http://arthurchiao.art/blog/linux-net-stack-implementation-rx-zh/复制
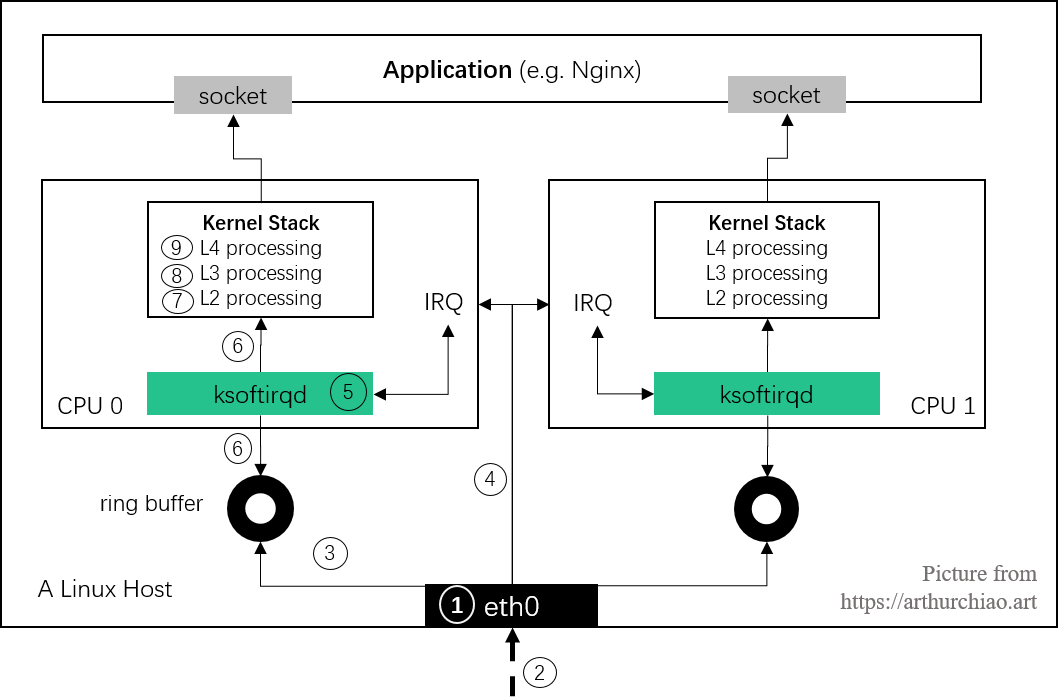
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
本文尝试从技术研发与工程实践(而非纯理论学习)角度,在原理与实现、监控告警、 配置调优三方面介绍内核5.10 网络栈。由于内容非常多,因此分为了几篇系列文章。
原理与实现
监控
调优
ksoftirqd 线程
udp_v4_early_demux()/udp_v4_rcv()udp_rcv() -> __udp4_lib_rcv()__udp4_lib_rcv() -> udp_unicast_rcv_skb()udp_unicast_rcv_skb() -> udp_queue_rcv_skb()udp_queue_rcv_skb() -> udp_queue_rcv_one_skb() -> __udp_queue_rcv_skb()__udp_queue_rcv_skb() -> __skb_queue_tail() -> socket's receive queue从比较高的层次看,一个数据包从被网卡接收到进入 socket 的整个过程如下:
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
poll() 方法;ksoftirqd:poll() 从 ring buffer 收包,并以 skb 的形式送至更上层处理;本文分 9 个章节来介绍图中内核接收及处理数据的全过程。
网卡成功完成初始化之后,数据包通过网线到达网卡时,才能被正确地收起来送到更上层去处理。 因此,我们的工作必须从网卡初始化开始,更准确地说,就是网卡驱动模块的初始化。 这一过程虽然是厂商相关的,但是非常重要;弄清楚了网卡驱动的工作原理, 才能对后面的部分有更加清晰的认识和理解。
网卡驱动一般都是作为独立的内核模块(kernel module)维护的,本文 将拿 mlx5_core 驱动作为例子,它是如今常见的 Mellanox ConnectX-4/ConnectX-5 25Gbps/40Gbps 以太网卡的驱动。
目前主流的网卡驱动都是以太网驱动,例如最常见的 Intel 系列:
i 是 intel,gb 表示(每秒 1)Gbx 是罗马数字 10,所以 xgb 表示 10Gb,e 表示以太网intel 40Gbps 以太网mlx5_core 这个驱动有点特殊,它支持以太网驱动,但由于历史原因,它的实现与普通以太网驱动有很大不同: Mellanox 是做高性能传输起家的(2019 年被 NVIDIA 收购),早起产品是 InfiniBand, 这是一个平行于以太网的二层传输和互联方案:
Fig. Different L2 protocols for interconnecting in the industry (with Ethernet as the dominant one)
Infiniband 在高性能计算、RDMA 网络中应用广泛,但毕竟市场还是太小了,所以 后来 Mellanox 又对它的网卡添加了以太网支持。表现在驱动代码上,就是会看到它有一些 特定的术语、变量和函数命名、模块组织等等,读起来比 ixgbe 这样原生的以太网驱动要累一些。 这里列一些,方便后面看代码:
接下来看下一个具体 Mellanox 网卡的硬件相关信息:
$ lspci -vvv | grep Mellanox -A 50
d8:00.0 Ethernet controller: Mellanox Technologies MT27710 Family [ConnectX-4 Lx]
Subsystem: Mellanox ... ConnectX-4 Lx EN, 25GbE dual-port SFP28, PCIe3.0 x8, MCX4121A-ACAT
Interrupt: pin A routed to IRQ 114
Capabilities: [9c] MSI-X: Enable+ Count=64 Masked-
Vector table: BAR=0 offset=00002000
PBA: BAR=0 offset=00003000
Capabilities: [180 v1] Single Root I/O Virtualization (SR-IOV)
...
Initial VFs: 8, Total VFs: 8, Number of VFs: 0, Function Dependency Link: 00
...
Kernel driver in use: mlx5_core
Kernel modules: mlx5_core
复制其中的一些关键信息:
ConnectX-4;25Gbps 以太网卡;双接口,也就是在系统中能看到 eth0 和 eth1 两个网卡;PCIe3.0 x8;IRQ 114, MSI-X;mlx5_core,对应的内核内核模块是 mlx5_core。可以看到现在用的驱动叫 mlx5_core,接下来就来看它的实现,代码位于 drivers/net/ethernet/mellanox/mlx5/core。
module_init() -> init() -> pci/mlx5e init首先看内核启动时,驱动的注册和初始化过程。非常简单直接, module_init() 注册一个初始化函数,内核加载驱动执行:
// https://github.com/torvalds/linux/blob/v5.10/drivers/net/ethernet/mellanox/mlx5/core/main.c
static int __init init(void) {
mlx5_fpga_ipsec_build_fs_cmds();
mlx5_register_debugfs(); // /sys/kernel/debug
pci_register_driver(&mlx5_core_driver); // 初始化 PCI 相关的东西
mlx5e_init(); // 初始化 ethernet 相关东西
}
module_init(init);
复制初始化的大部分工作在 pci_register_driver() 和 mlx5e_init() 里面完成。
pci_register_driver()前面 lspci 可以看到这个网卡是 PCI express 设备, 这种设备设备通过 PCI Configuration Space 识别。当设备驱动编译时,MODULE_DEVICE_TABLE 宏会导出一个 global 的 PCI 设备 ID 列表, 驱动据此识别它可以控制哪些设备,这样内核就能对各设备加载正确的驱动:
// https://github.com/torvalds/linux/blob/v5.10/include/linux/module.h
#ifdef MODULE
/* Creates an alias so file2alias.c can find device table. */
#define MODULE_DEVICE_TABLE(type, name) \
extern typeof(name) __mod_##type##__##name##_device_table __attribute__ ((unused, alias(__stringify(name))))
#else /* !MODULE */
#define MODULE_DEVICE_TABLE(type, name)
#endif
复制mlx5_core 驱动的设备表和 PCI 设备 ID:
// https://github.com/torvalds/linux/blob/v5.10/drivers/net/ethernet/mellanox/mlx5/core/main.c
static const struct pci_device_id mlx5_core_pci_table[] = {
{ PCI_VDEVICE(MELLANOX, PCI_DEVICE_ID_MELLANOX_CONNECTIB) },
{ PCI_VDEVICE(MELLANOX, 0x1012), MLX5_PCI_DEV_IS_VF}, /* Connect-IB VF */
{ PCI_VDEVICE(MELLANOX, PCI_DEVICE_ID_MELLANOX_CONNECTX4) },
{ PCI_VDEVICE(MELLANOX, 0x1014), MLX5_PCI_DEV_IS_VF}, /* ConnectX-4 VF */
{ PCI_VDEVICE(MELLANOX, PCI_DEVICE_ID_MELLANOX_CONNECTX4_LX) },
{ PCI_VDEVICE(MELLANOX, 0x1016), MLX5_PCI_DEV_IS_VF}, /* ConnectX-4LX VF */
{ PCI_VDEVICE(MELLANOX, 0x1017) }, /* ConnectX-5, PCIe 3.0 */
{ PCI_VDEVICE(MELLANOX, 0x1018), MLX5_PCI_DEV_IS_VF}, /* ConnectX-5 VF */
{ PCI_VDEVICE(MELLANOX, 0x1019) }, /* ConnectX-5 Ex */
{ PCI_VDEVICE(MELLANOX, 0x101a), MLX5_PCI_DEV_IS_VF}, /* ConnectX-5 Ex VF */
{ PCI_VDEVICE(MELLANOX, 0x101b) }, /* ConnectX-6 */
{ PCI_VDEVICE(MELLANOX, 0x101c), MLX5_PCI_DEV_IS_VF}, /* ConnectX-6 VF */
{ PCI_VDEVICE(MELLANOX, 0x101d) }, /* ConnectX-6 Dx */
{ PCI_VDEVICE(MELLANOX, 0x101e), MLX5_PCI_DEV_IS_VF}, /* ConnectX Family mlx5Gen Virtual Function */
{ PCI_VDEVICE(MELLANOX, 0x101f) }, /* ConnectX-6 LX */
{ PCI_VDEVICE(MELLANOX, 0x1021) }, /* ConnectX-7 */
{ PCI_VDEVICE(MELLANOX, 0xa2d2) }, /* BlueField integrated ConnectX-5 network controller */
{ PCI_VDEVICE(MELLANOX, 0xa2d3), MLX5_PCI_DEV_IS_VF}, /* BlueField integrated ConnectX-5 network controller VF */
{ PCI_VDEVICE(MELLANOX, 0xa2d6) }, /* BlueField-2 integrated ConnectX-6 Dx network controller */
{ 0, }
};
MODULE_DEVICE_TABLE(pci, mlx5_core_pci_table);
复制pci_register_driver() 会将该驱动的各种回调方法注册到一个 struct pci_driver mlx5_core_driver 变量,
// https://github.com/torvalds/linux/blob/v5.10/drivers/net/ethernet/mellanox/mlx5/core/main.c
static struct pci_driver mlx5_core_driver = {
.name = DRIVER_NAME,
.id_table = mlx5_core_pci_table,
.probe = init_one, // 初始化时执行这个方法
.remove = remove_one,
.suspend = mlx5_suspend,
.resume = mlx5_resume,
.shutdown = shutdown,
.err_handler = &mlx5_err_handler,
.sriov_configure = mlx5_core_sriov_configure,
};
复制更详细的 PCI 驱动信息不在本文讨论范围,如想进一步了解,可参考 分享, wiki, Linux Kernel Documentation: PCI。
pci_driver->probe()内核启动过程中,会通过 PCI ID 依次识别各 PCI 设备,然后为设备选择合适的驱动。 每个 PCI 驱动都注册了一个 probe() 方法,为设备寻找驱动就是调用其 probe() 方法。 probe() 做的事情因厂商和设备而已,但总体来说这个过程涉及到的东西都非常多, 最终目标也都是使设备 ready。典型过程包括:
来看下 mlx5_core 驱动的 probe() 包含哪些过程:
// https://github.com/torvalds/linux/blob/v5.10/drivers/net/ethernet/mellanox/mlx5/core/main.c
static int init_one(struct pci_dev *pdev, const struct pci_device_id *id) {
struct devlink *devlink = mlx5_devlink_alloc(); // 内核通用结构体,包含 netns 等信息
struct mlx5_core_dev *dev = devlink_priv(devlink); // 私有数据区域存储的是 mlx5 自己的 device 表示
dev->device = &pdev->dev;
dev->pdev = pdev;
mlx5_mdev_init(dev, prof_sel); // 初始化 mlx5 debugfs 目录
mlx5_pci_init(dev, pdev, id); // 初始化 IO/DMA/Capabilities 等功能
mlx5_load_one(dev, true); // 初始化 IRQ 等
request_module_nowait(MLX5_IB_MOD);
pci_save_state(pdev);
if (!mlx5_core_is_mp_slave(dev))
devlink_reload_enable(devlink);
}
复制第一行创建 devlink 时,可以声明一段私有空间大小(封装在函数里面),里面放什么数 据完全由这个 devlink 的 owner 来决定;在 Mellanox 驱动中,这段空间的大小是 sizeof(struct mlx5_core_dev),存放具体的 device 信息,所以第二行 devlink_priv() 拿到的就是 device 指针。
.probe()
|-init_one(struct pci_dev *pdev, pci_device_id id)
|-mlx5_devlink_alloc()
| |-devlink_alloc(ops) // net/core/devlink.c
| |-devlink = kzalloc()
| |-devlink->ops = ops
| |-return devlink
|
|-mlx5_mdev_init(dev, prof_sel)
| |-debugfs_create_dir
| |-mlx5_pagealloc_init(dev)
| |-create_singlethread_workqueue("mlx5_page_allocator")
| |-alloc_ordered_workqueue
| |-alloc_workqueue // kernel/workqueue.c
|
|-mlx5_pci_init(dev, pdev, id);
| |-mlx5_pci_enable_device(dev);
| |-request_bar(pdev); // Reserve PCI I/O and memory resources
| |-pci_set_master(pdev); // Enables bus-mastering on the device
| |-set_dma_caps(pdev); // setting DMA capabilities mask, set max_seg <= 1GB
| |-dev->iseg = ioremap()
|
|-mlx5_load_one(dev, true);
| |-if interface already STATE_UP
| | return
| |
| |-dev->state = STATE_UP
| |-mlx5_function_setup // Init firmware functions
| |-if boot:
| | mlx5_init_once
| | |-mlx5_irq_table_init // Allocate IRQ table memory
| | |-mlx5_eq_table_init // events queue
| | |-dev->vxlan = mlx5_vxlan_create
| | |-dev->geneve = mlx5_geneve_create
| | |-mlx5_sriov_init
| | else:
| | mlx5_attach_device
| |-mlx5_load
| | |-mlx5_irq_table_create // 初始化硬中断
| | | |-pci_alloc_irq_vectors(MLX5_IRQ_VEC_COMP_BASE + 1, PCI_IRQ_MSIX);
| | | |-request_irqs
| | | for i in vectors:
| | | request_irq(irqn, mlx5_irq_int_handler) // 注册中断处理函数
| | |-mlx5_eq_table_create // 初始化事件队列(EventQueue)
| | |-create_comp_eqs(dev) // Completion EQ
| | for ncomp_eqs:
| | eq->irq_nb.notifier_call = mlx5_eq_comp_int;
| | create_map_eq()
| | mlx5_eq_enable()
| |-set_bit(MLX5_INTERFACE_STATE_UP, &dev->intf_state);
|
|-pci_save_state(pdev);
|
|-if (!mlx5_core_is_mp_slave(dev))
devlink_reload_enable(devlink);
复制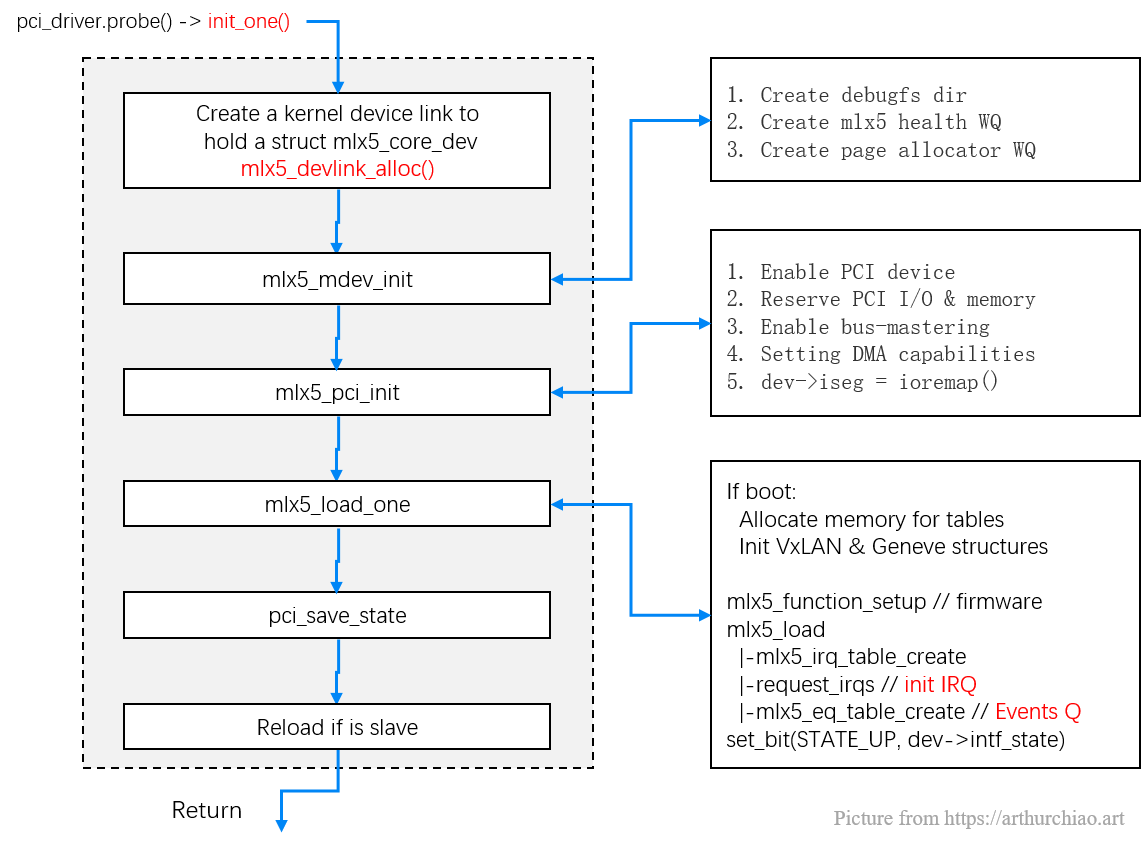
Fig. PCI probe during device initialization
devlink:mlx5_devlink_alloc()struct devlink 是个通用内核结构体:
// include/net/devlink.h
struct devlink {
struct list_head list;
struct list_head port_list;
struct list_head sb_list;
struct list_head dpipe_table_list;
struct list_head resource_list;
struct list_head param_list;
struct list_head region_list;
struct list_head reporter_list;
struct mutex reporters_lock; /* protects reporter_list */
struct devlink_dpipe_headers *dpipe_headers;
struct list_head trap_list;
struct list_head trap_group_list;
struct list_head trap_policer_list;
const struct devlink_ops *ops;
struct xarray snapshot_ids;
struct devlink_dev_stats stats;
struct device *dev;
possible_net_t _net; // netns 相关
u8 reload_failed:1,
reload_enabled:1,
registered:1;
char priv[0] __aligned(NETDEV_ALIGN);
};
复制mlx5_devlink_alloc() 注册一些硬件特性相关的方法,例如 reload、info_get 等:
// drivers/net/ethernet/mellanox/mlx5/core/devlink.c
struct devlink *mlx5_devlink_alloc(void) {
return devlink_alloc(&mlx5_devlink_ops, sizeof(struct mlx5_core_dev));
}
static const struct devlink_ops mlx5_devlink_ops = {
.flash_update = mlx5_devlink_flash_update,
.info_get = mlx5_devlink_info_get,
.reload_actions = BIT(DEVLINK_RELOAD_ACTION_DRIVER_REINIT) | BIT(DEVLINK_RELOAD_ACTION_FW_ACTIVATE),
.reload_limits = BIT(DEVLINK_RELOAD_LIMIT_NO_RESET),
.reload_down = mlx5_devlink_reload_down,
.reload_up = mlx5_devlink_reload_up,
};
复制mlx5_mdev_init()这里面会初始化 debugfs 目录:/sys/kernel/debug/mlx5/
