http://arthurchiao.art/blog/system-call-definitive-guide-zh/
本文翻译自 2016 年的一篇英文博客 The Definitive Guide to Linux System Calls 。如果能看懂英文,我建议你阅读原文,或者和本文对照看。
以下是译文。
本文介绍了 Linux 程序是如何调用内核函数的。包括:
glibc wrapperssyscall(2) 半手动发起系统调用
glibc 系统调用 wrapperssyscall 相关的有趣 bugs
当程序调用到 open、for、read、write 等函数时,就是在进行系统调用。
系统调用是一种 程序进入内核执行任务的方式。程序利用系统调用进行一系列操作,例如 创建进程、处理网络、读写文件等等。 通过 syscall(2) man page 可以查看完整的系统调用列表。
应用程序有多种发起系统调用的方式,其中涉及的底层指令会因 CPU 不同而有所 差异。应用开发者通常无需考虑系统调用是如何实现的,只需 include 相应的头文 件,像调用正常函数一样调用系统调用函数即可。glibc 提供的 wrapper 函数封装 了底层代码,如果使用这些 wrapper 函数,只需要传递相应的参数给它就可以进入内核。
在开始研究系统调用之前先定义一些术语,并介绍几个后面将会用到的核心理念。
本文将基于如下假设:
3.13.0 内核。介绍到实现的时候会给出一些 github 上的链接。其他 内核版本与此类似,但文件路径、具体行号等可能会有差别glibc 或其衍生版本(例如 eglibc )的实现有兴趣x86-64 在本文中将指基于 x86 架构的 64 位 Intel 或 AMD CPU。
用户程序(例如编辑器、终端、ssh daemon 等)需要和 Linux 内核交互,内核代替它们完 成一些它们自身无法完成的操作。
例如,如果用户程序需要做 IO 操作(open、read、write 等),或者需要修改它的 内存地址(mmpa、sbrk 等),那它必须触发内核替它完成。什么禁止用户程序做这些 操作?
原来,x86-64 CPU 有一个特权级别 (privilege levels)的概念。这个概念很复杂,完全可以单独写一篇博客。 出于本文讨论目的,我们将其(大大地)简化为如下:
用户程序要进行特权操作必须触发一次特权级别切换(从 “Ring 3” 到 “Ring 0”), 由内核(替它)执行。触发特权级别切换有多种方式,我们先从最常见的方式开始:中断。
可以将中断想象成硬件或软件产生(或“触发”)的事件。
硬件中断是由硬件设备触发的,以此通知内核发生了特定的事件。一个常见的例子是网卡收 到数据包时触发的硬中断。软件中断是由执行中的程序触发的。在 x86-64 系统上,软件中 断可以通过 int 指令触发。中断都有编号,其中一些编号有特定的意义。
可以想象内存中的一个数组,数组中的每项(entry)分别对应一个中断号。每项的内容包 括 中断发生时 CPU 需要执行的函数(回调函数,或称中断处理函数)的地址以及其他 一些选项,例如以哪个特权级别执行中断处理函数。
下面是 Intel CPU 手册中提供的一个中断项(entry)的内存布局视图:

注意其中有一个 2 bit 的 DPL(Descriptor Privilege Level,描述符特权级别)字段 ,这个值表示执行中断处理函数时 CPU 所应满足的最小特权级别。
这就是当一个特定类型的中断事件发生时,CPU 如何知道中断函数的地址,以及它应该以 哪个特权级别执行中断函数的原理。
实际上 x86-64 系统的中断还有很多其他方式。想了解更多可以阅读:
处理硬件和软件中断时还有其他一些复杂之处,例如中断号冲突(collision)和重映射 (remapping)。在本篇中我们不考虑这些方面。
(CPU)型号特定寄存器(Model Specific Registers, MSR)是用于特殊目的的控制寄存 器,可以控制 CPU 的特定特性。CPU 文档里列出了每个 MSR 的地址。
rdmsr 和 wrmsr 指令可以读写 MSR,也有命令行工具可以读写 MSR,但是不推荐这样 做,因为改变这些值(尤其是系统正在运行时)是非常危险的,除非你非常小心,知道自己 在做什么。
如果不怕导致系统不稳定或造成不可逆的数据损坏,那可以安装 msr-tools 并加载 msr 内核模块,然后就可以读写 MSR 了:
$ sudo apt-get install msr-tools
$ sudo modprobe msr
$ sudo rdmsr
本文接下来的一些系统调用使用了 MSR。
手写汇编代码来发起系统调用并不是一个好主意。其中一个重要原因是,glibc 中有 一些额外代码在系统调用之前或之后执行(而你自己写的汇编代码没有做这些类似的工作) 。
接下来的例子中我们使用 exit 系统调用。事实上你可以用 atexit函数向 exit 注册 回调函数,在它退出的时候就会执行。这些函数是从 glibc 里调用的,而不是内核。因 此,如果你自己写的汇编代码调用 exit,那注册的回调函数就不会被执行,因为这种方 式绕过了 glibc。
然而,徒手写汇编来调系统调用是一次很好的学习方式。
根据前面的知识我们知道了两件事情:
int 指令可以产生软中断将两者结合,我们就来到了 Linux 传统(Legacy)的系统调用接口。
Linux 内核预留了一个特殊的软中断号 128 (0x80),用户空间程序使用它可以进入内 核执行系统调用,对应的中断处理函数是 ia32_syscall。接下来看代码实现。
从 trap_init 函数开始,arch/x86/kernel/traps.c:
void __init trap_init(void)
{
/* ..... other code ... */
set_system_intr_gate(IA32_SYSCALL_VECTOR, ia32_syscall);
其中 IA32_SYSCALL_VECTOR 为 0x80,定义在 arch/x86/include/asm/irq_vectors.h. 。
但是, 如果内核只给用户空间程序预留了一个软中断,内核如何知道中断触发的时候,该去 执行哪个系统调用呢?
