http://arthurchiao.art/blog/bgp-in-data-center-zh/复制
本文是我在读 BGP in the Data Center ( O’Reilly, 2017)时的读书笔记。原书很短,只有 90 页不到,但理论和实践兼备,是现代 数据中心和 BGP 入门的很好参考。
作者 Dinesh G. Dutt 是一家网络公司的首席科学家,在网络行业有 20 多年工作经验,曾 是 Cisco Fellow,是 TRILL、VxLAN 等协议的合作者(co-author)之一。
BGP 原本是用于服务供应商(service provider)网络的,并不适用于数据中心,因此进入 到数据中心的 BGP 是经过改造的。本文介绍的就是数据中心中的 BGP(BGP in the data center),这与传统 BGP 还是有很大不同的。
以下是笔记内容。
remote-asremote-as 指定 BGP session 类型数据中心中的 BGP 就像一头怪兽(a rather strange beast)。BGP 进入数据中心是 相当意外的(rather unexpected),但现在已经是数据中心路由协议(routing protocol )的首选。
本书定位:网络运维人员和工程师,有基本的网络和 BGP 知识,想知道 BGP 在数据中 心是如何应用的。 理解本书内容无需任何 BGP 高级知识,或任何特定路由平台的经验。
本书主要目的:用一本书囊括数据中心部署 BGP 所需的理论和实践(theory and pratice)。
本书使用的 BGP 软件:FRRouting。
本章介绍在给定应用需求和预期规模的前提下,如何为现代数据中心设计网络(network design of a modern data center network)。
和十年前相比,现代数据中心规模更大,网络部署速度要求更快(秒级而不是天级)。这显 著影响了网络的设计和部署。
BGP(Border Gateway Protocol):边界网关协议。
过去的几十年里,连接到互联网(公网)的系统通过 BGP 发现彼此(find one another) 。但是,它也可以用在数据中心内部。现代数据中心中使用最广泛的路由协议就是 BGP。 BGP 是标准协议,有很多免费和开源(free and open source,这里 “free” 作者应该是指“免 费”,而不是“自由软件”的“自由”)的软件实现。
本章试图回答以下问题:
现代数据中心的演进都是由大型互联网公司的需求驱动的,例如 Google 和 Amazon。
核心需求:
服务器到服务器通信越来越多(Increased server-to-server communication)
单体应用到微服务化的转变,导致南北向流量减少,东西向流量增加。
规模(Scale)
过去,几百台服务器就已经是一个大数据中心;现在,现代数据中心一个机 房可能就有上万台服务器。
弹性(Resilience)
老式数据中心的设计都是假设网络是可靠的,而现代数据中心应用都是假设网络 是不可靠的 —— 总会由于各种原因导致网络或机器故障。弹性就是要保证发生故障时 ,受影响的范围可控,尽量做到不影响用户体验。
现代数据中心网络必须满足以上三方面基本需求。
多租户网络需要额外考虑:支持虚拟网络的快速部署和拆除(rapid deployment and teardown)。
传统网络设计的扩展方式:scale-in(垂直扩展),即通过更换性能更高的设备实现。 缺点:
大型互联网公司最后采用了一种称为 Clos 的架构。Clos 架构最初是贝尔实验室的 Charles Clos 在 1950s 为电话交换网设计的。
可以实现无阻塞架构(non-blocking architecture):上下行带宽都充分利用。
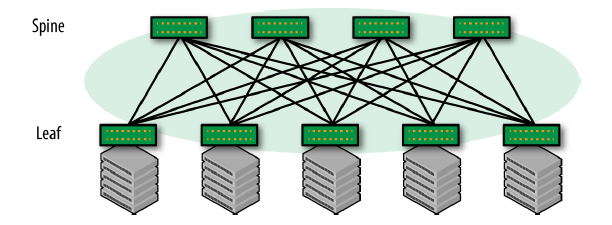
图 1-1 简单的两级(two-tier) Clos 网络
特点:
连接的一致性(uniformity of connectivity):任意两个服务器之间都是 3 跳
节点都是同构的(homogeneous):服务器都是对等的,交换机/路由器也是
全连接(full-mesh):故障时影响面小(gracefully with failures);总带宽高 ,而且方便扩展,总带宽只受限于 Spine 的接口数量