$ tree -L 2 /sys/kernel/debug/mlx5/
/sys/kernel/debug/mlx5/
├── 0000:12:00.0
│ ├── cc_params
│ ├── cmd
│ ├── commands
│ ├── CQs
│ ├── delay_drop
│ ├── EQs
│ ├── mr_cache
│ └── QPs
└── 0000:12:00.1
├── cc_params
├── cmd
├── commands
├── CQs
├── delay_drop
├── EQs
├── mr_cache
└── QPs
复制里面的信息非常多,可以 cat 其中一些文件来帮助排障。
另外就是初始化一些 WQ。Workqueue (WQ) 也是一个内核通用结构体,更多信息,见 Linux 中断(IRQ/softirq)基础:原理及内核实现。
mlx5_pci_init()static int
mlx5_pci_init(struct mlx5_core_dev *dev, struct pci_dev *pdev, const struct pci_device_id *id) {
mlx5_pci_enable_device(dev);
request_bar(pdev); // Reserve PCI I/O and memory resources
pci_set_master(pdev); // Enables bus-mastering on the device
set_dma_caps(pdev); // setting DMA capabilities mask, set max_seg <= 1GB
dev->iseg = ioremap(dev->iseg_base, sizeof(*dev->iseg)); // mapping initialization segment
mlx5_pci_vsc_init(dev);
dev->caps.embedded_cpu = mlx5_read_embedded_cpu(dev);
return 0;
}
复制mlx5_load_one()int mlx5_load_one(struct mlx5_core_dev *dev, bool boot) {
dev->state = MLX5_DEVICE_STATE_UP;
mlx5_function_setup(dev, boot);
if (boot) {
mlx5_init_once(dev);
}
mlx5_load(dev);
set_bit(MLX5_INTERFACE_STATE_UP, &dev->intf_state);
if (boot) {
mlx5_devlink_register(priv_to_devlink(dev), dev->device);
mlx5_register_device(dev);
} else {
mlx5_attach_device(dev);
}
}
复制这里会初始化硬件中断,
| |-mlx5_load
| | |-mlx5_irq_table_create // 初始化硬中断
| | | |-pci_alloc_irq_vectors(MLX5_IRQ_VEC_COMP_BASE + 1, PCI_IRQ_MSIX);
| | | |-request_irqs
| | | for i in vectors:
| | | request_irq(irqn, mlx5_irq_int_handler) // 注册中断处理函数
| | |-mlx5_eq_table_create // 初始化事件队列(EventQueue)
| | |-create_comp_eqs(dev) // Completion EQ
| | for ncomp_eqs:
| | eq->irq_nb.notifier_call = mlx5_eq_comp_int;
| | create_map_eq()
| | mlx5_eq_enable()
复制使用的中断方式是 MSI-X。 当一个数据帧通过 DMA 写到内核内存 ringbuffer 后,网卡通过硬件中断(IRQ)通知其他系统。 设备有多种方式触发一个中断:
设备驱动的实现也因此而异。驱动必须判断出设备支持哪种中断方式,然后注册相应的中断处理函数,这些函数在中断发 生的时候会被执行。
irqbalance 方式,或者修改/proc/irq/IRQ_NUMBER/smp_affinity)。后面会看到 ,处理中断的 CPU 也是随后处理这个包的 CPU。这样的话,从网卡硬件中断的层面就可 以设置让收到的包被不同的 CPU 处理。mlx5e_init()PCI 功能初始化成功后,接下来执行以太网相关功能的初始化。
// en_main.c
void mlx5e_init(void) {
mlx5e_ipsec_build_inverse_table();
mlx5e_build_ptys2ethtool_map();
mlx5_register_interface(&mlx5e_interface);
}
static struct mlx5_interface mlx5e_interface = {
.add = mlx5e_add,
.remove = mlx5e_remove,
.attach = mlx5e_attach,
.detach = mlx5e_detach,
.protocol = MLX5_INTERFACE_PROTOCOL_ETH, // 接口运行以太网协议
};
复制mlx5e_nic
|-mlx5e_ipsec_build_inverse_table();
|-mlx5e_build_ptys2ethtool_map();
|-mlx5_register_interface(&mlx5e_interface)
|-list_add_tail(&intf->list, &intf_list);
|
|-for priv in mlx5_dev_list
mlx5_add_device(intf, priv)
/
/
mlx5_add_device(intf, priv)
|-if !mlx5_lag_intf_add
| return // if running in InfiniBand mode, directly return
|
|-dev_ctx = kzalloc()
|-dev_ctx->context = intf->add(dev)
|-mlx5e_add
|-netdev = mlx5e_create_netdev(mdev, &mlx5e_nic_profile, nch);
| |-mlx5e_nic_init
| |-mlx5e_build_nic_netdev(netdev);
| |-netdev->netdev_ops = &mlx5e_netdev_ops; // 注册 ethtool_ops, poll
|-mlx5e_attach
| |-mlx5e_attach_netdev
| |-profile->init_tx()
| |-profile->init_rx()
| |-profile->enable()
| |-mlx5e_nic_enable
| |-mlx5e_init_l2_addr
| |-queue_work(priv->wq, &priv->set_rx_mode_work)
| |-mlx5e_open(netdev);
| | |-mlx5e_open_locked
| | |-mlx5e_open_channels
| | | |-mlx5e_open_channel
| | | |-netif_napi_add(netdev, &c->napi, mlx5e_napi_poll, 64);
| | | |-mlx5e_open_queues
| | | |-mlx5e_open_cq
| | | | |-mlx5e_alloc_cq
| | | | |-mlx5e_alloc_cq_common
| | | | |-mcq->comp = mlx5e_completion_event;
| | | |-napi_enable(&c->napi)
| | |-mlx5e_activate_priv_channels
| | |-mlx5e_activate_channels
| | |-for ch in channels:
| | mlx5e_activate_channel
| | |-mlx5e_activate_rq
| | |-mlx5e_trigger_irq
| |-netif_device_attach(netdev);
复制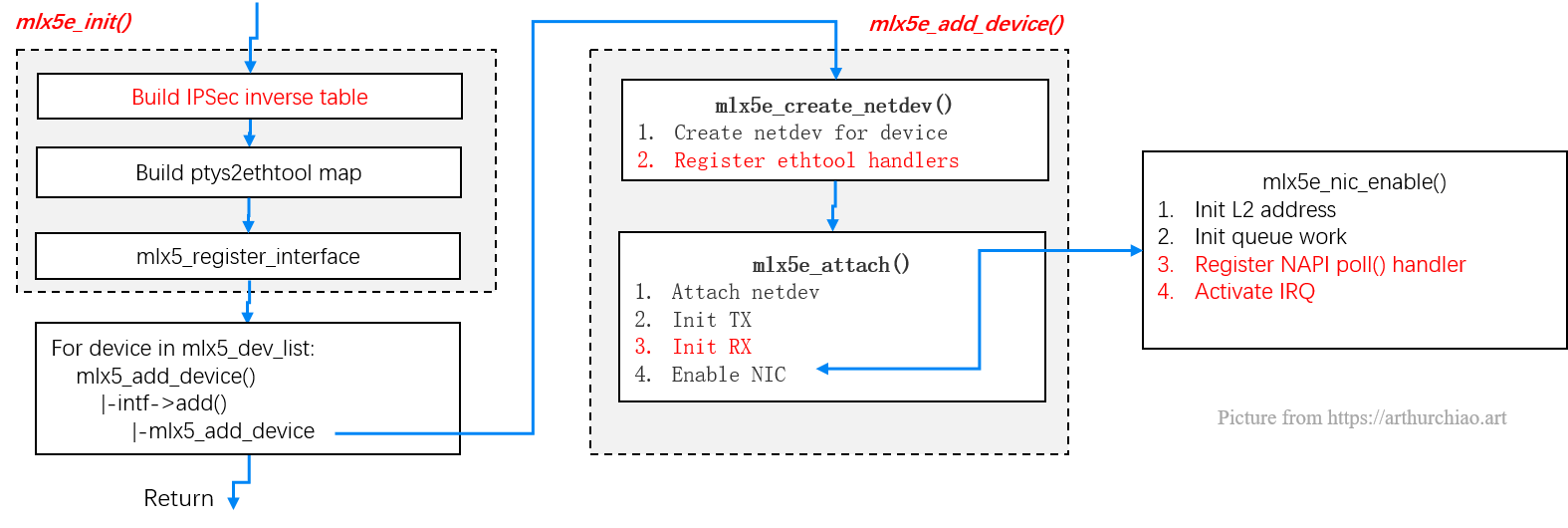
Fig. mlx5_core driver ethernet functions initialization
mlx5e_init() -> mlx5_register_interface() -> mlx5_add_device()// drivers/net/ethernet/mellanox/mlx5/core/dev.c
static LIST_HEAD(intf_list); // 全局 interface 双向链表
static LIST_HEAD(mlx5_dev_list); // 全局 mlx5 device 双向链表
int mlx5_register_interface(struct mlx5_interface *intf) {
list_add_tail(&intf->list, &intf_list);
list_for_each_entry(struct mlx5_priv *priv, &mlx5_dev_list, dev_list)
mlx5_add_device(intf, priv); // 如果网卡运行的是 InfiniBand 协议,里面会直接返回
}
复制mlx5/core/dev.c 中初始化了两个全局变量,分别表示全局的 interface 和 mlx5 device 链表;
struct mlx5_interface mlx5e_interface 是 Mellanox 的以太网接口方法;intf_list;遍历全局 Mellanox device 列表 mlx5_dev_list,调用 mlx5_add_device(intf, priv) 初始化每个网卡的以太网相关部分。其中包括,
static const struct mlx5e_profile mlx5e_nic_profile = {
.init = mlx5e_nic_init, // 网卡以太网相关内容初始化
.cleanup = mlx5e_nic_cleanup,
.init_rx = mlx5e_init_nic_rx, // 初始化接收队列(RX)
.cleanup_rx = mlx5e_cleanup_nic_rx,
.init_tx = mlx5e_init_nic_tx, // 初始化发送队列(TX)
.cleanup_tx = mlx5e_cleanup_nic_tx,
.enable = mlx5e_nic_enable, // 启用网卡时的回调
.disable = mlx5e_nic_disable,
.update_rx = mlx5e_update_nic_rx,
.update_stats = mlx5e_stats_update_ndo_stats,
.update_carrier = mlx5e_update_carrier,
.rx_handlers = &mlx5e_rx_handlers_nic, // 收包函数
.max_tc = MLX5E_MAX_NUM_TC,
.rq_groups = MLX5E_NUM_RQ_GROUPS(XSK),
.stats_grps = mlx5e_nic_stats_grps,
.stats_grps_num = mlx5e_nic_stats_grps_num,
};
复制mlx5_add_device() -> intf.add() -> mlx5e_add()mlx5e_create_netdev():创建 netdev、注册 ethtool 方法ethtool 是一个命令行工具,可以查看和修改网卡配置,常用于收集网卡统计数据。 内核实现了一个通用 ethtool 接口,网卡驱动只要实现这些接口,就可以使用 ethtool 来查看或修改网络配置; 在底层,它是通过 ioctl 和设备驱动通信的。
// drivers/net/ethernet/mellanox/mlx5/core/en_main.c
const struct net_device_ops mlx5e_netdev_ops = {
.ndo_open = mlx5e_open,
.ndo_stop = mlx5e_close,
.ndo_start_xmit = mlx5e_xmit,
.ndo_setup_tc = mlx5e_setup_tc,
.ndo_select_queue = mlx5e_select_queue,
.ndo_get_stats64 = mlx5e_get_stats,
.ndo_set_rx_mode = mlx5e_set_rx_mode,
.ndo_set_mac_address = mlx5e_set_mac,
.ndo_vlan_rx_add_vid = mlx5e_vlan_rx_add_vid,
.ndo_vlan_rx_kill_vid = mlx5e_vlan_rx_kill_vid,
.ndo_set_features = mlx5e_set_features,
.ndo_fix_features = mlx5e_fix_features,
.ndo_change_mtu = mlx5e_change_nic_mtu,
.ndo_do_ioctl = mlx5e_ioctl,
.ndo_set_tx_maxrate = mlx5e_set_tx_maxrate,
.ndo_udp_tunnel_add = udp_tunnel_nic_add_port,
.ndo_udp_tunnel_del = udp_tunnel_nic_del_port,
.ndo_features_check = mlx5e_features_check,
.ndo_tx_timeout = mlx5e_tx_timeout,
.ndo_bpf = mlx5e_xdp, // BPF
.ndo_xdp_xmit = mlx5e_xdp_xmit, // XDP
.ndo_xsk_wakeup = mlx5e_xsk_wakeup,
.ndo_get_devlink_port = mlx5e_get_devlink_port,
};
复制mlx5e_attach()今天的大部分网卡都使用 DMA 将数据直接写到内存,接下来操作系统可以直接从里 面读取。实现这一目的所使用的数据结构就是 ring buffer(环形缓冲区)。 要实现这一功能,设备驱动必须和操作系统合作,预留(reserve)出一段内存来给网卡 使用。预留成功后,网卡知道了这块内存的地址,接下来收到的包就会放到这里,进而被 操作系统取走。
static int mlx5e_init_nic_rx(struct mlx5e_priv *priv) {
struct mlx5_core_dev *mdev = priv->mdev;
mlx5e_create_q_counters(priv);
mlx5e_open_drop_rq(priv, &priv->drop_rq);
mlx5e_create_indirect_rqt(priv);
mlx5e_create_direct_rqts(priv, priv->direct_tir);
mlx5e_create_indirect_tirs(priv, true);
mlx5e_create_direct_tirs(priv, priv->direct_tir);
mlx5e_create_direct_rqts(priv, priv->xsk_tir);
mlx5e_create_direct_tirs(priv, priv->xsk_tir);
mlx5e_create_flow_steering(priv);
mlx5e_tc_nic_init(priv); // 初始化 TC offload 功能
mlx5e_accel_init_rx(priv); // 初始化 kTLS offload
#ifdef CONFIG_MLX5_EN_ARFS
priv->netdev->rx_cpu_rmap = mlx5_eq_table_get_rmap(priv->mdev);
#endif
复制以及 profile 中注册的 rx_handlers:
const struct mlx5e_rx_handlers mlx5e_rx_handlers_nic = {
.handle_rx_cqe = mlx5e_handle_rx_cqe,
.handle_rx_cqe_mpwqe = mlx5e_handle_rx_cqe_mpwrq,
};
复制查看一台真实机器的 queue 的数量:
$ ethtool -l eth0 # 能用 ethtool 看到这些信息,就是因为前面注册了 ethtool 的相应方法
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 40 # 最多支持 40 个
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 40 # 目前配置 40 个
复制每个 Queue 的 descriptor 数量(或称 queue depth):
$ ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 8192
RX Mini: 0
RX Jumbo: 0
TX: 8192
Current hardware settings:
RX: 1024
RX Mini: 0
RX Jumbo: 0
TX: 1024
复制Hash:
$ ethtool -x eth0
RX flow hash indirection table for eth0 with 40 RX ring(s):
0: 0 1 2 3 4 5 6 7
8: 8 9 10 11 12 13 14 15
16: 16 17 18 19 20 21 22 23
24: 24 25 26 27 28 29 30 31
32: 32 33 34 35 36 37 38 39
40: 0 1 2 3 4 5 6 7
48: 8 9 10 11 12 13 14 15
56: 16 17 18 19 20 21 22 23
64: 24 25 26 27 28 29 30 31
72: 32 33 34 35 36 37 38 39
80: 0 1 2 3 4 5 6 7
88: 8 9 10 11 12 13 14 15
96: 16 17 18 19 20 21 22 23
104: 24 25 26 27 28 29 30 31
112: 32 33 34 35 36 37 38 39
120: 0 1 2 3 4 5 6 7
RSS hash key:
9a:b0:e3:53:ed:d4:14:7a:a0:...:e5:57:e8:6a:ec
RSS hash function:
toeplitz: off
xor: on
crc32: off
复制内核有一种称为 NAPI(New API)的机制,允许网卡注册自己的 poll() 方法,执行这个方法就会从相应的网卡收包。 关于 NAPI 后面会有更详细介绍,这里只看一下注册时的调用栈:
mlx5e_open(netdev);
|-mlx5e_open_locked
|-mlx5e_open_channels
| |-mlx5e_open_channel
| |-netif_napi_add(netdev, &c->napi, mlx5e_napi_poll, 64); // 注册 NAPI
| |-mlx5e_open_queues
| |-mlx5e_open_cq
| | |-mlx5e_alloc_cq
| | |-mlx5e_alloc_cq_common
| | |-mcq->comp = mlx5e_completion_event;
| |-napi_enable(&c->napi) // 启用 NAPI
|-mlx5e_activate_priv_channels
|-mlx5e_activate_channels
|-for ch in channels:
mlx5e_activate_channel // 启用硬中断(IRQ)
|-mlx5e_activate_rq
|-mlx5e_trigger_irq
复制到这里,几乎所有的准备工作都就绪了,唯一剩下的就是打开硬中断, 等待数据包进来。
打开硬中断的方式因硬件而异,mxl5_core 驱动是在 mlx5e_trigger_irq() 中完成的。 调用栈见上面。
网卡启用后,驱动可能还会做一些额外的事情,例如启动定时器 或者其他硬件相关的设置。这些工作做完后,网卡就可以收包了。
从流程来说,网卡驱动初始化完成之后,我们就等着包从网卡上来了,也就是图中第 2 步:
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
这是物理层(L1)和数据链路层(L2)的行为,这里就不展开了。
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
数据从网线进入网卡,通过 DMA 直接写到 ring buffer(第 3 步),然后就该操作系统来收包了。
如果对其原理感兴趣,可以查看内核文档 DMA API HOWTO: Dynamic DMA mapping Guide。
在包从网卡到达应用层的过程中,会经历几次数据复制,这个对性能影响非常大,所以我们记录一下:
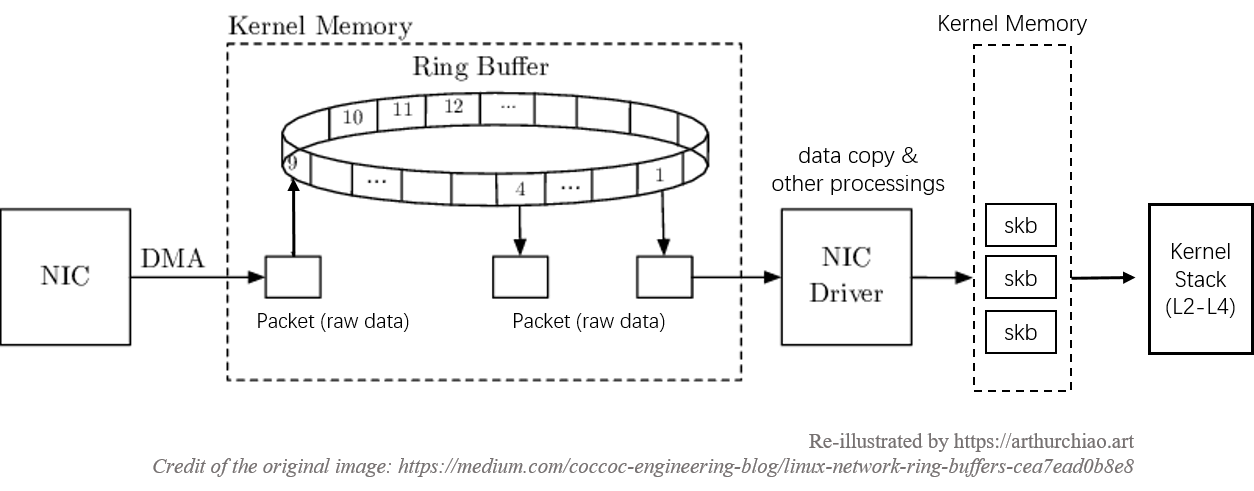
Fig. DMA, ring buffer and the data copy steps
这里需要停下来考虑一个问题:网卡是没有处理器的(近几年刚出现的所谓“ 智能网卡”除外,它们有自己独立的处理器、内存等等,可以与 CPU 并行处理),所以 如果到达网卡的数据没有进程或线程来处理,就只能被丢弃。那么,接下来谁来收这些包,怎么收这些包呢?
