https://cizixs.com/2017/12/04/raft-consensus-algorithm/复制
分布式系统有一个很重要的问题要解决,当一台机器出现问题时,我们希望整个集群还是能够正常运行的,以达到高可用的要求。因为系统的数据是不断变化的,所以要保证集群的数据是同步的,不然会出现数据混论或者丢失的情况。这就是一致性问题。
换个说法,一致性就是让多台机器对一组给定的操作最终得到的状态一样,也就是所有机器执行命令的顺序是一样的,对客户端来说,它们表现得就要像一个机器一样。
分布式一致性问题可以抽象成下面这张图(分布式状态机 Replicated State Machine):
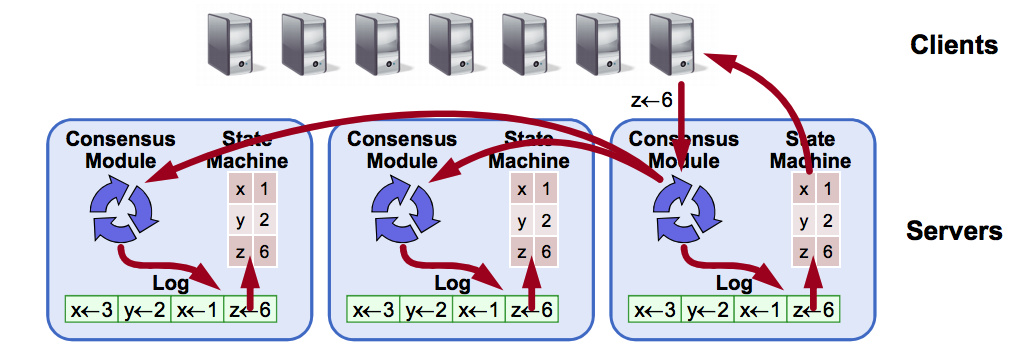
最终的目的是所有节点上保存的状态机器(文件内容)是一样的,这是通过各个节点上一致性模块之间的通信完成的,它们保证按顺序添加日志,然后把日志执行修改状态机的内容。如果机器初始状态相同,而且日志中记录顺序是一样的,那么最终的状态一定也是相同的。
一致性算法需要满足以下条件才能在实际系统中工作:
分布式系统关于一致性最著名的算法是 paxos,它的发布者 Lamport 是图灵奖的获得者。但是 paxos 算法非常复杂,很多实现都是它的特殊版。尽管 Lamport 后来还发布过 Paxos Made Simple 的文章,试图用更简单的语言解释 paxos 算法,但是这个版本的解释还是过于复杂,这对于理解和实现都带来困难。
paxos 算法在分布式系统中地位很高,Chubby 作者有过这样一段话:
There is only one consensus protocol, and that’s Paxos. All other approaches are just broken versions of Paxos.
只有一种一致性算法,那就是 Paxos;而其他所有的一致性算法都是 Paxos 的特殊版本。
raft 算法是基于 paxos 算法提出来的,主要是为了更加易懂,提出 raft 算法的论文是 《In search of an Understandable Consensus Algorithm》,可以在网上很容易搜到原文。
为了容易理解,raft 算法主要分成几个可以单独解释的问题:
它的工作流程是这样的:集群选择出一个节点作为 leader,leader 节点负责接收客户端的请求(日志),并负责把请求复制给所有的从节点,保证节点之间数据的同步。如果 leader 节点出现问题挂掉,那么其他正常节点会重新选择 leader。
每个节点在任意情况下,只能有三种状态可选:
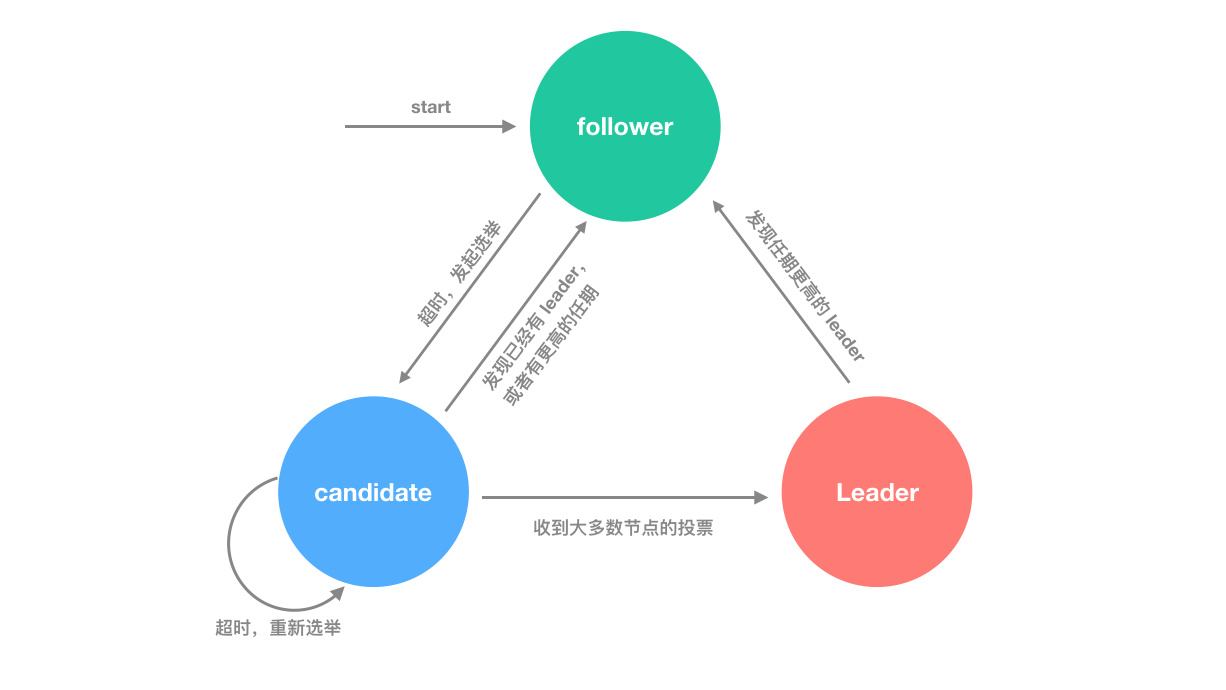
raft 算法还有一个任期(Term)的概念,任期是依次递增的编号,每次选举都是一个新的任期。在一个任期内最多只能有一个 leader,也就是说一个任期可以有一个 leader,表示正常工作;也可以没有 leader,表明选举失败。某个节点选举成功后,就成为当前任期的 leader,负责日志复制工作。
