https://www.zhihu.com/column/c_1087047428959608832?utm_id=0复制
目前我们EC Bigdata team 运维公司 4个 Redis 集群,300+ Redis 实例,500G+ 的内存数据,我们想要分析业务是否有误用,以提高资源利用率。伴随着业务team的广泛使用,近期数据增 长比较快,我们紧迫需要一个工具分析一下各种业务存储的数据有多大,是否存入僵死数据浪费资源;同时E4 WWW redis 集群有业务方反馈近期有比较明显的慢查询发生,所以我们需要针对 slow log 和存入的常用数据类型Hash,List,Set分析,是否有big key引起慢查询,是否有team存在超大的 big key和不合理设置ttl的情况
那有没有什么办法让我们安全高效的看到 Redis 内存消耗的详细报表呢?办法总比问题多,有需求就有解决方案。EC Bigdata team针对这个问题实现了一个 Redis 内存数据可视化分析平台 RCT (Redis Computed Tomography)。
RCT可以非常方便的对 Reids 的内存进行分析,了解一个 Redis 实例里都有哪些 key,哪类 key 占用的空间是多少,最耗内存的 key 有哪些,占比如何,非常直观,除此之外,我们还可以针对Redis slowlog/clientlist进行分钟级别监控,直观监控集群效应状况。
市面上已经存在这么多开源的产品,我们为什么还要重新做一个呢?主要还是没有满足我们的需求,以上的都是redis rdb解析工具,最接近我们需求的就是雪球开源的rdr,但是也只限于离线分析,而我们节点众多,不可能一个一个去线上机器copy,或者开发copy工具,这样也会给相应机器带来网络热点(总有办法解决这个问题),带来很多繁重无意义的劳动,么不是专门的运维工程师,还有更多的开发任务等着我们去做。
我们想要一个每天都会给我们产生报表,自动推送到我们的邮箱,或者在网页上就能看到最近redis内存的变化,它不仅仅是一个工具,还是常态化运行的服务,基于此我们打造了属于最近的redis内存分析平台RCT。
使用 bgsave,获取 rdb 文件,解析后获取数据。
优点:机制成熟,可靠性好;文件相对小,传输、解析效率高;
缺点:bgsave 虽然会 fork 子进程,但还是有可能导致主进程卡住一段时间,对业务有产生影响的风险;
采用低峰期在从节点做 bgsave 获取 rdb 文件,相对安全可靠。拿到了 rdb 文件就相当于拿到了 Redis 实例的所有数据,接下来就是生成报表的过程了:
解析 rdb 文件,获取到 Key 和 Value 的内容;根据相对应的数据结构及内容,估算内存消耗等;统计并生成报表;逻辑很简单,所以设计思路很清晰。
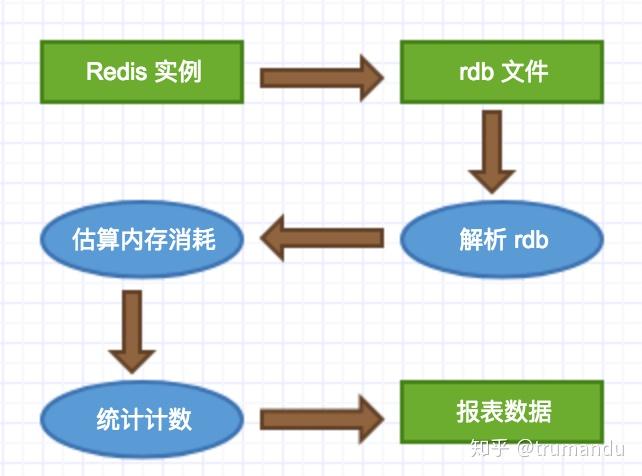
为了使对线上机器不产生影响,我们选择是在slave节点进行rdb文件分析,该任务是分布式的。为了均衡对每个机器的影响,通过算法去保证slave分配算法均匀的落在不同的机器上。
/**
* 根据<master:slaves>获取执行分析任务ports规则
* 即获取其中一个slave,尽量保持均衡在不同机器上
*
* @param clusterNodesMap
* @return <ip:ports>
*/
public static Map<String, Set<String>> generateAnalyzeRule(Map<String, List<String>> clusterNodesMap) {
// 通过该map存储不同IP分配的数量,按照规则,优先分配数量最小的IP
Map<String, Integer> staticsResult = new HashMap<>();
Map<String, Set<String>> generateRule = new HashMap<>();
// 此处排序是为了将slave数量最小的优先分配
List<Map.Entry<String, List<String>>> sortList = new LinkedList<>(clusterNodesMap.entrySet());
Collections.sort(sortList, new Comparator<Entry<String, List<String>>>() {
@Override
public int compare(Entry<String, List<String>> o1, Entry<String, List<String>> o2) {
return o1.getValue().size() - o2.getValue().size();
}
});
for (Entry<String, List<String>> entry : sortList) {
List<String> slaves = entry.getValue();
boolean isSelected = false;
String tempPort = null;
String tempIP = null;
int num = 0;
for (String slave : slaves) {
String ip = slave.split(":")[0];
String port = slave.split(":")[1];
// 统计组里面不存在的IP优先分配
if (!staticsResult.containsKey(ip)) {
staticsResult.put(ip, 1);
Set<String> generatePorts = generateRule.get(ip);
if (generatePorts == null) {
generatePorts = new HashSet<>();
}
generatePorts.add(port);
generateRule.put(ip, generatePorts);
isSelected = true;
break;
} else {
// 此处是为了求出被使用最少的IP
Integer staticsNum = staticsResult.get(ip);
if (num == 0) {
num = staticsNum;
tempPort = port;
tempIP = ip;
continue;
}
if (staticsNum < num) {
tempPort = port;
tempIP = ip;
num = staticsNum;
}
}
}
// 如果上面未分配,则选择staticsResult中数值最小的那个slave
if (!isSelected) {
if (slaves != null && slaves.size() > 0) {
