https://zhuanlan.zhihu.com/p/527034350
目录
1 服务器与CPU技术综述
1.1 服务器综述
1.1.1 服务器的发展历史
1.1.2 服务器的组成
1.1.3 服务器的分类
1.1.4 服务器集群与冗余技术
1.1.5 虚拟化技术
1.2 CPU综述
1.2.1 CPU的组成
1.2.2 CPU与GPU和DPU的分工
1.2.3 CPU指令集
2 服务器CPU架构概况
2.1 服务器CPU的架构分类
2.2 CISC-x86
2.3 RISC- ARM
2.4 RISC-V
2.5 其他
2.5.1 Alpha
2.5.2 MIPS
2.5.3 SPARC
3 服务器软件生态
3.1 操作系统
3.2 LLVM
3.3 (运行)库
3.4 云计算/容器/虚拟化
3.5 数据库/中间件
4 服务器CPU演进趋势
4.1 CPU优化的传统方向
4.1.1 工艺制程提升
4.1.2 并行度(核数)提升
4.1.3 缓存提升
4.1.4 专用指令集
4.2 CPU提升性能的新趋势
4.2.1 HBM与Chiplet
4.2.2 异构集成
4.2.3 存算一体
4.2.4 动态可重构/软件定义芯片
5 服务器CPU市场
5.1 服务器CPU产业链
5.2 服务器CPU市场规模
5.3 竞争格局
5.4 主要国外厂商
5.4.1 Intel
5.4.2 AMD
5.4.3 Amazon
5.4.4 SiFive
6 国产服务器CPU的市场机遇
6.1 国产服务器CPU发展路线
6.2 国内数字化需求
6.2.1 新基建
6.2.2 东数西算
6.2.3 5G与边缘计算
6.3 自主技术替代需求
6.4 互联网大厂的元宇宙布局
6.5 高端CPU与IP核心技术稀缺
7 国产服务器CPU厂商
7.1 x86架构:兆芯、海光
7.2 RISC-V架构:睿思芯科、赛昉、平头哥
7.3 ARM架构:飞腾、鲲鹏
7.4 MIPS架构:龙芯
7.5 Alpha架构:申威
一直以来,服务器CPU都倾向于使用最先进的技术来提升性能,进而提供更强大的计算支持。本章将介绍服务器CPU的技术演进趋势,包括CPU优化和性能提升的传统方式与最新趋势。
CPU优化的传统方式包括工艺制程的提升、并行度提升、缓存提升、专用化等方法。除了专用化之外,上述方法已经在CPU甚至GPU中广泛使用。
