https://zhuanlan.zhihu.com/p/91757020?utm_id=0复制
有的同学虽然写了一段时间 Java 了,但是对于 JVM 却不太关注。有的同学说,参数都是团队规定好的,部署的时候也不用我动手,关注它有什么用,而且,JVM 这东西,听上去就感觉很神秘很高深的样子,还是算了吧。
没错,部署的时候可能用不到你亲自动手,但是出现问题了怎么办,难道不用你解决问题吗,如果对 JVM 了解不够的话,有些问题可能排查起来就很费力,或者根本无法解决。
本篇以 JDK Hotspot 8 为背景,介绍一下 JVM 的常用参数。建议你在做一些小项目、小 demo 的时候,也把这些参数加上,加深印象。以我的经验来看,有些知识你刚开始接触的时候会感觉很难理解,但是没关系,万事开头难嘛,知识点都是需要消化时间的。第一天不理解,甚至过了一个月也不理解,但是总有那么一刻,你会突然有种茅塞顿开的感觉,感觉一下子通了。最后心里面感谢自己在多少多少天以前能够开始学习并坚持学习这些知识点。
只介绍一些常用参数,除了这些常用参数外,Hotspot 还提供了很多其他的参数,每一个都值得考究。
在使用这些参数之前,你需要对 Java 内存模型有一定的了解,可以读一下 这篇文章 了解一下内存模型。
还是要把内存模型图放在这里,方便理解。
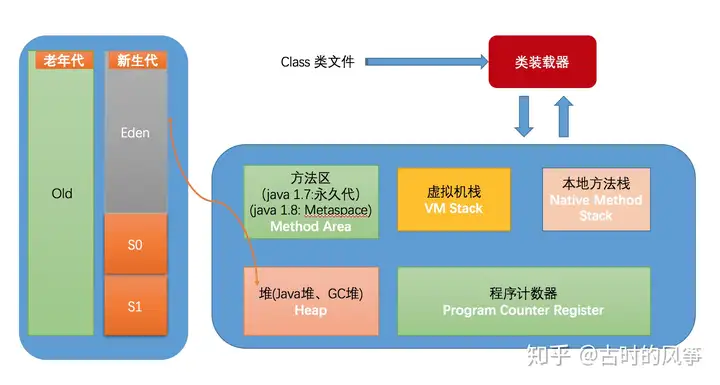
-Xms: 堆的初始值,例如 -Xmx2048,初始堆大小为 2G
-Xmx: 堆的最大值,例如 -Xmx2048M,允许最大堆内存 2G
-Xmn: 新生代大小
-XX:SurvivorRatio:Eden 区所占比例,默认是 8,也就是 80%,例如 -XX:SurvivorRatio=8
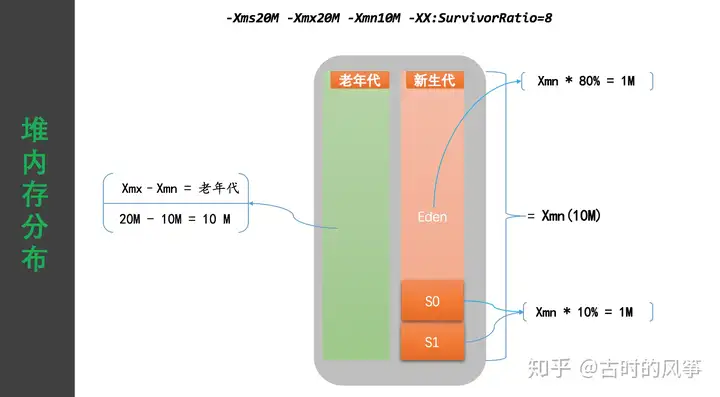
最好将 -Xms 和 -Xmx 的值设置成一样的值,这样做是为了防止随着堆空间使用量增加,会动态的调整堆空间大小,有一定的性能损耗,不如开始就设置成相同的值,来规避性能损失。
-Xss:栈空间大小,栈是线程独占的,所以是一个线程使用栈空间的大小,例如 -Xss256K,如果不设置此参数,默认值是 1M,一般来讲设置成 256K 就足够了。
-XX:MetaspaceSize:Metaspace 空间初始大小,如果不设置的话,默认是20.79M,这个初始大小是触发首次 Metaspace Full GC 的阈值,例如 -XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize:Metaspace 最大值,默认不限制大小,但是线上环境建议设置,例如
-XX:MaxMetaspaceSize=256M
-XX:MinMetaspaceFreeRatio:最小空闲比,当 Metaspace 发生 GC 后,会计算 Metaspace 的空闲比,如果空闲比(空闲空间/当前 Metaspace 大小)小于此值,就会触发 Metaspace 扩容。默认值是 40 ,也就是 40%,例如 -XX:MinMetaspaceFreeRatio=40
-XX:MaxMetaspaceFreeRatio:最大空闲比,当 Metaspace 发生 GC 后,会计算 Metaspace 的空闲比,如果空闲比(空闲空间/当前 Metaspace 大小)大于此值,就会触发 Metaspace 释放空间。默认值是 70 ,也就是 70%,例如 -XX:MaxMetaspaceFreeRatio=70