有两种方式,我们分别来看下。
Busy-polling(持续轮询):给网卡预留专门的 CPU 和线程,100% 用于收发包,典型的方式是 DPDK;
优点是延迟低,吞吐高,因为 CPU 100% 给网卡了;缺点:资源浪费、绕过了内核协 议栈(kernel bypass),但是业内没有一个足够公认和广泛使用的用户态协议栈,所 以这种方案主要用在纯 L3/L4 处理场景,例如网关(路由转发)、四层负载均 衡等等。
XDP 技术出来之后,DPDK 的优势逐渐消失,对 XDP 感兴趣可移步: XDP (eXpress Data Path):在操作系统内核中实现快速、可编程包处理(ACM,2018)。
硬件中断(IRQ)
在绝大部分场景下,预留专门的 CPU 用于收发包都是极大的资源浪费:简单来说, 只需要在网卡有包达到时,通知 CPU 来收即可;如果没有包,CPU 做别的事情去就可以了。 那么网卡怎么通知 CPU 呢?答案是通过硬件中断(IRQ),这是最高优先级的通知机制,告诉 CPU 必须马上得到处理。 这就是经典的中断方式。
它的优点是在普通场景下,CPU 能够得到合理利用,不会浪费在空跑(一直执行 poll 方法),缺点是在吞吐很高的场景 下,IRQ 所占的开销很高,这也是为什么在高吞吐场景下引入了 DPDK。
中断方式针对高吞吐场景的改进是 NAPI 方式,简单来说它结合了轮询和中断两种方式。 绝大部分网卡都是这种模式,本文所用的 mlx5_core 就属于这一类。
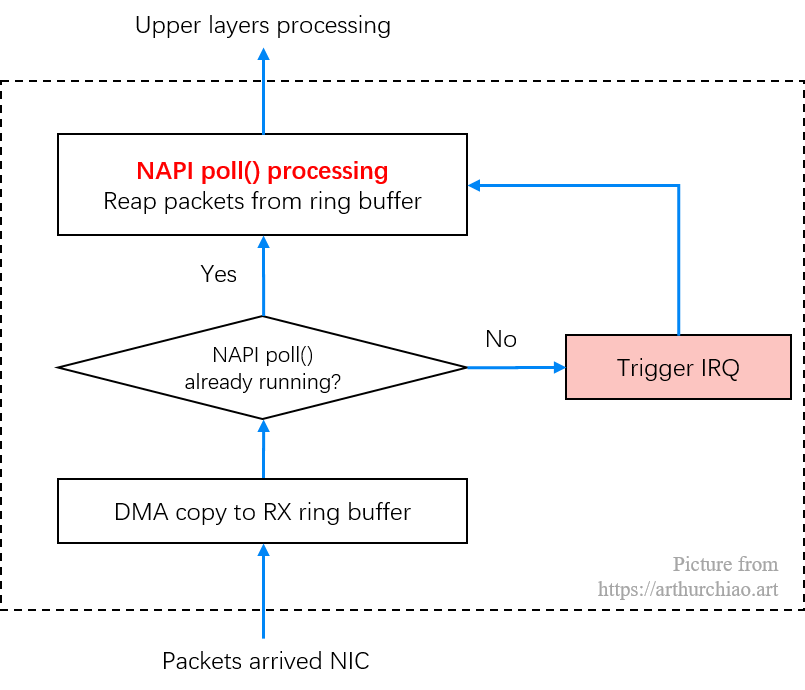
Fig. NAPI working mechanism: poll (batch receiving) + IRQ
简单来说,NAPI 结合了轮询和中断两种方式。
每次执行到 NAPI poll() 方法时,也就是会执行到网卡注册的 poll() 方法时,会批量从 ring buffer 收包;
在这个 poll 工作时,会尽量把所有待收的包都收完(budget 可以配置和调优);在此期间内新到达网卡的包,也不会再触发 IRQ;
不在这个调度周期内,收到的包会触发 IRQ,然后内核来启动 poll() 再收包;
此外还有 IRQ 合并技术,用于减少 IRQ 数量,提升整体吞吐。
假如此时 NAPI poll() 没有正在运行, 接下来我们看通过 IRQ 来通知 CPU(图中第 4 步)从 ring buffer 收包的。
DMA 将包复制到 ring buffer(内核内存)之后,网卡发起对应的中断(在 MSI-X 场景,中断和 RX 队列绑定)。 来个具体例子,下面是台 40 核的机器,
$ cat /proc/interrupts
CPU0 CPU1 ... CPU38 CPU39
0: 33 0 ... 0 0 IR-IO-APIC 2-edge timer
1: 0 0 ... 0 0 IR-IO-APIC 1-edge i8042
8: 0 0 ... 0 0 IR-IO-APIC 8-edge rtc0
9: 0 0 ... 0 0 IR-IO-APIC 9-fasteoi acpi
...
93: 0 0 ... 0 0 DMAR-MSI 1-edge dmar1
94: 0 0 ... 0 0 DMAR-MSI 0-edge dmar0
96: 68719 42920 ... 0 0 IR-PCI-MSI 9437189-edge mlx5_comp1@pci:0000:12:00.0
...
179: 5743 15415 ... 0 1 IR-PCI-MSI 9439275-edge mlx5_comp39@pci:0000:12:00.1
200: 0 0 ... 0 0 IR-PCI-MSI 67188736-edge ioat-msix
NMI: 8282 78282 ... 8281 8281 Non-maskable interrupts
PMI: 8282 78282 ... 8281 8281 Performance monitoring interrupts
IWI: 3768 86227 ... 3083 0136 IRQ work interrupts
CAL: 217210 245619 ... 425777 430686 Function call interrupts
复制其中的 mlx5_comp{id}@pci:xxx 就是我们网卡的中断处理函数, 它是在网卡初始化 IRQ 时生成的,后面会看到调用栈。
硬中断期间是不能再进行另外的硬中断的,也就是说不能嵌套。 所以硬中断处理函数(handler)执行时,会屏蔽部分或全部(新的)硬中断。
所以,所有耗时的操作都应该从硬中断处理逻辑中剥离出来, 硬中断因此能尽可能快地执行,然后再重新打开。软中断就是针对这一目的提出的。
内核中也有其他机制将耗时操作转移出去,不过对于网络栈,我们接下来只看软中断这种方式。
这个过程其实是在网卡驱动初始化(第一章)时完成的,但是第一章的内容太多了,所以我们放到这里看一下:
mlx5_load
|-mlx5_irq_table_create
| |-table->irq = kcalloc()
| |-pci_alloc_irq_vectors(dev->pdev, MLX5_IRQ_VEC_COMP_BASE + 1, nvec, PCI_IRQ_MSIX);
| |-request_irqs
| |-for i in vectors:
| irq = mlx5_irq_get(dev, i);
| irqn = pci_irq_vector(dev->pdev, i);
| irq_set_name(sprintf("mlx5_comp%d", vecidx-MLX5_IRQ_VEC_COMP_BASE), i);
| snprintf(irq->name, "%s@pci:%s", name, pci_name(dev->pdev));
| request_irq(irqn, mlx5_irq_int_handler, 0, irq->name, &irq->nh); // 注册中断处理函数
|
|-mlx5_eq_table_create // 初始化事件队列(EventQueue)
|-create_comp_eqs(dev) // Completion EQ
for ncomp_eqs:
eq->irq_nb.notifier_call = mlx5_eq_comp_int; // 每个 EQ 事件完成时的回调函数
create_map_eq()
mlx5_eq_enable()
复制mlx5_irq_int_handler(),irq->name,格式是 mlx5_comp{id}@pci:xxx,正是 cat /proc/interrupts 看到的最后一列;request_irq() 已经跳出了 mlx5_core 驱动,是通用内核代码,见 include/linux/interrupt.h。mlx5_eq_comp_int()注意是先注册 NAPI poll,再打开硬件中断; 硬中断先执行到网卡注册的 IRQ handler,在 handler 里面再触发 NET_RX_SOFTIRQ softirq。
mlx5_irq_int_handler()mlx5_irq_int_handler() 非常简单,
// drivers/net/ethernet/mellanox/mlx5/core/pci_irq.c
static irqreturn_t mlx5_irq_int_handler(int irq, void *nh) {
atomic_notifier_call_chain(nh, 0, NULL); // 内核函数,见 kernel/notifier.c
return IRQ_HANDLED;
}
复制然后中断事件就进入了 Mellanox 的完成队列(EQ),会执行 EQ 完成时的回调方法。
irq_nb.notifier_call() -> mlx5_eq_comp_int()// https://github.com/torvalds/linux/blob/v5.10/drivers/net/ethernet/mellanox/mlx5/core/eq.c
static int mlx5_eq_comp_int(struct notifier_block *nb) {
struct mlx5_eq_comp *eq_comp = container_of(nb, struct mlx5_eq_comp, irq_nb);
struct mlx5_eq *eq = &eq_comp->core;
u32 cqn = -1;
struct mlx5_eqe *eqe = next_eqe_sw(eq); // 从 event queue 拿出一个 entry
do {
dma_rmb(); // Make sure we read EQ entry contents after we've checked the ownership bit.
struct mlx5_core_cq *cq = mlx5_eq_cq_get(eq, cqn); // 获取 EQ completion queue
if (likely(cq)) {
++cq->arm_sn;
cq->comp(cq, eqe); // 执行 completion 方法,里面最主要的步骤是执行 napi_schedule()
mlx5_cq_put(cq); // refcnt--,释放空间
}
++eq->cons_index;
} while ((++num_eqes < MLX5_EQ_POLLING_BUDGET) && (eqe = next_eqe_sw(eq)));
eq_update_ci(eq, 1); // 更新一个硬件寄存器,记录 IRQ 频率
if (cqn != -1)
tasklet_schedule(&eq_comp->tasklet_ctx.task);
}
复制是个比较简单的循环,
获取 EQ 中的 CQ(完成队列);然后对 CQ 中的包执行 cq->comp() 方法,这里面最重要的步骤是执行 napi_schedule(),如果此时 NAPI poll 还没开始执行,就会唤醒它;
注意,这个处理循环是在软中断中执行的,而不是硬中断。
最后,更新一个硬件寄存器,记录硬件中断频率。 可以用ethtool 调整 IRQ 触发频率。
cq->comp() -> mlx5e_completion_event() -> napi_schedule()void mlx5e_completion_event(struct mlx5_core_cq *mcq, struct mlx5_eqe *eqe) {
struct mlx5e_cq *cq = container_of(mcq, struct mlx5e_cq, mcq);
napi_schedule(cq->napi);
cq->event_ctr++;
cq->channel->stats->events++;
}
复制napi_schedule() -> ____napi_schedule()接下来看从硬件中断中调用的 napi_schedule 是如何工作的。
注意,NAPI 存在的意义是无需硬件中断通知就可以接收网络数据。前面提到, NAPI 的轮询循环(poll loop)是受硬件中断触发而跑起来的。换句话说,NAPI 功能启用了 ,但是默认是没有工作的,直到第一个包到达的时候,网卡触发的一个硬件将它唤醒。后面 会看到,也还有其他的情况,NAPI 功能也会被关闭,直到下一个硬中断再次将它唤起。
napi_schedule 只是一个简单的封装,内层调用 __napi_schedule。
// https://github.com/torvalds/linux/blob/v5.10/net/core/dev.c
/**
* __napi_schedule - schedule for receive
* @n: entry to schedule
*
* The entry's receive function will be scheduled to run.
* Consider using __napi_schedule_irqoff() if hard irqs are masked.
*/
void __napi_schedule(struct napi_struct *n) {
unsigned long flags;
local_irq_save(flags);
____napi_schedule(this_cpu_ptr(&softnet_data), n);
local_irq_restore(flags);
}
复制获取对应这个 CPU 的 structure softnet_data 变量,作为参数传过去。
____napi_schedule() -> __raise_softirq_irqoff()// https://github.com/torvalds/linux/blob/v5.10/net/core/dev.c
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi) {
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ); // kernel/softirq.c
}
复制这段代码了做了两个重要的事情:
napi_struct 变量,添加到 poll list,后者 attach 到这个 CPU 上的 softnet_data__raise_softirq_irqoff 触发一个 NET_RX_SOFTIRQ 类型软中断。这会触发执行 net_rx_action(如果没有正在执行),后者是网络设备初始化的时候注册的(下一章会看到)。接下来会看到,软中断处理函数 net_rx_action 会调用 NAPI 的 poll 函数来收包。
注意到目前为止,我们从硬中断处理函数中转移到软中断处理函数的逻辑,都是使用的本 CPU 变量。
驱动的硬中断处理函数做的事情很少,但软中断将会在和硬中断相同的 CPU 上执行。这就 是为什么给每个 CPU 一个特定的硬中断非常重要:这个 CPU 不仅处理这个硬中断,而且通 过 NAPI 处理接下来的软中断来收包。
后面我们会看到,Receive Packet Steering 可以将软中断分给其他 CPU。
ksoftirqd 线程现在来到了图中第 5 步:
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
网络设备(netdev)的初始化在 net_dev_init(),在系统启动期间执行:
// net/core/dev.c
// Initialize the DEV module. At boot time this walks the device list and
// unhooks any devices that fail to initialise (normally hardware not
// present) and leaves us with a valid list of present and active devices.
static int __init net_dev_init(void) {
dev_proc_init(); // 注册 /proc/net/{dev,softnet_stat,ptytpe}
netdev_kobject_init();
INIT_LIST_HEAD(&ptype_all);
for (i = 0; i < PTYPE_HASH_SIZE; i++)
INIT_LIST_HEAD(&ptype_base[i]);
INIT_LIST_HEAD(&offload_base);
register_pernet_subsys(&netdev_net_ops);
// 针对每个 CPU,初始化各种接收队列(packet receive queues)
for_each_possible_cpu(i) {
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i);
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
skb_queue_head_init(&sd->xfrm_backlog);
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->cpu = i;
#endif
init_gro_hash(&sd->backlog); // GRO
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
}
dev_boot_phase = 0;
register_pernet_device(&loopback_net_ops)
register_pernet_device(&default_device_ops)
// 注册 RX/TX 软中断处理函数
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
cpuhp_setup_state_nocalls(CPUHP_NET_DEV_DEAD, "net/dev:dead", NULL, dev_cpu_dead);
}
复制/proc/net/{dev,softnet_data,ptype}dev_proc_init() 会注册 /proc/net/{dev,softnet_stat,ptytpe}:
$ cat /proc/net/dev # 网络设备收发统计
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
lo: 5354018267 34340262 0 0 0 0 0 0 5354018267 34340262 0 0 0 0 0 0
enp0s3: 58744000 428517 0 0 0 0 0 0 654185884 624670 0 0 0 0 0 0
$ cat /proc/net/softnet_stat # 网络设备收发、错误等详细信息
0212786d 00000000 00005674 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
$ cat /proc/net/ptype # 网络设备 RX 协议
Type Device Function
0800 ip_rcv
0806 arp_rcv
86dd ipv6_rcv
复制struct softnet_datanet_dev_init() 为每个 CPU 创建一个 struct softnet_data 变量。这个变量包含很多 重要信息:
net_dev_init 分别为接收和发送数据注册了一个软中断处理函数, 后面会看到网卡驱动的中断处理函数是如何触发 net_rx_action() 执行的。
内核的软中断系统是一种在硬中断处理上下文(驱动中)之外执行代码的机制。
可以把软中断系统想象成一系列内核线程(每个 CPU 一个), 这些线程执行针对不同事件注册的处理函数(handler)。
如果用过 top 命令,可能会注意到 ksoftirqd/0 这个内核线程,其表示这个软中断线程跑在 CPU 0 上。
内核子系统(比如网络)能通过 open_softirq() 注册软中断处理函数。
接下来会看到网络系统是如何注册它的处理函数的。
调度执行到某个特定线程的调用栈:
smpboot_thread_fn
|-while (1) {
set_current_state(TASK_INTERRUPTIBLE); // 设置当前 CPU 为可中断状态
if !thread_should_run { // 无 pending 的软中断
preempt_enable_no_resched();
schedule();
} else { // 有 pending 的软中断
__set_current_state(TASK_RUNNING);
preempt_enable();
thread_fn(td->cpu); // 如果此时执行的是 ksoftirqd 线程,
|-run_ksoftirqd // 那会执行 run_ksoftirqd() 回调函数
|-local_irq_disable(); // 关闭所在 CPU 的所有硬中断
|
|-if local_softirq_pending() {
| __do_softirq();
| local_irq_enable(); // 重新打开所在 CPU 的所有硬中断
| cond_resched(); // 将 CPU 交还给调度器
| return;
|-}
|
|-local_irq_enable(); // 重新打开所在 CPU 的所有硬中断
}
}
复制如果此时调度到的是 ksoftirqd 线程,那 thread_fn() 执行的就是 run_ksoftirqd()。
run_ksoftirqd()软中断对分担硬中断的工作量至关重要,因此软中断线程在内核启动的很早阶段就 spawn 出来了:
// https://github.com/torvalds/linux/blob/v5.10/kernel/softirq.c#L730
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run= ksoftirqd_should_run, // 调度到该线程是,判断能否执行
.thread_fn = run_ksoftirqd, // 调度到该线程时,执行的回调函数
.thread_comm = "ksoftirqd/%u", // 线程名字,ps -ef 最后一列可以看到
};
static __init int spawn_ksoftirqd(void) {
cpuhp_setup_state_nocalls(CPUHP_SOFTIRQ_DEAD, "softirq:dead", NULL, takeover_tasklets);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
}
early_initcall(spawn_ksoftirqd);
复制看到注册了两个回调函数: ksoftirqd_should_run() 和 run_ksoftirqd(), smpboot_thread_fn() 会调用这两个函数。
线程的命名格式是 ksoftirqd/%u,其中 %u 是该线程所在 CPU 的 ID,
$ ps -ef | grep softirq
root 10 2 0 00:11:57 [ksoftirqd/0]
root 10 2 0 00:11:57 [ksoftirqd/2]
复制smpboot_thread_fn() -> run_ksoftirqd()每个 CPU 上的调度器会调度执行不同的线程,例如处理 OOM 的线程、处理 swap 的线程,以及 我们的软中断处理线程。每个线程分配一定的时间片:
查看 CPU 利用率时,si 字段对应的就是 softirq 开销, 衡量(从硬中断转移过来的)软中断的 CPU 使用量:
$ top -n1 | head -n3
top - 18:14:05 up 86 days, 23:45, 2 users, load average: 5.01, 5.56, 6.26
Tasks: 969 total, 2 running, 733 sleeping, 0 stopped, 2 zombie
%Cpu(s): 13.9 us, 3.2 sy, 0.0 ni, 82.7 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
# ^
# |
# si: software interrupt overhead
复制代码:
// https://github.com/torvalds/linux/blob/v5.10/kernel/smpboot.c#L107
// smpboot_thread_fn - percpu hotplug thread loop function
// @data: thread data pointer
//
// Returns 1 when the thread should exit, 0 otherwise.
static int smpboot_thread_fn(void *data) {
struct smpboot_thread_data *td = data;
struct smp_hotplug_thread *ht = td->ht;
while (1) {
set_current_state(TASK_INTERRUPTIBLE); // 设置当前 CPU 为可中断状态
preempt_disable();
if (kthread_should_park()) {
...
continue; /* We might have been woken for stop */
}
switch (td->status) { /* Check for state change setup */
case HP_THREAD_NONE: ... continue;
case HP_THREAD_PARKED: ... continue;
}
if (!ht->thread_should_run(td->cpu)) { // 无 pending 的软中断
preempt_enable_no_resched();
schedule();
} else { // 有 pending 的软中断
__set_current_state(TASK_RUNNING);
preempt_enable();
ht->thread_fn(td->cpu); // 执行 `run_ksoftirqd()`
}
}
}
复制如果此时调度到的是 ksoftirqd 线程,并且有 pending 的软中断等待处理, 那 thread_fn() 执行的就是 run_ksoftirqd()。
run_ksoftirqd()// https://github.com/torvalds/linux/blob/v5.10/kernel/softirq.c#L730
static void run_ksoftirqd(unsigned int cpu) {
local_irq_disable(); // 关闭所在 CPU 的所有硬中断
if (local_softirq_pending()) {
// We can safely run softirq on inline stack, as we are not deep in the task stack here.