注意,在以上模型中,Spine 仅仅用于连接 Leaf,因此在这种模型中,所有的功能( functionality)都集中在 Leaf 上。
扩展方式:scale-out(水平扩展)。
最大服务器数量(无阻塞架构下):n * m / 2,其中 n 是一个 Leaf 节点的端口 数量,m 是一个 Spine 节点的端口数量。
典型带宽,分为接入(leaf-server)和互连(leaf-spine):
受电源限制,单个机柜最大不超过 40 台服务器。
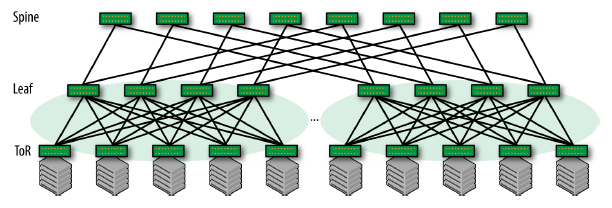
图 1-2 三级(three-tier) Clos 网络
一组 ToR 和 Leaf 组成一个二级 Clos,称为一个 pod 或 cluster; pod/cluster 作为一个独立单元再和 Spine 组成一个二级 Clos。
最大服务器数量:n * n * n /4,其中 n 是交换机端口数量。
Clos 架构的魅力:无论从哪一级看,每个组成部分都是类似的,可以方便地替换和扩容。
为了解决规模瓶颈,大型互联网公司甚至会考虑 4 级甚至 6 级 Clos 架构。
由于 Spine 和 Leaf 之间是 full-mesh,网线会特别多,排线会复杂一些。
设备故障影响面比较小,排障和更换设备方便(resilience)。
设备都是对等的,管理比较方便。
传统网络架构中,接入层和汇聚层走二层交换,因此需要运行 STP 协议消除二层环路。 如果在 Clos 网络中交换机也走二层,那可用(active)链路就会大大减少,如图 1-3 所 示:
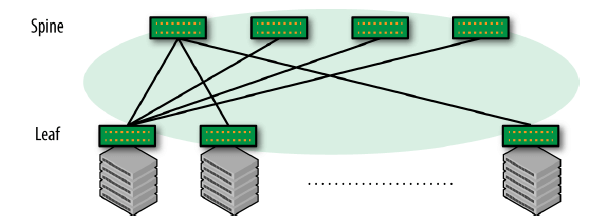
图 1-3 启用 STP 之后的网络连接
如果有链路发生故障,那可用链路的效率会更低:
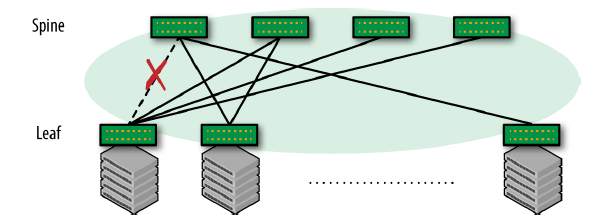
图 1-4 启用 STP 并且一条链路发生故障之后的网络连接
由此可见,走二层会导致非常低效和不均匀的连接(highly inefficient and nonuniform connectivity)。
而另一方面,如果走三层路由,那就可以充分利用 Spine 和 Leaf 之间的 full-mesh 连接。而且路由还可以判断最短路径,或者为了达到更高整体利用率设置特定的路径。
因此,第一个结论:对于 Spine-Leaf 网络,路由(三层)比交换(二层)更合适。通 过二层连接的网络称为桥接网络(bridged network);通过路由连接的网络称为路 由网络(routed network)。
使用路由的另一个好处是,避免了各种厂商相关的 STP 优化方案(将多条物理链路聚合成 一条虚拟链路提高利用率)。
典型的传统桥接网络需要运行:
如果是路由网络,那只需要:
和服务器直连的路由器(leaf)会充当 anycast gateway(也可以称为分布式网关), 此外就不需要其他协议了。
以上,就是 Clos 网络如何实现高度可扩展和弹性伸缩的。
大型互联网公司采用单接入方式(single-attach servers),即,每个服务器只连接 到单个置顶交换机。这种设计背后的逻辑是:服务器数量足够多,由于网络问题导致单个机 柜挂掉时,影响不是很大。
但是对于小型网络,乃至部分大型公司的网络,挂掉一个机柜带来的影响是不能接受的。 因此这些公司采用双接入(dual-attach servers)方式:每个服务器连接到两个置顶 交换机。
双接入方式为了提高链路利用率,会将两个链路聚合成一个虚拟链路,这个技术是厂商相关 的,因此叫法不太一样:
这需要宿主机运行链路聚合控制协议(Link Aggreration Control Protocol, LACP) 以创建 bond 链路。如图 1-5 所示。
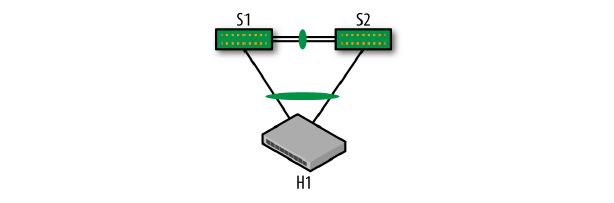
图 1-5 双接入方式下的链路聚合
对于中型或大型网络,通过 border leaf 连接到外网。
主要好处:将数据中心的网络和外部网络隔开(isolate)。数据中心内的路由协议无需和 外部交互(interact),更加稳定和安全。
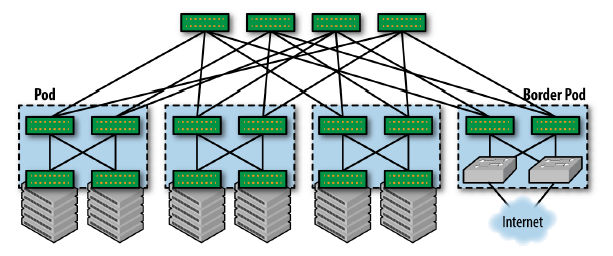
图 1-6 通过 border leaf 将一个 Clos 网络连接到外部网络