if (tempPort != null) {
Set<String> generatePorts = generateRule.get(tempIP);
if (generatePorts == null) {
generatePorts = new HashSet<>();
}
generatePorts.add(tempPort);
generateRule.put(tempIP, generatePorts);
staticsResult.put(tempIP, staticsResult.get(tempIP) + 1);
}
}
}
}
return generateRule;
}
复制redis中支持多种内存分配算法,推荐Jemalloc,因此我们选择该算法来预估内存大小。因为这个算法比较复杂,我们参考雪球做法使用约定数组,根据不同数据大小分配不同内存空间,为了提高查找效率,这块采用了变种二分查找。
public class Jemalloc {
private static long[] array16;
private static long[] array192;
private static long[] array768;
private static long[] array4096;
private static long[] array4194304;
static {
array16 = range(16, 128 + 1, 16);
array192 = range(192, 512 + 1, 64);
array768 = range(768, 4096 + 1, 256);
array4096 = range(4096, 4194304 + 1, 4096);
array4194304 = range(4194304, 536870912 + 1, 4194304);
}
/**
* 根据Jemalloc 估算分配内存大小 Small: All 2^n-aligned allocations of size 2^n will incur
* no additional overhead, due to how small allocations are aligned and packed.
* Small: [8], [16, 32, 48, ..., 128], [192, 256, 320, ..., 512], [768, 1024,
* 1280, ..., 3840] Large: The worst case size is half the chunk size, in which
* case only one allocation per chunk can be allocated. If the remaining
* (nearly) half of the chunk isn't otherwise useful for smaller allocations,
* the overhead will essentially be 50%. However, assuming you use a diverse
* mixture of size classes, the actual overhead shouldn't be a significant issue
* in practice. Large: [4 KiB, 8 KiB, 12 KiB, ..., 4072 KiB] Huge: Extra virtual
* memory is mapped, then the excess is trimmed and unmapped. This can leave
* virtual memory holes, but it incurs no physical memory overhead. Earlier
* versions of jemalloc heuristically attempted to optimistically map chunks
* without excess that would need to be trimmed, but it didn't save much system
* call overhead in practice. Huge: [4 MiB, 8 MiB, 12 MiB, ..., 512 MiB]
*
* @param size
* @return
*/
public static long assign(long size) {
if (size <= 4096) {
// Small
if (is_power2(size)) {
return size;
} else if (size < 128) {
return min_ge(array16, size);
} else if (size < 512) {
return min_ge(array192, size);
} else {
return min_ge(array768, size);
}
} else if (size < 4194304) {
// Large
return min_ge(array4096, size);
} else {
// Huge
return min_ge(array4194304, size);
}
}
/**
* 创建一个long数组
*
* @param start
* @param stop
* @param step
* @return
*/
public static long[] range(int start, int stop, int step) {
int size = (stop - 1 - start) / step + 1;
long[] array = new long[size];
int index = 0;
for (int i = start; i < stop; i = i + step) {
array[index] = i;
index++;
}
return array;
}
public static long min_ge(long[] srcArray, long key) {
int index = binarySearch(srcArray, key);
return srcArray[index];
}
// 二分查找最小值,即最接近要查找的值,但是要大于该值
public static int binarySearch(long srcArray[], long key) {
int mid = (0+srcArray.length-1) / 2;
if (key == srcArray[mid]) {
return mid;
}