任期的主要目的是保证所有节点逻辑时间上的一致,而不会出现过期的请求导致逻辑混乱的情况。

每个节点都会保存一个当前任期的值,当节点通信时会交互当前任期的值,如果节点发现其他节点的当前任期比自己的大,就更新自己当前任期的值;如果 leader 节点发现有比自己大的任期值,则知道自己的任期过期了,集群中有更新的 leader 节点,它立即变成 follower 状态;如果节点接收到历史任期的请求,则直接无视(这很可能是因为网络延迟或者报文重复导致的)。
当节点刚启动的时候,默认是在 follower 状态。如果它能定时收到 leader 的心跳或者日志复制的请求,则会一直处于该状态;如果在设定的超时时间(election timeout)内没有收到 leader 的消息,则认为当前集群没有 leader,或者 leader 以及失效,立即会发起重新投票。
投票开始,节点会增加自己的当前任期值,转换成 candidate 状态,并向其他节点发送请求投票的消息(表示自己想成为下一个任期的 leader)。下面的状态分为三种情况:
如果不采取任何措施,那么第三种情况一直出现,会导致整个集群一直处于选举的状态,这当然是不可接受的。为此,raft 采取了随机时间的办法。
首先,选举超时时间(election timeout)是随机的,保证会有一个节点首先超时,率先选举,其他节点来不及和它竞选,它就会成为新的 leader,发送心跳和日志复制请求。
其次,在开始选举时,每个 candidate 节点重置它的超时计时器,等待计时器结束之后才会开始下一次选举,从而打乱下次选举的前后顺序,保证有一个节点先开始选举,并成为 leader。
事实证明,这两种方式能够保证选举在很短的时间里完成,而不会一直循环。
NOTE:
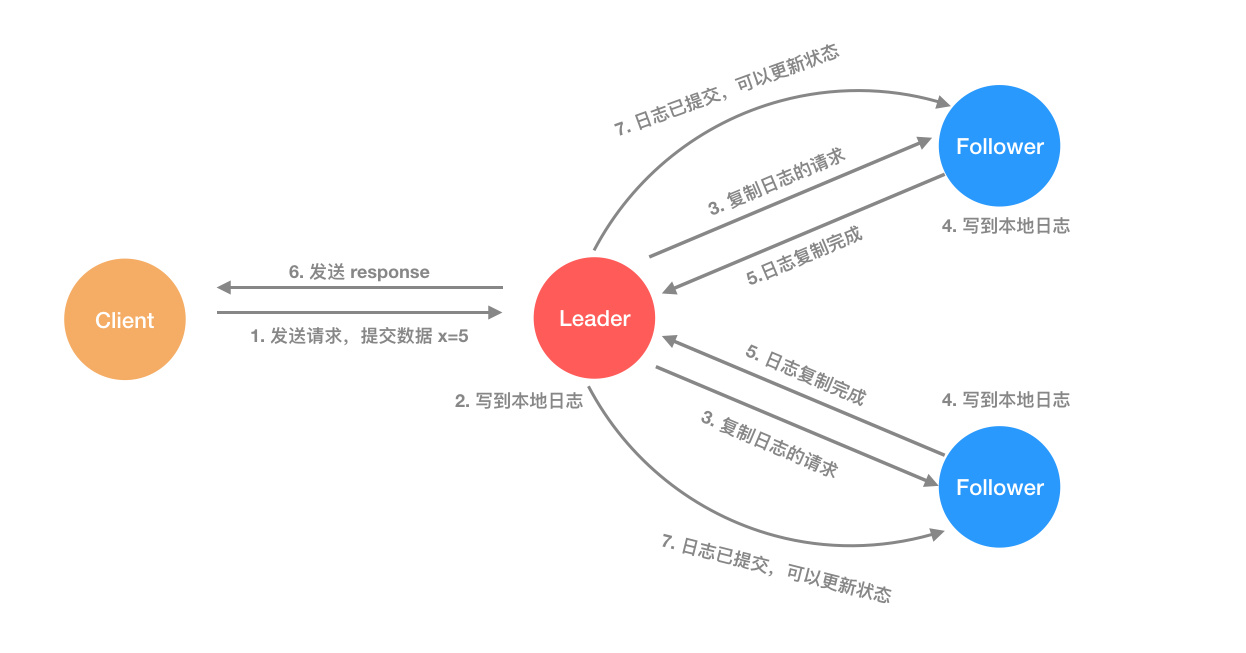
当一个节点成为 leader 之后,它就会负责接收客户端的请求。客户端的每个请求都是一个指令,replicate state machine(复制状态机) 会执行这个指令,修改自己的状态。
主节点收到请求之后,把它作为新纪录写入到自己的日志中,然后发送请求给所有的从节点,让它们进行日志复制,等到日志复制完成,leader 节点返回结果给客户端。如果有从节点失败或者比较慢,主节点会一直重试,直到所有的节点保存了所有的日志记录(达到统一的状态)。
每个日志记录都要保存一个状态机的指令,同时还保存主节点接受请求时候的任期值,此外还有一个 index 表示它在日志文件中的位置。
当日志记录被状态机执行后,就称它为已提交(commited)。当主节点知道日志记录已经复制到大多数节点时,会把当前记录提交到本地的状态机(因为日志已经更新到大多数节点,所有数据是安全的),也就是更改数据的值。