__do_softirq();
local_irq_enable(); // 重新打开所在 CPU 的所有硬中断
cond_resched(); // 将 CPU 交还给调度器
return;
}
local_irq_enable(); // 重新打开所在 CPU 的所有硬中断
}
复制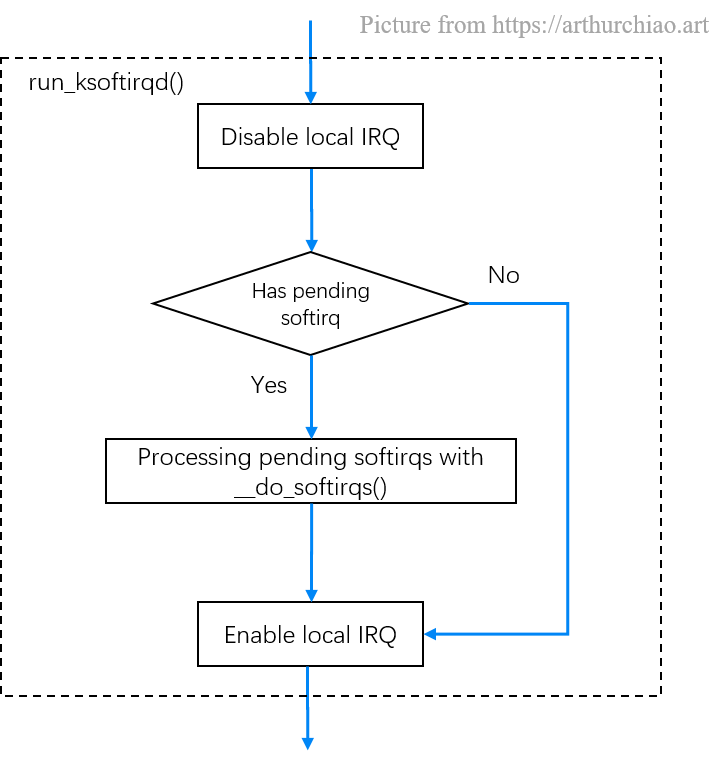
首先调用 local_irq_disable(),这是一个宏,最终会 展开成处理器架构相关的函数,功能是关闭所在 CPU 的所有硬中断;
接下来,判断如果有 pending softirq,则 执行 __do_softirq() 处理软中断,然后重新打开所在 CPU 的硬中断,然后返回;
否则直接打开所在 CPU 的硬中断,然后返回。
__do_softirq() -> net_rx_action()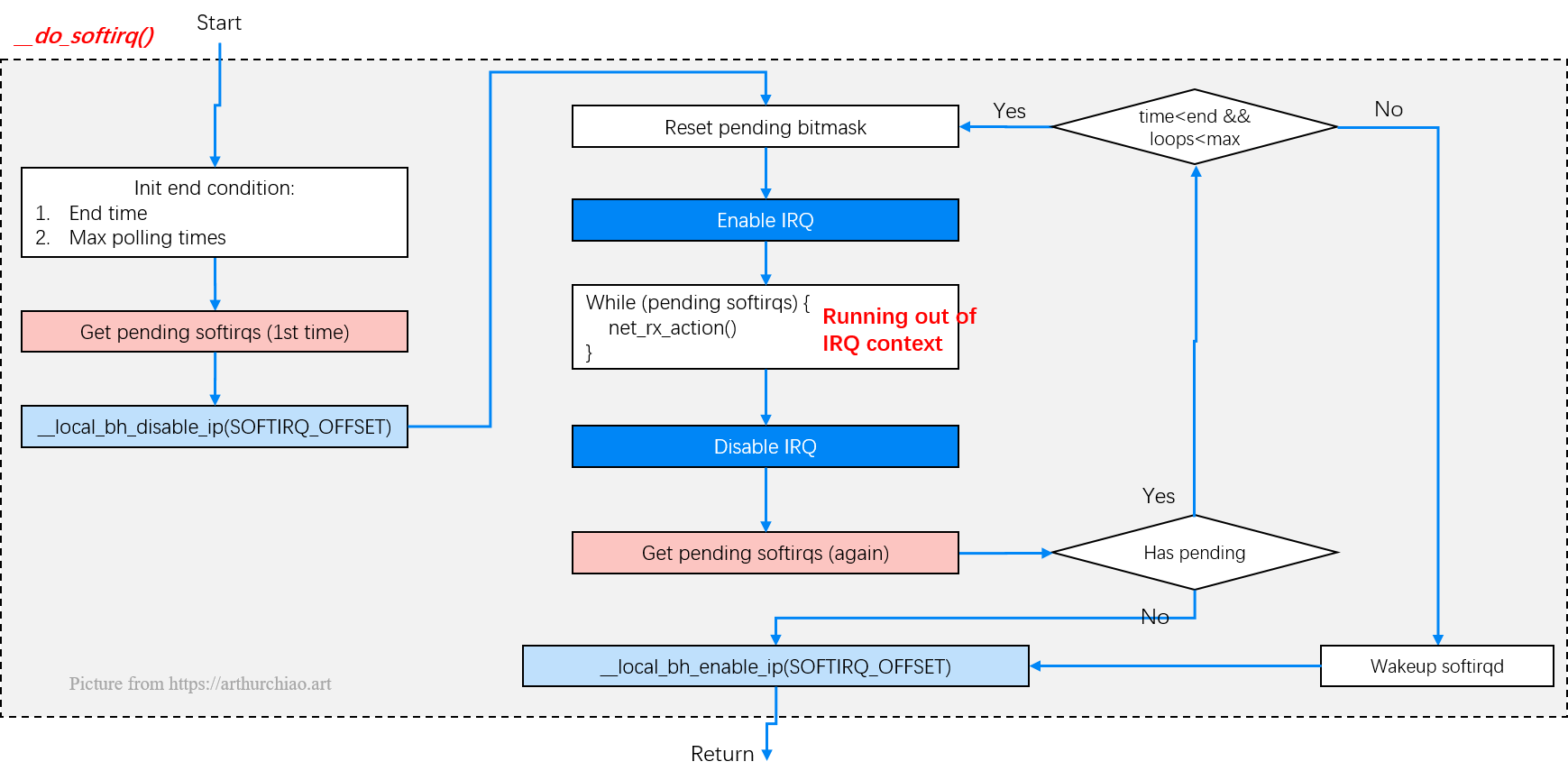
Fig. run_ksoftirqd()
// https://github.com/torvalds/linux/blob/v5.10/kernel/softirq.c#L730
asmlinkage __visible void __softirq_entry
__do_softirq(void) {
unsigned long end = jiffies + MAX_SOFTIRQ_TIME; // 时间片最晚结束时刻
unsigned long old_flags = current->flags;
int max_restart = MAX_SOFTIRQ_RESTART; // 最大轮询 pending softirq 次数
// Mask out PF_MEMALLOC as the current task context is borrowed for the softirq.
// A softirq handler, such as network RX, might set PF_MEMALLOC again if the socket is related to swapping.
current->flags &= ~PF_MEMALLOC;
pending = local_softirq_pending(); // 获取 pending softirq 数量
account_irq_enter_time(current);
__local_bh_disable_ip(_RET_IP_, SOFTIRQ_OFFSET);
in_hardirq = lockdep_softirq_start();
restart:
set_softirq_pending(0); // Reset the pending bitmask before enabling irqs
local_irq_enable(); // 打开 IRQ 中断
struct softirq_action *h = softirq_vec;
while ((softirq_bit = ffs(pending))) {
h += softirq_bit - 1;
unsigned int vec_nr = h - softirq_vec;
int prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(vec_nr);
h->action(h); // 指向 net_rx_action()
h++;
pending >>= softirq_bit;
}
if (__this_cpu_read(ksoftirqd) == current)
rcu_softirq_qs();
local_irq_disable(); // 关闭 IRQ
pending = local_softirq_pending(); // 再次获取 pending softirq 的数量
if (pending) {
if (time_before(jiffies, end) && !need_resched() && --max_restart)
goto restart;
wakeup_softirqd();
}
lockdep_softirq_end(in_hardirq);
account_irq_exit_time(current);
__local_bh_enable(SOFTIRQ_OFFSET);
current_restore_flags(old_flags, PF_MEMALLOC);
}
复制一旦软中断代码判断出有 softirq 处于 pending 状态,就会开始处理, 执行 net_rx_action,从 ring buffer 收包。
现在来到了图中第 6 步:
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
上一节看到,软中断线程 ksoftirqd 被处理器调度执行之后,会调用 net_rx_action() 方法。 这个函数的功能是 ring buffer 取出数据包,然后对其进行进入协议栈之前的大量处理。
net_rx_action() -> napi_poll():从 ring buffer 读数据Ring buffer 是内核内存,其中存放的包是网卡通过 DMA 直接送过来的, net_rx_action() 从处理 ring buffer 开始处理。
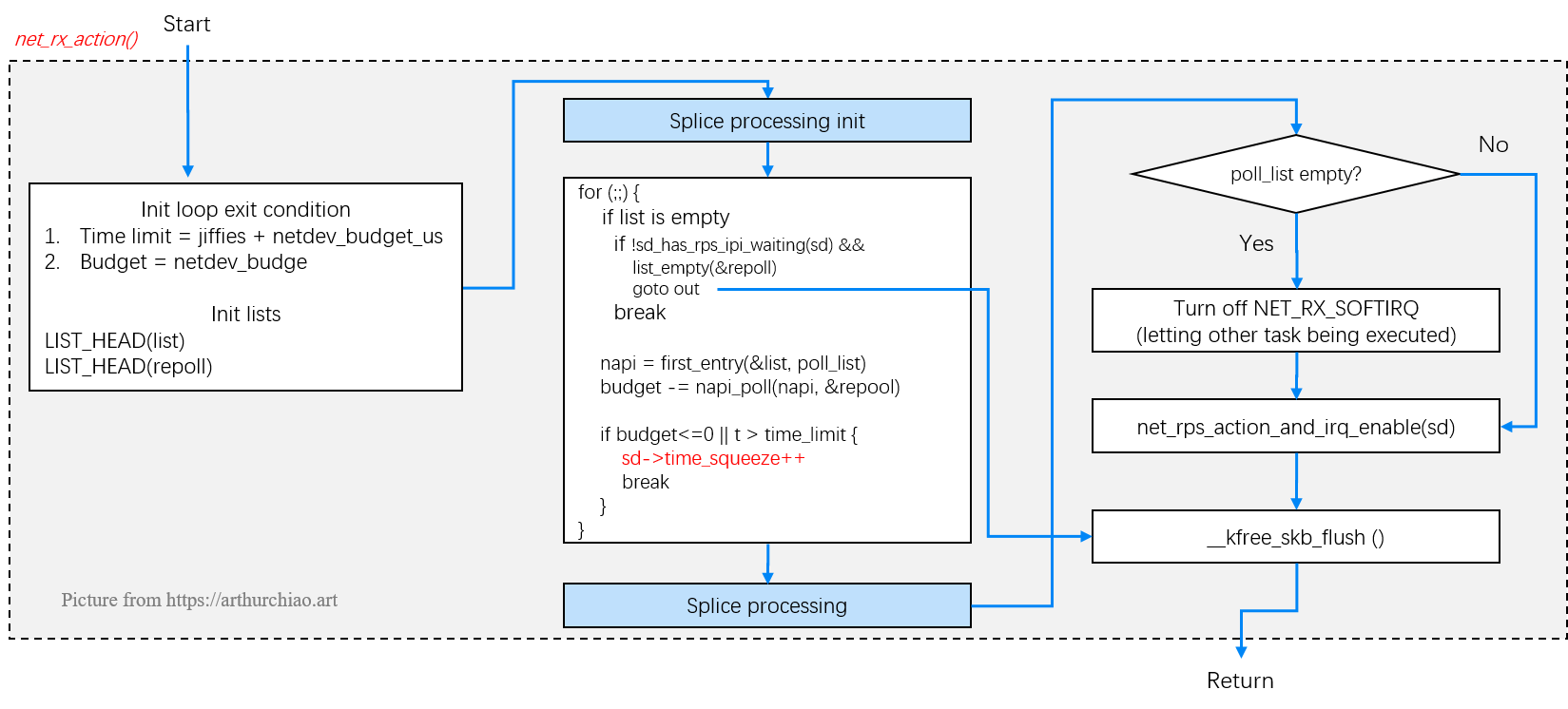
Fig. ksoftirqd: receiving packets from ring buffer with net_rx_action()
// net/core/dev.c
static __latent_entropy void
net_rx_action(struct softirq_action *h) {
struct softnet_data *sd = this_cpu_ptr(&softnet_data); // 改 CPU 的 softnet_data 统计
time_limit = jiffies + usecs_to_jiffies(netdev_budget_usecs); // 该 CPU 的所有 NAPI 变量的总 time limit
budget = netdev_budget; // 该 CPU 的所有 NAPI 变量的总预算
LIST_HEAD(list); // 声明 struct list_head list 变量并初始化;
LIST_HEAD(repoll); // 声明 struct list_head repoll 变量并初始化;
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
if list_empty(&list) {
if !sd_has_rps_ipi_waiting(sd) && list_empty(&repoll) // RPS 相关逻辑,IPI 进程间中断
goto out;
break;
}
struct napi_struct *n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll); // 执行网卡驱动注册的 poll() 方法,返回的是处理的数据帧数量,
// 函数返回时,那些数据帧都已经发送到上层栈进行处理了。
if (budget <= 0 || time_after_eq(jiffies, time_limit)) { // budget 或 time limit 用完了
sd->time_squeeze++; // 更新 softnet_data.time_squeeze 计数
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if !list_empty(&sd->poll_list) // 在给定的 time/budget 内,没有能够处理完全部 napi
__raise_softirq_irqoff(NET_RX_SOFTIRQ); // 关闭 NET_RX_SOFTIRQ 类型软中断,将 CPU 让给其他任务用,
// 主动让出 CPU,不要让这种 softirq 独占 CPU 太久。
// Receive Packet Steering:唤醒其他 CPU 从 ring buffer 收包。
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}
复制在给定的预算范围内,函数遍历当前 CPU 队列的 NAPI 变量列表,依次执行其 poll 方法。
有三种情况会退出循环:
list_empty(&list) == true:说明 list 已经为空,没有 NAPI 需要 poll 了(这个 list 是怎么初始化和更新的,需要好好研究);budget <= 0:说明收包的数量已经 >= netdev_budget(例如 2400 个,默认是 300), 或者time_after_eq(jiffies, time_limit) == true:说明累计运行时间已经 >= netdev_budget_us(例如 8ms,默认是 2ms)netdev_budget 和 netdev_budget_usecs这俩参数控制每次 softirq 线程的收包预算,
这两个预算限制中,任何一个达到后都将导致退出本次 softirq 处理。二者的默认值:
// net/core/dev.c
int netdev_budget __read_mostly = 300;
// Must be at least 2 jiffes to guarantee 1 jiffy timeout
unsigned int __read_mostly netdev_budget_usecs = 2 * USEC_PER_SEC / HZ; // 2000us
复制注意这些预算是每个 CPU 上所有 NAPI 实例共享的总预算。
另外,这两个变量都是 sysctl 配置项,可以按需调优:
$ sudo sysctl -a | grep netdev_budget
net.core.netdev_budget = 300 # 300 个包
net.core.netdev_budget_usecs = 2000 # 2ms
复制net_rx_action() 也体现出了内核是如何防止 softirq 收包过程霸占过多 CPU 的。 这也是多队列网卡应该精心调整 IRQ Affinity 的原因。
最终导致该 CPU 无法及时接收它负责的 RX 队列中的所有包。
如果没有足够的 CPU 来分散网卡硬中断,可以考虑增大以上两个 budget 配置项,使每个 CPU 能有更多的预算来处理收包,这会增加 CPU 使用量(top 等命令看到的 sitime 或 si 部分),但可以减少延迟,因为软中断收包更加及时。
time_squeeze 计数:ringbuffer 还有包,但 softirq 预算用完了 if (budget <= 0 || time_after_eq(jiffies, time_limit)) { // budget 或 time limit 用完了
sd->time_squeeze++; // 更新 softnet_data.time_squeeze 计数
break;
}
复制softnet_data.time_squeeze 字段记录的是满足如下条件的次数: ring buffer 中还有包等待接收,但本次 softirq 的 budget 已经用完了。 这对理解网络处理的瓶颈至关重要。
需要说明的是,time_squeeze 在 softnet_data 的所有字段中是非常特殊的一个:
xx_drop/xx_errors,会在多个地方更新,所以不能从计数增 加直接定位到是哪段代码或哪个逻辑导致的;另外,time_squeeze 升高并不一定表示系统有丢包,只是表示 softirq 的收包预算用完时,RX queue 中仍然有包等待处理。只要 RX queue 在下次 softirq 处理之前没有溢出,那就不会因为 time_squeeze 而导致丢包;但如果有持续且 大量的 time_squeeze,那确实有 RX queue 溢出导致丢包的可能,需要结合其他监控指标 来看。在这种情况下,调大 budget 参数是更合理的选择:与其让网卡频繁触发 IRQ->SoftIRQ 来收包,不如让 SoftIRQ 一次多执行一会,处理掉 RX queue 中尽量多的 包再返回,因为中断和线程切换开销也是很大的。
接下来重新回到主线,看一次 napi poll() 调用到网卡 handler 的具体过程。
napi_poll() -> mlx5e_napi_poll() -> mlx5e_poll_rx_cq()设备驱动在注册其 poll() 方法时,会传一个 weight 参数,在 Mellanox 中是 hardcode 64:
netif_napi_add(netdev, &c->napi, mlx5e_napi_poll, 64);
复制这个参数控制了网卡一次 poll() 时,最多允许处理的包数(下面会看到,变量名也叫 budget)。
$ sudo sysctl -a | grep dev_weight
net.core.dev_weight = 64
net.core.dev_weight_rx_bias = 1
net.core.dev_weight_tx_bias = 1
复制NAPI 子系统和设备驱动之间的就是否关闭 NAPI 有一份契约:
poll() 用完了它的全部 weight,那它不要更改 NAPI 状态。接下来 net_rx_action() 会做的;poll() 没有用完全部 weight,那它必须关闭 NAPI。下次有硬件 中断触发,驱动的硬件处理函数调用 napi_schedule() 时,NAPI 会被重新打开。mlx5e_napi_poll() -> mlx5e_poll_rx_cq()对于本文所用的网卡,注册的 poll() 方法是 mlx5e_napi_poll():
// drivers/net/ethernet/mellanox/mlx5/core/en_txrx.c
int mlx5e_napi_poll(struct napi_struct *napi, int budget) { // 这里的 budget 就是上面的 weight
struct mlx5e_channel *c = container_of(napi, struct mlx5e_channel, napi);
struct mlx5e_ch_stats *ch_stats = c->stats;
struct mlx5e_xdpsq *xsksq = &c->xsksq;
struct mlx5e_rq *xskrq = &c->xskrq;
struct mlx5e_rq *rq = &c->rq;
bool aff_change = false;
bool busy_xsk = false;
bool busy = false;
int work_done = 0;
bool xsk_open;
xsk_open = test_bit(MLX5E_CHANNEL_STATE_XSK, c->state);
ch_stats->poll++;
for (i = 0; i < c->num_tc; i++) // 遍历 TX channel,发包,释放 ring buffer
busy |= mlx5e_poll_tx_cq(&c->sq[i].cq, budget); // 每次发送最多 MLX5E_TX_CQ_POLL_BUDGET 个包
// budget 结束时还有包没发完,则返回 busy=true。
busy |= mlx5e_poll_xdpsq_cq(&c->xdpsq.cq); // XDP TX 队列发包,有自己独立的 budget 预算
if (c->xdp)
busy |= mlx5e_poll_xdpsq_cq(&c->rq_xdpsq.cq); // XDP RX 队列收包,有自己独立的 budget 预算
if (likely(budget)) { // 如果 budget!=0,则 poll RX ring 来收包;否则就跳过 RX ring
if (xsk_open)
work_done = mlx5e_poll_rx_cq(&xskrq->cq, budget);
if (likely(budget - work_done))
work_done += mlx5e_poll_rx_cq(&rq->cq, budget - work_done);
busy |= work_done == budget;
}
mlx5e_poll_ico_cq(&c->icosq.cq);
if (mlx5e_poll_ico_cq(&c->async_icosq.cq))
clear_bit(MLX5E_SQ_STATE_PENDING_XSK_TX, &c->async_icosq.state);
busy |= INDIRECT_CALL_2(rq->post_wqes, mlx5e_post_rx_mpwqes, mlx5e_post_rx_wqes, rq);
if (xsk_open) {
busy |= mlx5e_poll_xdpsq_cq(&xsksq->cq);
busy_xsk |= mlx5e_napi_xsk_post(xsksq, xskrq);
}
busy |= busy_xsk;
if (busy) {
if (likely(mlx5e_channel_no_affinity_change(c))) {
work_done = budget;
goto out;
}
ch_stats->aff_change++;
aff_change = true;
if (budget && work_done == budget)
work_done--;
}
if (unlikely(!napi_complete_done(napi, work_done)))
goto out;
ch_stats->arm++;
for (i = 0; i < c->num_tc; i++) {
mlx5e_handle_tx_dim(&c->sq[i]);
mlx5e_cq_arm(&c->sq[i].cq);
}
mlx5e_handle_rx_dim(rq);
mlx5e_cq_arm(&rq->cq);
mlx5e_cq_arm(&c->icosq.cq);
mlx5e_cq_arm(&c->async_icosq.cq);
mlx5e_cq_arm(&c->xdpsq.cq);
if (xsk_open) {
mlx5e_handle_rx_dim(xskrq);
mlx5e_cq_arm(&xsksq->cq);
mlx5e_cq_arm(&xskrq->cq);
}
if (unlikely(aff_change && busy_xsk)) {
mlx5e_trigger_irq(&c->icosq);
ch_stats->force_irq++;
}
return work_done;
}
复制Mellanox 是 TX 和 RX 是一起的,成为 combined queue。所以在一个 poll 操作里会依次处理 TX 和 RX 队列。
接下来只看普通的 RX 队列处理。
mlx5e_poll_rx_cq() -> mlx5e_handle_rx_cqe()Mellanox 术语:
// drivers/net/ethernet/mellanox/mlx5/core/en_rx.c
int mlx5e_poll_rx_cq(struct mlx5e_cq *cq, int budget) { // budget <= weight (hardcode 64)
struct mlx5e_rq *rq = container_of(cq, struct mlx5e_rq, cq);
struct mlx5_cqwq *cqwq = &cq->wq; // CQ 的 WQ
int work_done = 0;
cqe = mlx5_cqwq_get_cqe(cqwq);
do {
mlx5_cqwq_pop(cqwq); // 出队,解除 DMA 映射,释放 ring buffer
INDIRECT_CALL_2(rq->handle_rx_cqe, mlx5e_handle_rx_cqe_mpwrq, mlx5e_handle_rx_cqe, rq, cqe);
} while ((++work_done < budget) && (cqe = mlx5_cqwq_get_cqe(cqwq)));
out:
if (rcu_access_pointer(rq->xdp_prog)) // 如果 attach 了 XDP 程序,
mlx5e_xdp_rx_poll_complete(rq); // 处理 XDP RX 队列
mlx5_cqwq_update_db_record(cqwq); // 更新 ring buffer 元信息
wmb(); // 确保 CQ 空间(ring buffer)已经释放了,这样才能放新的 CQE 进来
return work_done; // 返回处理的包数。注意:XDP 的包并没有统计在这里面
}
复制也是个循环,退出条件很明确:
mlx5e_handle_rx_cqe() -> napi_gro_receive()根据 rq->handle_rx_cqe 是哪种情况,分别调用相应的 handler,最终都是调用到 napi_gro_receive():
static void mlx5e_handle_rx_cqe(struct mlx5e_rq *rq, struct mlx5_cqe64 *cqe) {
struct mlx5_wq_cyc *wq = &rq->wqe.wq;
u16 ci = mlx5_wq_cyc_ctr2ix(wq, be16_to_cpu(cqe->wqe_counter));
struct mlx5e_wqe_frag_info *wi = get_frag(rq, ci);
u32 cqe_bcnt = be32_to_cpu(cqe->byte_cnt);
// 创建 skb,从 ringbuffer DMA 区域复制数据包;从这一步开始,才有了内核 skb 结构体
struct sk_buff *skb = INDIRECT_CALL_2(rq->wqe.skb_from_cqe,
mlx5e_skb_from_cqe_linear,
mlx5e_skb_from_cqe_nonlinear,
rq, cqe, wi, cqe_bcnt);
if (!skb) { // 可能是 XDP 包
if (__test_and_clear_bit(MLX5E_RQ_FLAG_XDP_XMIT, rq->flags)) {
goto wq_cyc_pop; // do not return page to cache, it will be returned on XDP_TX completion.