小型数据中心出于成本考虑,不会部署单独的 border leaf 节点,而是通过 Spine 连接到 外部网络,如图 1-7 所示。需要注意:这种方案中所有 Spine 都需要连接到外部网络,而 不是一部分 Spine。这非常重要,因为 Clos 网络中所有 Spine 都是对等的。
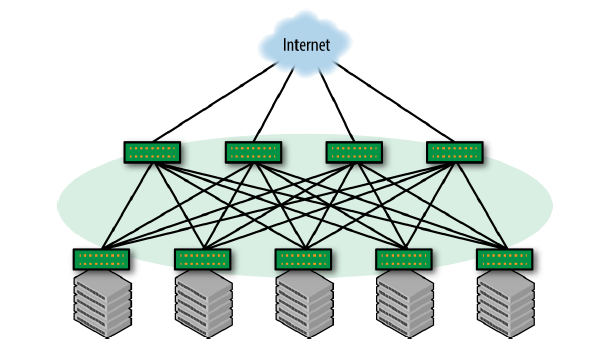
图 1-7 通过 spine 将一个 Clos 网络连接到外部网络
Clos 拓扑也适用于云计算网络,不管是公有云还是私有云。
云计算架构的额外需求:
数据中心的设计会影响到数据中心的运维。
自动化是最基本的要求(Automation is nothing less than a requirement for basic survial)。在设计的时候要考虑能使自动化运维简单、可重复(simple and repeatable)。
对企业网(enterprise network),两种协议比较合适:
它们都设计用于企业网内部,大部分企业网管理员对此应该很熟悉。
但是,OSPF 不支持多协议(例如对 IPv4 和 IPv6 需要运行两个独立协议),因此并没有 被大型互联网厂商采用。
IS-IS 支持 IPv4/IPv6,但是可选的实现比较少。而且,一些管理员认为,IS-IS 这样的链 路状态(link-state)协议不适用于 Clos 这样的富连接(richly connected)网络。
BGP 的特点:
只需对 BGP 做一些改造,就可以将它高效地应用中数据中心中。微软的 Azure 团队是最早 对 BGP 进行改造用于数据中心的。现在,我接触的大部分客户都是部署 BGP。
在下一章中,我们将看到人们对传统 BGP 进行了哪些改造,然后将它应用到数据中心的。
在 BGP 用于数据中心之前,它主要用于服务提供商网络(service provider network)。 这导致的一个问题就是,数据中心不能运行 BGP,不然会和底层供应商的网络有冲突。如 果你是网络管理和运维人员,那意识到这一点非常重要。
不同网络场景:
因此,服务提供商的网络首先是考虑可靠性(stability),其次才是(路由等)变化的快 速通知(rapid notification of changes)。因此,BGP 发送通知的实时性比较低。而在 数据中心中,管理员更希望路由更新(routing updates)越快越好。
另外,由于 BGP 自身的设计、行为,以及它作为路径矢量协议(path-verctor protocol) 的特性,单个链路挂掉会导致节点之间发送大量 BGP 消息。
第三个例子,BGP 从多个 ASN 收到一条 prefix(路由网段前缀)之后,最 终只会生成一条最优路径。而在数据中心中,我们希望生成多条路径。
为适配数据中心而对 BGP 进行的改造,见 FRC 7938。
本章描述这些改动,以及背后的考虑(rationale for the change)。这里再次强调,数 据中心使用的 BGP 和传统的 BGP 并不一样,如果不理解这一点,管理员很容易误操作造成 网络故障。
传统 BGP 从 OSPF、IS-IS、EIGRP(Enhanced Interior Gateway Routing Protocol) 等 协议接收路由通告,这些称为内部路由协议(internal routing protocols),用于控制 企业内的路由。无怪乎很多人当时认为,要在数据中心中落地 BGP,还需要另一个协议。 但实际上,在数据中心中 BGP 就是(特定的)内部路由协议,不需要再运行另一个协议 了。
数据中心内部是该使用内部网关协议(iBGP)还是外部网关协议(eBGP)?很多人觉得应 该是 iBGP,因为在数据中心内部,但其实不是。
数据中心中 eBPG 是使用最广泛的。原因;
主要原因是 eBGP 比 iBGP 更易理解和部署
iBGP 的最优路径选择算法很复杂,而且存在一些限制,使用、配置、管理复杂。
eBGP 的实现比 iBGP 多,选择面比较大
每个 BGP 节点都有一个 ASN(Autonomous System Number)。ASN 用于识别路由环境、 判断最优路径、关联路由策略等等。
ASN 有两个版本:老版用 2 个字节表示,新版用 4 个字节表示。
数据中心 BGP 中 ASN 的分配方式和公网 BGP ASN 的分配方式不同。
