https://zhuanlan.zhihu.com/p/360624952复制
纯真IP数据库文件QQWry.dat的获取与解密,基于二进制的文件结构分析以及代码示例。
QQWry.dat文件是显IP版QQ的数据库文件,用于获取对方IP及位置,纯真IP数据库也采用了这个格式,并沿用至今。
纯真IP库是民间自发收集、提交、聚合而来的数据库,囊括了国内外的大量IP数据,部分记录甚至比商业付费数据库更加准确。它的官网提供了记录提交和纠错的功能,来自全国各地的网友将不同地区的ISP及位置数据上传,管理员在统一整合后每5天更新一次。从2005年到现在的16年间,这个数据库已经聚合了超过五十万条IP记录。
纯真IP库是完全免费的,它的官网上有在线查询功能,同时也可以下载离线数据库用于低延迟场景,但数据不可用于商业用途。这些记录在稍加分析处理后能达到不错的效果,基本满足定位IP所处城市及ISP信息的需求,不过它目前只支持IPv4地址,在一些应用场景下稍显不足。
个人博客阅读体验更佳
纯真IP数据库的文件名为 qqwry.dat,这个文件在官网上并没有公开链接可以下载,官方只提供了一个Windows工具用于查询和升级数据库。因此,如果想在服务器上实现数据库的获取与升级,必须模拟官方工具的更新机制。
如果仅用于临时测试,可以通过下载并安装纯真IP数据库查询器来得到这个文件,它内置了 qqwry.dat 文件,同时也具备自动更新机制。
你可以在官网下载最新版的Windows安装包,将下载的 setup.zip 压缩包解压,打开里面的 setup.exe,默认安装目录为 C:\Program Files (x86)\cz88.net\ip,已解密的 qqwry.dat 文件就放置在这个文件夹下。
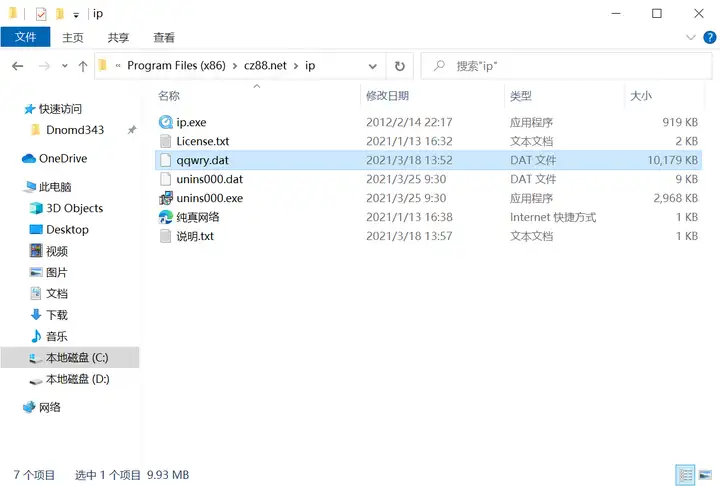
点击工具的解压按钮可以将数据库导出为文本文件。
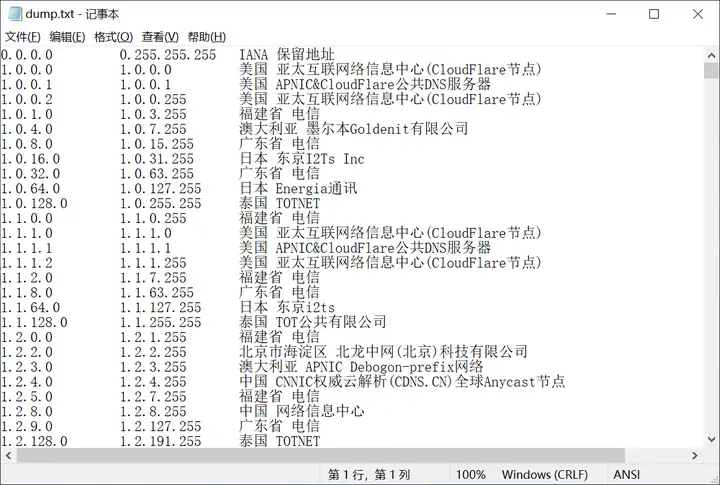
可以发现,每条记录均由起始IP、终止IP和两个数据段共四部分组成,且前后两条记录的IP范围是连续相接的,覆盖了从 0.0.0.0 到 255.255.255.255 的所有IPv4地址。
纯真官网没有提供 qqwry.dat 的下载,但其Windows查询工具内置了数据库更新功能,可以通过分析它的行为机制来获取下载和解密的算法。
对程序抓包时,检测到它会向 update.cz88.net 发起GET请求,分别下载 /ip/copywrite.rar 与 /ip/qqwry.rar 两个文件,使用以下命令来获取它们:
# 获取加密的源文件
shell> wget http://update.cz88.net/ip/copywrite.rar
···
shell> wget http://update.cz88.net/ip/qqwry.rar
···
# 查看文件字节数
shell> du -b copywrite.rar qqwry.rar
280 copywrite.rar
5385785 qqwry.rar复制在另一些测试中,需要加入以下http请求头才能正常下载,不过大多数情况下并没有这个限制,直接wget即可。
Accept: text/html, */*
User-Agent: Mozilla/3.0 (compatible; Indy Library)复制下载得到的 copywrite.rar 和 qqwry.rar 虽然后缀名是rar,但实质上并不是rar格式的压缩文件,在对文件结构进行分析后,可以得出如下的解密原理:
copywrite.rar 文件长度固定为280字节,其中包含了文件大小、密钥、版本,官网链接等数据,而 qqwry.rar 是加密的,需要使用前者携带的密钥解开。
使用hexdump命令预览 copywrite.rar 的二进制结构
shell> hexdump copywrite.rar -Cv
00000000 43 5a 49 50 f1 ac 00 00 01 00 00 00 39 2e 52 00 |CZIP........9.R.|
00000010 08 e3 fe c8 3e 01 00 00 b4 bf d5 e6 49 50 b5 d8 |....>.......IP..|