答案是,用户程序会将系统调用编号放到 eax 寄存器,系统调用所需的参数放到其他的 通用寄存器上。
arch/x86/ia32/ia32entry.S 对这个过程做了注释:
* Emulated IA32 system calls via int 0x80.
*
* Arguments:
* %eax System call number.
* %ebx Arg1
* %ecx Arg2
* %edx Arg3
* %esi Arg4
* %edi Arg5
* %ebp Arg6 [note: not saved in the stack frame, should not be touched]
*
现在我们知道了如何发起系统调用,也知道了系统调用的参数应该放到哪里,接下来就写一 些内联汇编来试试。
发起一次传统系统调用只需要少量内联汇编。虽然从学习的角度来说很有趣,但是我建议读 者永远不要(在生产环境)这样做。
在这个例子中,我们将调用 exit 系统调用,它只有一个参数:返回值。
首先,我们要找到 exit 的系统调用编号。内核有一个文件列出了所有的系统调用编号。 在编译期间,这个文件会被多个脚本处理,最后生成用户空间会用到的头文件。这个列表位 于arch/x86/syscalls/syscall_32.tbl:
1 i386 exit sys_exit
exit 的系统调用编号是 1。根据前面的信息,我们只需要将系统调用编号放到 eax 寄 存器,然后将第一个参数(返回值)放到 ebx。
如下是实现这个功能的简单 C 代码,其中包括几行内联汇编。这里将返回值设置为 42。 (这个程序其实还可以进一步简化,这样写是为了让没有 GCC 内联汇编基础的读者更容易看 懂。)
int
main(int argc, char *argv[])
{
unsigned int syscall_nr = 1;
int exit_status = 42;
asm ("movl %0, %%eax\n"
"movl %1, %%ebx\n"
"int $0x80"
: /* output parameters, we aren't outputting anything, no none */
/* (none) */
: /* input parameters mapped to %0 and %1, repsectively */
"m" (syscall_nr), "m" (exit_status)
: /* registers that we are "clobbering", unneeded since we are calling exit */
"eax", "ebx");
}
编译运行,查看返回值:
$ gcc -o test test.c
$ ./test
$ echo $?
42
成功!我们通过触发一个软中断完成了一次传统系统调用。
int $0x80 入口上面看到了如何从用户端触发一个系统调用,接下来看内核端是如何实现的。
前面提到内核注册了一个系统调用回调函数 ia32_syscall。这个函数定义在 arch/x86/ia32/ia32entry.S 。函数里最重要的一件事情,就是调用 真正的系统调用:
ia32_do_call:
IA32_ARG_FIXUP
call *ia32_sys_call_table(,%rax,8) # xxx: rip relative
宏 IA32_ARG_FIXUP 的作用是对传入的参数进行重新排列,以便能被当前的系统调用层正 确处理。
ia32_sys_call_table 是一个中断号列表,定义在 arch/x86/ia32/syscall_ia32.c ,注意代码结束处的 #include:
const sys_call_ptr_t ia32_sys_call_table[__NR_ia32_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_ia32_syscall_max] = &compat_ni_syscall,
#include <asm/syscalls_32.h>
};
回忆前面在 arch/x86/syscalls/syscall_64.tbl 中看到了系统调用列表的定义。有几个脚本会在内核编译期间运行,通过这个文件生成 syscalls_32.h 头文件,后者是合法的 C 代码文件,通过上面看到的#include 插入到 ia32_sys_call_table。
这就是通过 传统系统调用方式进入内核的过程。
iret: 系统调用返回至此我们已经看到了如何通过软中断进入内核,那么,系统调用结束后,内核又是如何释放 特权级别回到用户空间的呢?
