http://arthurchiao.art/blog/linux-net-stack-zh/复制
本文尝试从技术研发与工程实践(而非纯理论学习)角度,在原理与实现、监控告警、 配置调优三方面介绍内核5.10 网络栈。由于内容非常多,因此分为了几篇系列文章。
原理与实现
监控
调优
作为网络、虚拟化、稳定性等方向的研发工程师,我们经常会遇到各种各样的网络问题。 按照著名的 80/20 定律,
剩下的 20% 就无法快速定位并解决,需要一些额外专业知识和时间来排查,例如,粗看一些相关代码,把可疑点提交到社区或邮件列表讨论等等;所花时间在几个小时到几天不等。
如果对这 20% 再用一次 80/20 定律,那这 20% 里面,
如果你愿意,还可以再用 80/20 法则继续分下去,第三次剩下的将是 0.8% —— 这个长尾 已经足够小了,但解决这些问题花费的时间一般也足够长。 对于这一部分(性能)问题,我们必须系统地学习整个网络栈,理解数据包从到达 网卡之后分别经过哪些模块、进行什么处理,一直到最终被应用程序收起的整个过程,没 有其他捷径,除非你们的业务方能忍受这份长尾,或者通过工程手段绕过这些问题, 例如最简单的加机器降负载。但在云原生时代、网络可编程的今天,功能需求也同样要求我们具备 内核网络栈这一领域知识。例如,K8s 是采用了非常灵活的 spec & impl 设计,它以契约规范的方式描述了很多 k8s 的功能应该是什么样,而具体实现则交给开发者或厂商,网络相关的两个例子:
如果让你来实现这两个方案(demo),你觉得需要哪些网络知识?需要熟悉网络栈的哪些模块和子系统?熟悉到什么程度?
两篇参考:
有了对内核网络的完整理解,就会发现一片新天地,对于前面那若干层 “80” 问题,也会有完全不一样的认识。
早年的 Linux 网络栈监控和调优:接收数据(2016) 因为很多原因在今天的参考价值越来越小:
3.13,1Gbps 网卡驱动 igb),尤其对容器和网络虚拟化团队,这种配置都是古董机了:本文参考了那篇文章的主线,基于新内核重新整理了整个网络栈处理过程和一些监控调优选项,
mlx5_core 驱动;本文写的是 “Linux networking stack”,这里的 “stack” 指的不仅仅是内核协议栈, 而是包括内核协议栈在内的、从数据包到达物理网卡到最终被用户态程序收起的整个路径, 如下图所示(接收数据路径和步骤):
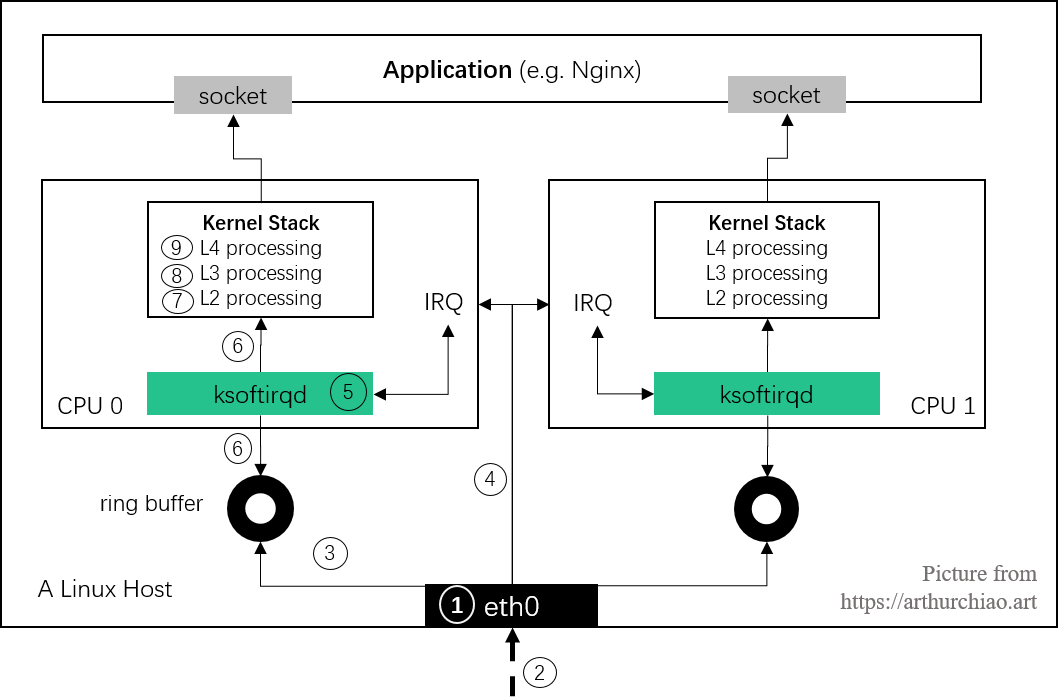
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
本文还有很多地方不完善,可能还有一些错误,仅作学习参考,后续会不定期更新。