公网的 BGP 使用 well-known ASN,但数据中心中使用的一般都是私有 ASN,因为一般不需 要和公网做 peer。
私有 ASN 和 私有网段类似。
但注意:如果管理员真要用公网 ASN,那也是没人能阻止的。有两个原因不建议这样做:
私有 ASN 数量:
有多种分配 ASN 的方式。
如果采用每个节点一个 ASN 的方案,那会存在一个 count-to-infinity 问题。简单说就是 :每个节点不知道其他节点的物理链路状态(physical link state),因此无法判断一条 路由是真的不通了(节点挂掉)还是通过其他路径还是可达的。
当一个节点挂到后,其他节点陆续撤回(withdraw)可达路由时,导致网络内大量的 BGP 消 息。这个问题称为 path hunting。
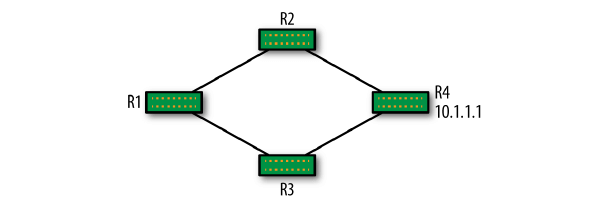
图 2-1 一个简单拓扑,解释 path hunting
为了避免 path hunting 问题,Clos 网络内的 ASN 编号模型如下:
图 2-2 是一个三级 Clos 的例子:
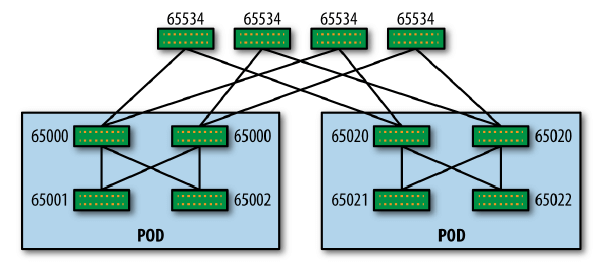
图 2-2 Clos 拓扑 ASN 编号模型示例
这种编号模型是如何解决 path hunting 问题的:以图 2-1 为例,如果 R2 和 R3 有 相同的 ASN,那 R1 收到 R2 的一条到 10.1.1.1 的消息后,再收到 R3 来的到 10.1.1.1 消息时(检测到有环路),就会拒绝后者。当 R4 挂掉时,消息回撤会很简单。
这种编号模型的缺点:无法做路由聚合或摘要(route aggregation or summarization )。还是拿图 2-1 为例,如果 R2 和 R3 通过直连的服务器总共收集到了 10.1.1.2/32 ~ 10.1.1.250/32 的可达消息。如果 R2 和 R3 做路由聚合,那只需要向 R1 通告一条 10.1.1.0/24 可达消息,而不用通告 250 次,每次一个 IP。在这种情况下,如果 R2-R4 链路挂了,那 R1 仍然认为 10.1.1.0/24 到 R4 仍然是可达的,因为可以通过 R1-R3-R4 ,但实际上有些 IP 是只能通过 R2-R4 才通的。也即路由聚合在这种情况下带来了问题。
给定一个节点的 prefix,BGP 通过算法判断到这个 node 的最佳路径。
UPDATE 消息会触发最优路径计算过程。可以对 UPDATE 消息做缓存,批量处理,具体取决 于不同 BGP 的实现。
最优路径算法中有 8 个参数,但和数据中心相关的只有一个:AS_PATH。 可以用下面这句话记这八个参数:
Wise Lip Lovers Apply Oral Mediacation Every Night.
每个字段的意思见图 2-3。
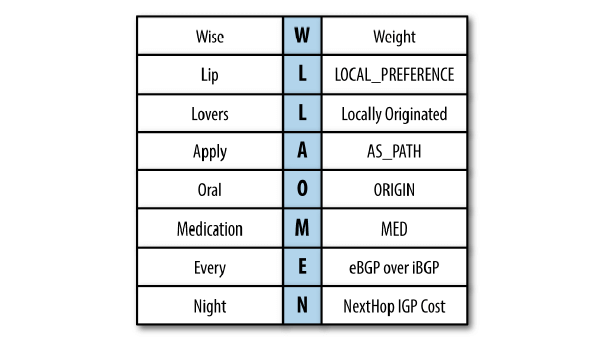
图 2-3 BGP 最优路径选择标准
对于 Clos 这种密集连接型网络,路由多路径(route multi-pahting)是构建健壮、 可扩展网络的基本要求。
BGP 支持多路径,包括对等(equal cost)和非对等(unequal cost)多路径。但支持 程度取决于具体实现。
两条路由相同的判断标准:以上八个条件都相同。其中,AS_PATH 字段一定要 ASN 相同才算相同,只是跳数相同不行。这将多路径分为了两种部署方式。
第一种方式,服务器是双接入的(直连两个 ToR),如图 2-4 所示。在这种情况下,Spine 会收到两条到服务器的路径,分别经过两个 ToR。由于两条 path 的 ASN 不一样,Spine 认为这两个 path 不同(unequal),因此最终会二选一。
第二种方式,服务器内起 VM 或容器,并且在不同服务器内有多个实例,所有实例有相同的 虚 IP (virutal IP)。由于不同服务器连接到了不同 ToR,因此 Spine 会收到多条到虚 IP 的路径,所有路径的跳数相同,但每个路径上的 ASN 不同,因此 Spine 也将它们当作 unequal path 处理。
要解决以上问题有多种方式,最简单的方式:配置最优路径算法,认为跳数相同 AS_PATH 就算相同,不管 ASN 是否相同。
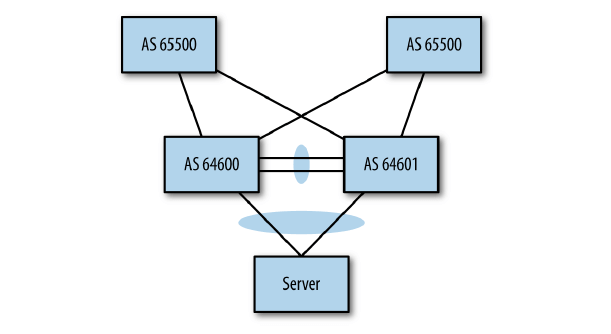
图 2-4 一个简单拓扑,解释 path hunting