如果查看 Intel Software Developer’s Manual(警告:很 大的 PDF),里面有一张非常有帮助的图,它解释了当特权级别变化时,程序栈是如何组织的:
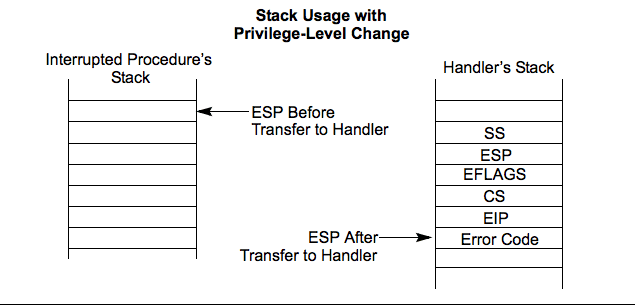
执行转交给 ia32_syscall 时会发生特权级别切换,其结果是进入 ia32_syscall 时的 栈会变成如上图所示的样子。从中可以看出,返回地址、包含特权级别的 CPU flags 以 及其他一些参数都在 ia32_syscall 执行之前压入栈顶。所以,内核只需要将这些值 从栈里复制回它们原来所在的寄存器,程序就可以回到用户空间继续执行。那么,如何做 呢?
有几种方式,其中最简单的是通过 iret 指令。
Intel 指令集手册解释说 iret 指令从栈上依次 pop 返回地址和保存的寄存器值:
As with a real-address mode interrupt return, the IRET instruction pops the return instruction pointer, return code segment selector, and EFLAGS image from the stack to the EIP, CS, and EFLAGS registers, respectively, and then resumes execution of the interrupted program or procedure.
要在内核中找到相应的代码有点困难,因为它隐藏在多层宏后面,系统依赖这些宏处理很 多事情,比例信号和 ptrace 系统返回跟踪。
irq_return 定义在 arch/x86/kernel/entry_64.S:
irq_return:
INTERRUPT_RETURN
其中 INTERRUPT_RETURN 定义在 arch/x86/include/asm/irqflags.h ,就是 iretq。
以上就是传统系统调用如何工作的。
传统系统调用看起来合情合理,但也有新的方式,它们不需要软中断,因此更快。
两种快速方法都包含两个指令:一个进入内核的指令和一个离开内核的指令。在 Intel CPU 文档中,两种方法都被称作“快速系统调用”(Fast System Call)。
但当 CPU 是 32bit 或 64bit 模式时,哪种方法是合法的,Intel 和 AMD 的实现不同。为 了最大化 Intel 和 AMD CPU 的兼容性:
sysenter 和 sysexitsyscall 和 sysretsysenter/sysexit使用 sysenter 发起系统调用比使用传统中断方式复杂很多,涉及更多用户程序(通过 glibc)和内核之间的协作。
我们逐步来看,一窥其中乾坤。首先来看 Intel Instruction Set Reference (警告:很大的 PDF)如何描述 sysenter 的,以及如何使用它。
Prior to executing the SYSENTER instruction, software must specify the privilege level 0 code segment and code entry point, and the privilege level 0 stack segment and stack pointer by writing values to the following MSRs:
• IA32_SYSENTER_CS (MSR address 174H) — The lower 16 bits of this MSR are the segment selector for the privilege level 0 code segment. This value is also used to determine the segment selector of the privilege level 0 stack segment (see the Operation section). This value cannot indicate a null selector.
• IA32_SYSENTER_EIP (MSR address 176H) — The value of this MSR is loaded into RIP (thus, this value references the first instruction of the selected operating procedure or routine). In protected mode, only bits 31:0 are loaded.
• IA32_SYSENTER_ESP (MSR address 175H) — The value of this MSR is loaded into RSP (thus, this value contains the stack pointer for the privilege level 0 stack). This value cannot represent a non-canonical address. In protected mode, only bits 31:0 are loaded.