}
goto free_wqe;
}
mlx5e_complete_rx_cqe(rq, cqe, cqe_bcnt, skb);
if (mlx5e_cqe_regb_chain(cqe))
if (!mlx5e_tc_update_skb(cqe, skb)) { // TC 信息
dev_kfree_skb_any(skb);
goto free_wqe;
}
napi_gro_receive(rq->cq.napi, skb);
free_wqe:
mlx5e_free_rx_wqe(rq, wi, true);
wq_cyc_pop:
mlx5_wq_cyc_pop(wq);
}
复制skb = mlx5e_skb_from_cqe_linear():创建内核数据包这个函数从 ringbuffer DMA 区域复制数据,然后初始化一个 struct sk_buff *skb 结构体变量,也就是我们最常打交道的内核协议栈中的数据包 —— 也就是说,本文从开始到现在,网络处理流程中不出现任何错误的话,我们才终于在内核中 有了一个数据包(skb),至于那些依赖 skb 的邻居子系统、路由子系统、 Netfilter/iptables、TC、各种网络 BPF 程序(XDP 除外),都还在后面(甚至很远的地方)。 可以体会到内核网络栈是多么复杂(而精巧)。
// drivers/net/ethernet/mellanox/mlx5/core/en_rx.c
static struct sk_buff *
mlx5e_skb_from_cqe_linear(struct mlx5e_rq *rq, struct mlx5_cqe64 *cqe, struct mlx5e_wqe_frag_info *wi, u32 cqe_bcnt) {
struct mlx5e_dma_info *di = wi->di;
u16 rx_headroom = rq->buff.headroom;
struct xdp_buff xdp;
struct sk_buff *skb;
void *va, *data;
u32 frag_size;
va = page_address(di->page) + wi->offset;
data = va + rx_headroom;
frag_size = MLX5_SKB_FRAG_SZ(rx_headroom + cqe_bcnt);
dma_sync_single_range_for_cpu(rq->pdev, di->addr, wi->offset,
frag_size, DMA_FROM_DEVICE);
net_prefetchw(va); /* xdp_frame data area */
net_prefetch(data);
mlx5e_fill_xdp_buff(rq, va, rx_headroom, cqe_bcnt, &xdp);
if (mlx5e_xdp_handle(rq, di, &cqe_bcnt, &xdp))
return NULL; /* page/packet was consumed by XDP */
rx_headroom = xdp.data - xdp.data_hard_start;
frag_size = MLX5_SKB_FRAG_SZ(rx_headroom + cqe_bcnt);
skb = mlx5e_build_linear_skb(rq, va, frag_size, rx_headroom, cqe_bcnt);
if (unlikely(!skb))
return NULL;
/* queue up for recycling/reuse */
page_ref_inc(di->page);
return skb;
}
static inline
struct sk_buff *mlx5e_build_linear_skb(struct mlx5e_rq *rq, void *va, u32 frag_size, u16 headroom, u32 cqe_bcnt) {
struct sk_buff *skb = build_skb(va, frag_size); // 通用内核函数
skb_reserve(skb, headroom);
skb_put(skb, cqe_bcnt);
return skb;
}
复制这里就是第二次数据复制的地方。
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
mlx5e_complete_rx_cqe() -> mlx5e_build_rx_skb():初始化 L2 header、IPSec、时间戳等static inline void
mlx5e_complete_rx_cqe(struct mlx5e_rq *rq, struct mlx5_cqe64 *cqe, u32 cqe_bcnt, struct sk_buff *skb) {
struct mlx5e_rq_stats *stats = rq->stats;
stats->packets++;
stats->bytes += cqe_bcnt;
mlx5e_build_rx_skb(cqe, cqe_bcnt, rq, skb); // 初始化 L2 header
}
static inline void
mlx5e_build_rx_skb(struct mlx5_cqe64 *cqe, u32 cqe_bcnt, struct mlx5e_rq *rq, struct sk_buff *skb)
{
u8 lro_num_seg = be32_to_cpu(cqe->srqn) >> 24;
struct net_device *netdev = rq->netdev;
skb->mac_len = ETH_HLEN; // L2 header length
mlx5e_tls_handle_rx_skb(rq, skb, cqe, &cqe_bcnt);
if (unlikely(mlx5_ipsec_is_rx_flow(cqe)))
mlx5e_ipsec_offload_handle_rx_skb(netdev, skb, cqe);
if (lro_num_seg > 1) {
mlx5e_lro_update_hdr(skb, cqe, cqe_bcnt);
skb_shinfo(skb)->gso_size = DIV_ROUND_UP(cqe_bcnt, lro_num_seg);
stats->packets += lro_num_seg - 1;
stats->lro_packets++;
stats->lro_bytes += cqe_bcnt;
}
if (unlikely(mlx5e_rx_hw_stamp(rq->tstamp))) // 硬件打时间戳
skb_hwtstamps(skb)->hwtstamp = mlx5_timecounter_cyc2time(rq->clock, get_cqe_ts(cqe));
skb_record_rx_queue(skb, rq->ix);
if (likely(netdev->features & NETIF_F_RXHASH))
mlx5e_skb_set_hash(cqe, skb);
if (cqe_has_vlan(cqe)) { // 添加 VLAN header
__vlan_hwaccel_put_tag(skb, htons(ETH_P_8021Q), be16_to_cpu(cqe->vlan_info));
stats->removed_vlan_packets++;
}
skb->mark = be32_to_cpu(cqe->sop_drop_qpn) & MLX5E_TC_FLOW_ID_MASK;
mlx5e_handle_csum(netdev, cqe, rq, skb, !!lro_num_seg); // L2 校验和
if (unlikely(cqe->ml_path & MLX5E_CE_BIT_MASK))
mlx5e_enable_ecn(rq, skb); // L2 纠错
skb->protocol = eth_type_trans(skb, netdev); // 函数里面还会设置 skb->pkt_type
}
复制eth_type_trans() 定义在 net/ethernet/eth.c,这个函数除了返回 skb 的 ethernet protocol 类型, 还会设置 skb->pkt_type,可能类型:
mlx5e_build_rx_skb() -> mlx5e_post_rx_wqes():重新填充 RX ring已经完成的 CQ WQ (简单来说就是 RX ringbuffer)会释放掉,所以最后需要重新分配 CQ WQ:
INDIRECT_CALLABLE_SCOPE bool
mlx5e_post_rx_wqes(struct mlx5e_rq *rq) {
struct mlx5_wq_cyc *wq = &rq->wqe.wq;
u8 wqe_bulk = rq->wqe.info.wqe_bulk;
if (mlx5_wq_cyc_missing(wq) < wqe_bulk)
return false;
do {
u16 head = mlx5_wq_cyc_get_head(wq);
mlx5e_alloc_rx_wqes(rq, head, wqe_bulk);
mlx5_wq_cyc_push_n(wq, wqe_bulk);
} while (mlx5_wq_cyc_missing(wq) >= wqe_bulk);
dma_wmb(); /* ensure wqes are visible to device before updating doorbell record */
mlx5_wq_cyc_update_db_record(wq);
return !!err;
}
复制执行完这些网卡相关的 poll() 逻辑之后,最后通过 napi_gro_receive() 重新回到内核通用逻辑。
napi_gro_receive()Large Receive Offloading (LRO) 是一个硬件优化,GRO 是 LRO 的一种软件实现。
GRO 是一种较老的硬件特性(LRO)的软件实现,功能是对分片的包进行重组然后交给更上层,以提高吞吐。 GRO 给协议栈提供了一次将包交给网络协议栈之前,对其检查校验和 、修改协议头和发送应答包(ACK packets)的机会。
enqueue_backlog() 将这个分片放到某个 CPU 的包队列;当包重组完成后,会交会协议栈网上送;LRO 和 GRO 的主要思想都是通过合并“足够类似”的包来减少传送给网络栈的包数,这有 助于减少 CPU 的使用量。例如,考虑大文件传输的场景,包的数量非常多,大部分包都是一 段文件数据。相比于每次都将小包送到网络栈,可以将收到的小包合并成一个很大的包再送 到网络栈。GRO 使协议层只需处理一个 header,而将包含大量数据的整个大包送到用 户程序。
这类优化方式的缺点是信息丢失:包的 option 或者 flag 信息在合并时会丢 失。这也是为什么大部分人不使用或不推荐使用 LRO 的原因。LRO 的实现,一般来说,对 合并包的规则非常宽松。GRO 是 LRO 的软件实现,但是对于包合并的规则更严苛。
顺便说一下,如果用 tcpdump 抓包,有时会看到机器收到了看起来不现实的、非常大的包, 这很可能是你的系统开启了 GRO;后面会看到,tcpdump 的抓包点(捕获包的 tap)在整个栈的更后面一些,在 GRO 之后。
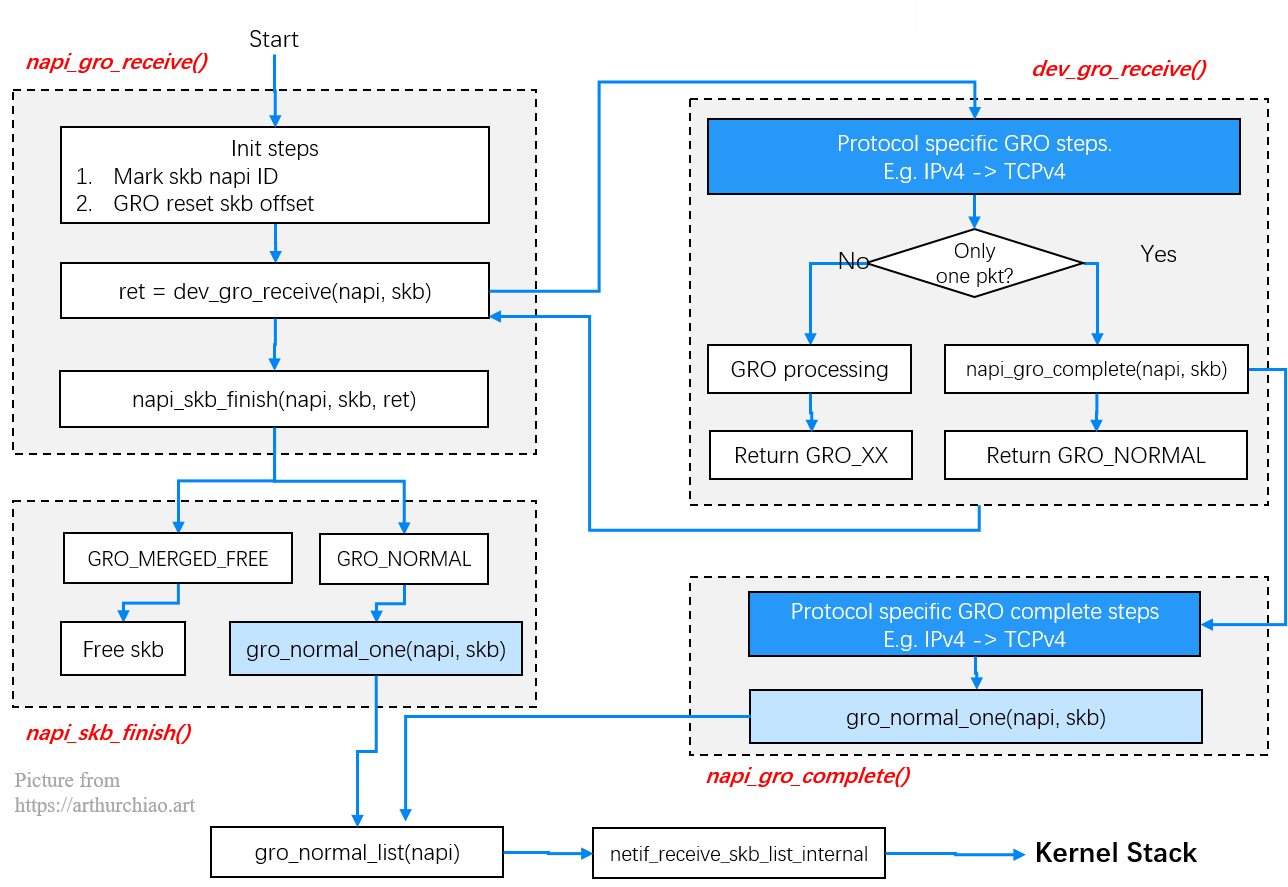
Fig. GRO receive process: heavy-lifting work before entering kernel stack
napi_gro_receive() 负责处理数据,并将数据送到协议栈,大部分 相关的逻辑在函数 dev_gro_receive() 里实现:
// net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb) {
skb_mark_napi_id(skb, napi);
skb_gro_reset_offset(skb, 0);
return napi_skb_finish(napi, skb, dev_gro_receive(napi, skb));
}
复制dev_gro_receive()// https://github.com/torvalds/linux/blob/v5.10/net/core/dev.c
static struct list_head offload_base __read_mostly; // offload list
static enum gro_result dev_gro_receive(struct napi_struct *napi, struct sk_buff *skb) {
struct list_head *gro_head = gro_list_prepare(napi, skb);
struct sk_buff *pp;
struct packet_offload *ptype; // packet offload 相关结构体
struct list_head *head = &offload_base;
list_for_each_entry_rcu(ptype, head, list) {
if (ptype->type != skb->protocol || !ptype->callbacks.gro_receive)
continue; // L2/L3 协议类型不同,或者没有回调方法,只能跳过
skb_set_network_header(skb, skb_gro_offset(skb));
skb_reset_mac_len(skb);
NAPI_GRO_CB(skb)->same_flow = 0;
NAPI_GRO_CB(skb)->flush = skb_is_gso(skb) || skb_has_frag_list(skb);
NAPI_GRO_CB(skb)->free = 0;
NAPI_GRO_CB(skb)->encap_mark = 0;
NAPI_GRO_CB(skb)->recursion_counter = 0;
NAPI_GRO_CB(skb)->is_fou = 0;
NAPI_GRO_CB(skb)->gro_remcsum_start = 0;
/* Setup for GRO checksum validation */
...
pp = INDIRECT_CALL_INET(ptype->callbacks.gro_receive, ipv6_gro_receive, inet_gro_receive, gro_head, skb);
break;
}
if (&ptype->list == head)
goto normal;
u32 hash = skb_get_hash_raw(skb) & (GRO_HASH_BUCKETS - 1);
if (pp) { // 如果 pp 非空,说明这已经是一个完成的包,可以送到更上层去处理了
skb_list_del_init(pp);
napi_gro_complete(napi, pp); // 将包送到协议栈
napi->gro_hash[hash].count--;
}
// 执行到这里说明这个包不完整,需要执行 GRO 合并
int same_flow = NAPI_GRO_CB(skb)->same_flow;
if (same_flow) // 这个包属于已经存在的一个 flow,需要和其他包合并
goto ok;
if (NAPI_GRO_CB(skb)->flush) // 合并完成了,已经拿到完整包
goto normal;
if (unlikely(napi->gro_hash[hash].count >= MAX_GRO_SKBS)) { // 新建一个 entry 加到本 CPU 的 NAPI 变量的 gro_list
gro_flush_oldest(napi, gro_head);
} else {
napi->gro_hash[hash].count++;
}
NAPI_GRO_CB(skb)->count = 1;
NAPI_GRO_CB(skb)->age = jiffies;
NAPI_GRO_CB(skb)->last = skb;
skb_shinfo(skb)->gso_size = skb_gro_len(skb);
list_add(&skb->list, gro_head);
ret = GRO_HELD;
pull:
int grow = skb_gro_offset(skb) - skb_headlen(skb);
if (grow > 0)
gro_pull_from_frag0(skb, grow);
ok:
if (napi->gro_hash[hash].count) {
if (!test_bit(hash, &napi->gro_bitmask))
__set_bit(hash, &napi->gro_bitmask);
} else if (test_bit(hash, &napi->gro_bitmask)) {
__clear_bit(hash, &napi->gro_bitmask);
}
return ret;
normal:
ret = GRO_NORMAL;
goto pull;
}
复制首先遍历 packet type 列表,找到合适的 receive 方法:
$ cat /proc/net/ptype # packet type (skb->protocol)
Type Device Function
0800 ip_rcv
0806 arp_rcv
86dd ipv6_rcv
复制然后遍历一个 offload filter 列表,如果高层协议(L3/L4)认为其中一些数据属于 GRO 处理的范围,就会允许其对数据进行操作。 协议层的返回是 struct sk_buff * 指针,指针非空表示这个 packet 需要做 GRO,非空表示可以送到协议栈 。另外,也可以通过这种方式传递一些协议相关的信息。例如,TCP 协 议需要判断是否以及合适应该将一个 ACK 包合并到其他包里。
如果协议层提示是时候 flush GRO packet 了,那就到下一步处理了。这发生在 napi_gro_complete(),会进一步调用相应协议的 gro_complete() 回调方法,然后调用 netif_receive_skb_list_internal() 将包送到协议栈。
napi_gro_complete()static int napi_gro_complete(struct napi_struct *napi, struct sk_buff *skb) {
if (NAPI_GRO_CB(skb)->count == 1) {
skb_shinfo(skb)->gso_size = 0;
goto out;
}
struct packet_offload *ptype;
struct list_head *head = &offload_base;
list_for_each_entry_rcu(ptype, head, list) {
if (ptype->type != skb->protocol || !ptype->callbacks.gro_complete)
continue;
INDIRECT_CALL_INET(ptype->callbacks.gro_complete, ipv6_gro_complete, inet_gro_complete, skb, 0);
break;
}
out:
gro_normal_one(napi, skb, NAPI_GRO_CB(skb)->count);
return NET_RX_SUCCESS;
}
// net/ipv4/af_inet.c
int inet_gro_complete(struct sk_buff *skb, int nhoff) {
struct iphdr *iph = (struct iphdr *)(skb->data + nhoff); // IP header 起始位置
if (skb->encapsulation) {
skb_set_inner_protocol(skb, cpu_to_be16(ETH_P_IP));
skb_set_inner_network_header(skb, nhoff);
}
__be16 newlen = htons(skb->len - nhoff);
csum_replace2(&iph->check, iph->tot_len, newlen); // IP header checksum
iph->tot_len = newlen;
const struct net_offload *ops = rcu_dereference(inet_offloads[iph->protocol]);
/* Only need to add sizeof(*iph) to get to the next hdr below
* because any hdr with option will have been flushed in
* inet_gro_receive().