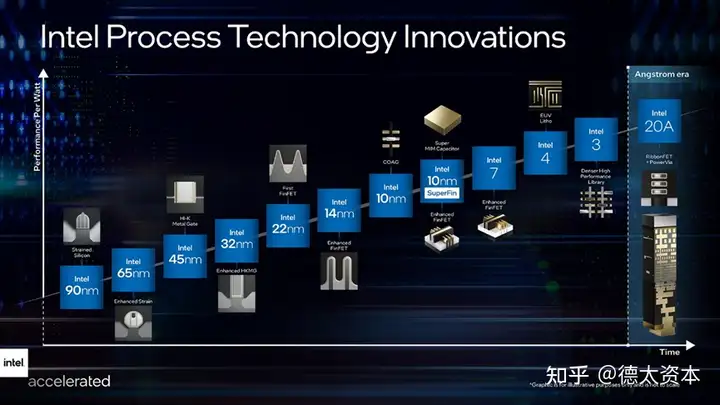
根据摩尔定律,集成电路芯片上所集成的电路数目每隔18个月翻一番, 微处理器性能每隔18个月提高一倍。 CPU的制程工艺越先进,意味着单个晶体管的尺寸越小,同样的内核面积可以放下更多的晶体管,同样的芯片空间内可以增加更多内核;同时制程工艺越先进,电流在晶体管中的传输距离就越短,晶体管和互连线的电容负载就越小, CPU的主频可以进一步提升,功耗也能不断降低。
在这一基础上,通过工艺制程的提升,芯片内的计算速度加快,同时可以在芯片内集成更多的计算单元(例如ALU),进而提升CPU的整体性能。
在摩尔定律正常推进的很长一段时间,工艺制程提升都是CPU演进的一条关键路径。
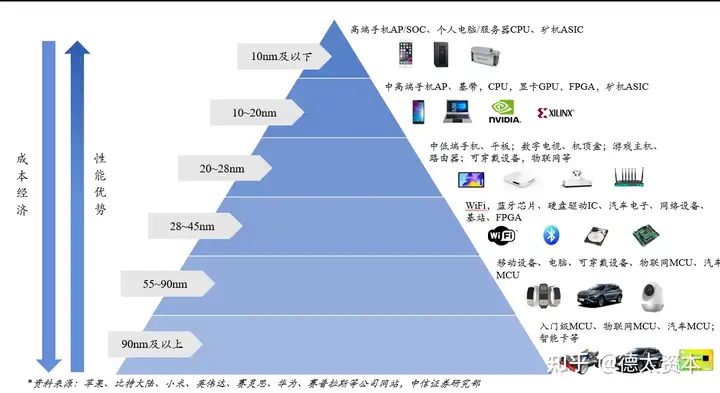
处理器性能提升主要两个途径,一是提高处理器主频,二是提高IPC(每时钟指令数,Instruction Per Clock)。通常IPC的提高可以通过对处理器微架构的调整来完成,但是提升幅度有限。而通过提高处理器主频率从而提升性能的方式为最显著有效,但同样面临触及频率墙的问题。针对以上的限制,处理器厂商最终发现通过提高指令执行的并行度来提高IPC是最为有效且瓶颈低。
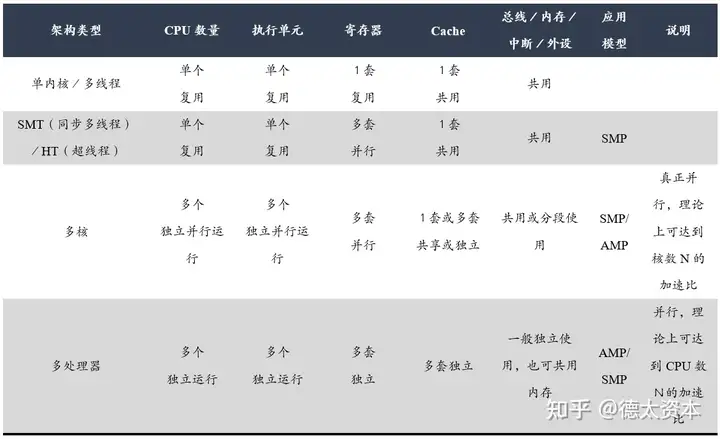
提高并行度主要由两种方式:1. 提高微架构的指令并行度;2. 采用多核并发。
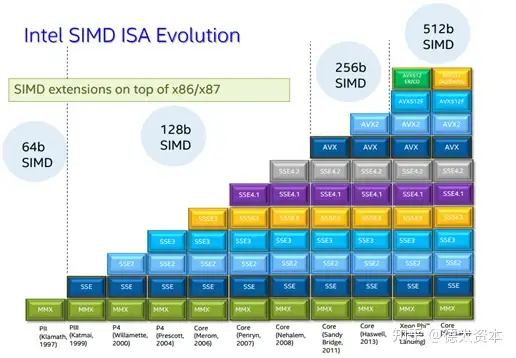
(1)SIMD
提高并行度一个典型的例子就是SIMD(单指令多数据)。 SIMD 是一种CPU核心内的并行处理指令。计算单元在SIMD指令下执行完全相同的操作,但是使用不同的数据,以此提升CPU数据处理能力。形象的说,SIMD就好像是一个班长下命令,一个班的物流工人整齐划一的搬运不同的货物。大多数现代CPU设计都包含 SIMD 指令,以提高多媒体计算性能。
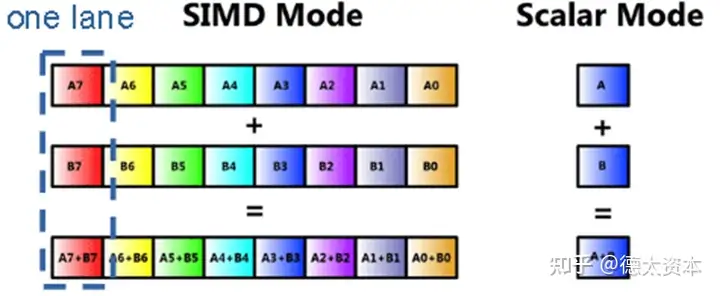
在现代处理器中通常有三种 SIMD 指令架构:
矢量计算架构使用包含多达 64 或 128 个矢量元素的矢量寄存器进行操作,将来自矢量寄存器的数据作为输入,批量执行算术和逻辑运算。
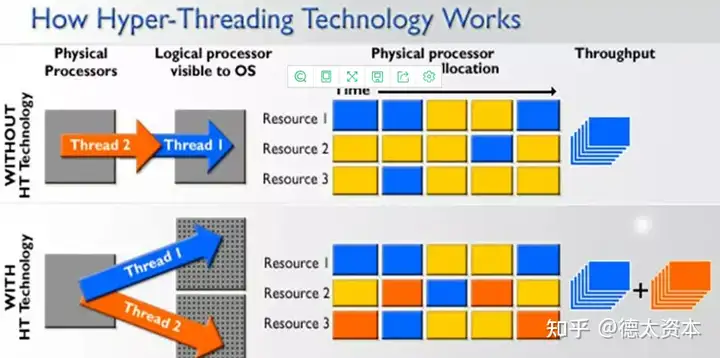
(2)超线程
