id integer,
h_d_id integer,
h_w_id integer,
h_date timestamp,
h_amount decimal(6,2),
h_data varchar(24)
) WITH (FILLFACTOR=80);
create table bmsql_new_order (
no_w_id integer not null,
no_d_id integer not null,
no_o_id integer not null
) WITH (FILLFACTOR=80);
create table bmsql_oorder (
o_w_id integer not null,
o_d_id integer not null,
o_id integer not null,
o_c_id integer,
o_carrier_id integer,
o_ol_cnt integer,
o_all_local integer,
o_entry_d timestamp
) WITH (FILLFACTOR=80);
create table bmsql_order_line (
ol_w_id integer not null,
ol_d_id integer not null,
ol_o_id integer not null,
ol_number integer not null,
ol_i_id integer not null,
ol_delivery_d timestamp,
ol_amount decimal(6,2),
ol_supply_w_id integer,
ol_quantity integer,
ol_dist_info char(24)
) WITH (FILLFACTOR=80);
create table bmsql_item (
i_id integer not null,
i_name varchar(24),
i_price decimal(5,2),
i_data varchar(50),
i_im_id integer
);
create table bmsql_stock (
s_w_id integer not null,
s_i_id integer not null,
s_quantity integer,
s_ytd integer,
s_order_cnt integer,
s_remote_cnt integer,
s_data varchar(50),
s_dist_01 char(24),
s_dist_02 char(24),
s_dist_03 char(24),
s_dist_04 char(24),
s_dist_05 char(24),
s_dist_06 char(24),
s_dist_07 char(24),
s_dist_08 char(24),
s_dist_09 char(24),
s_dist_10 char(24)
) WITH (FILLFACTOR=80) tablespace example3;
3.4. 运行benchmark
关注tpmTOTAL、tpmC即可
cd benchmarksql-5.0/run
## 生成测试数据
## 为了方便多次测试,减少导入数据的时间,可以通过停止数据库,将整个数据目录执行一次拷贝对数据库进行备份。
./runDatabaseBuild.sh props.pg
## TPCC测试
./runBenchmark.sh props.pg
##清空测试数据
./runDatabaseDestroy.sh props.pg
测试结果类似于下图,OpenGauss在单机下,tpmC最高可达150万

3.5. 测试辅助SQL或命令
# 查看数据库占用空间大小,
select datname, pg_size_pretty (pg_database_size(datname)) AS size from pg_database
# 查看tpccdb中各表的记录条数
select relname as TABLE_NAME, reltuples as rowCounts from pg_class where relkind = 'r' and relnamespace = (select oid from pg_namespace where nspname='public') order by rowCounts desc;

- 通过numactl 查看NUMA的配置或将进程绑定到指定CPU core
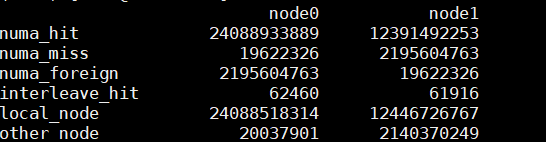
- 通过numastat命令观察各个NUMA节点的状态。
- numa_hit表示节点内CPU核访问本地内存的次数。
- numa_miss表示节点内核访问其他节点内存的次数。跨节点的内存访问会存在高延迟从而降低性能,因此,numa_miss的值应当越低越好,如果过高,则应当考虑绑核。
# numa安装
yum -y install numactl numastat
# 查看当前服务器的NUMA配置
numactl -H
#进程绑定到指定CPU core
#使用htop监控数据库服务端和tpcc客户端CPU利用情况,最佳性能测试情况下,各个业务CPU的占用率都非常高(> 90%)。
#如果有CPU占用率没有达标,可能是绑核方式不对或其他问题,需要定位找到根因进行调整。
numactl -C 0-13,28-41,14-27,42-55 ./runBenchmark.sh props.pg
# 查看当前NUMA节点的内存访问命中率
numastat
# 通过htop查看各CPU的使用情况
从numactl执行结果可以看到,示例服务器共划分为2个NUMA节点。每个节点包含28个CPU core,每个节点的内存大小约为128GB。同时,该命令还给出了不同节点间的距离,距离越远,跨NUMA内存访问的延时越大。应用程序运行时应减少跨NUMA访问内存。