*/
INDIRECT_CALL_2(ops->callbacks.gro_complete, tcp4_gro_complete, udp4_gro_complete, skb, nhoff + sizeof(*iph));
}
复制napi_skb_finish() -> gro_normal_one() -> gro_normal_list()dev_gro_receive() 的返回结果是 napi_skb_finish() 的参数,
static gro_result_t napi_skb_finish(struct napi_struct *napi, struct sk_buff *skb, gro_result_t ret) {
switch (ret) {
case GRO_NORMAL:
gro_normal_one(napi, skb, 1); break;
case GRO_DROP:
kfree_skb(skb); break;
case GRO_MERGED_FREE: // 已经被合并,释放 skb
if (NAPI_GRO_CB(skb)->free == NAPI_GRO_FREE_STOLEN_HEAD)
napi_skb_free_stolen_head(skb);
else
__kfree_skb(skb);
break;
case GRO_HELD:
case GRO_MERGED:
case GRO_CONSUMED:
break;
}
return ret;
}
复制如果是 GRO_NORMAL,会调用 gro_normal_one(),它会更新当前 napi->rx_count 计数, 当数量足够多时,将调用 gro_normal_list(),后者会将包一次性都送到协议栈:
// Queue one GRO_NORMAL SKB up for list processing. If batch size exceeded, pass the whole batch up to the stack.
static void gro_normal_one(struct napi_struct *napi, struct sk_buff *skb, int segs) {
napi->rx_count += segs;
if (napi->rx_count >= gro_normal_batch) // int gro_normal_batch __read_mostly = 8;
gro_normal_list(napi); //
}
复制这里的阈值 gro_normal_batch 默认是 8,可以通过 sysctl 配置:
$ sudo sysctl net.core.gro_normal_batch
net.core.gro_normal_batch = 8
复制gro_normal_list() -> netif_receive_skb_list_internal():批量将包送到协议栈gro_normal_list() 调用 netif_receive_skb_list_internal() 将一组包一次性送到协议栈:
// Pass the currently batched GRO_NORMAL SKBs up to the stack.
static void gro_normal_list(struct napi_struct *napi) {
if (!napi->rx_count) // 没有包的话直接返回,什么都不做
return;
netif_receive_skb_list_internal(&napi->rx_list); // 注意这个函数没有返回值,所有错误都在内部处理
INIT_LIST_HEAD(&napi->rx_list); // 把这个 NAPI 重新入队,并放到队首(下次最后一个被处理,因为刚处理过一次了)
napi->rx_count = 0; // 重置计数
}
复制每个 NAPI 变量都会运行在相应 CPU 的软中断的上下文中。而且,触发硬中断的这个 CPU 接下来会负责执行相应的软中断处理函数来收包。换言之,同一个 CPU 既处理硬中断,又 处理相应的软中断。
另一方面,DMA 区域是网卡与内核协商之后预留的内存,由于这块内存区域是有限的, 如果收到的包非常多,单个 CPU 来不及取走这些包,新来的包就会被丢弃。 一些网卡有能力将接收到的包写到多个不同的内存区域,每个区域都是独立的接收队列,即多队列功能。 这样操作系统就可以利用多个 CPU(硬件层面)并行处理收到的包。
如今大部分网卡都在硬件层支持多队列。这意味着收进来的包会被通过 DMA 放到 位于不同内存的队列上,而不同的队列有相应的 NAPI 变量管理软中断 poll()过程。因此, 多个 CPU 同时处理从网卡来的中断,处理收包过程。 这个特性被称作 RSS(Receive Side Scaling,接收端水平扩展)。
RPS(Receive Packet Steering,接收包控制,接收包引导)是 RSS 的一种软件实现。
RPS 的工作原理:
softnet_data.received_rps 记录了每个 CPU 收到了多少 IPI:
// net/core/net-procfs.c
static int softnet_seq_show(struct seq_file *seq, void *v) {
struct softnet_data *sd = v;
seq_printf(seq,
"%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n",
sd->processed, sd->dropped, sd->time_squeeze, 0,
0, 0, 0, 0, /* was fastroute */
0, /* was cpu_collision */
sd->received_rps, flow_limit_count,
softnet_backlog_len(sd), (int)seq->index);
return 0;
}
复制cat /proc/net/softnet_stat 的第 10 列。
RFS(Receive flow steering)和 RPS 配合使用。RPS 试图在 CPU 之间平衡收包,但是 没考虑数据的局部性问题,如何最大化 CPU 缓存的命中率。
RFS 将相同 flow 的包送到相同的 CPU 进行处理,可以提高缓存命中率。
RFS 可以用硬件加速,网卡和内核协同工作,判断哪个 flow 应该在哪个 CPU 上处理。这需要网 卡和网卡驱动的支持。
如果你的网卡驱动实现了 ndo_rx_flow_steer() 方法,那就是支持 RFS。
最后再回到我们的 GRO 处理逻辑:
Fig. GRO receive process: heavy-lifting work before entering kernel stack
可以看到有两个地方最终都会执行到 gro_normal_one():
napi_skb_finish:当 packet 不需要被合并到已经存在的某个 GRO flow 的时候napi_gro_complete:协议层提示需要 flush 当前的 flow 的时候而 gro_normal_one() 又通过 gro_normal_list() -> netif_receive_skb_list_internal() 最终进入内核协议栈。我们在下一节来详细看进入协议栈之后的处理。
netif_receive_skb_list_internal运行在软中断处理循环(softirq processing loop)的上下文中, 因此这里的时间会记录到top命令看到的si或者sitime字段。
现在来到了图中第 7 步:
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
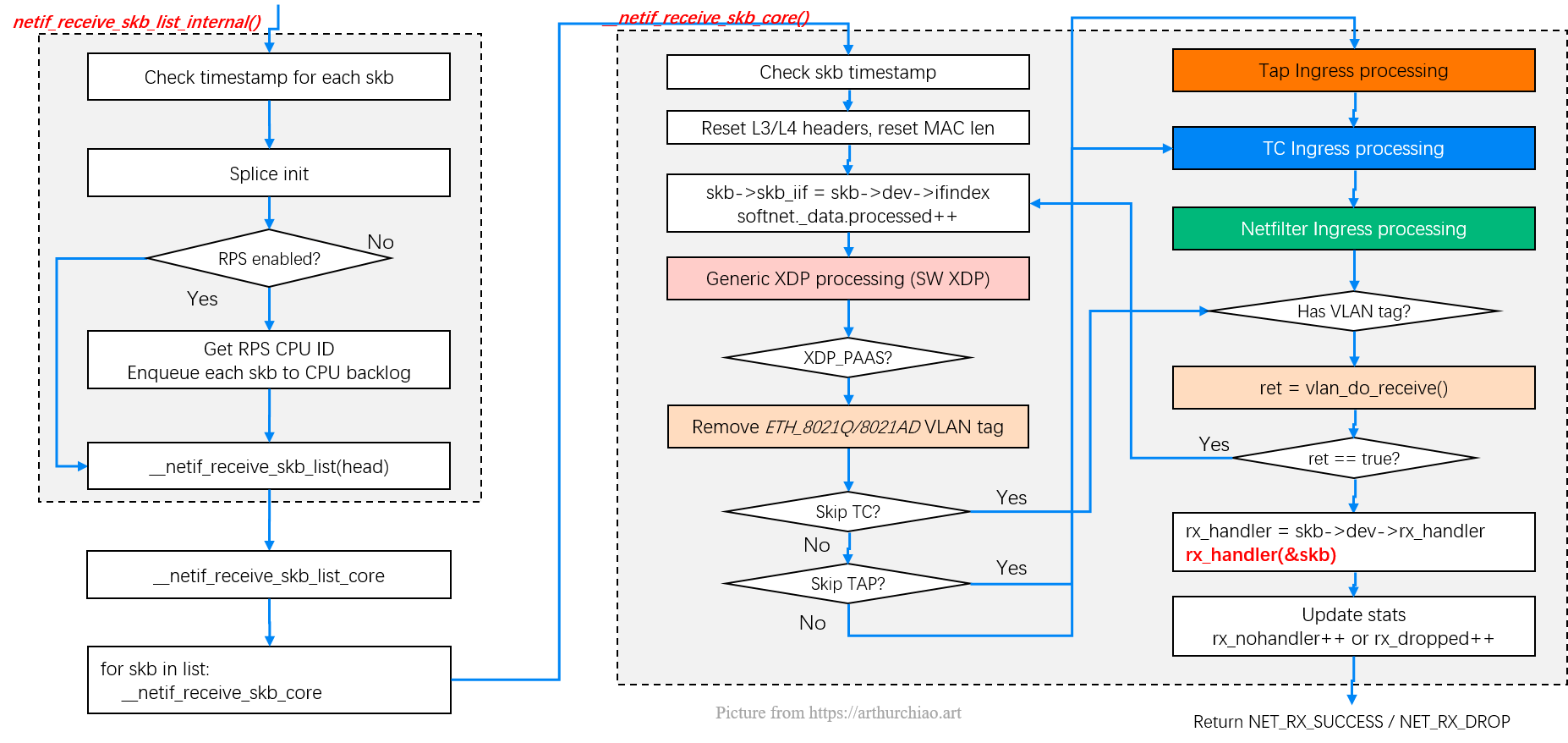
Fig. Entering kernel stack: L2 processing steps
netif_receive_skb_list_internal() -> __netif_receive_skb_list()// net/core/dev.c
static void netif_receive_skb_list_internal(struct list_head *head) {
struct list_head sublist;
list_for_each_entry_safe(skb, next, head, list) { // struct sk_buff *skb, *next;
net_timestamp_check(netdev_tstamp_prequeue, skb);
skb_list_del_init(skb);
if !skb_defer_rx_timestamp(skb)
list_add_tail(&skb->list, &sublist);
}
list_splice_init(&sublist, head);
if static_branch_unlikely(&rps_needed) // RPS 处理逻辑
list_for_each_entry_safe(skb, next, head, list) {
int cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
skb_list_del_init(skb); /* Will be handled, remove from list */
enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
}
}
__netif_receive_skb_list(head);
}
复制首先会检查有没有设置一个接收时间戳选项(sysctl),这个选项决定在 packet 在到达 backlog queue 之前还是之后打时间戳。
如果 RPS 开启了,那这个选项可以将打时间戳的任务分散个其他 CPU,但会带来一些延迟。
处理完时间戳后,会根据 RPS 是否启用来做不同的事情。
简单情况,RPS 未启用(默认)。
调用栈:__netif_receive_skb_list() -> __netif_receive_skb_list_core() -> __netif_receive_skb_core()
执行到 __netif_receive_skb_list(),它会继续调用 __netif_receive_skb_list_core(),后者做一些 bookkeeping 工作, 进而对每个 skb 调用 __netif_receive_skb_core(),将数据送到网络栈更上层一些。
启用了 RPS:先 enqueue_to_backlog,后面的逻辑和 1 一样。
static void __netif_receive_skb_list(struct list_head *head) {
unsigned long noreclaim_flag = 0;
struct sk_buff *skb, *next;
bool pfmemalloc = false; /* Is current sublist PF_MEMALLOC? */
list_for_each_entry_safe(skb, next, head, list) {
if (sk_memalloc_socks() && skb_pfmemalloc(skb)) != pfmemalloc {
list_cut_before(&sublist, head, &skb->list); /* Handle the previous sublist */
if (!list_empty(&sublist))
__netif_receive_skb_list_core(&sublist, pfmemalloc);
pfmemalloc = !pfmemalloc;
if (pfmemalloc) /* See comments in __netif_receive_skb */
noreclaim_flag = memalloc_noreclaim_save();
else
memalloc_noreclaim_restore(noreclaim_flag);
}
}
if !list_empty(head) /* Handle the remaining sublist */
__netif_receive_skb_list_core(head, pfmemalloc);
if (pfmemalloc) /* Restore pflags */
memalloc_noreclaim_restore(noreclaim_flag);
}
static void __netif_receive_skb_list_core(struct list_head *head, bool pfmemalloc) {
// Fast-path assumptions:
// - There is no RX handler.
// - Only one packet_type matches.
//
// If either of these fails, we will end up doing some per-packet
// processing in-line, then handling the 'last ptype' for the whole
// sublist. This can't cause out-of-order delivery to any single ptype,
// because the 'last ptype' must be constant across the sublist, and all
// other ptypes are handled per-packet.