换言之,为了使 sysenter 能够接收到系统调用请求,内核必须设置 3 个 MSR。这里最 有意思的 MSR 是 IA32_SYSENTER_EIP(地址 0x176),内核将回调函数地址放在这里 ,当 sysenter 指令执行的时候,就触发调用相应的回调函数。
内核里写 MSR 的地方 arch/x86/vdso/vdso32-setup.c:
void enable_sep_cpu(void)
{
/* ... other code ... */
wrmsr(MSR_IA32_SYSENTER_EIP, (unsigned long) ia32_sysenter_target, 0);
其中 MSR_IA32_SYSENTER_EIP 定义在 arch/x86/include/uapi/asm/msr-index.h ,值为 0x00000176。
和传统软中断系统调用类似,使用 sysenter 创建快速系统调用时也需要一个约定( convention )。内核的 arch/x86/ia32/ia32entry.S 这里对这一过程做了注释说明:
* 32bit SYSENTER instruction entry.
*
* Arguments:
* %eax System call number.
* %ebx Arg1
* %ecx Arg2
* %edx Arg3
* %esi Arg4
* %edi Arg5
* %ebp user stack
* 0(%ebp) Arg6
回忆前面讲的,传统系统调用方式包含一个 iret 指令,用于在调用结束时返回用户程序。
跟踪 sysenter 工作的逻辑是一项相当复杂的工作,因为和软中断不同,sysenter 并 不保存返回地址。内核在调用 sysenter 之前所做的工作随着内核版本在不断变化(已经 变了,接下来在 Bugs 小节会看到)。
为了消除将来的变动带来的影响,用户程序使用一个叫 __kernel_vsyscall 的函数,它在内核实现,但每个用户进程启动的时候它会映射到用户进程。这颇为怪异,它 是内核函数,但在用户空间运行。其实,__kernel_vsyscall 是一种被称为虚拟动态共 享库(virtual Dynamic Shared Object, vDSO)的一部分,这种技术允许在用户空间 执行内核代码。我们后面会深入介绍 vDSO 的原理和用途。现在,先看 __kernel_vsyscall 的实现。
__kernel_vsyscall 实现内核函数 __kernel_vsyscall 封装了 sysenter 调用约定(calling convention),见 arch/x86/vdso/vdso32/sysenter.S :
__kernel_vsyscall:
.LSTART_vsyscall:
push %ecx
.Lpush_ecx:
push %edx
.Lpush_edx:
push %ebp
.Lenter_kernel:
movl %esp,%ebp
sysenter
__kernel_vsyscall 属于 vDSO 的一部分,vDSO 是共享库,那用户程序是如何在运行时 确定函数地址的呢?
__kernel_vsyscall 的地址写入了 ELF auxiliary vector (辅助功能矢量),用户程序能(典型情况下通过 glibc)找到后者并使用它。寻找 ELF auxiliary vector 有多种方式:
getauxval,带 AT_SYSINFO 参数方法 1 是最简单的方式,但 glibc 2.16+ 才支持。下面的示例代码使用方法 2.
我们已经看到,__kernel_vsyscall 在调用 sysenter 之前做了一些 bookkeeping 工 作。因此,要手动进入 sysenter,我们需要:
AT_SYSINFO 字段,这是写 __kernel_vsyscall 地址的地方__kernel_vsyscall不要试图自己写进入 sysenter 的 wrapper 函数,因为内核和它的进出系统调用的约定 随着时间在变,最终你的代码会变得不可用。应该永远使用 __kernel_vsyscall 进入 sysenter。
sysenter和传统系统调用的例子一样,我们手动调用 exit ,设置返回值为 42。
exit 系统调号是 1,根据上面描述的调用接口,我们需要将系统调用编号放到 eax 寄 存器,第一个参数(返回值)放到 ebx。
(这个程序其实还可以进一步简化,这样写是为了让没有 GCC 内联汇编基础的读者更容易看 懂。)
#include <stdlib.h>
#include <elf.h>
int
main(int argc, char* argv[], char* envp[])
{
unsigned int syscall_nr = 1;
int exit_status = 42;
Elf32_auxv_t *auxv;
/* auxilliary vectors are located after the end of the environment
* variables
*
* check this helpful diagram: https://static.lwn.net/images/2012/auxvec.png
*/
while(*envp++ != NULL);
/* envp is now pointed at the auxilliary vectors, since we've iterated
* through the environment variables.
*/
for (auxv = (Elf32_auxv_t *)envp; auxv->a_type != AT_NULL; auxv++)
{
if( auxv->a_type == AT_SYSINFO) {
break;
}
}
/* NOTE: in glibc 2.16 and higher you can replace the above code with
* a call to getauxval(3): getauxval(AT_SYSINFO)
*/
asm(
"movl %0, %%eax \n"
"movl %1, %%ebx \n"
"call *%2 \n"
: /* output parameters, we aren't outputting anything, no none */
/* (none) */
: /* input parameters mapped to %0 and %1, repsectively */
"m" (syscall_nr), "m" (exit_status), "m" (auxv->a_un.a_val)
: /* registers that we are "clobbering", unneeded since we are calling exit */
"eax", "ebx");
}
(译者注:这里 main 函数 main(int argc, char* argv[], char* envp[])的签名很特 殊,常见的 main 都是不带参数或带两个参数,带三个参数的平时还是比较少见。)
编译,运行,查看返回值:
$ gcc -m32 -o test test.c
$ ./test
$ echo $?