除了SMID,超线程(Hyper-Threading)也是提升并行度的非常有效的技术。通过超线程,可以将空闲的计算单元用于其他线程的计算,进而提升整体计算速度。
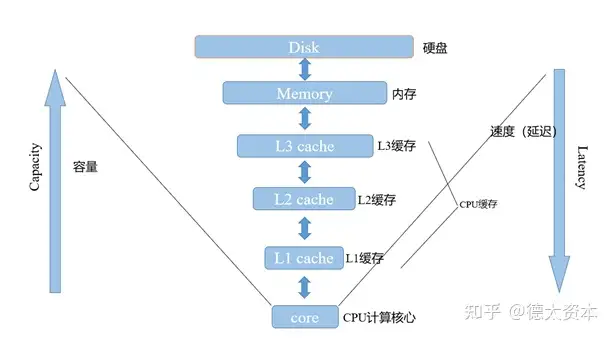
Cache(缓存)在存储层次结构中位于CPU的ALU和内存之间。相对而言,内存的访问速度比缓存慢很多。当CPU处理数据时,会先从Cache中访问,若数据因历史操作而已经暂存在其中,CPU则不需要再从主存中读取数据。除此之外,使用硬件实现的分支预测与数据预提取技术可以提升CPU访问内存的速度。提供Cache的目的是为了让数据的访问速度适应CPU的处理速度,因此,cache的性能和大小会对CPU的性能产生直接的影响。
各级缓存,内存,硬盘与CPU架构图:
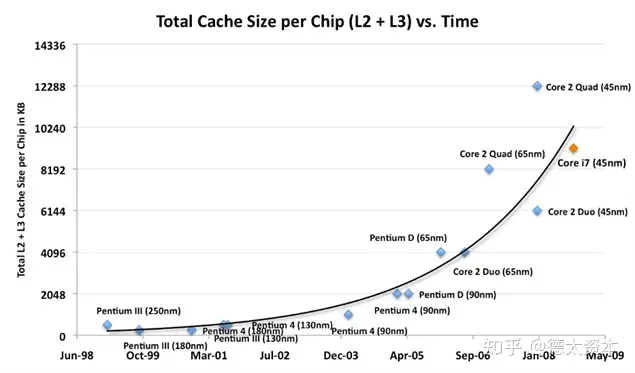
通过Intel CPU缓存发展的历史可以看到,随着CPU技术的进步,CPU片上缓存的大小有着显著的提升,且提升的增速在加大。
专用指令使编程人员能够通过特定的指令连续以最优的方式操作处理器的流水线、寄存器架构和专用加速器,完成特定的复杂操作。
专用指令一般可以调用处理器中的专用加速器,执行使用频繁的工作任务。例如卷积计算、快速傅里叶变换等都可以通过专用指令和对应的加速器进行加速,提升CPU的处理能力。
Intel CPU架构的SSE指令集就是典型的专用指令集,可以显著提升3D几何运算、图形处理、视频编辑/压缩/解压、语音识别以及声音压缩和合成等应用的速度。
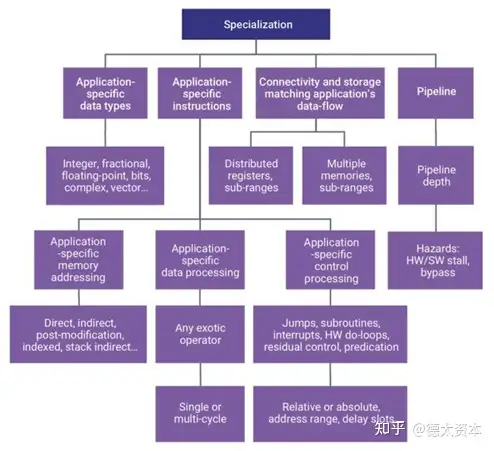
在传统的并行度提升和专用指令集之外,还有一些新兴的技术,可以帮助CPU获得更显著的性能提升,这些技术包括Chiplet技术、异构集成技术、存算一体技术与动态可重构技术。
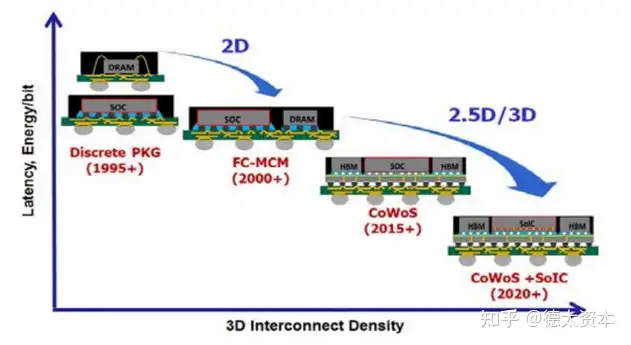
本节将首先介绍Chiplet(芯粒)技术的总体情况,然后通过Chiplet技术在内存中的典型代表HBM、Chiplet中的典型封装技术CoWoS和新兴的Chiplet接口技术UCIe,多维度的介绍Chiplet技术对CPU性能提升的助力。
(1)Chiplet