00000020 d6 b7 ca fd be dd bf e2 20 32 30 32 31 c4 ea 30 |........ 2021..0|
00000030 33 d4 c2 31 38 c8 d5 00 00 00 00 00 00 00 00 00 |3..18...........|
00000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000060 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000090 00 00 00 00 00 00 00 00 68 74 74 70 3a 2f 2f 77 |........http://w|
000000a0 77 77 2e 63 7a 38 38 2e 6e 65 74 00 00 00 00 00 |ww.cz88.net.....|
000000b0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000000c0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000000d0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000000e0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000000f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000100 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000110 00 00 00 00 00 00 00 00 |........|
00000118复制由此可见 copywrite.rar 的280字节按先后顺序分为以下部分:
43 5a 49 50,即 CZIP1899年12月30日 到发布日期的天数。这里为 f1 ac 00 00,即十六进制 0x0000acf1,转为十进制是 44273,将1899年12月30日后推44273天即为2021年03月18日。关于这里为何要将起始点设在12月30日而非12月31日,个人猜想是源作者忽略了1900年不是闰年,从而出现了这一天的误差。01 00 00 00,可能用于标记文件格式版本qqwry.rar 文件大小。这里为 39 2e 52 00,即十六进制 0x00522e39,转为十进制是 5385785,也就是 qqwry.rar 共有5385785字节。qqwry.dat 的前512个加密字节。这里为 3e 01 00 00,即十六进制 0x0000013e,转为十进制是 318,也就是初始密钥为318。b4 bf d5 e6 49 50 b5 d8 d6 b7 ca fd be dd bf e2 20 32 30 32 31 c4 ea 30 33 d4 c2 31 38 c8 d5,解译出来就是 纯真IP地址数据库 2021年03月18日68 74 74 70 3a 2f 2f 77 77 77 2e 63 7a 38 38 2e 6e 65 74,即 http://www.cz88.netqqwry.rar 的前512个字节需要使用上面提到的密钥解密,解密过程逐字节进行,每次解密后密钥均会变化。密钥用K0、K1、K2...表示,qqwry.rar 前512字节的密文按字节分别用D1、D2、D3...表示,解密后用U1、U2、U3...表示,三者类型均为无符号整数。
解密流程如下:
copywrite.rar 文件绝对偏移20-24字节(K0 * 2053) + 1 的低8位内容,得到密钥K1K(n+1) = (Kn * 2053) + 1 、Un = XOR(Kn, Dn)只需处理文件前512字节,后面的字节流直接拼接即可,完成后将得到一个由zlib压缩的文件,对其解压就能得到明文的 qqwry.dat 文件。
以下是对解密过程的PHP代码实现
<?php
$copywrite = file_get_contents("copywrite.rar"); // 读入copywrite.rar文件