42
成功!我们使用 sysenter 方法调用了 exit 系统调用,而不是通过触发软件中断的方式。
sysenter 入口现在已经看到了如何在用户程序中通过 __kernel_vsyscall 以 sysenter 方式进入系 统调用,接下来看一下内核端的实现。
回忆前面,内核注册了一个系统调用回调函数 ia32_sysenter_taret。这个函数在 arch/x86/ia32/ia32entry.S 。看下执行系统调用的时候 eax 寄存器中的值如何被使用的:
sysenter_dispatch:
call *ia32_sys_call_table(,%rax,8)
这和前面传统系统调用的代码完全相同:用系统调用编号作为索引去 ia32_sys_call_table 列表查找回调函数。也就是说,做完必须的 bookkeeping 工作后, 传统方式和 sysenter 方式通过相同的机制(表+索引)分发系统调用。
ia32_sys_call_table 是如何定义及构建出来的可以查看前面 int $0x80 入口 小节。
这就是通过 sysenter 系统调用方式进入内核的原理。
sysexit:从 sysenter 返回内核使用 sysexit 指令恢复用户程序的执行。
这个指令的使用并不像 iret 那样直接。调用者必须将需要返回的地址放到 rdx 寄存 器,将需要使用的栈地址放到 rcx 寄存器。这意味着应用程序需要自己计算程序恢复 执行时的地址,保存这个值,然后在调用 sysexit 之前恢复它。这个过程的代码实现 arch/x86/ia32/ia32entry.S :
sysexit_from_sys_call:
andl $~TS_COMPAT,TI_status+THREAD_INFO(%rsp,RIP-ARGOFFSET)
/* clear IF, that popfq doesn't enable interrupts early */
andl $~0x200,EFLAGS-R11(%rsp)
movl RIP-R11(%rsp),%edx /* User %eip */
CFI_REGISTER rip,rdx
RESTORE_ARGS 0,24,0,0,0,0
xorq %r8,%r8
xorq %r9,%r9
xorq %r10,%r10
xorq %r11,%r11
popfq_cfi
/*CFI_RESTORE rflags*/
popq_cfi %rcx /* User %esp */
CFI_REGISTER rsp,rcx
TRACE_IRQS_ON
ENABLE_INTERRUPTS_SYSEXIT32
ENABLE_INTERRUPTS_SYSEXIT32 宏封装了 sysexit,定义在 arch/x86/include/asm/irqflags.h 。
这就是 32 位系统上的快速系统调用是如何工作的。
接下来看 64 位系统的快速系统调用的工作原理,它用到了 syscall 和 sysret 两个 指令。
syscall/sysretIntel Instruction Set Reference (警告:很大的 PDF)解释了 syscall 是如何工作的:
SYSCALL invokes an OS system-call handler at privilege level 0. It does so by loading RIP from the IA32_LSTAR MSR (after saving the address of the instruction following SYSCALL into RCX).
意思是,要使内核接收系统调用请求,必须将对应的回调函数地址写到 IA32_LSTAR MSR 。相应的代码实现在 arch/x86/kernel/cpu/common.c :
void syscall_init(void)
{
/* ... other code ... */
wrmsrl(MSR_LSTAR, system_call);
MSR_LSART 的值是 0xc0000082,定义在 arch/x86/include/uapi/asm/msr-index.h 。
和传统系统调用类似,syscall 方式需要定义一种调用约定(convention): 用户空间程序将系统调用编号放到 rax 寄存器,参数放到通用寄存器。 这定义在 x86-64 ABI 的 A.2.1 小节:
- User-level applications use as integer registers for passing the sequence %rdi, %rsi, %rdx, %rcx, %r8 and %r9. The kernel interface uses %rdi, %rsi, %rdx, %r10, %r8 and %r9.
- A system-call is done via the syscall instruction. The kernel destroys registers %rcx and %r11.
- The number of the syscall has to be passed in register %rax.
- System-calls are limited to six arguments,no argument is passed directly on the stack.
- Returning from the syscall, register %rax contains the result of the system-call. A value in the range between -4095 and -1 indicates an error, it is -errno.