if (key > srcArray[mid] && key <= srcArray[mid + 1]) {
return mid + 1;
}
int start = 0;
int end = srcArray.length - 1;
while (start <= end) {
mid = (end - start) / 2 + start;
if (key == srcArray[mid]) {
return mid;
}
if (key > srcArray[mid] && key <= srcArray[mid + 1]) {
return mid + 1;
}
if (key < srcArray[mid]) {
end = mid - 1;
}
if (key > srcArray[mid]) {
start = mid + 1;
}
}
return 0;
}
public static boolean is_power2(long size) {
if (size == 0) {
return false;
}
if ((size & (size - 1)) == 0) {
return true;
}
return false;
}
}
复制详见redis源码
private static final long redisObject = (long)(8 + 8);
// 一个dictEntry,24字节,jemalloc会分配32字节的内存块
private static final long dicEntry = (long)(2 * 8 + 8 + 8);
private static final String patternString = "^[-\\\\+]?[\\\\d]*$";
private static long skiplistMaxLevel = 32;
private static long redisSharedInterges = 10000;
private static long longSize = 8;
private static long pointerSize = 8;
/**
* 一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+len+1=len+9
*
* @param length
* @return
*/
private static long sds(long length) {
long mem = 9 + length;
return mem;
}
/**
*
* 计算 string byte 大小
*
* @param kv
* https://searchdatabase.techtarget.com.cn/wp-content/uploads/res/database/article/2011/2011-11-14-16-56-18.jpg
* @return
*/
public static long CalculateString(KeyStringValueString kv) {
long mem = KeyExpiryOverhead(kv);
mem = dicEntry + SizeofString(kv.getRawKey());
mem = mem + redisObject + SizeofString(kv.getValueAsString());
return mem;
}
public static long CalculateLinkedList(KeyStringValueList kv) {
long mem = KeyExpiryOverhead(kv);
mem = mem + SizeofString(kv.getRawKey());
mem = mem + redisObject;
mem = mem + dicEntry;
long length = kv.getValueAsStringList().size();
mem = mem + LinkedListEntryOverhead() * length;
mem = mem + LinkedlistOverhead();
mem = mem + redisObject * length;
for (String value : kv.getValueAsStringList()) {
mem = mem + SizeofString(value);
}
return mem;
}
public static long CalculateZipList(KeyStringValueList kv) {
long mem = KeyExpiryOverhead(kv);
mem = mem + dicEntry;
mem = mem + SizeofString(kv.getRawKey());
mem = mem + redisObject;
long length = kv.getValueAsStringList().size();
mem = mem + ZiplistOverhead(length);
for (String value : kv.getValueAsStringList()) {
mem = mem + ZiplistAlignedStringOverhead(value);
}
return mem;
}
public static long CalculateHash(KeyStringValueHash kv) {
long mem = KeyExpiryOverhead(kv);
mem = mem + SizeofString(kv.getRawKey());
mem = mem + redisObject;
mem = mem + dicEntry;
long length = kv.getValueAsHash().size();
mem = mem + HashtableOverhead(length);
for (String key : kv.getValueAsHash().keySet()) {
String value = kv.getValueAsHash().get(key);
mem = mem + SizeofString(key);
mem = mem + SizeofString(value);
mem = mem + 2 * redisObject;
mem = mem + HashtableEntryOverhead();
}
return mem;
}
public static long CalculateSet(KeyStringValueSet kv) {
long mem = KeyExpiryOverhead(kv);