$qqwry = file_get_contents("qqwry.rar"); // 读入qqwry.dat文件
$key = unpack("V6", $copywrite)[6]; // 从文件绝对偏移20字节处读入4字节,并将其转为32位无符号整数
for ($i = 0; $i < 512; $i++) { // 处理前512字节
$key = (($key * 2053) + 1) & 0xFF; // 密钥变换
$qqwry[$i] = chr(ord($qqwry[$i]) ^ $key); // 做异或运算解密对应字节
}
$qqwry = gzuncompress($qqwry); // 解压数据流
$fp = fopen("qqwry.dat", "wb"); // 打开并覆盖qqwry.dat文件
fwrite($fp, $qqwry); // 写入数据
fclose($fp);
?>复制将上述流程封装为一个脚本,实现自动下载并解密,输出 qqwry.dat 文件。
# 确保有PHP环境
shell> php -v
···PHP版本信息···
shell> vim qqwryUpdate.sh复制写入以下内容
#!/bin/sh
cd `dirname $0`
mkdir -p qqwryTemp
cd qqwryTemp
wget http://update.cz88.net/ip/copywrite.rar
wget http://update.cz88.net/ip/qqwry.rar
cat > unlock.php <<EOF
<?php
\$copywrite = file_get_contents("copywrite.rar");
\$qqwry = file_get_contents("qqwry.rar");
\$key = unpack("V6", \$copywrite)[6];
for (\$i = 0; \$i < 512; \$i++) {
\$key = ((\$key * 2053) + 1) & 0xFF;
\$qqwry[\$i] = chr(ord(\$qqwry[\$i]) ^ \$key);
}
\$qqwry = gzuncompress(\$qqwry);
\$fp = fopen("qqwry.dat", "wb");
fwrite(\$fp, \$qqwry);
fclose(\$fp);
?>
EOF
php unlock.php
cd ..
cp -f qqwryTemp/qqwry.dat qqwry.dat
rm -rf qqwryTemp/复制运行脚本即可自动获取 qqwry.dat 文件
shell> wget https://res.dnomd343.top/Share/QQWry.dat/qqwryUpdate.sh
···
shell> sh qqwryUpdate.sh
···
shell> du -b qqwry.dat
10422485 qqwry.dat复制可以使用 crontab 等定时工具,按时运行脚本拉取更新,保持 qqwry.dat 文件一直处于最新版本
# 部署定时任务
shell> crontab -e
# 设置为每天00:00时运行更新脚本,具体参数自行更改
00 0 * * * /var/www/echoIP/backend/qqwryUpdate.sh复制在得到 qqwry.dat 文件以后,使用程序自动分析结构、读取数据
从上面解压的数据可以了解到,数据库的每条记录有4个部分,分别是起始IP、终止IP、记录A、记录B,前两者构成了一个IP范围,后两者组合起来标记IP段的位置与ISP信息。起始IP与终止IP各占4字节,记录A与记录B不定长,均以字节0结束,数据为GBK编码。
记录A一般为国家、地区名,记录B一般为运营商或者具体位置,不同条目间差异较大且存在不少特殊情况,大多数情况下可将记录A与记录B分别理解为全局部分与局部部分。
一个典型的记录条目如下:
起始IP:42.83.64.0
终止IP:42.83.79.255
记录A:广东省广州市