struct packet_type *pt_curr = NULL; // Current (common) ptype of sublist */
struct net_device *od_curr = NULL; // Current (common) orig_dev of sublist */
struct sk_buff *skb, *next;
INIT_LIST_HEAD(&sublist);
list_for_each_entry_safe(skb, next, head, list) {
struct net_device *orig_dev = skb->dev;
struct packet_type *pt_prev = NULL;
skb_list_del_init(skb);
__netif_receive_skb_core(&skb, pfmemalloc, &pt_prev);
if (!pt_prev)
continue;
if (pt_curr != pt_prev || od_curr != orig_dev) {
__netif_receive_skb_list_ptype(&sublist, pt_curr, od_curr); /* dispatch old sublist */
INIT_LIST_HEAD(&sublist); /* start new sublist */
pt_curr = pt_prev;
od_curr = orig_dev;
}
list_add_tail(&skb->list, &sublist);
}
/* dispatch final sublist */
__netif_receive_skb_list_ptype(&sublist, pt_curr, od_curr);
}
复制接下来先看未启用 RPS 的情况(7.3),然后再开启用了 RPS 的情况(7.4)。
__netif_receive_skb_core():送到协议层__netif_receive_skb_core 完成将数据送到协议栈这一繁重工作。这里面做的事情非常多, 按顺序包括:
再贴一下流程图,方便对照:
// https://github.com/torvalds/linux/blob/v5.10/net/core/dev.c
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc, struct packet_type **ppt_prev) {
struct sk_buff *skb = *pskb;
net_timestamp_check(!netdev_tstamp_prequeue, skb); // 检查时间戳
skb_reset_network_header(skb);
if (!skb_transport_header_was_set(skb))
skb_reset_transport_header(skb);
skb_reset_mac_len(skb);
struct packet_type *ptype = NULL;
struct net_device *orig_dev = skb->dev; // 记录 skb 原来所在的网络设备
another_round:
skb->skb_iif = skb->dev->ifindex; // 设置 skb 是从那个网络设备接收的
__this_cpu_inc(softnet_data.processed); // 更新 softnet_data.processed 计数
if (static_branch_unlikely(&generic_xdp_needed_key)) { // Generic XDP(软件实现 XDP 功能)
preempt_disable();
ret2 = do_xdp_generic(skb->dev->xdp_prog, skb);
preempt_enable();
if (ret2 != XDP_PASS) {
ret = NET_RX_DROP;
goto out;
}
skb_reset_mac_len(skb);
}
if (skb->protocol == ETH_P_8021Q || skb->protocol == ETH_P_8021AD)
skb = skb_vlan_untag(skb);
if (skb_skip_tc_classify(skb))
goto skip_classify;
if (pfmemalloc) // 跳过抓包逻辑
goto skip_taps;
list_for_each_entry_rcu(ptype, &ptype_all, list) { // 抓包
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) { // 抓包
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
skip_taps: // 如果是使用 goto 跳转过来的,那跳过了抓包逻辑(libpcap、tcpdump 等)
if (static_branch_unlikely(&ingress_needed_key)) { // TC ingress 处理
bool another = false;
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev, &another);
if (another) // TCP BPF 优化,通过 another round 将包从宿主机网卡直接送到容器 netns 内网卡
goto another_round; // 需要内核 5.10+
if (!skb)
goto out;
if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0) // Netfilter ingress 处理
goto out;
}
skb_reset_redirect(skb); // 重置 redirect
skip_classify: // 如果是使用 goto 跳转过来的,那跳过了抓包、TC、Netfilter 逻辑
if (pfmemalloc && !skb_pfmemalloc_protocol(skb))
goto drop;
if (skb_vlan_tag_present(skb)) { // 处理 VLAN 头
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
if (vlan_do_receive(&skb))
goto another_round;
}
bool deliver_exact = false;
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto out;
case RX_HANDLER_ANOTHER:
goto another_round;
case RX_HANDLER_EXACT:
deliver_exact = true;
case RX_HANDLER_PASS:
break;
}
}
if (unlikely(skb_vlan_tag_present(skb)) && !netdev_uses_dsa(skb->dev)) {
check_vlan_id:
// 一些 VLAN 特殊处理
}
type = skb->protocol;
/* deliver only exact match when indicated */
if (likely(!deliver_exact)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &ptype_base[ntohs(type) & PTYPE_HASH_MASK]);
}
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &orig_dev->ptype_specific);
if (unlikely(skb->dev != orig_dev)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &skb->dev->ptype_specific);
}
if (pt_prev) {
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
goto drop;
*ppt_prev = pt_prev;
} else {
drop:
if (!deliver_exact)
atomic_long_inc(&skb->dev->rx_dropped); // 更新网卡的 rx_dropped 统计
else
atomic_long_inc(&skb->dev->rx_nohandler); // 更新网卡的 rx_nohandler 统计
kfree_skb(skb);
ret = NET_RX_DROP;
}
out:
*pskb = skb;
return ret;
}
复制ptype_base[]:L2/L3 协议层注册上面代码中的 ptype_base 是一个 hash table,
// https://github.com/torvalds/linux/blob/v5.10/net/core/dev.c
extern struct list_head ptype_all __read_mostly;
extern struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
复制每种协议在初始化时,通过 dev_add_pack() 注册各自的协议信息进去, 用于处理相应协议的网络数据(后面 L3/L4 章节会看到更具体的调用栈)。这就是协议层如何注册自身的。几种重要类型:
$ grep -R "dev_add_pack(" net/{ipv4,packet}/*
net/ipv4/af_inet.c: dev_add_pack(&ip_packet_type);
net/ipv4/arp.c: dev_add_pack(&arp_packet_type);
net/ipv4/ipconfig.c: dev_add_pack(&rarp_packet_type);
net/ipv4/ipconfig.c: dev_add_pack(&bootp_packet_type);
net/packet/af_packet.c: dev_add_pack(&po->prot_hook);
net/packet/af_packet.c: dev_add_pack(&f->prot_hook);
复制如果硬件网卡不支持 XDP 程序,那 XDP 程序会推迟到这里来执行。
XDP 的目的是将部分逻辑下放(offload)到网卡执行,通过硬件处理提高效率。 但是不是所有网卡都支持这个功能,所以内核引入了 Generic XDP 这样一个环境,如果网卡不支持 XDP, 那 XDP 程序就会推迟到这里来执行。它并不能提升效率,所以主要用来测试功能。
更多关于 XDP 的内容: XDP (eXpress Data Path):在操作系统内核中实现快速、可编程包处理(ACM,2018)。
检查是否插入了 tap(探测点),这些 tap 是抓包用的。例如,AF_PACKET 地址族就 可以插入这些抓包指令,一般通过 libpcap 库。 如果存在 tap,数据就会送到 tap,然后才到协议层。
代码会轮询所有的 socket tap,将包放到正确的 tap 设备的缓冲区。
tap 设备监听的是三层协议(L3 protocols),例如 IPv4、ARP、IPv6 等等。 如果 tap 设备存在,它就可以操作这个 skb 了。
static inline void __netif_receive_skb_list_ptype(struct list_head *head,
struct packet_type *pt_prev, struct net_device *orig_dev) {
if (!pt_prev)
return;
if (pt_prev->list_func != NULL)
INDIRECT_CALL_INET(pt_prev->list_func, ipv6_list_rcv, ip_list_rcv, head, pt_prev, orig_dev);
else
list_for_each_entry_safe(skb, next, head, list) { // 遍历 list 中的每个 skb
skb_list_del_init(skb);
pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
}
复制如果对 packet 如何经过 pcap 有兴趣,可以阅读 net/packet/af_packet.c。
通过 sch_handle_ingress() 进入 TC ingress 处理。 TC(Traffic Control)是 Linux 的流量控制子系统,
更多信息:
这个功能需要内核 5.10+,而且需要网络应用(例如 Cilium)自己 attach BPF 程序。 适用场景:容器通过 veth pair 连接到宿主机(例如 Cilium 默认的网络模式),
好处: 避免重新进入协议栈,显著提升吞吐,降低延迟,具体 benchmark 见 Cilium 1.9 Release Notes, 我们自己也压测确认了这个结果;
已知不足:
绕过了完整的协议栈逻辑,导致容器网卡的一些 ingress 统计不对(/sys/class/ 下面)。
kubelet 会通过读 /sys/class/... 收集这些 ingress 统计,例如 /sys/class/net/<dev>/statistics/rx_packets,然后通过 12050 端口将 metric 暴露出来。 所以依赖 kubelet metric 的看板会看到容器 ingress packets/bandwidth 等等都不对(几乎为零)。
通过 nf_ingress() 进入 Netfilter ingress 处理。 Netfilter 是传统的内核包过滤子系统,iptables 是其用户空间客户端。
更多信息:
通过 skb->dev->rx_handler(&skb) 进入 L3 ingress 处理,例如 IPv4 处理逻辑。
具体见代码。
enqueue_to_backlog() 再转 7.3如果 RPS 启用了,它会做一些计算,判断使用哪个 CPU 的 backlog queue,这个过程由 get_rps_cpu 函数完成。
get_rps_cpu 会考虑前面提到的 RFS 和 aRFS 设置,以此选出一个合适的 CPU,通过调用 enqueue_to_backlog 将数据放到它的 backlog queue。
enqueue_to_backlog()首先从远端 CPU 的 struct softnet_data 获取 backlog queue 长度。如果 backlog 大于 netdev_max_backlog,或者超过了 flow limit,直接 drop,并更新 softnet_data 的 drop 统计。注意这是远端 CPU 的统计。
代码见 net/core/dev.c。
RPS 在不同 CPU 之间分发 packet,但是,如果一个 flow 特别大,会出现单个 CPU 被打爆,而 其他 CPU 无事可做(饥饿)的状态。因此引入了 flow limit 特性,放到一个 backlog 队列的属 于同一个 flow 的包的数量不能超过一个阈值。这可以保证即使有一个很大的 flow 在大量收包 ,小 flow 也能得到及时的处理。
Flow limit 功能默认是关掉的。要打开 flow limit,需要指定一个 bitmap(类似于 RPS 的 bitmap)。
每个 CPU 都有一个 backlog queue,其加入到 NAPI 变量的方式和驱动差不多,都是注册一个 poll() 方法,在软中断的上下文中处理包。此外,还提供了一个 weight,这也和驱动类似 。
注册发生在网络系统初始化时,net_dev_init():
// https://github.com/torvalds/linux/blob/v5.10/net/core/dev.c
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
sd->backlog.gro_list = NULL;
sd->backlog.gro_count = 0;
复制backlog NAPI 变量和设备驱动 NAPI 变量的不同之处在于,它的 weight 是可以调节的,而设备 驱动是 hardcode 64。
process_backlog()见 net/core/dev.c。
现在来到了图中第 8 步:
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
接下来我们看协议层注册自身的实现。
本文会拿 IP 层作为例子,因为它最常用,大家都很熟悉。
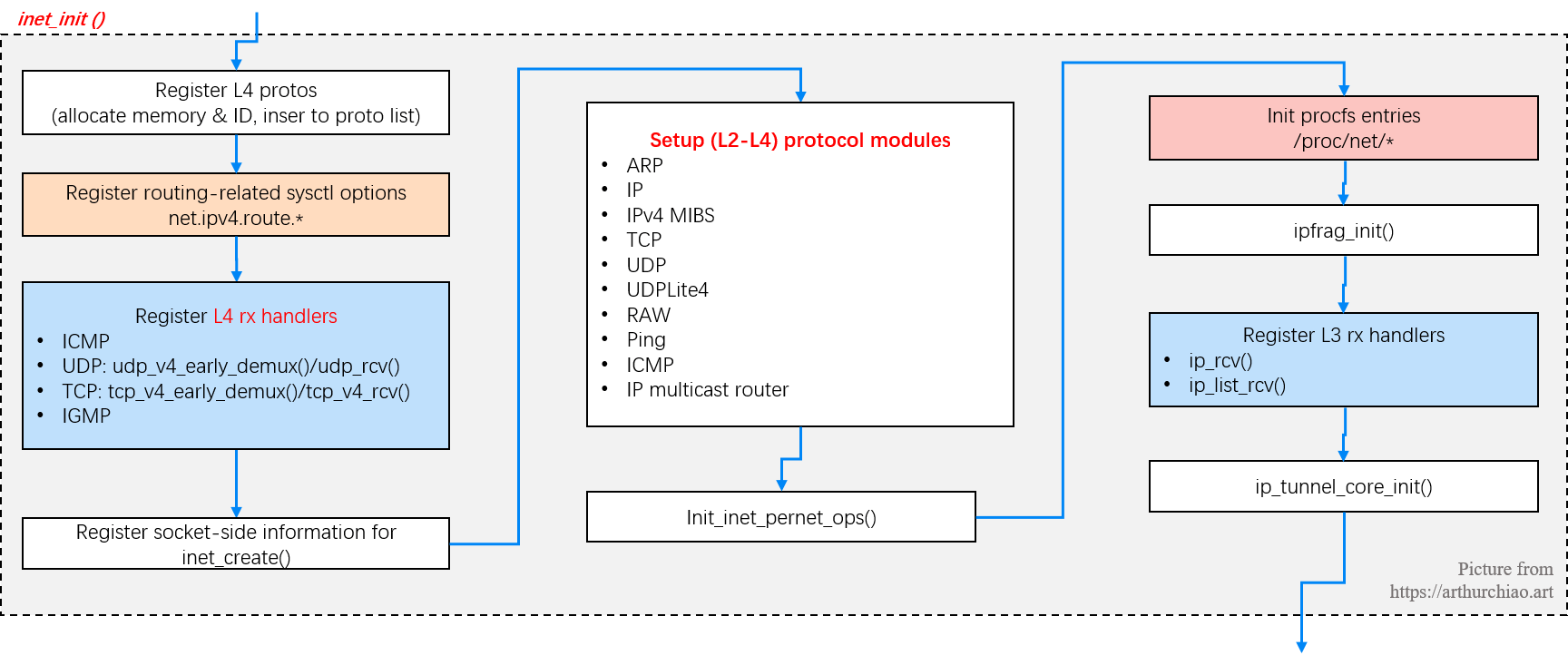
IP 层在函数 inet_init 中将自身注册到 ptype_base 哈希表(前面提到过):
// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/af_inet.c
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
static int __init inet_init(void) {
// 分配各种 L4 协议的内存空间和协议号(proto index),并插入 L4 协议链表
proto_register(&tcp_prot, 1);
proto_register(&udp_prot, 1);
proto_register(&raw_prot, 1);
proto_register(&ping_prot, 1);
(void)sock_register(&inet_family_ops); // Tell SOCKET that we are alive...
ip_static_sysctl_init(); // 注册路由相关的 sysctl 参数:net.ipv4.route.*
// 注册几种基础 L4 协议的 rx handler
inet_add_protocol(&icmp_protocol, IPPROTO_ICMP);
inet_add_protocol(&udp_protocol, IPPROTO_UDP);
inet_add_protocol(&tcp_protocol, IPPROTO_TCP);
inet_add_protocol(&igmp_protocol, IPPROTO_IGMP);
/* Register the socket-side information for inet_create. */
for (struct list_head *r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (struct inet_protosw *q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
// 各种协议模块的初始化
arp_init(); // Set the ARP module up
ip_init(); // Set the IP module up
init_ipv4_mibs(); // Initialise per-cpu ipv4 mibs
tcp_init(); // Setup TCP slab cache for open requests
udp_init(); // Setup UDP memory threshold
udplite4_register(); // Add UDP-Lite (RFC 3828)
raw_init();
ping_init();
icmp_init(); // Set the ICMP layer up
ip_mr_init(); // Initialise the multicast router
init_inet_pernet_ops();
ipv4_proc_init(); // 注册 /proc/net/*, 例如 cat /proc/net/tcp 能看到所有 TCP socket 的状态统计
ipfrag_init();
dev_add_pack(&ip_packet_type); // 注册 L3 rx handler:ip_rcv()/ip_list_rcv()
ip_tunnel_core_init();
}
复制__netif_receive_skb_core 会调用 deliver_skb (前面介绍过了), 后者会调用.func 方法(这里指向 ip_rcv)。
ip_rcv() -> NF_HOOK(PRE_ROUTING, ip_rcv_finish())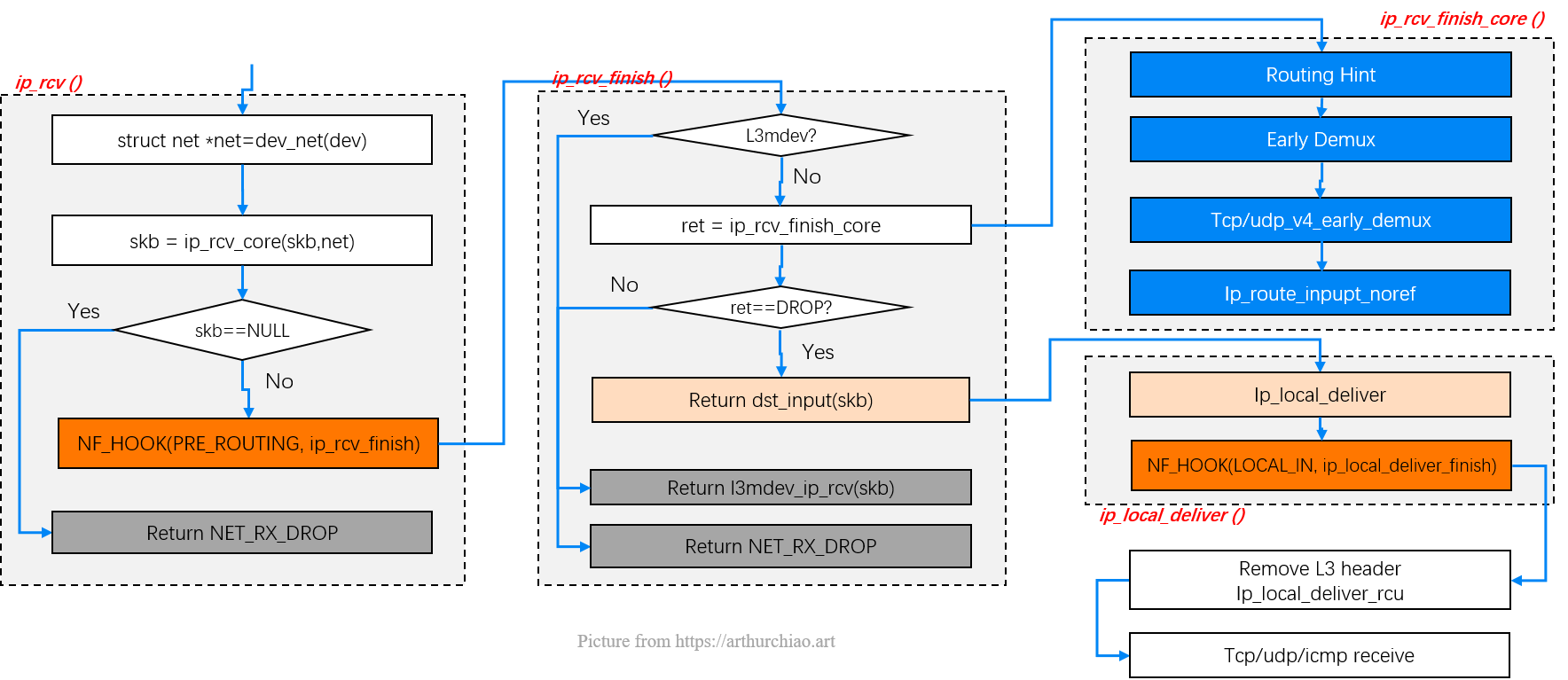
Fig. L3 processing in ip_rcv()
// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/ip_input.c
// IP receive entry point
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) {
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, net, NULL, skb, dev, NULL, ip_rcv_finish);
}
复制ip_rcv() 方法的核心逻辑非常简单直接,就是一些数据合法性验证,统计计数器更新等 等,它在最后会以 netfilter hook 的方式调用 ip_rcv_finish() 方法。 这样任何 iptables 规则都能在 packet 刚进入 IP 层协议的时候被应用,在其他处理之前。
NF_INET_PRE_ROUTING hook注意:netfilter 或 iptables 规则都是在软中断上下文中执行的, 数量很多或规则很复杂时会导致网络延迟。
TC BPF 也是在软中断上下文中, 但要比 netfilter/iptables 规则高效地多,也发生在更前面(能提前返回),所以应尽可能用 BPF。
ip_rcv_finish() -> routing -> dst_entry.input()Netfilter 完成对数据的处理之后,就会调用 ip_rcv_finish() —— 当然,前提是 netfilter 没有丢掉这个包。
// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/ip_input.c
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb) {
struct net_device *dev = skb->dev;
skb = l3mdev_ip_rcv(skb); // if ingress device is enslaved to an L3 master device
if (!skb) // pass the skb to its handler for processing
return NET_RX_SUCCESS;
ret = ip_rcv_finish_core(net, sk, skb, dev, NULL);
if (ret != NET_RX_DROP)
ret = dst_input(skb);
return ret;
}
static int ip_rcv_finish_core(struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *dev, const struct sk_buff *hint) {
const struct iphdr *iph = ip_hdr(skb);
int (*edemux)(struct sk_buff *skb);
struct rtable *rt;
int err;
if (ip_can_use_hint(skb, iph, hint)) {
err = ip_route_use_hint(skb, iph->daddr, iph->saddr, iph->tos, dev, hint);
if (unlikely(err))
goto drop_error;
}
if (net->ipv4.sysctl_ip_early_demux && !skb_dst(skb) && !skb->sk && !ip_is_fragment(iph)) {
const struct net_protocol *ipprot;
int protocol = iph->protocol;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot && (edemux = READ_ONCE(ipprot->early_demux))) {
err = INDIRECT_CALL_2(edemux, tcp_v4_early_demux, udp_v4_early_demux, skb);
if (unlikely(err))
goto drop_error;
/* must reload iph, skb->head might have changed */
iph = ip_hdr(skb);
}
}
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
if (!skb_valid_dst(skb)) {
err = ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, dev);
if (unlikely(err))
goto drop_error;
}
#ifdef CONFIG_IP_ROUTE_CLASSID
if (unlikely(skb_dst(skb)->tclassid)) {
struct ip_rt_acct *st = this_cpu_ptr(ip_rt_acct);
u32 idx = skb_dst(skb)->tclassid;
st[idx&0xFF].o_packets++;
st[idx&0xFF].o_bytes += skb->len;
st[(idx>>16)&0xFF].i_packets++;
st[(idx>>16)&0xFF].i_bytes += skb->len;
}
#endif
if (iph->ihl > 5 && ip_rcv_options(skb, dev))
goto drop;
rt = skb_rtable(skb);
if (rt->rt_type == RTN_MULTICAST) {
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST) {
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INBCAST, skb->len);
} else if (skb->pkt_type == PACKET_BROADCAST ||
skb->pkt_type == PACKET_MULTICAST) {
struct in_device *in_dev = __in_dev_get_rcu(dev);
if (in_dev && IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST))
goto drop;
}
return NET_RX_SUCCESS;
drop:
kfree_skb(skb);
return NET_RX_DROP;
drop_error:
if (err == -EXDEV)
__NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);
goto drop;
}
复制这里做了一个优化。为了能将包送到合适的目的地,需要一个路由 子系统的 dst_entry 变量。为了获取这个变量,早期的代码调用了 early_demux 函数。 early_demux 是一个优化项,通过检查相应的变量是否缓存在 socket 变量上,来路由 这个包所需要的 dst_entry 变量。默认 early_demux 是打开的:
$ sysctl -a |grep early demux
net.ipv4.ip_early_demux = 1 # <-- 这个
net.ipv4.tcp_early_demux = 1
net.ipv4.udp_early_demux = 1
复制如果这个优化打开了,但是并没有命中缓存(例如,这是第一个包),这个包就会被送到内 核的路由子系统,在那里将会计算出一个 dst_entry 并赋给相应的字段。
路由子系统完成工作后,会更新计数器,然后调用 dst_input(skb),后者会进一步调用 dst_entry 变量中的 input 方法,这个方法是一个函数指针,由路由子系统初始化。例如 ,如果 packet 的最终目的地是本机(local system),路由子系统会将 ip_local_deliver 赋 给 input。
ip_local_deliver()回忆我们看到的 IP 协议层过程:
ip_local_deliver_finish(),将数据包送到协议栈的更上层ip_local_deliver 的逻辑与此类似:
// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/ip_input.c
// Deliver IP Packets to the higher protocol layers.
int ip_local_deliver(struct sk_buff *skb) {
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, net, NULL, skb, skb->dev, NULL, ip_local_deliver_finish);
}
复制只要 packet 没有在 netfilter 被 drop,就会调用 ip_local_deliver_finish 函数。
ip_local_deliver_finish() -> ip_protocol_deliver_rcu() -> l4proto.callback// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/ip_input.c
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb) {
__skb_pull(skb, skb_network_header_len(skb));
ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol); // 没有返回值,错误在内部处理
return 0; // 永远返回成功
}
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol) {
resubmit:
int raw = raw_local_deliver(skb, protocol); // 处理 raw socket case,也就是不是 TCP/UDP 等等协议
struct net_protocol *ipprot = inet_protos[protocol];
if (ipprot) {
if (!ipprot->no_policy) {
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
kfree_skb(skb);
return;
}
nf_reset_ct(skb);
}
ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv, skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
} else {
if (!raw) {
if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
__IP_INC_STATS(net, IPSTATS_MIB_INUNKNOWNPROTOS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0);
}
kfree_skb(skb);
} else {
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
consume_skb(skb);
}
}
}
复制ip_local_deliver_finish 从数据包中读取协议,寻找注册在这个协议上的 struct net_protocol 变量,并调用该变量中的回调方法。这样将包送到协议栈的更上层。
根据上层协议类型选择不同的 callback 函数把数据收走:
tcp_v4_rcvudp_v4_rcvicmp_send现在来到了图中第 9 步:
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
四层协议的处理,这里以 UDP 为例,因为它比较简单。TCP 太复杂了,得单独写一篇。
UDP 和 UDP-Lite 都会执行哈希表的创建,
// net/ipv4/udp.c
void __init udp_table_init(struct udp_table *table, const char *name) {
table->hash = alloc_large_system_hash(name,
2 * sizeof(struct udp_hslot),
uhash_entries,
21, /* one slot per 2 MB */
0,
&table->log,
&table->mask,
UDP_HTABLE_SIZE_MIN,
64 * 1024);
...