按照摩尔定律,芯片晶体管数量每24个月翻一倍,这对CPU,GPU,FPGA和DSA依然有效。随着芯片算力呈指数级增长,芯片尺寸逐渐超出光刻掩模版尺寸,系统级封装(System on Package,SoP),特别是Chiplet技术,成为维持摩尔定律,超越掩模版限制的有效方式。(Y. H. Chen et al., 2020)。
早在2015年,Marvell创始人周秀文(Sehat Sutardja)博士就在ISSCC 2015上提出MoChi(Modular Chip,模块化芯片)概念。随后,AMD以实现性能、功耗和成本的平衡为目标,推行Chiplet设计, 并提出performance/W和performance/$衡量标准。
Chiplet有望解决目前半导体产业面临四大难题:
而封装技术从2D逐渐发展到2.5D和3D,集成电路从扩大面积和立体发展两条路来提升整体性能。
(2)HBM:Chiplet之高带宽内存
HBM是一种标准化的堆叠高带宽内存技术,它为堆栈内以及内存和逻辑之间的数据提供了快速通道。基于HBM的封装将内存堆在一起,并使用TSV将它们连接起来,这样创建了更多的I/O和带宽。HBM也是一种JEDEC标准,它垂直集成了多个层次的DRAM组件,这些组件与应用程序处理器、GPU和SoC封装在一起。HBM主要在高端服务器和网络芯片的2.5D封装中应用;它现在已经发展到HBM3技术。
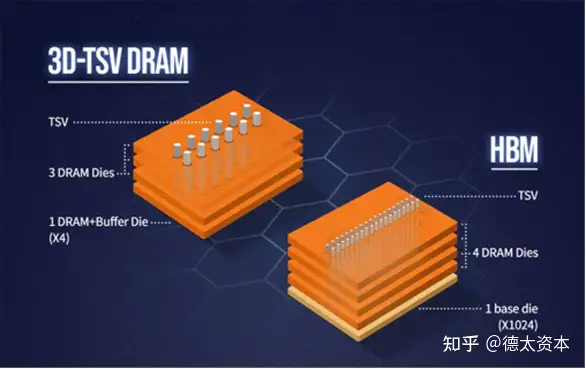
凭借TSV方式,HBM大幅提高了容量和数据传输速率,与传统内存技术相比,HBM具有更高带宽、更多I/O数量、更低功耗、更小尺寸,可应用于高性能计算(HPC)、超级计算机、大型数据中心、人工智能/深度学习、云计算等领域。
(3)CoWoS:Chiplet之封装技术
CoWoS(Chip-on-Wafer-on-Substrate)是台积电推出的 2.5D封装技术,CoWoS是把芯片封装到硅转接板(中介层)上,并使用硅转接板上的高密度布线进行互连,然后再安装在封装基板上,如下图所示:
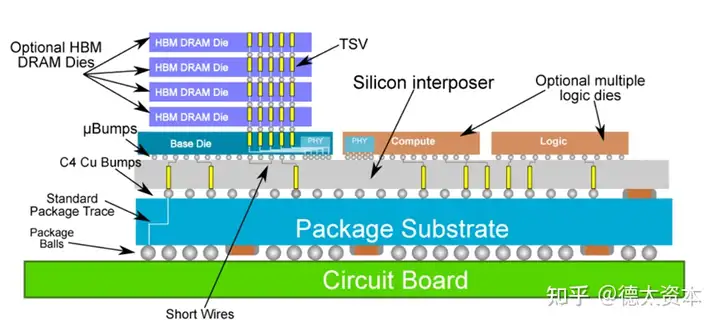
台积电2012年就开始量产CoWoS,通过该技术把多颗芯片封装到一起,通过Silicon Interposer高密度互连,达到了封装体积小,性能高、功耗低,引脚少的效果。CoWoS技术应用很广泛,英伟达的GP100、战胜柯洁的AlphaGo背后的Google芯片TPU2.0都是采用CoWoS技术,人工智能AI的背后也是有CoWoS的贡献。目前,CoWoS已经获得NVIDIA、AMD、Google、XilinX、华为海思等高端芯片厂商的支持。