记录B:电信天翼云计算数据中心复制在文件结构上,qqwry.dat 可分为三部分,分别是文件头、记录区和索引区,文件头指出索引区的位置,索引区信息指明记录区的偏移量。
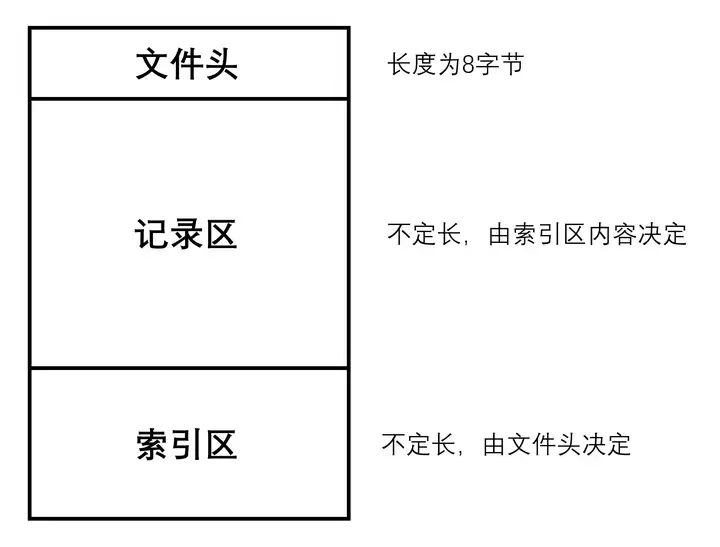
文件头共8字节,前4字节是第一条索引的绝对偏移,后4字节为最后一条索引的绝对偏移。

文件头标记出索引区的偏移量及包含范围
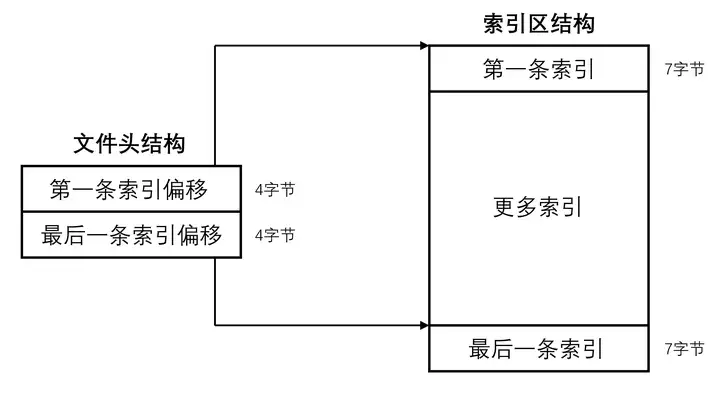
索引区由多条等长的索引连续排列而成,每条索引长度为7字节。单条索引由两部分构成,前4个字节为区间的起始IP,后3个字节为其余数据的绝对偏移量,指向记录区的一个位置。

要查找的目标IP必定处于一个IP范围内,而索引区中的起始IP是按从小到大排列的,所以可以根据指定IP匹配到相应的索引,查找到偏移量,并据此到记录区获取其他信息。
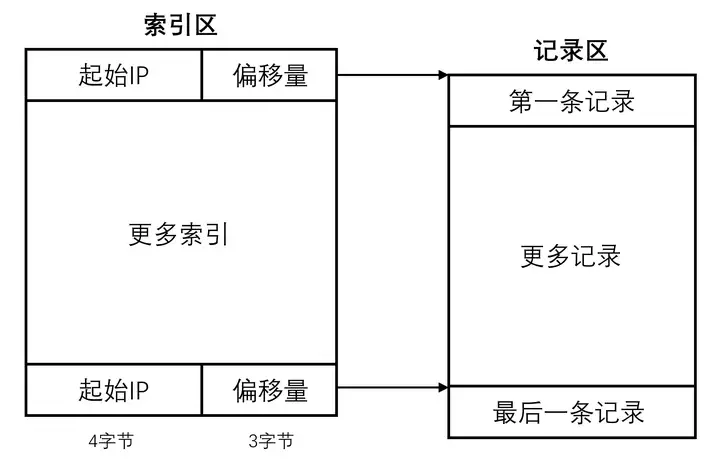
定位到目标索引后可以得到起始IP与偏移量,根据这个偏移量在记录区获取余下的终止IP、记录A和记录B三段信息。
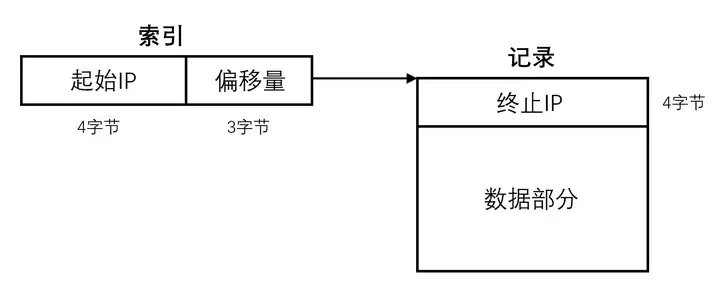
索引中偏移量指向位置的前4字节为终止IP的数据,下方数据部分存放着记录A与记录B两段信息,由于不同IP段之间记录内容存在大量重合,因此文件使用了重定向机制以节省空间,可分为5种存储方式。
这是最简单的一种格式,记录A与记录B在终止IP数据后连续存放,两者均为字符串格式,以二进制0结尾
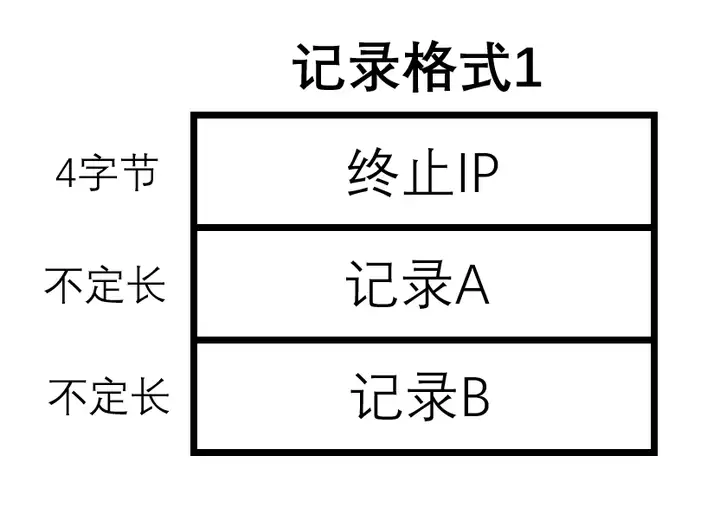
这种格式不能共用任何记录,一般用于没有重复的数据。
在这种格式下,终止IP后跟有一个重定向标志 0x01,我们暂且称其为重定向模式A。重定向标志后跟随一个偏移量,指明记录A与记录B所在位置,两者在指定的位置连续存放,同样也是字符串格式,以二进制0结尾。
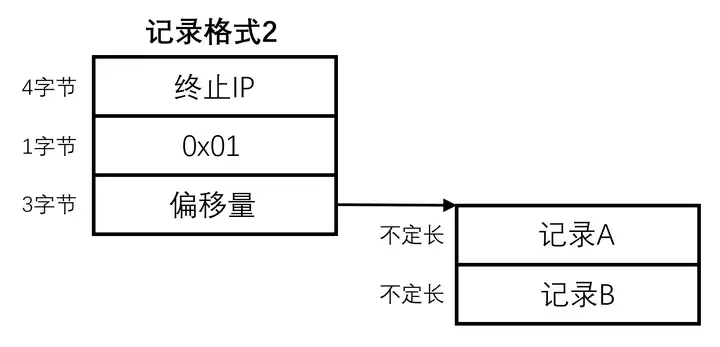
由于正常存储的字符串不会以0x01开头,因此可以与格式1区分开。
这种格式与记录模式2类似,但是只有记录A被重定向,终止IP后跟随重定向标志 0x02,我们暂且称其为重定向模式B。重定向标志后跟随一个偏移量,指出了记录A所在位置,而偏移量后紧接记录B的数据,两条记录均为字符串格式,以二进制0结尾。
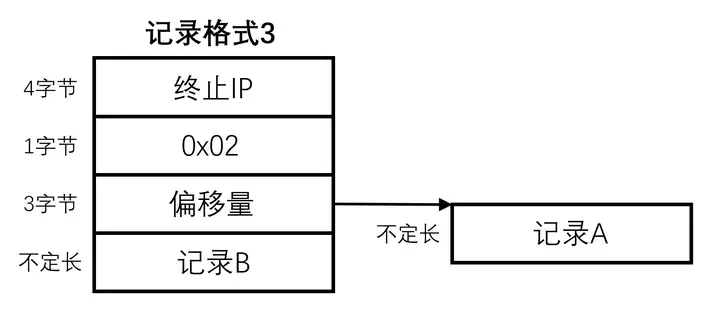
两种重定向模式以标志 0x01 与 0x02 作区分,模式A中记录A与记录B是连续存放的,而模式B的重定向仅针对记录A,记录B接在偏移量后面。
与上一种格式一样,正常字符串不会以0x02开头,因此也可以与记录模式1和2区分开。
这种方式需要重定向两次,可以看成重定向模式A与B的叠加。第一次重定向使用标志 0x01,但是偏移量所指位置又出现了重定向标志 0x02,后接的偏移量指出了记录A的内容,偏移量后同时紧跟记录B的数据,两条记录均为字符串格式,以二进制0结尾。
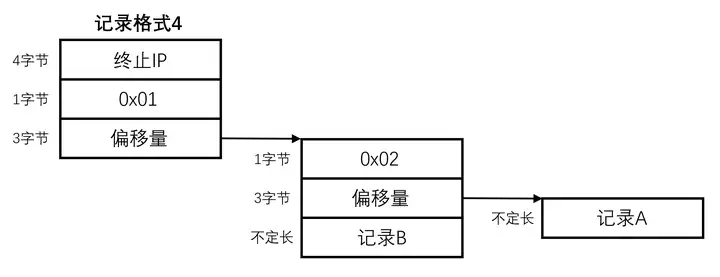
在第一次重定向时,正常字符串不会以0x01开头,因而可以与记录模式2区分开。
这是最繁杂的一种记录方式,可以看成记录模式4的一种扩展。在记录模式4的第二个偏移量后再接一个重定向标志 0x01 或 0x02,标志后有一个偏移量用于指出记录B的位置,不过这个偏移量可能为0,用于表示记录B无数据。同样的,记录A与记录B均为字符串格式,以二进制0结尾。
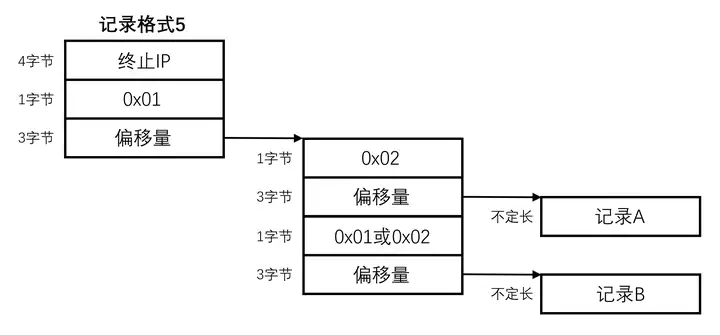
在对记录B重定向时,正常字符串同样不会以0x01或0x02开头,因此也可以与记录模式4区分开。
数据库的最后一条记录不包含IP信息,而是数据库的版本内容,格式如下:
起始IP:255.255.255.0
终止IP:255.255.255.255
记录A:纯真网络
记录B:XXXX年XX月XX日IP数据复制这一部分属于特殊IPv4段 240.0.0.0/4,被标记为 SPECIAL-IPV4-FUTURE-USE-IANA-RESERVED,即IANA特殊保留地址。对于这部分,我们必须对其劫持并返回正确的结果,一般标记为 IANA保留地址。同时,也可以根据这一段信息来提取版本号,格式为 YYYYMMDD,用于标记当前数据库的版本信息。