}
复制传过来的 name 分别是 UDP 和 UDP-Lite。 alloc_large_system_hash() 在哈希表创建成功之后会打印哈希表的信息:
// mm/page_alloc.c
pr_info("%s hash table entries: %ld (order: %d, %lu bytes, %s)\n",
tablename, 1UL << log2qty, ilog2(size) - PAGE_SHIFT, size,
virt ? "vmalloc" : "linear");
复制$ dmesg -T | grep "hash table entries" | grep UDP
[Thu Jul 28 15:37:27 2022] UDP hash table entries: 65536 (order: 9, 2097152 bytes, vmalloc)
[Thu Jul 28 15:37:27 2022] UDP-Lite hash table entries: 65536 (order: 9, 2097152 bytes, vmalloc)
复制udp_v4_early_demux()/udp_v4_rcv()在 net/ipv4/af_inet.c 中定义了 UDP、TCP 和 ICMP 协议的回调函数相关的数据结构,IP 层处 理完毕之后会调用相应的回调。
// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/af_inet.c
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
static struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.early_demux_handler = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.err_handler = icmp_err,
.no_policy = 1,
.netns_ok = 1,
};
复制这些变量在 inet 地址族初始化时通过 inet_add_protocol()注册:
// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/af_inet.c
static int __init inet_init(void) {
...
// Add all the base protocols.
inet_add_protocol(&icmp_protocol, IPPROTO_ICMP);
inet_add_protocol(&udp_protocol, IPPROTO_UDP);
inet_add_protocol(&tcp_protocol, IPPROTO_TCP);
inet_add_protocol(&igmp_protocol, IPPROTO_IGMP);
...
}
复制上面可以看到,UDP 的回调函数是 udp_rcv(),这是从 IP 层进入 UDP 层的入口。我们就从这里开始探索四层协议处理。
udp_rcv() -> __udp4_lib_rcv()// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/udp.c
int udp_rcv(struct sk_buff *skb) {
return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
}
复制这个函数只要一行, 调用 __udp4_lib_rcv() 接收 UDP 报文, 其中指定了协议类型是 IPPROTO_UDP;这是因为 __udp4_lib_rcv() 封装了两种 UDP 协议的处理:
IPPROTO_UDPIPPROTO_UDPLITE__udp4_lib_rcv() -> udp_unicast_rcv_skb()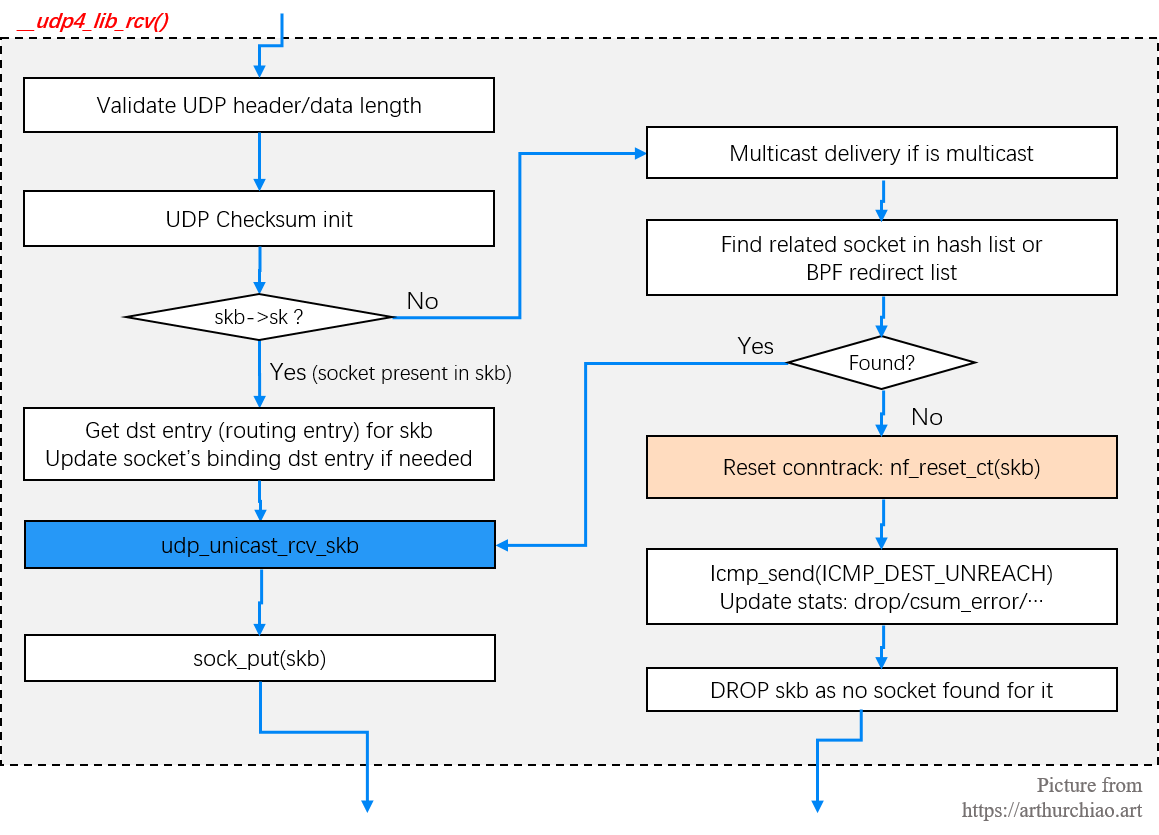
Fig. __udp4_lib_rcv()
// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/udp.c
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable, int proto) {
pskb_may_pull(skb, sizeof(struct udphdr);
struct udphdr *uh = udp_hdr(skb);
unsigned short ulen = ntohs(uh->len);
saddr = ip_hdr(skb)->saddr;
daddr = ip_hdr(skb)->daddr;
if (proto == IPPROTO_UDP) {
if (ulen < sizeof(*uh) || pskb_trim_rcsum(skb, ulen)) // UDP validates ulen.
goto short_packet;
uh = udp_hdr(skb); // 如果是 UDP 而非 UDPLITE,需要再次获取 UDP header
}
udp4_csum_init(skb, uh, proto);
// 如果能直接从 skb 中获取 sk 信息(skb->sk 字段)
bool refcounted;
struct sock *sk = skb_steal_sock(skb, &refcounted);
if (sk) {
struct dst_entry *dst = skb_dst(skb);
if (unlikely(sk->sk_rx_dst != dst))
udp_sk_rx_dst_set(sk, dst);
ret = udp_unicast_rcv_skb(sk, skb, uh);
if (refcounted)
sock_put(sk);
return ret;
}
// 不能从 skb->sk 获取 socket 信息
struct net *net = dev_net(skb->dev);
struct rtable *rt = skb_rtable(skb);
if (rt->rt_flags & (RTCF_BROADCAST|RTCF_MULTICAST))
return __udp4_lib_mcast_deliver(net, skb, uh, saddr, daddr, udptable, proto);
// 从 udp hash list 中搜索有没有关联的 socket,或者查看有没有 BPF redirect socket
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk)
return udp_unicast_rcv_skb(sk, skb, uh);
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto drop;
nf_reset_ct(skb);
if (udp_lib_checksum_complete(skb)) /* No socket. Drop packet silently, if checksum is wrong */
goto csum_error;
__UDP_INC_STATS(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
// We got an UDP packet to a port to which we don't wanna listen. Ignore it.
kfree_skb(skb);
return 0;
}
复制__udp4_lib_rcv 首先对包数据进行合法性检查,获取 UDP 头、UDP 数据报长度、源地址、目 标地址等信息。然后进行其他一些完整性检测和 checksum 验证。
回忆前面的 IP 层内容,在送到更上面一层协议(这里是 UDP)之前,会将一个 dst_entry 会关联到 skb。
如果对应的 dst_entry 找到了,并且有对应的 socket,__udp4_lib_rcv 会将 packet 放到 socket 的接收队列; 如果 socket 没有找到,数据报(datagram)会被丢弃。
udp_unicast_rcv_skb() -> udp_queue_rcv_skb()如果对应的 dst_entry 找到了,并且有对应的 socket,__udp4_lib_rcv 会将 packet 放到 socket 的接收队列; 如果 early_demux 中没有关联 socket 信息,那此时会调用__udp4_lib_lookup_skb 查找对应的 socket。
以上两种情况,最后都会将 packet 放到 socket 的接收队列:
// wrapper for udp_queue_rcv_skb tacking care of csum conversion and
// return code conversion for ip layer consumption
static int udp_unicast_rcv_skb(struct sock *sk, struct sk_buff *skb, struct udphdr *uh) {
if (inet_get_convert_csum(sk) && uh->check && !IS_UDPLITE(sk))
skb_checksum_try_convert(skb, IPPROTO_UDP, inet_compute_pseudo);
udp_queue_rcv_skb(sk, skb);
}
复制udp_queue_rcv_skb() -> udp_queue_rcv_one_skb() -> __udp_queue_rcv_skb()判断 queue 未满之后,就会将数据报放到里面: net/ipv4/udp.c:
static int udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb) {
struct sk_buff *next, *segs;
if (likely(!udp_unexpected_gso(sk, skb)))
return udp_queue_rcv_one_skb(sk, skb);
__skb_push(skb, -skb_mac_offset(skb));
segs = udp_rcv_segment(sk, skb, true);
skb_list_walk_safe(segs, skb, next) {
__skb_pull(skb, skb_transport_offset(skb));
ret = udp_queue_rcv_one_skb(sk, skb);
if (ret > 0)
ip_protocol_deliver_rcu(dev_net(skb->dev), skb, ret);
}
return 0;
}
/* returns:
* -1: error
* 0: success
* >0: "udp encap" protocol resubmission
*
* Note that in the success and error cases, the skb is assumed to
* have either been requeued or freed.
*/
static int udp_queue_rcv_one_skb(struct sock *sk, struct sk_buff *skb) {
struct udp_sock *up = udp_sk(sk);
int is_udplite = IS_UDPLITE(sk);
// Charge it to the socket, dropping if the queue is full.
if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb))
goto drop;
nf_reset_ct(skb);
if (static_branch_unlikely(&udp_encap_needed_key) && up->encap_type) {
int (*encap_rcv)(struct sock *sk, struct sk_buff *skb);
/* if we're overly short, let UDP handle it */
encap_rcv = READ_ONCE(up->encap_rcv);
if (encap_rcv) {
int ret;
/* Verify checksum before giving to encap */
if (udp_lib_checksum_complete(skb))
goto csum_error;
ret = encap_rcv(sk, skb);
if (ret <= 0) {
__UDP_INC_STATS(sock_net(sk), UDP_MIB_INDATAGRAMS, is_udplite);
return -ret;
}
}
/* FALLTHROUGH -- it's a UDP Packet */
}
prefetch(&sk->sk_rmem_alloc);
if (rcu_access_pointer(sk->sk_filter) &&
udp_lib_checksum_complete(skb))
goto csum_error;
if (sk_filter_trim_cap(sk, skb, sizeof(struct udphdr)))
goto drop;
udp_csum_pull_header(skb);
ipv4_pktinfo_prepare(sk, skb);
return __udp_queue_rcv_skb(sk, skb);
csum_error:
__UDP_INC_STATS(sock_net(sk), UDP_MIB_CSUMERRORS, is_udplite);
drop:
__UDP_INC_STATS(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
atomic_inc(&sk->sk_drops);
kfree_skb(skb);
return -1;
}
复制这个函数的前面部分所做的工作:
__udp_queue_rcv_skb() -> __skb_queue_tail() -> socket's receive queue// https://github.com/torvalds/linux/blob/v5.10/net/ipv4/udp.c
static int __udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb) {
if (inet_sk(sk)->inet_daddr) {
sock_rps_save_rxhash(sk, skb);
sk_mark_napi_id(sk, skb);
sk_incoming_cpu_update(sk);
} else {
sk_mark_napi_id_once(sk, skb);
}
rc = __udp_enqueue_schedule_skb(sk, skb);
if (rc < 0) {
int is_udplite = IS_UDPLITE(sk);
/* Note that an ENOMEM error is charged twice */
if (rc == -ENOMEM)
UDP_INC_STATS(sock_net(sk), UDP_MIB_RCVBUFERRORS, is_udplite);
UDP_INC_STATS(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
kfree_skb(skb);
trace_udp_fail_queue_rcv_skb(rc, sk);
return -1;
}
return 0;
}
int __udp_enqueue_schedule_skb(struct sock *sk, struct sk_buff *skb) {
struct sk_buff_head *list = &sk->sk_receive_queue;
int rmem, delta, amt, err = -ENOMEM;
spinlock_t *busy = NULL;
int size;
rmem = atomic_read(&sk->sk_rmem_alloc);
if (rmem > sk->sk_rcvbuf) // try to avoid the costly atomic add/sub pair when the receive queue is full; always allow at least a packet
goto drop;
// Under mem pressure, it might be helpful to help udp_recvmsg() having linear skbs :
// - Reduce memory overhead and thus increase receive queue capacity
// - Less cache line misses at copyout() time
// - Less work at consume_skb() (less alien page frag freeing)
if (rmem > (sk->sk_rcvbuf >> 1)) {
skb_condense(skb);
busy = busylock_acquire(sk);
}
size = skb->truesize;
udp_set_dev_scratch(skb);
// we drop only if the receive buf is full and the receive queue contains some other skb
rmem = atomic_add_return(size, &sk->sk_rmem_alloc);
if (rmem > (size + (unsigned int)sk->sk_rcvbuf))
goto uncharge_drop;
if (size >= sk->sk_forward_alloc) {
amt = sk_mem_pages(size);
delta = amt << SK_MEM_QUANTUM_SHIFT;
if (!__sk_mem_raise_allocated(sk, delta, amt, SK_MEM_RECV)) {
err = -ENOBUFS;
spin_unlock(&list->lock);
goto uncharge_drop;
}
sk->sk_forward_alloc += delta;
}
sk->sk_forward_alloc -= size;
// no need to setup a destructor, we will explicitly release the forward allocated memory on dequeue
sock_skb_set_dropcount(sk, skb);
__skb_queue_tail(list, skb); // 将这个 skb 插入 socket 的接收队列 sk->sk_receive_queue
if (!sock_flag(sk, SOCK_DEAD))
sk->sk_data_ready(sk);
busylock_release(busy);
return 0;
uncharge_drop:
atomic_sub(skb->truesize, &sk->sk_rmem_alloc);
drop:
atomic_inc(&sk->sk_drops);
busylock_release(busy);
return err;
}
复制网络数据通过 __skb_queue_tail() 进入 socket 的接收队列,在此之前,会做几件事情:
sk_filter,这允许在 socket 上执行 BPF 程序;sk_rmem_scedule,确保有足够大的 receive buffer 接收这个数据报skb_set_owner_r,这会计算数据报的长度并更新 sk->sk_rmem_alloc 计数__skb_queue_tail 将数据加到队列尾端最后,所有在这个 socket 上等待数据的进程都收到一个通知通过 sk_data_ready 通知处理 函数。
以上 1~9 章,就是一个数据包从到达机器开始,依次穿过协议栈,到达 socket 的过程。
还有一些值得讨论的问题,放在前面哪里都不太合适,统一放到这里。
前面提到,网络栈可以收集包的时间戳信息。如果使用了 RPS 功能,有相应的 sysctl 参数 可以控制何时以及如何收集时间戳;一些网卡甚至支持在硬件上打时间戳。 如果想看内核网络栈给收包增加了多少延迟,那这个特性非常有用。
内核关于时间戳的文档 非常优秀,甚至还包括一个示例程序和相应的 Makefile,有兴趣的话可以上手试试。
使用 ethtool -T 可以查看网卡和驱动支持哪种打时间戳方式:
$ sudo ethtool -T eth0
Time stamping parameters for eth0:
Capabilities:
software-transmit (SOF_TIMESTAMPING_TX_SOFTWARE)
software-receive (SOF_TIMESTAMPING_RX_SOFTWARE)
software-system-clock (SOF_TIMESTAMPING_SOFTWARE)
PTP Hardware Clock: none
Hardware Transmit Timestamp Modes: none
Hardware Receive Filter Modes: none
复制从上面这个信息看,该网卡不支持硬件打时间戳。但这个系统上的软件打时间戳,仍然可以 帮助判断内核在接收路径上到底带来多少延迟。
socket 有个 SO_BUSY_POLL 选项,可以让内核在阻塞式接收(blocking receive) 时做 busy poll。这个选项会减少延迟,但会增加 CPU 使用量和耗电量。
重要提示:要使用此功能,首先要检查设备驱动是否支持。 如果驱动实现(并注册)了 struct net_device_ops 的 ndo_busy_poll() 方法,那就是支持。
Intel 有一篇非常好的文章介绍其原理。
对单个 socket 设置此选项,需要传一个以微秒(microsecond)为单位的时间,内核会 在这个时间内对设备驱动的接收队列做 busy poll。当在这个 socket 上触发一个阻塞式读请 求时,内核会 busy poll 来收数据。
全局设置此选项,可以修改 sysctl 配置项:
$ sudo sysctl -a | grep busy_poll
net.core.busy_poll = 0
复制注意这并不是一个 flag 参数,而是一个毫秒(microsecond)为单位的时间长度,当 poll 或 select 方 法以阻塞方式调用时,busy poll 的时长就是这个值。
Linux 内核提供了一种方式,在内核挂掉(crash)时,设备驱动仍然可以接收和发送数据, 相应的 API 被称作 Netpoll。这个功能在一些特殊的网络场景有用途,两个著名的例子:
netconsole 的说明:
This module logs kernel printk messages over UDP allowing debugging of problem where disk logging fails and serial consoles are impractical.
It can be used either built-in or as a module. As a built-in, netconsole initializes immediately after NIC cards and will bring up the specified interface as soon as possible. While this doesn’t allow capture of early kernel panics, it does capture most of the boot process.
大部分驱动都支持 Netpoll 功能。支持此功能的驱动需要实现 struct net_device_ops 的 ndo_poll_controller 方法。
想进一步了解其使用方式,可在内核代码中 grep -R netpoll_ net/*。
SO_INCOMING_CPU:判断哪个 CPU 在处理给定 socketgetsockopt(SO_INCOMING_CPU) 可以判断当前哪个 CPU 在处理这个 socket 的网络包。 应用程序可以据此将 socket 交给在期望的 CPU 上运行的线程,增加数据本地性( data locality)和缓存命中率。
SO_INCOMING_CPU 的patch 里有一个简单示例,展示在什么场景下使用这个功能。
DMA engine 是一个硬件,允许 CPU 将大的数据复制操作下放(offload)给它,
优点:将 CPU 从复制数据中解放出来,去做其他事情。
使用 DMA 引擎需要代码做适配,调用它的 API。Linux 内核有一个通用的 DMA 引擎 接口,DMA engine 驱动实现这个接口即可。更多信息参考内核文档 Documentation/driver-api/dmaengine。
缺点:有数据损坏的风险。
具体例子:Intel 的 IOAT DMA engine。
Linux 网络栈很复杂。 对于这样复杂的系统(以及类似的其他系统),如果不能在更深的源码层次上理解它正在 做什么,就无法做好监控和调优;而有了对内核网络栈的完整理解,就会发现一片新天地, 对于一些哪怕是“常规问题”的解决,也会有不一样的认识。