简单来说,BGP 中的几个定时器控制 peer 之间通信的速度。对于 BGP,这些参数的默认值 都是针对服务提供商环境优化的,其中稳定性的优先级高于快速收敛。而数据中心 则相反,快速收敛的优先级更高。
当一个节点挂掉,或挂掉之后恢复时,有四个定时器影响 BGP 的收敛速度。对这些参数进 行调优,可以使得 BGP 达到内部路由协议(例如 OSFP)的性能。
发布路由通告的间隔。在这个间隔内的事件会被缓存,然后时间到了一起发送。
默认:eBGP 是 30s,iBGP 是 0s。
对于密集连接型的数据中心来说,30s 显然太长了,0s 比较合适。这会使得 eBGP 的收敛 速度达到 OSFP 这种 IGP 的水平。
每个节点会向它的 peer 发送心跳消息。如果一段时间内(称为 hold time)没收到 peer 的心跳,就会清除所有从这个 peer 收到的消息。
默认:
这表示每分钟发一个心跳,如果三分钟之内一个心跳都没收到,就认为 peer 挂了。
数据中心中的三分钟太长了,足以让人过完一生(Inside the data center, three minutes is a lifetime)。典型配置:
节点和 peer 建立连接失败后,再次尝试建立连接之前需要等待的时长。
默认:60s。
很多 BGP 实现的默认配置都是针对服务提供商网络调优的,而不是针对数据中心。
建议:显示配置用到的参数(即使某些配置和默认值相同),这样配置一目了然,运维和排障都比较方便。
下面是 FRRouting BGP 的默认配置,我认为是数据中心 BGP 的最优实践。在我参与过的 几乎所有生产环境数据中心都使用的这个配置:
eBGP and iBGP0s3s and 9s接下来的两章将会把本章学到的知识用到真实 Clos 环境。
运维口头禅:无自动化,即等死(automate or die)。
只要存在模式(pattern),就有可能实现自动化(Automation is possible when there are patterns)。
本书剩余部分将使用图 3-1 所示的拓扑,它代表了当前大部分数据中心网络的拓扑。
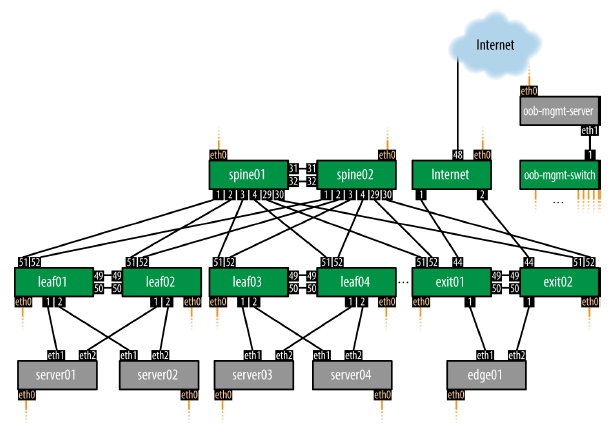
图 3-1 示例数据中心网络
接下来涉及以下节点的配置:
除了服务器之外,其他所有节点都是路由器,路由协议是 BGP。
A quick reminder: 我们使用的是 Clos 拓扑,因此 Spine 和 Leaf 节点都是路由器。
配置 3-1 网络:
router bgp 65000
配置 ASN,并开始了一个 BGP 配置 block(对 FRR)。
bgp router-id 10.0.254.1
每个节点要有一个唯一的 router-id。一种比较好的方式是,选择这个节点的 loopback IP 作为 router-id。
neighbor peer-group ISL
在 FRR 中,定义配置模板。
neighbor ISL remote-as 65500
配置对端 ASN。传统 BGP 配置需要这一项。
neighbor 169.254.1.0 peer-group ISL
使用配置模板 ISL 中的参数,和指定 IP 建立连接。
address-family ipv4 unicast
BGP 支持多协议,因此需要显式指定希望的路由协议,此处为 ipv4 unicast。
neighbor ISL activate
启用。
network 10.0.254.1/32
对外通告本节点到 10.0.254.1/32 的路由是可达的。这首先需要确保这条路由在节点的 路由表中是存在的。
maximum-paths 64
允许使用多路径。
// leaf01’s BGP configuration
log file /var/log/frr/frr.log
router bgp 65000
bgp router-id 10.0.254.1
bgp log-neighbor-changes
bgp no default ipv4-unicast
timers bgp 3 9
neighbor peer-group ISL
neighbor ISL remote-as 65500
neighbor ISL advertisement-interval 0
neighbor ISL timers connect 5
neighbor 169.254.1.0 peer-group ISL
neighbor 169.254.1.64 peer-group ISL
address-family ipv4 unicast
neighbor ISL activate
network 10.0.254.1/32
network 10.1.1.0/26
maximum-paths 64
exit-address-family
复制// leaf02’s BGP configuration
log file /var/log/frr/frr.log
router bgp 65001
bgp router-id 10.0.254.2
bgp log-neighbor-changes
bgp no default ipv4-unicast
timers bgp 3 9
neighbor peer-group ISL
neighbor ISL remote-as 65500
neighbor ISL advertisement-interval 0
neighbor ISL timers connect 5
neighbor 169.254.1.0 peer-group ISL
neighbor 169.254.1.64 peer-group ISL
address-family ipv4 unicast
neighbor ISL activate
network 10.0.254.1/32
network 10.1.1.0/26
maximum-paths 64
exit-address-family
复制// spine01’s BGP configuration
log file /var/log/frr/frr.log
router bgp 65534
bgp router-id 10.0.254.254
bgp log-neighbor-changes
bgp no default ipv4-unicast
timers bgp 3 9
neighbor peer-group ISL
neighbor ISL advertisement-interval 0
neighbor ISL timers connect 5
neighbor 169.254.1.1 remote-as 65000
neighbor 169.254.1.1 peer-group ISL
neighbor 169.254.1.3 remote-as 65001
neighbor 169.254.1.3 peer-group ISL
neighbor 169.254.1.5 remote-as 65002
neighbor 169.254.1.5 peer-group ISL
neighbor 169.254.1.7 remote-as 65003
neighbor 169.254.1.7 peer-group ISL
bgp bestpath as-path multipath-relax
address-family ipv4 unicast
neighbor ISL activate
network 10.0.254.254/32
maximum-paths 64
exit-address-family
复制// spine02’s BGP configuration
log file /var/log/frr/frr.log
router bgp 65534
bgp router-id 10.0.254.253
bgp log-neighbor-changes
bgp no default ipv4-unicast
timers bgp 3 9
neighbor peer-group ISL
neighbor ISL advertisement-interval 0
neighbor ISL timers connect 5
neighbor 169.254.1.1 remote-as 65000
neighbor 169.254.1.1 peer-group ISL
neighbor 169.254.1.3 remote-as 65001
neighbor 169.254.1.3 peer-group ISL
neighbor 169.254.1.5 remote-as 65002
neighbor 169.254.1.5 peer-group ISL
neighbor 169.254.1.7 remote-as 65003
neighbor 169.254.1.7 peer-group ISL
bgp bestpath as-path multipath-relax
address-family ipv4 unicast
neighbor ISL activate
network 10.0.254.254/32
maximum-paths 64
exit-address-family
复制总结自动化会遇到的问题:配置中使用 IP 地址的话,会有很多地方重复;新加或修改 IP 地址时很多地方都要改。
如何解决这个问题?看下面几个工具。
将一种协议收到的路由以另一种协议再发送出去,称为路由再分发(redistributing routes) 。格式:
resitribute <protocol> route-map <route-map-name>
复制<protocol> 支持:
static:通告(announce)静态配置的路由connected:通告和接口地址(interface address)相关联的路由kernel:只适用于 Linux。通过路由套件(FRRouting、bird、quagga 等)配置的路由 ,或通过 iproute2 等工具直接配置在内核的路由ospf:通过 OSPF 学习到的路由bgp:通过 BGP 学习到的路由rip:通过 RIP 学习到的路由因此,以上 network <IP> 配置就可以简化成 redistribute connected,去掉了 hardcode IP。Leaf 节点的配置变成:
log file /var/log/frr/frr.log
router bgp 65000
bgp router-id 10.0.254.1
bgp log-neighbor-changes
bgp no default ipv4-unicast
timers bgp 3 9
neighbor peer-group ISL
neighbor ISL remote-as 65500
neighbor ISL advertisement-interval 0
neighbor ISL timers connect 5
neighbor 169.254.1.0 peer-group ISL
neighbor 169.254.1.64 peer-group ISL
address-family ipv4 unicast
neighbor ISL activate
redistribute connected
maximum-paths 64
exit-address-family
复制但是,redistribute 方式也有潜在的问题。如果接口上的 IP 配错了会导致错误的路 由通告,例如如果接口配置了 8.8.8.8/32,也就是默认 DNS 地址,那所有的 DNS 请求 都会打到这个接口。
解决这个问题需要用到路由策略(routing policy)。
用最简单的话来说,路由策略就是规定哪些路由通告可以接受,哪些需要拒绝。
例如,禁止通告上面提到的 8.8.8.8 问题:
if prefix equals '8.8.8.8/32' then reject else accept
复制策略可以写成函数,支持传递参数,例如只接受本地路由:
ACCEPT_DC_LOCAL(prefix)
{
if prefix belongs to 10.1.0.0/16 then accept
else if (10.0.254.0/24 contains prefix and
subnet equals 32) then
accept
else reject
}
复制注意:建议所有变量使用大写,因为我见过的几乎所有网络配置都是这样的,不要使用 camelCase 等其他格式。
route-maps 是实现路由策略的常见方式。Cisco IOS、NXOS,以及开源的 FRRouting、 Arista 等等都支持 route-maps。BIRD软件走的更远,支持一种简单的领域特定语言 (DSL)。
route-maps 格式:
route-map NAME (permit|deny) [sequence_number]
match classifier
set action
复制其中的 sequence_number 规定了在 route-maps 内 clause 的匹配优先级。