- Only values of class INTEGER or class MEMORY are passed to the kernel.
内核源文件 arch/x86/kernel/entry_64.S 也对这个有注释说明。
接下来写汇编试验一下。
还是前面的例子,手动写代码调用 exit 系统调用,设置返回值为 42 。
首先找 exit 的系统调用编号,这次定义在 arch/x86/syscalls/syscall_64.tbl :
60 common exit sys_exit
按照调用约定,需要将 60 放到 rax 寄存器,第一个参数(返回值)放到 rdi 寄存 器。
相应的 C 代码:
int
main(int argc, char *argv[])
{
unsigned long syscall_nr = 60;
long exit_status = 42;
asm ("movq %0, %%rax\n"
"movq %1, %%rdi\n"
"syscall"
: /* output parameters, we aren't outputting anything, no none */
/* (none) */
: /* input parameters mapped to %0 and %1, repsectively */
"m" (syscall_nr), "m" (exit_status)
: /* registers that we are "clobbering", unneeded since we are calling exit */
"rax", "rdi");
}
编译,运行,查看返回值:
$ gcc -o test test.c
$ ./test
$ echo $?
42
成功!我们通过 syscall 方式完成了一次系统调用,避免了软中断,从而速度更快。
syscall 入口接下来看内核端是如何实现的。
回忆前面,我们看到一个名为 system_call 函数的地址写到了 LSTAR MSR。 我们来看下这个函数的实现,看它如何使用 rax 将执行交给系统调用的, arch/x86/kernel/entry_64.S :
call *sys_call_table(,%rax,8) # XXX: rip relative
和传统系统调用方式类似,sys_call_table 是一个数组,定义在 C 文件,通过 #include 方式生成。 arch/x86/kernel/syscall_64.c ,注意末尾的 #include:
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};
syscall 数组定义在 arch/x86/syscalls/syscall_64.tbl 。也和传统方式类似,在内核编译期间脚本通过 syscall_64.tbl 生成 syscalls_64.h 。
这就是如何通过 syscall 方式的系统调用进入内核的过程。
sysret:系统调用返回内核通过 sysret 指令将执行过程返还给用户程序。sysret 比 sysexit 要简单,因 为当执行 syscall 的时候,恢复执行的地址复制到了 rcx。只要将值缓存到某处,在 调用 sysret 离开之前再把它恢复到 rcx,那执行过程就能恢复到 syscall 之前的程 序和状态。这比 sysenter 方便,因为后者还需要应用程序自己计算恢复执行的地址,需 要用到额外的寄存器。
相应的代码 arch/x86/kernel/entry_64.S:
movq RIP-ARGOFFSET(%rsp),%rcx
CFI_REGISTER rip,rcx
RESTORE_ARGS 1,-ARG_SKIP,0
/*CFI_REGISTER rflags,r11*/
movq PER_CPU_VAR(old_rsp), %rsp
USERGS_SYSRET64
USERGS_SYSRET64 宏封装了 sysret,定义在 arch/x86/include/asm/irqflags.h 。
这就是 64 位系统上快速系统调用如何工作的。
syscall(2) 半手动发起系统调用现在,我们已经看到如何手动写汇编通过几种不同方式触发系统调用了。通常不需要自己写 汇编程序,glibc 已经提供了 wrapper 函数处理这些事情。然而,有些系统调用 glibc 没有提供 wrapper,一个例子是 futex,快速用户空 间锁(fast userspace locking)系统调用。为什么没有为 futex 实现一个 wrapper 呢?
futex 的设计里它只会被库函数(library)调用,并不会被应用程序直接调用。因 此,要调用 futex,你有两种方式可选:
glibc 提供的 syscall wrapper如果要使用一个没有 wrapper 的系统,你应该首选方法 2。
接下来看如何使用 glibc 提供的 syscall 调用 exit,返回 42。
#include <unistd.h>
int
main(int argc, char *argv[])
{
unsigned long syscall_nr = 60;
long exit_status = 42;
syscall(syscall_nr, exit_status);
}
编译,运行,查看返回值:
$ gcc -o test test.c
$ ./test
$ echo $?