其中,最近苹果发布的电脑芯片M1 Ultra,将两个M1 Max芯片进行拼接,使芯片各项硬件指标性能翻倍,其背后关键技术架构—UltraFusion,就是最先进的Chiplet封装技术。从M1 Ultra发布的Ultra Fusion图示评估,UltraFusion是基于台积电CoWos Chiplet技术的互联架构。
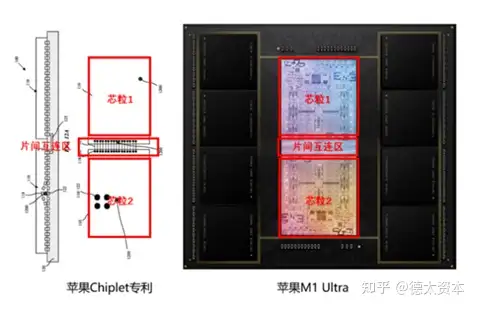
(4)UCIe:Chiplet之接口标准
UCIe标准是由日月光,AMD,arm,Google Cloud,Intel,Meta,微软,高通,三星和台积电共同设立,以建设晶片之间通用组件互联传输标准,培育一个开放的芯粒(Chiplet)系统来满足客户对更多定制化整合封装技术的诉求,是链接可互操作和多重供应商生态系统的晶片之间的互联和协议。
类似于PC机中的PCIe标准,UCIe相当于芯片间的PCIe协议,可以将多个芯粒进行系统级的单一接口的整合。
在UCIe框架下,各种不同工艺,功能的Chiplet芯片,可以通过2D,2.5D,3D等各种封装技术进行整合,多种形态的处理器共同组成超大规模的复杂芯片系统,其具有高带宽,低延迟,经济节能等优点。

异构集成:主要指将多个不同架构的系统、芯片或模组整合,以增强功能性和提高性能。
异构集成有三个层次:首先,在芯片级(设备级)存在异构集成。其次,在系统级别存在异构集成。第三,软件层面的异构集成。
芯片级的异构集成与Chiplet技术有一定相关性,例如将不同厂商的7nm、10nm、28nm、45nm的不同架构的芯粒通过Chiplet技术封装在一起,可以视为基于Chiplet技术的异构集成。
与CPU相关的常见异构集成有以下几种:
(1)CPU+GPU
CPU + GPU 是一个强大的组合,因为 CPU 包含几个专为串行处理而优化的核心,而 GPU 则由数以千计更小、更节能的核心组成,这些核心专为提供强劲的并行性能而设计。程序的串行部分在 CPU 上运行,而并行部分则在 GPU上运行。GPU 已经发展到成熟阶段,可轻松执行现实生活中的各种应用程序,而且程序运行速度已远远超过使用多核系统时的情形。未来计算架构将是并行核心 GPU 与多核 CPU 共同运行的混合型系统。
