https://plantegg.github.io/2019/07/19/%E5%B0%B1%E6%98%AF%E8%A6%81%E4%BD%A0%E6%87%82%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1--%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1%E8%B0%83%E5%BA%A6%E7%AE%97%E6%B3%95%E5%92%8C%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E5%9D%87%E8%A1%A1/复制
最近用 sysbench 做压测的时候,sysbench每次创建100个长连接,lvs后面两台RS(通过wlc来均衡),发现每次都是其中一台差不多95个连接,另外一台大概5个连接,不均衡得太离谱了,并且稳定重现,所以想要搞清楚为什么会出现20倍的不均衡。
前面是啰嗦的基础知识部分,bug直达文章末尾
vip:Virtual IP,LVS实例IP
RS: Real Server 后端真正提供服务的机器
LB: Load Balance 负载均衡器
LVS: Linux Virtual Server
复制LVS的负载调度算法有10种,其它不常用的就不说了,凑数没有意义。基本常用的如下四种,这四种又可以分成两大种:rr轮询调度和lc最小连接调度。
轮询调度(Round Robin Scheduling)算法就是以轮询的方式依次将请求调度到不同的服务器,即每次调度执行i = (i + 1) mod n,并选出第i台服务器。算法的优点是其简洁性,它无需记录当前所有连接的状态,不管服务器上实际的连接数和系统负载,所以它是一种无状态调度。
加权轮询调度(Weighted Round-Robin Scheduling)算法可以解决服务器间性能不一的情况,它用相应的权值表示服务器的处理性能,服务器的缺省权值为1。假设服务器A的权值为1,B的权值为2,则表示服务器B的处理性能是A的两倍。加权轮叫调度算法是按权值的高低和轮叫方式分配请求到各服务器。权值高的服务器先收到的连接,权值高的服务器比权值低的服务器处理更多的连接,相同权值的服务器处理相同数目的连接数。
最小连接调度(Least-Connection Scheduling)算法是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态调度算法,它通过服务器当前所活跃的连接数来估计服务器的负载情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中止或超时,其连接数减一。
如果集群系统的真实服务器具有相近的系统性能,采用”最小连接”调度算法可以较好地均衡负载。
特别注意:这种调度算法还需要考虑active(权重*256)和inactive连接的状态,这个实现考量实际会带来严重的不均衡问题。
加权最小连接调度(Weighted Least-Connection Scheduling)算法是最小连接调度的超集,各个服务器用相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。
调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
其中wlc和lc可以看成一种,wrr和rr可以看成另外一种。下面只重点说wrr和wlc为什么不均衡
非常简单,来了新连接向各个RS转发就行,比如一段时间内创建100个连接,那这100个连接能基本均匀分布在后端所有RS上。
如果所有请求都是长连接,如果后端有RS重启(宕机、OOM服务不响应、日常性重启等等),那么其上面的连接一般会重建,重建的新连接会均匀分布到其它RS上,当重启的RS正常加入到LVS后,它上面的连接是最少的,即使后面大批量建新的连接,也只是新连接在这些RS上均匀分布,重新加入的RS没法感知到历史已经存在的老连接所以容易导致负载不均衡。
批量重启所有RS(升级等,多个RS进入服务状态肯定有先后),第一个起来的RS最容易获取到更多的连接,压力明显比其它RS要大,这肯定也是不符合预期的。
总之wrr/rr算法因为不考虑已存在的连接问题,在长连接的情况下对RS重启、扩容(增加新的RS)十分不友好,容易导致长连接的不均衡。
当然对于短连接不存在这个问题,所以可以考虑让应用端的连接不要那么长,比如几个小时候断开重新连接一下。升级的时候等所有RS都启动好后再让LVS开始工作等
不等效。原因是由于RR调试算法加入了初始随机因子,而WRR由于算法的限制没有此功能。因此在新建连接数少,同时并发连接少,也没有预热的情况下,RR算法会有更好的均衡性表现。
WRR在每一次健康检查抖动的时候,会重置调度器,从头开始WRR的逻辑,因此可能会导致调度部分调度不均匀。
比如如下这个负载不均衡,因为第一个RS CPU特别忙,QPS的不均衡大致能说明工作连接的差异

和lvs负载监控数据对比来看是一致的:
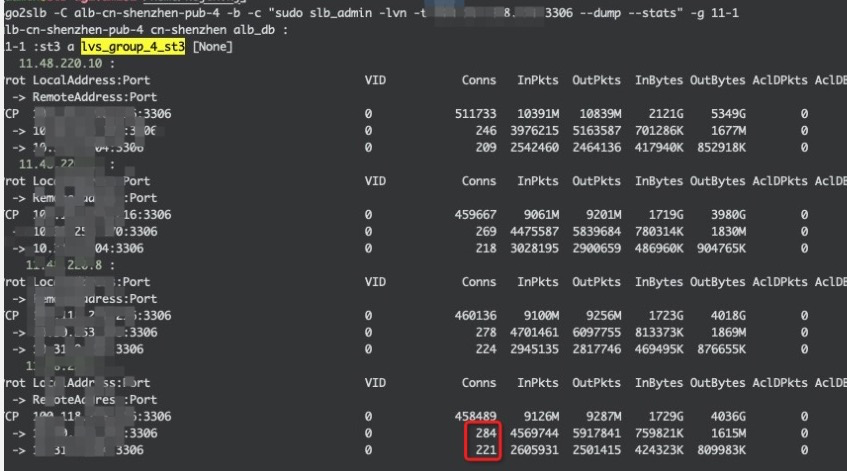
针对wrr对长连接的上述不均衡,所以wlc算法考虑当前已存在的连接数,尽量把新连接发送到连接数较少的RS上,看起来比较完美地修复了wrr的上述不均衡问题。
wlc将连接分成active(ESTABLISHED)和inactive(syn/fin等其它状态),收到syn包后LVS按照如下算法判定该将syn发给哪个RS
static inline int
ip_vs_dest_conn_overhead(struct ip_vs_dest *dest)
{
/* We think the overhead of processing active connections is 256