使用PHP实现,操作被封装为 QQWry 类,代码保存为 qqwry.php。
<?php
// 数据来源:纯真IP数据库 qqwry.dat
// 初始化类:new QQWry($fileName)
// 请求方式:getDetail($ip)
// 返回格式:
// {
// "beginIP": IP段起始点
// "endIP": IP段结束点
// "dataA": 数据段1
// "dataB": 数据段2
// }
//
// 请求版本:getVersion()
// 返回格式:YYYYMMDD
class QQWry {
private $fp; // 文件指针
private $firstRecord; // 第一条记录的偏移地址
private $lastRecord; // 最后一条记录的偏移地址
private $recordNum; // 总记录条数
public function __construct($fileName) { // 构造函数
$this->fp = fopen($fileName, 'rb');
$this->firstRecord = $this->read4byte();
$this->lastRecord = $this->read4byte();
$this->recordNum = ($this->lastRecord - $this->firstRecord) / 7; // 每条索引长度为7字节
}
public function __destruct() { // 析构函数
if ($this->fp) {
fclose($this->fp);
}
}
private function read4byte() { // 读取4字节并转为long
return unpack('Vlong', fread($this->fp, 4))['long'];
}
private function read3byte() { // 读取3字节并转为long
return unpack('Vlong', fread($this->fp, 3) . chr(0))['long'];
}
private function readString() { // 读取字符串
$str = '';
$char = fread($this->fp, 1);
while (ord($char) != 0) { // 读到二进制0结束
$str .= $char;
$char = fread($this->fp, 1);
}
return $str;
}
private function zipIP($ip) { // IP地址转为数字
$ip_arr = explode('.', $ip);
$tmp = (16777216 * intval($ip_arr[0])) + (65536 * intval($ip_arr[1])) + (256 * intval($ip_arr[2])) + intval($ip_arr[3]);
return pack('N', intval($tmp)); // 32位无符号大端序长整型
}
private function unzipIP($ip) { // 数字转为IP地址
return long2ip($ip);
}
public function getVersion() { // 获取当前数据库的版本
fseek($this->fp, $this->lastRecord + 4);
$tmp = $this->getRecord($this->read3byte())['B'];
return substr($tmp, 0, 4) . substr($tmp, 7, 2) . substr($tmp, 12, 2);
}
public function getDetail($ip) { // 获取IP地址区段及所在位置
if (!filter_var($ip, FILTER_VALIDATE_IP, FILTER_FLAG_IPV4)) { // 判断是否为IPv4地址
return null;
}
fseek($this->fp, $this->searchRecord($ip)); // 跳转到对应IP记录的位置
$detail['beginIP'] = $this->unzipIP($this->read4byte()); // 目标IP所在网段的起始IP
$offset = $this->read3byte(); // 索引后3字节为对应记录的偏移量
fseek($this->fp, $offset);
$detail['endIP'] = $this->unzipIP($this->read4byte()); // 目标IP所在网段的结束IP
$tmp = $this->getRecord($offset); // 获取记录的dataA与dataB
$detail['dataA'] = $tmp['A'];
$detail['dataB'] = $tmp['B'];
if ($detail['beginIP'] == '255.255.255.0') { // 去除附加信息
$detail['dataA'] = 'IANA';
$detail['dataB'] = '保留地址';
}
if ($detail['dataA'] == ' CZ88.NET' || $detail['dataA'] == '纯真网络') {
$detail['dataA'] = '';
}
if ($detail['dataB'] == ' CZ88.NET') {
$detail['dataB'] = '';
}
return $detail;
}
private function searchRecord($ip) { // 根据IP地址获取索引的绝对偏移量
$ip = $this->zipIP($ip); // 转为数字以比较大小
$down = 0;
$up = $this->recordNum;
while ($down <= $up) { // 二分法查找
$mid = floor(($down + $up) / 2); // 计算二分点
fseek($this->fp, $this->firstRecord + $mid * 7);
$beginip = strrev(fread($this->fp, 4)); // 获取二分区域的下边界
if ($ip < $beginip) { // 目标IP在二分区域以下
$up = $mid - 1; // 缩小搜索的上边界
} else {
fseek($this->fp, $this->read3byte());
$endip = strrev(fread($this->fp, 4)); // 获取二分区域的上边界
if ($ip > $endip) { // 目标IP在二分区域以上
$down = $mid + 1; // 缩小搜索的下边界
} else { // 目标IP在二分区域内
return $this->firstRecord + $mid * 7; // 返回索引的偏移量
}
}
}
return $this->lastRecord; // 无法找到对应索引,返回最后一条记录的偏移量
}
private function getRecord($offset) { // 读取IP记录的数据
fseek($this->fp, $offset + 4);
$flag = ord(fread($this->fp, 1));
if ($flag == 1) { // dataA与dataB均重定向
$offset = $this->read3byte(); // 重定向偏移
fseek($this->fp, $offset);
if (ord(fread($this->fp, 1)) == 2) { // dataA再次重定向
fseek($this->fp, $this->read3byte());
$data['A'] = $this->readString();
fseek($this->fp, $offset + 4);
$data['B'] = $this->getDataB();
} else { // dataA无重定向
fseek($this->fp, -1, SEEK_CUR); // 文件指针回退1字节
$data['A'] = $this->readString();
$data['B'] = $this->getDataB();
}
} else if ($flag == 2) { // dataA重定向
fseek($this->fp, $this->read3byte());
$data['A'] = $this->readString();
fseek($this->fp, $offset + 8); // IP占4字节, 重定向标志占1字节, dataA指针占3字节
$data['B'] = $this->getDataB();
} else { // dataA无重定向
fseek($this->fp, -1, SEEK_CUR); // 文件指针回退1字节
$data['A'] = $this->readString();
$data['B'] = $this->getDataB();
}
$data['A'] = iconv("GBK", "UTF-8", $data['A']); // GBK -> UTF-8
$data['B'] = iconv("GBK", "UTF-8", $data['B']);
return $data;
}
private function getDataB() { // 从fp指定偏移获取dataB
$flag = ord(fread($this->fp, 1));
if ($flag == 0) { // dataB无信息
return '';
} else if ($flag == 1 || $flag == 2) { // dataB重定向
fseek($this->fp, $this->read3byte());
return $this->readString();
} else { // dataB无重定向
fseek($this->fp, -1, SEEK_CUR); // 文件指针回退1字节
return $this->readString();
}
}
}
?>复制调用示例,文件名为 demo.php ,同目录下放置 qqwry.dat 数据文件。
<?php
include("qqwry.php"); // 引入代码
$demo = new QQWry('qqwry.dat'); // 初始化类
echo '数据库版本:' . $demo->getVersion() . PHP_EOL;
$detail = $demo->getDetail('8.8.8.8'); // 调用查询函数
var_dump($detail); // 输出查询结果
?>复制使用示例
# 确保有PHP环境
shell> php -v
···PHP版本信息···
# 获取源代码
shell> wget https://res.dnomd343.top/Share/QQWry.dat/qqwry.php
···
shell> wget https://res.dnomd343.top/Share/QQWry.dat/demo.php
···
shell> wget https://res.dnomd343.top/Share/QQWry.dat/qqwry.dat
···
# 运行测试
shell> php demo.php
array(4) {
["beginIP"]=>
string(7) "8.8.8.8"
["endIP"]=>
string(7) "8.8.8.8"
["dataA"]=>
string(6) "美国"
["dataB"]=>
string(66) "加利福尼亚州圣克拉拉县山景市谷歌公司DNS服务器"
}复制可以借鉴qqwry.ipdb项目的数据修正与提取功能,将读到的 dataA 与 dataB 进行格式化。由于项目这部分的代码由JS编写,因此必须配置Nodejs环境,考虑到要和PHP对接,可以将配置为一个网络服务。
添加 server.js 文件,默认监听TCP/1602端口
var http = require('http');
var url = require('url');
const format = require('./');
http.createServer(function(req, res){
var params = url.parse(req.url, true).query;