建议将 MetaspaceSize 和 MaxMetaspaceSize 设置为同样大小,避免频繁扩容。
简单日志
-verbose:gc 或者 -XX:+PrintGC
日志格式:
[GC (Allocation Failure) 7892K->5646K(19456K), 0.0060442 secs]
[GC (Allocation Failure) , 0.0066315 secs]
[Full GC (Allocation Failure) 19302K->13646K(19456K), 0.0032698 secs]复制详细日志
#打印详细日志
-XX:+PrintGCDetails
#打印 GC 的时间点
-XX:+PrintGCDateStamps复制日志格式:
2019-11-13T14:06:46.099-0800: [GC (Allocation Failure) 2019-11-13T14:06:46.099-0800: [DefNew (promotion failed) : 9180K->9157K(9216K), 0.0084297 secs]2019-11-13T14:06:46.107-0800: [Tenured: 10145K->10145K(10240K), 0.0035768 secs] 13802K->13646K(19456K), [Metaspace: 3895K->3895K(1056768K)], 0.0120887 secs] [Times: user=0.00 sys=0.00, real=0.02 secs]
2019-11-13T14:06:47.243-0800: [Full GC (Allocation Failure) 2019-11-13T14:06:47.244-0800: [Tenured: 10145K->10145K(10240K), 0.0042686 secs] 19304K->19146K(19456K), [Metaspace: 3895K->3895K(1056768K)], 0.0043232 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]复制以下几个 GC 日志相关的参数打印的内容比较多,生产环境可选择性开启,大多数时候不需要开启。
GC 前后的堆信息
-XX:+PrintHeapAtGC
{Heap before GC invocations=0 (full 0):
def new generation total 9216K, used 7892K [0x00000007bec00000, 0x00000007bf600000, 0x00000007bf600000)
eden space 8192K, 96% used [0x00000007bec00000, 0x00000007bf3b5200,
xxx....
class space used 445K, capacity 462K, committed 512K, reserved 1048576K
Heap after GC invocations=1 (full 0):
def new generation total 9216K, used 1023K [0x00000007bec00000,
xxx...