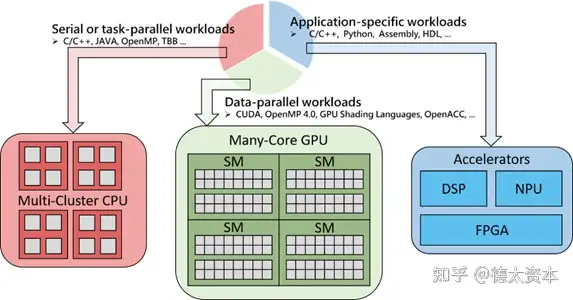
(2)CPU+FPGA
FPGA即现场可编程门阵列芯片。在FPGA芯片内集成了大量数字电路基本门电路、存储器以及互连线资源,用户可以通过对FPGA进行编程,来定义内部的门电路功能以及模块之间的连线,具有高空间并发和低时延的特点。最大的特点是可重构,实现性能优化和功能改变。在处理特定类型的海量数据计算的时候,FPGA相较于CPU和GPU计算效率更高。
(3)CPU+NPU
神经处理器( NPU )是一种专用电路,实现了执行人工智能算法所需的所有必要控制和算术逻辑。
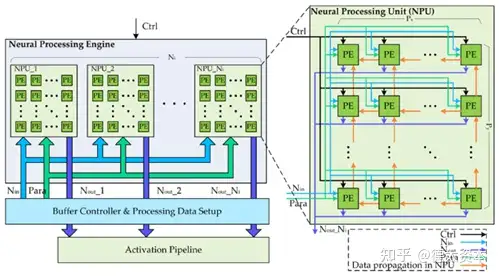
执行深度神经网络(例如卷积神经网络)意味着执行大量的乘法累加运算,通常需要数十亿和数万亿次迭代。而这些计算往往是可以高度并行化的,可以通过NPU进行极大的针对深度学习的计算速度提升,可提升处理器对于人脸识别、图形分类等算法的计算速度与能效。

存算一体(Computing in Memory)是在存储器中嵌入计算能力,以新的运算架构进行二维和三维矩阵乘法/加法运算。
存算一体技术直接利用存储器进行数据处理或计算,把数据存储与计算融合在同一个芯片的同一片区域中,从而实现彻底突破“冯氏”计算架构瓶颈,尤其适用于深度学习神经网络这种海量数据大规模并行的应用场景。
存算一体的优势包括:
存算一体对CPU性能提升的表现:
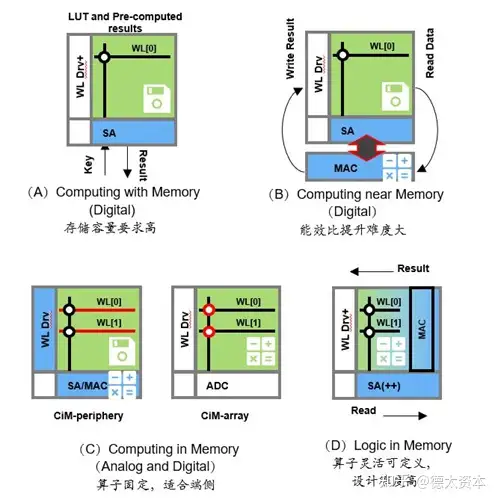
存算一体技术可以分为查存计算,近存计算,存内计算,存内逻辑。
其中近存计算已开始应用于先进CPU,存内计算和存内逻辑技术将在未来逐渐成为主力的算力芯片技术。
(1)近存计算
AMD Zen系列CPU就是存算一体技术中的近存计算架构的典型代表。以AMD Zen3为例,AMD 的 3D V-Cache 技术将一个 64 兆字节的 SRAM 缓存 [红色] 芯粒连接到 Zen 3 计算芯片上。而TSV则构建在L3的SRAM模块中,并在其所有的8个内核之间共享。

(2)存内计算
顾名思义,在存储器中进行计算,有效解决“冯氏”架构中存储单元和计算单元之间因海量数据调取,传输所带来的速度慢,能耗高的缺点。尤其适用在基于神经网络模型的人工智能方面的应用。