let info = format(params.dataA, params.dataB);
res.write("{");
res.write("\"dataA\": \"" + info['country'] + "\",");
res.write("\"dataB\": \"" + info['area'] + "\",");
res.write("\"country\": \"" + info['country_name'] + "\",");
res.write("\"region\": \"" + info['region_name'] + "\",");
res.write("\"city\": \"" + info['city_name'] + "\",");
res.write("\"domain\": \"" + info['owner_domain'] + "\",");
res.write("\"isp\": \"" + info['isp_domain'] + "\"");
res.write("}");
res.end();
}).listen(1602);
复制启动服务可以使用以下命令
# 必须有Nodejs环境
shell> node server复制也可以编写一个启动脚本 start.sh
#!/bin/bash
node server&复制使用PHP与其对接,编写 format.php 文件
<?php
function formatData($dataA, $dataB) { // 从数据中提取国家、地区、城市、运营商等信息
$str_json = file_get_contents('http://127.0.0.1:1602/?dataA=' . urlencode($dataA) . '&dataB=' . urlencode($dataB));
return json_decode($str_json, true); // 格式化为JSON
}
$data = formatData('广东省广州市', '华南理工大学机器人实验室'); // 输入记录A与记录B
var_dump($data);
?>复制完整示例如下:
# 获取文件
shell> wget https://res.dnomd343.top/Share/QQWry.dat/qqwryFormat.zip
···
shell> wget https://res.dnomd343.top/Share/QQWry.dat/format.php
···
# 解压并删除文件
shell> unzip qqwryFormat.zip && rm -f qqwryFormat.zip && cd qqwryFormat
···
# 确保有Nodejs环境
shell> node -v
···Nodejs版本信息···
# 开启格式化服务
shell> sh ./start.sh && cd ..
# 确认服务是否运行
shell> netstat -tlnp | grep 1602
tcp6 0 0 :::1602 :::* LISTEN 20831/node
# 测试查询
shell> php format.php
array(7) {
["dataA"]=>
string(18) "广东省广州市"
["dataB"]=>
string(36) "华南理工大学机器人实验室"
["country"]=>
string(6) "中国"
["region"]=>
string(6) "广东"
["city"]=>
string(6) "广州"
["domain"]=>
string(0) ""
["isp"]=>
string(9) "教育网"
}复制这里使用Nodejs将格式化工具配置为一个服务,监听本机1602端口,请求格式是 http://127.0.0.1:1602/?dataA=$dataA&dataB=$dataB,其中 $dataA 与 $dataB 是两段记录的内容,使用UrlEncode编码,返回数据是JSON字符串,交由PHP读取解析。对于给入的dataA与dataB,处理以后给回来5个解析内容,分别是 country、region、city、domain 与 isp,对应国家、行政区、城市、运营商网站与ISP名称。