42
成功!我们用 glibc 提供的 syscall wrapper 发起了 exit 系统调用。
glibc syscall wrapper 内部实现代码 sysdeps/unix/sysv/linux/x86_64/syscall.S:
/* Usage: long syscall (syscall_number, arg1, arg2, arg3, arg4, arg5, arg6)
We need to do some arg shifting, the syscall_number will be in
rax. */
.text
ENTRY (syscall)
movq %rdi, %rax /* Syscall number -> rax. */
movq %rsi, %rdi /* shift arg1 - arg5. */
movq %rdx, %rsi
movq %rcx, %rdx
movq %r8, %r10
movq %r9, %r8
movq 8(%rsp),%r9 /* arg6 is on the stack. */
syscall /* Do the system call. */
cmpq $-4095, %rax /* Check %rax for error. */
jae SYSCALL_ERROR_LABEL /* Jump to error handler if error. */
L(pseudo_end):
ret /* Return to caller. */
前面我们介绍过 x86_64 ABI 文档,描述了用户态和内核态的调用约定。
这段汇编 stub 代码非常酷,因为它同时展示了两个调用约定:传递给这个函数的参数 符合 用户空间调用约定,然后将这些参数移动到其他寄存器,使得它们在通过 syscall 进入内核之前符合 内核调用约定。
这就是 glibc wrapper 如何工作的。
到目前为止,我们已经展示了通过多种触发系统调用的方式从用户空间进入内核的过程。
能否让用户程序不进入内核,就可以发起特定的系统调用呢?
这就是 Linux 虚拟动态共享库(VDSO)技术。Linux vDSO 是一段内核代码,但映射到 用户空间,因而可以被用户空间程序直接调用。其设计思想就是部分系统调用无需用户程序 进入内核就可以调用,一个例子就是 gettimeofday。
调用 gettimeofday 的程序无需进入内核,而是调用内核提供的、运行在用户空间的代码 。无需软中断,无需复杂的 sysenter 或 syscall 等 bookkeeping 工作,就像一个正 常的函数调用一样。
使用 ldd 查看时,可以看到列出的第一个已加载库就是 vDSO:
$ ldd `which bash`
linux-vdso.so.1 => (0x00007fff667ff000)
libtinfo.so.5 => /lib/x86_64-linux-gnu/libtinfo.so.5 (0x00007f623df7d000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f623dd79000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f623d9ba000)
/lib64/ld-linux-x86-64.so.2 (0x00007f623e1ae000)
接下来看 vDSO 在内核是如何实现的。
vDSO 的代码位于 arch/x86/vdso/,由 一些汇编、C 和一个连接器脚本组成。
连接器脚本是一个很酷的东西, arch/x86/vdso/vdso.lds.S :
/*
* This controls what userland symbols we export from the vDSO.
*/
VERSION {
LINUX_2.6 {
global:
clock_gettime;
__vdso_clock_gettime;
gettimeofday;
__vdso_gettimeofday;
getcpu;
__vdso_getcpu;
time;
__vdso_time;
local: *;
};
}
链接器脚本是一个很有用的东西,但知道的人并不多。这个脚本排列了即将通过 vDSO 导出 的符号(函数)。我们能看到它导出了 4 个函数,每个函数都有两个名字。每个函数的定义 可以在这个目录中的 C 文件中找到。
例如,gettimeofday 在 arch/x86/vdso/vclock_gettime.c:
int gettimeofday(struct timeval *, struct timezone *)
__attribute__((weak, alias("__vdso_gettimeofday")));
这里定义了 gettimeofday 是 __vdso_gettimeofday 的weak alias。 后者的定义在 同一个源文件 中,当用户程序调用 gettimeofday 时,实际执行的是 __vdso_gettimeofday。
由于地址空间布局随机化 (address space layout randomization)的存在,vDSO 会在程序启动时加载到一个随机地址。 那么,用户程序是如何找到 vDSO 的呢?