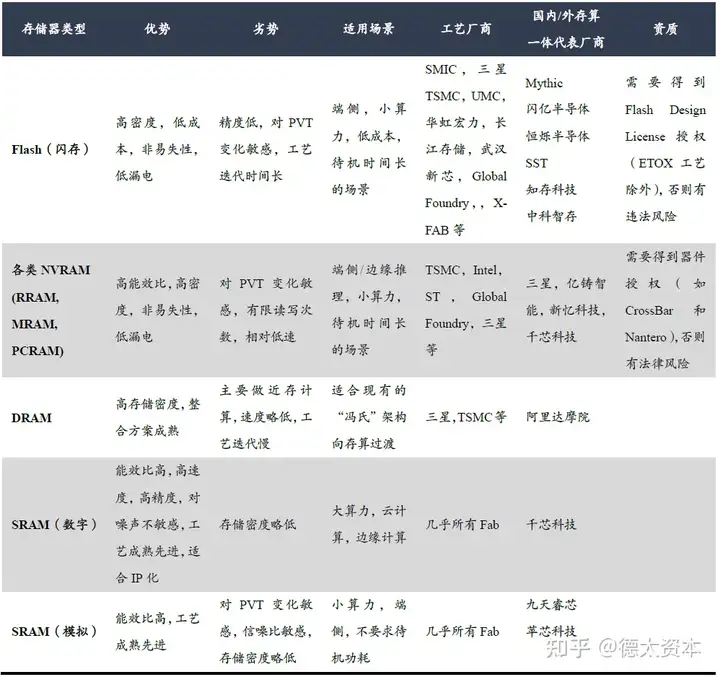
存内计算的典型代表包括Mythic、闪亿半导体、千芯科技、亿铸科技、知存科技、九天睿芯等。
其中,存内计算可分为数字存内计算和模拟存内计算。
数字存内计算:主要以SRAM/RRAM/DRAM作为存储器件,采用先进逻辑工艺,具有高性能高精度的优势,且具备很好的抗噪声能力和可靠性。
模拟存内计算:通常使用FLASH、RRAM、PRAM等非易失性介质作为存储器件,存储密度大,并行度高,但是对环境噪声和温度非常敏感,并且因精度上限在4-8bit的精度范围内,一般只适合做定点计算,难以实现浮点计算,因此在有大算力需求的场景(如云计算和训练场景),模拟存算无法满足。一般情况下模拟存算只适用于精度要求低的场景。
另外,因模拟计算的电路设计对器件的SPICE模型精度要求很高,因此产品级的模拟存内计算目前还无法使用近/亚阈值等功耗降低技术,能效比提升受到一定的限制。
(3)存内逻辑
存内逻辑是在存内计算的原理之上,在存储阵列中添加逻辑计算电路,以提升存算一体计算的灵活性,可以更好的支持浮点运算与多样的算子,同时保持了更高的能效比和算力,是存内计算的技术升级。
存内逻辑的典型代表包括台积电、千芯科技等。
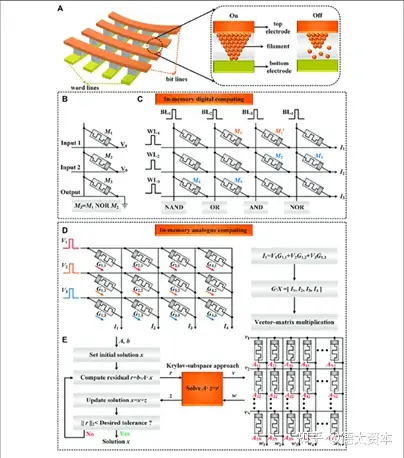
动态可重构技术是一种在无需重新启动或编程,在运行时动态更新数据路径或计算方式的电路架构技术。
与普通的处理器相比,动态可重构技术可在运行时变更数据路径和计算流程;与普通ASIC相比,动态可重构技术可合并多个计算模块的功能,提升电路模块的使用效率,相对多个不同计算功能的模块具有更小的芯片面积。
高性能可重构计算(HPRC) 就是一种将基于可重构计算的加速器(如现场可编程门阵列)与 CPU 或多核处理器相结合的计算机架构。例如通过在 动态可重构单元上复制算法,可以实现动态可重构的SIMD系统,提升特定并行算法的计算效率。
(连载中,未完待续)
本文作者:Vivian,YOYO,Victor
关于我们
德太资本由腾讯(http://0700.HK) 联合创始人和德迅投资创始人曾李青先生联合创立。德太资本在香港和中国大陆分别设有持牌机构,用于运作咨询及资产管理等受规管业务。德太资本专注消费和科技领域,是一家致力于为境内外创业者提供私募融资咨询服务、企业并购等服务的精品投行