mem = mem + SizeofString(kv.getRawKey());
mem = mem + redisObject;
mem = mem + dicEntry;
long length = kv.getValueAsSet().size();
mem = mem + HashtableOverhead(length);
mem = mem + redisObject * length;
for (String value : kv.getValueAsSet()) {
mem = mem + SizeofString(value);
mem = mem + 2 * redisObject;
mem = mem + HashtableEntryOverhead();
}
return mem;
}
public static long CalculateIntSet(KeyStringValueSet kv) {
long mem = KeyExpiryOverhead(kv);
mem = mem + dicEntry;
mem = mem + SizeofString(kv.getRawKey());
mem = mem + redisObject;
long length = kv.getValueAsSet().size();
mem = mem + IntsetOverhead(length);
for (String value : kv.getValueAsSet()) {
mem = mem + ZiplistAlignedStringOverhead(value);
}
return mem;
}
public static long CalculateZSet(KeyStringValueZSet kv) {
long mem = KeyExpiryOverhead(kv);
mem = mem + SizeofString(kv.getRawKey());
mem = mem + redisObject;
mem = mem + dicEntry;
long length = kv.getValueAsSet().size();
mem = mem + SkiplistOverhead(length);
mem = mem + redisObject * length;
for (ZSetEntry value : kv.getValueAsZSet()) {
mem = mem + 8;
mem = mem + SizeofString(value.getElement());
// TODO 还有个 score
mem = mem + 2 * redisObject;
mem = mem + SkiplistEntryOverhead();
}
return mem;
}
// TopLevelObjOverhead get memory use of a top level object
// Each top level object is an entry in a dictionary, and so we have to include
// the overhead of a dictionary entry
public static long TopLevelObjOverhead() {
return HashtableEntryOverhead();
}
/**
* SizeofString get memory use of a string
* https://github.com/antirez/redis/blob/unstable/src/sds.h
*
* @param bytes
* @return
*/
public static long SizeofString(byte[] bytes) {
String value = new String(bytes);
if (isInteger(value)) {
try {
Long num = Long.parseLong(value);
if (num < redisSharedInterges && num > 0) {
return 0;
}
return 8;
} catch (NumberFormatException e) {
}
}
return Jemalloc.assign(sds(bytes.length));
}
public static long SizeofString(String value) {
if (isInteger(value)) {
try {
Long num = Long.parseLong(value);
if (num < redisSharedInterges && num > 0) {
return 0;
}
return 8;
} catch (NumberFormatException e) {
}
}
return Jemalloc.assign(sds(value.length()));
}
public static long DictOverhead(long size) {
return Jemalloc.assign(56 + 2*pointerSize + nextPower(size) * 3*8);
}
public static boolean isInteger(String str) {
Pattern pattern = Pattern.compile(patternString);
return pattern.matcher(str).matches();
}
/**
* 过期时间也是存储为一个 dictEntry,时间戳为 int64;
*
* @param kv
* @return
*/
// KeyExpiryOverhead get memory useage of a key expiry
// Key expiry is stored in a hashtable, so we have to pay for the cost of a
// hashtable entry
// The timestamp itself is stored as an int64, which is a 8 bytes
@SuppressWarnings("rawtypes")
public static long KeyExpiryOverhead(KeyValuePair kv) {
// If there is no expiry, there isn't any overhead
if (kv.getExpiredType() == ExpiredType.NONE) {
return 0;
}
return HashtableEntryOverhead() + 8;
}
public static long HashtableOverhead(long size) {
return 4 + 7 * longSize + 4 * pointerSize + nextPower(size) * pointerSize * 3 / 2;
}
// HashtableEntryOverhead get memory use of hashtable entry
// See https://github.com/antirez/redis/blob/unstable/src/dict.h
// Each dictEntry has 2 pointers + int64
public static long HashtableEntryOverhead() {
return 2 * pointerSize + 8;
}
public static long ZiplistOverhead(long size) {
return Jemalloc.assign(12 + 21 * size);
}
public static long ZiplistAlignedStringOverhead(String value) {
try {
Long.parseLong(value);
return 8;
} catch (NumberFormatException e) {
}
return Jemalloc.assign(value.length());
}
// LinkedlistOverhead get memory use of a linked list
// See https://github.com/antirez/redis/blob/unstable/src/adlist.h
// A list has 5 pointers + an unsigned long
public static long LinkedlistOverhead() {
return longSize + 5 * pointerSize;
}
// LinkedListEntryOverhead get memory use of a linked list entry
// See https://github.com/antirez/redis/blob/unstable/src/adlist.h
// A node has 3 pointers
public static long LinkedListEntryOverhead() {
return 3 * pointerSize;
}
// SkiplistOverhead get memory use of a skiplist
public static long SkiplistOverhead(long size) {
return 2 * pointerSize + HashtableOverhead(size) + (2 * pointerSize + 16);
}
// SkiplistEntryOverhead get memory use of a skiplist entry
public static long SkiplistEntryOverhead() {
return HashtableEntryOverhead() + 2 * pointerSize + 8 + (pointerSize + 8) * zsetRandLevel();
}
public static long nextPower(long size) {
long power = 1;
while (power <= size) {
power = power << 1;
}
return power;
}
public static long zsetRandLevel() {
long level = 1;
int rint = new Random().nextInt(65536);
int flag = 65535 / 4;
while (rint < flag) {// skiplistP
level++;
rint = new Random().nextInt(65536);
}
if (level < skiplistMaxLevel) {
return level;
}
return skiplistMaxLevel;
}
public static long IntsetOverhead(long size) {
// typedef struct intset {
// uint32_t encoding;
// uint32_t length;
// int8_t contents[];
// } intset;
return (4 + 4) * size;
}
复制RCT是一个一站式redis内存分析分析平台,分析任务是分布式的,需要将RCT-Analyze部署到rdb所在机器上,RCT-Dashboard部署在任何机器,只要能保持和RCT-Analyze通信即可。不同于以上列举的工具,我们最初定位RCT就是一个可以长期运行,尽可能每天分析redis中数据,为redis运维人员提供运维依据,便于做出更好的规范,高效的使用redis。
部署过程略,详见官方文档,推荐使用docker方式,这样也是我们目前采用的方式。
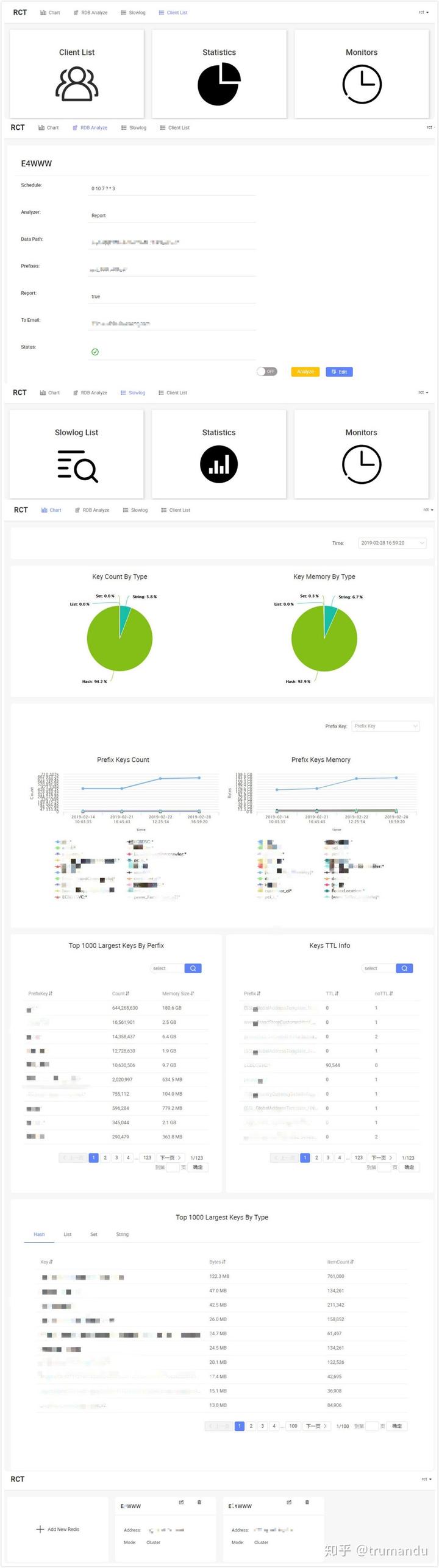
只有先创建了redis节点之后,才能进入到RCT工具导航页面。 1. 点击导航RDB Analyze 2. 如若一直没有添加过RDB信息,则可在页面弹出的框中进行完善信息,或者点击下方的Add按钮进行添加 3. 点击edit则可以对RDB 信息进行修改 4. 如若已经完善了RDB信息,则点击打开switch开关,则是对RDB直接进行定时任务的开启和关闭 5. 点击Analyze,则是对RDB信息进行手动分析,分析进行的状态可在status中查看,可以通过status后面的链接进入到实时查看rdb分析任务的进度状态
RDB主页面参数与add页面参数基本相同,在此不再做赘述,唯一有区别的是: Status:分析RDB文件的进度状态,分为成功,正在分析,失败三种状态,status为正在分析状态时,可通过点击后面的链接进入到实时分析页面,查看实时状态。
点击Analyze,则是对RDB信息进行手动分析,分析进行的状态可在status中查看,可以通过status后面的链接进入到实时查看rdb分析任务的进度状态
目前RCT支持dashboard/email两种方式,这里我仅展示dashboard.
https://github.com/xaecbd/RCT,欢迎使用,欢迎加入我们,帮我们提高RCT。如果你有问题,可以前往github新建issue。