前面 sysenter 章节,我们看到用户程序应该调用 __kernel_vsyscall 而 不是写他们自己的 sysenter 汇编代码。这个函数其实就是 vDSO 的一部分。 相同的代码用于在 ELF auxiliary headers 里搜索一个 AT_SYSINFO 类型的头,以此来定位 __kernel_vsyscall 的位置。
类似地,要确定 vDSO 的地址,用户程序可以搜索 AT_SYSINFO_EHDR 类型 ELF auxiliary header,它包含了 vDSO 的 ELF 头的内存地址。
以上两种情况,内核都在程序加载时将 vDSO 地址写入 ELF 头,这就是为什么 vDSO 的地 址永远出现在 AT_SYSINFO_EHDR 和 AT_SYSINFO 的原因。
定位到 header 之后,用户程序就可以解析 ELF 对象(例如通过 libelf),调用里面的函数 。这种方式很好,因为这意味着 vDSO 可以用到一些 ELF 特性,例如 符号版本 。
内核文档 Documentation/vDSO/ 提供了一个解析和调用 vDSO 中函数的例子。
glibc 中的 vDSO很多情况下大家已经用到了 vDSO,只是没意识到,这是因为 glibc 使用我们前面介绍的 接口对它做了封装。
当程序加载的时候,动态连接器和加载器 会加载程序依赖的动态链接库( DSO),其中就包括 vDSO。
解析 ELF 头的时候,glibc 保存了 vDSO 的位置信息等数据,后面加载的时候会用上。另 外,它还包含了一个很短的 stub 函数,在系统调用真正发生之前在 vDSO 中查找符号(函数 )。
例如,glibc 中的 gettimeofday 函数, sysdeps/unix/sysv/linux/x86_64/gettimeofday.c :
void *gettimeofday_ifunc (void) __asm__ ("__gettimeofday");
void *
gettimeofday_ifunc (void)
{
PREPARE_VERSION (linux26, "LINUX_2.6", 61765110);
/* If the vDSO is not available we fall back on the old vsyscall. */
return (_dl_vdso_vsym ("gettimeofday", &linux26)
?: (void *) VSYSCALL_ADDR_vgettimeofday);
}
__asm (".type __gettimeofday, %gnu_indirect_function");
这段代码在 vDSO 中寻找 gettimeofday 函数的地址并返回,它使用了重定向函 数( indirect function)来优雅地完成这一过程。
应用程序就是通过这种方式经 glibc 调用 vDSO 的 gettimeofday 函数,从而避免了 切换到内核、提升特权级别以及触发软中断等过程。
以上就是 Linux 32 和 64 位系统上所有的发起系统调用的方法,适用于 Intel 和 AMD CPU。
glibc 系统调用 wrappers前面讨论的都是 Linux 系统调用本身,接下来将范围稍微向外一些,看一看 glibc 作为 更上层库是如何处理系统调用的。
对于很多系统调用,glibc 只用到了一个简单的 wrapper 程序:将参数放到合适的寄存器 ,然后执行 syscall 或 int $0x80 指令,或者调用 __kernel_vsyscall。这个过程 用到了一系列的列表,这些列表的核心内容定义在几个文本文件里,然后被脚本文件处理之 后生成 C 代码。
例如, sysdeps/unix/syscalls.list 文件描述了一些常规系统调用:
access - access i:si __access access
acct - acct i:S acct
chdir - chdir i:s __chdir chdir
chmod - chmod i:si __chmod chmod
要了解每一列代表什么,请查看这个文件里的注释: sysdeps/unix/make-syscalls.sh 。
更复杂的系统调用,例如 exit,并没有包含在这样的文本文件中,因为它们涉及到独立 的 C 或汇编处理函数实现。
我们将来的博客会针对有趣的系统调用来探索 glibc 的实现以及 Linux 内核相关的内容。
syscall 相关的有趣 bugs如果不趁此机会介绍几个与 syscall 相关的著名的 bug,就未免太过遗憾了。
我们来看两个。
这个安全漏洞允许本地 用户获取 root 权限。
根本原因是汇编代码有一个小 bug,在 x86-64 平台上允许用户程序进行传统方式的系统调 用。恶意代码非常聪明:它用 mmap 在一个特定地址生成一块内存区域,然后利用整形溢 出(integer overflow)使得如下代码(还记得这段代码吗?在前面的传统系统调用小节我 们介绍过)将执行移交到一段任意地址,以内核代码模式运行,将进程的特权级别升级到 root 级。
call *ia32_sys_call_table(,%rax,8)
sysenter ABI hardcode还记得前面说过,不要在应用程序中 hardcode sysenter ABI 吗?
不幸的是,android-x86 的开发者犯了这个错误,导致内核 API 变了之后,android-x86 突然停止工作。
内核开发者只好恢复了老版 sysenter ABI,以避免那些 hardcode ABI 的 android 设备 无法使用。
这是 内核的修复代码,可以从中找到导致这次问题的 android 代码的 commit 地址。
记住:永远不要自己写 sysenter 汇编代码。如果出于某些原因不得不自己实现,请使 用和我们上面给出的例子类似的代码,至少要经过 __kernel_vsyscall API。
Linux 内核的系统调用基础架构相当复杂。有多种方式可以发起系统调用,各有优缺点。
通常来说,自己写汇编代码来发起系统调用并不是一个好主意,因为内核的 ABI 可能会有 不兼容更新。内核和 libc 实现通常(可能)会为每个系统自动选择最快的系统调用方式。
如果无法使用 glibc 提供的 wrapper(或者没有 wrapper 可用),你至少应该使用 syscall wrapper,或者尝试 vDSO 提供的 __kernel_vsyscall。
保持关注本博客,我们将来会针对单个系统调用及其实现进行研究。
如果对本文感兴趣,那么你可能对我们的以下文章也感兴趣: