数据库“断页”是个很有意思的话题,目前任何数据库应该都绕不过去。我们知道数据库的块大小一般是8k、16k、32k,而操作系统块大小是4k,那么在数据库刷内存中的数据页到磁盘上的时候,就有可能中途遭遇类似操作系统异常断电而导致数据页部分写的情况,进而造成数据块损坏,数据块损坏对于某些数据库是致命的,可能导致数据库无法启动。既然对于断页问题数据库都可能遇到,那么再来看看主流数据库是如何避免发生断页的。
先看看mysql,innodb的page size一般是16k,innodb的数据行发生变更时,将buffer pool中的page更新,并且将这次变更写入redolog中,buffer pool中发生改变的dirty page再择机刷新到磁盘。脏页刷到磁盘的过程中就可能发生断页问题。mysql为了解决这个问题,引入了“双写”double write,也就是说在将数据页写入磁盘之前先写入一个共享的空间,然后再写入数据文件中。这个共享的空间大小是2M,当然为了加速写也引入了innodb double write buffer,也是2M,总体写流程如下图
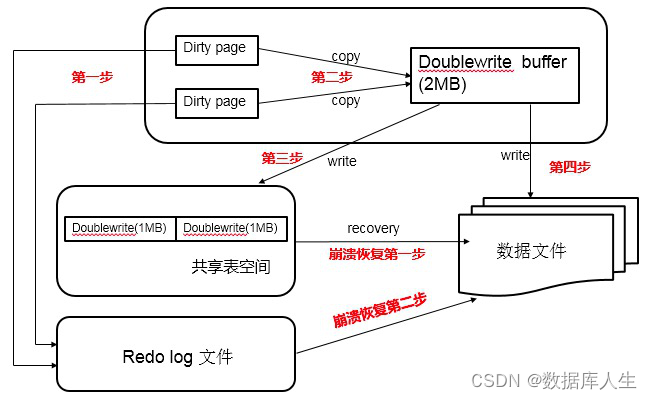
2M的大小共包含128个页面,前120个页面是批量刷脏使用的空间,后8个页面是单页面刷脏使用的空间,批量刷脏是后台线程发起,而单页面刷脏是用户线程发起,单页面刷脏需要同步完成,要求实时性,值得注意的是double write是页面顺序写,速度很快,而buffer pool刷脏是随机写,效率较低。如果刷脏过程中发生写断页问题,存储引擎会从2M共享表空间中找到该页面的副本,然后恢复到数据文件中,然后应用redo进行恢复。innodb双写对性能的影响还是比较大的,相当于每次都要写两份数据。
再看看oracle,oracle对于断页比较“看得开”,他不会从数据库层面去避免发生断页问题,数据库内部没有机制保证断页的处理,它通过其他方面比如rman恢复、adg等方式保证出了问题进行恢复。
最后看看pg的处理,pg通过开启full_page_writes参数(默认开启)来避免断页问题。具体原理是当checkpoint发生后,某个块第一次被更改时将整个页面写入xlog文件中,如果发生块折断,从checkpoint开始从xlog中找到这个数据块的初始完整副本,然后应用redo日志进行恢复。这种方式对性能也有一定影响,但是相比mysql的方式我觉得要好一些,mysql相当于任何一个脏页刷盘前都需要写两份,pg只是在数据块第一次发生变更的时候写入xlog中。
full_page_writes还有一个作用是用于在线备份,因为basebackup是物理备份,那么有可能发生数据写一半的时候数据块被拷走的情况,这样备份是不可用、不可恢复的。而full_page_writes避免了这一点。
当然开启full_page_writes的副作用就是增加了xlog的日志量,因为要记录完整页面,另外对性能也有影响,有人测试过大概会有20%-30%的性能影响。