* times higher than that of inactive connections in average. (This
* 256 times might not be accurate, we will change it later) We
* use the following formula to estimate the overhead now:
* dest->activeconns*256 + dest->inactconns
*/
return (atomic_read(&dest->activeconns) << 8) +
atomic_read(&dest->inactconns);
}
复制也就是一个active状态的连接权重是256,一个inactive权重是1,然后将syn发给总连接负载最轻的RS。
这里会导致不均衡过程: 短时间内有一批syn冲过来(同时并发创建一批连接),必然有一个RS(假如这里总共两个RS)先建立第一个active的连接,在第二个RS也建立第一个active连接之前,后面的syn都会发给第二个RS,那么最终会看到第二个RS的连接远大于第一个RS,这样就导致了最终连接数的负载不均衡。
主要是因为这里对inactive 连接的判定比较糙,active连接的权重直接256就更糙了(作者都说了是拍脑袋的)。实际握手阶段的连接直接都判定为active比较妥当,挥手阶段的连接判定为inactive是可以的,但是active的权重取4或者8就够了,256有点夸张。
这个不均衡场景可以通过 sysbench 稳定重现,如果两个RS的rt差异大一点会更明显。
RS到LVS之间的时延差异会放大这个不均衡,这个差异必然会存在,再就是vpc网络环境下首包延时很大(因为overlay之类的网络,连接的首包都会去网关拉取路由信息,所以首包都很慢),差异会更明显,因为这些都会影响第一个active连接的建立。
只对NAT模式下有效:
With LVS-NAT, the director sees all the packets between the client and the realserver, so always knows the state of tcp connections and the listing from ipvsadm is accurate. However for LVS-DR, LVS-Tun, the director does not see the packets from the realserver to the client.
Example with my Apache Web server.
Client <---> Server
A client request an object on the web server on port 80 :
SYN REQUEST ---->
SYN ACK <----
ACK ----> *** ActiveConn=1 and 1 ESTABLISHED socket on realserver.
HTTP get ----> *** The client request the object
HTTP response <---- *** The server sends the object
APACHE closes the socket : *** ActiveConn=1 and 0 ESTABLISHED socket on realserver
The CLIENT receives the object. (took 15 seconds in my test)
ACK-FIN ----> *** ActiveConn=0 and 0 ESTABLISHED socket on realserver
复制阿里slb集群下多台LVS服务器之间是开启的session同步功能,因此WLC在计算后端RS的连接权重时会将其它LVS服务器同步的连接计算进来,所以说实际上是一个准全局的调度算法,因此它的调度均衡性最好
WLC由于要计算所有连接的权重,因此消耗的CPU最多,性能最差。由于Session同步不是实时的,同时WLC算法对完成三次握手连接与半开连接的计算权重不同,因此WLC算法不适合突发新建连接的场景。
lvs(多个LVS节点的集群)后面总共两个RS,如果一次性同时创建100个连接,那么基本上这个100个连接都在第一个RS上,如果先创建50个,这时这50个基本在第一个RS上,休息几秒钟,再创建50个,那么第二批的50个基本落在第二个RS上。
如果先创建50个,这时这50个基本在第一个RS上,休息几秒钟,再创建100个,那么第二批的100个中前50个基本落在第二个RS上,后面50个又都跑到第一个RS上了。
LB 上开启了“会话保持”(Session Persistence),会将会话黏在某个RS上,如果刚好某个请求端访问量大,就会导致这个RS访问量大,从而不均衡
LVS的会话保持有这两种
把同一个client的请求信息记录到lvs的hash表里,保存时间使用persistence_timeout控制,单位为秒。 persistence_granularity 参数是配合persistence_timeout的,在某些情况特别有用,他的值是子网掩码,表示持久连接的粒度,默认是 255.255.255.255,也就是单独的client ip,如果改成,255.255.255.0就是client ip一个网段的都会被分配到同一个real server。
一个连接创建后空闲时的超时时间,这个时间为3种
What is an ActiveConn/InActConn (Active/Inactive) connnection?