Metaspace used 3892K, capacity 4646K, committed 4864K, reserved 1056768K
class space used 445K, capacity 462K, committed 512K, reserved 1048576K
}复制GC 导致的 Stop the world 时间
-XX:+PrintGCApplicationStoppedTime
Total time for which application threads were stopped: 0.0070384 seconds, Stopping threads took: 0.0000200 seconds复制加载类信息
-verbose:class
[Loaded java.net.URLClassLoader$3$1 from /Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home/jre/lib/rt.jar]复制GC 前后的类加载情况
-XX:+PrintClassHistogramBeforeFullGC
-XX:+PrintClassHistogramAfterFullGC
num #instances #bytes class name
----------------------------------------------
1: 140 19016264 [B
2: 2853 226256 [C
3: 138 169072 [I
4: 761 86240 java.lang.Class
5: 2850 68400 java.lang.String
6: 660 41024 [Ljava.lang.Object;复制日志输出到文件
以上参数配置好之后,默认会输出到控制台或者服务指定的统一日志的位置。但是这里还会有服务的一般性信息日志、错误日志等,都混在一起的话会比较乱,所以,一般都会把 jvm 日志单独存放。
#GC 活动日志,根据配置的参数输出内容
-Xloggc:/Users/fengzheng/jvmlog/gc.log
#致命错误日志,只有在 jvm 发生崩溃的时候会输出
-XX:ErrorFile=/Users/fengzheng/jvmlog/hs_err_pid%p.log复制堆溢出现场保留
有些错误虽然不会导致 jvm 崩溃,但是对于服务而言也是非常严重的,比如stackOverflow、OutOfMemoryError,发生错误后,留存现场信息对分析错误原因是至关重要的。jvm 提供了保留堆溢出现场的方法,对于 JDK 8 而言,可能是 heap 溢出,也可能是 Metasapce 溢出。
-XX:HeapDumpPath=/Users/fengzheng/jvmlog
-XX:+HeapDumpOnOutOfMemoryError复制最后出现异常后,保存的文件格式为 java_pidxxx.hprof,pid 后面是发生溢出的进程 id,之后可以用 VisualVM、JProfiler 等工具打开分析。
随着 JDK 版本的升级,可使用的垃圾收集器类型也越来越多了。JDK 8 可使用的垃圾收集器有 7 种,当然有点只适用于年轻代,有点只使用于老年代,JDK 8 中最新的垃圾收集器是 G1,可以用于年轻代和老年代。到了 JDK 11,还出了 ZGC。
下图是 JDK 8 中可使用的垃圾收集器以及它们配合使用的关系。
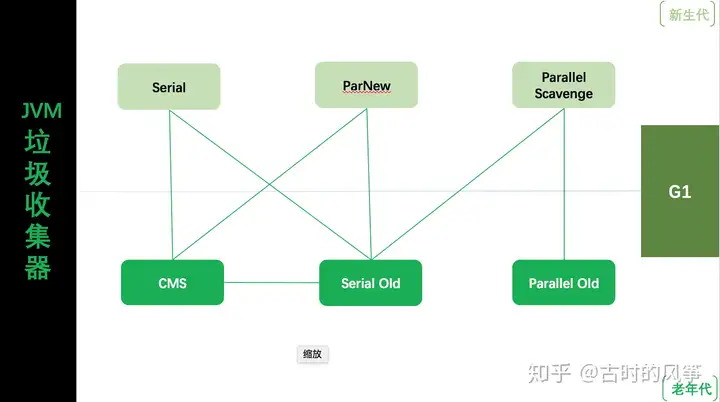
Serial、ParNew、Parallel Scavenge 只适用于年轻代,CMS、Serial Old、Parallel Old 只适用于老年代,而 G1 通用于年轻代和老年代。连线表示它们之间可配合使用的关系,其中 CMS 和 Serial Old 连线的意思是说 Serial Old 会作为 CMS 的后预案,当 CMS 发生 Concurrent Mode Failure 时启用。
在 JDK 8 中,如果不指定垃圾收集器,默认使用参数 -XX:+UseParallelGC,新生代使用 Parallel Scavenge,老年代使用 Serial Old。
-XX:+UseSerialGC:使用 Serial + Serial Old ,运行于 client 模式下的默认设置
-XX:+UseConcMarkSweepGC:使用 ParNew+CMS+Serial Old,CMS 垃圾收集器
-XX:+UseParallelGC:Parallel Scavenge + Serial Old,JDK 8 server 模式下的默认设置
-XX:+UseParallelOldGC:Parallel Scavenge + Parallel Old
-XX:+UseG1GC:使用 G1 垃圾收集器
除了日志外,当我们需要实时查看 JVM 运行情况的时候怎么办,当然可以到 JVM 所在服务器用 jstack、jmap、jinfo 等工具进行查看,但是又不够直观,这时候就需要开启 JMX 远程功能,使用 jConsole、VisualVM 等工具进行监控。或者自己开发监控平台,比如我之前就做了一个 web 版的简易 VisualVm。无意中就做了个 web 版 JVM 监控端
开启参数如下:
-Dcom.sun.management.jmxremote
#指定 jvm 所在服务器 ip 或域名
-Djava.rmi.server.hostname=192.168.1.1
#指定端口
-Dcom.sun.management.jmxremote.port=9999
-Dcom.sun.management.jmxremote.rmi.port=9999
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false复制