leader 节点会记录已经提交(commited)的最大日志 index,然后后续的心跳和日志复制请求会带上这个值,这样从节点就能知道哪些记录已经提交了,自己也会让状态机开始执行日志中的记录。从而达到所有状态机数据的一致性!
这样的日志机制保证了如果不同节点的日志文件某个记录的 index 和任期都相同,那么它们的内容也一定相同,而且之前的日志记录也一定是一样的。
当主节点发送日志复制的请求时,它会带上前一个日志记录的 index 和 term,如果从节点发现自己的日志中不存在这个记录,则会拒绝这个请求。
正常情况下,每次日志复制都能正常完成,而且节点都能保证日志记录都是完全一致的。但如果 leader 节点崩溃掉,可能会出现日志不一致的情况(奔溃的主节点还没有完全把自己日志文件中的记录复制到其他节点,因此有些节点的日志比另外一些节点内容更多)。
对于日志内容不一致的请求,raft 采取用主节点日志内容覆盖 follower 节点日志的做法,先找到从节点日志和自己日志记录第一个不一致的地方,然后一直覆盖到最后。
整个过程是这样的:当某个节点当选 leader 之后,会发送日志复制请求到从节点,并带着 nextIndex(主节点要发送的下一个日志记录的 index),如果从节点出现日志记录不一致的情况,会拒绝该请求,那么主节点知道发生了不一致,递减 nextIndex,然后重新发送请求,直到日志一致的地方,一切回复正常,然后继续发送日志复制请求,就会把从节点的日志覆盖为主节点的日志内容。
前面提到的选主和日志复制是 raft 算法的核心,能够保证日志里面记录最终是一致的,但是还不能够保证所有节点的状态机能够按顺序执行命令。raft 对选主做出了限制,从而实现算法的正确性。
总的来说,这个限制只有一句话:只有保存了最新日志的节点才能选举成为 leader,选举的时候如果节点发现候选节点日志没有自己的新,则拒绝投票给它。因为保存了最新日志,因此新 leader 产生之后,follower 节点和它保持同步就不会出现数据冲突的问题。这样也能保证 leader 节点不会覆盖日志中的记录。
上面最新日志指的是保存了所有的已提交日志记录,因为已提交已经包含了集群中大多数节点都会有对应的日志记录,因此能保证没有最新记录的候选人选不上(因为大多数节点会拒绝投票给它),而且至少有一个节点符合条件(只要集群节点数超过 3)。
除了上述最核心的内容之外,raft 算法还有节点增删时候保证数据一致性的解决方案,以及利用快照(snapshot)进行日志压缩(log compaction)的内容,而且还要求客户端发送请求时带有一个 id,raft 集群保证请求处理的幂等性。
总的来说,易懂性是 raft 强调的核心,在不损失功能和性能的情况下,保证算法和系统的容易理解非常重要,这也是为什么相比很早就就出现的 paxos 算法,2013 年刚出现的 raft 就成为了很多新的分布式系统核心算法(比如分布式键值数据库 etcd )。