以下的策略:
route-map EXCEPT_ISL_ETH0 deny 10
match interface swp51
route-map EXCEPT_ISL_ETH0 deny 20
match interface swp52
route-map EXCEPT_ISL_ETH0 deny 30
match interface eth0
route-map EXCEPT_ISL_ETH0 permit 40
redistribute connected route-map EXCEPT_ISL_ETH0
复制和以下为代码是等价的:
EXCEPT_ISL_ETH0(interface)
{
if interface is not swp51 and
interface is not swp52 and
interface is not eth0 then
redistribute connected
}
复制route-maps 对 BGP 处理的影响BGP 是路径矢量协议,因此它在运行完最优路径算法之后,才会通告路由更新。
route-maps 会应用到每个收到和发出的包。
如果 BGP 有大量的邻居,同时有大量的和邻居相关的 route-maps,最优路径计算过程 将非常慢,不仅消耗大量 CPU 资源,而且使得路由通告变慢,即路由收敛变慢。
解决这个问题的一种方式是使用 peer-group。将有相同路由策略的邻居放到一个 group 。一般都是由实现完成,不需要手动配置。
FRRouting 的一个特性,可以自动推断出接口的 IP 地址,因此策略中可以指定端口而不是 IP。
Leaf 节点:
// leaf01’s BGP configuration
log file /var/log/frr/frr.log
ip prefix-list DC_LOCAL_SUBNET 5 permit 10.1.0.0/16 le 26
ip prefix-list DC_LOCAL_SUBNET 10 permit 10.0.254.0/24 le 32
route-map ACCEPT_DC_LOCAL permit 10
match ip-address DC_LOCAL_SUBNET
router bgp 65000
bgp router-id 10.0.254.1
bgp log-neighbor-changes
bgp no default ipv4-unicast
timers bgp 3 9
neighbor peer-group ISL
neighbor ISL remote-as 65500
neighbor ISL advertisement-interval 0
neighbor ISL timers connect 5
neighbor swp51 peer-group ISL
neighbor swp52 peer-group ISL
address-family ipv4 unicast
neighbor ISL activate
redistribute connected route-map DC_LOCAL
maximum-paths 64
exit-address-family
复制// leaf02’s BGP configuration
log file /var/log/frr/frr.log
ip prefix-list DC_LOCAL_SUBNET 5 permit 10.1.0.0/16 le 26
ip prefix-list DC_LOCAL_SUBNET 10 permit 10.0.254.0/24 le 32
route-map ACCEPT_DC_LOCAL permit 10
match ip-address DC_LOCAL_SUBNET
router bgp 65001
bgp router-id 10.0.254.2
bgp log-neighbor-changes
bgp no default ipv4-unicast
timers bgp 3 9
neighbor peer-group ISL
neighbor ISL remote-as 65500
neighbor ISL advertisement-interval 0
neighbor ISL timers connect 5
neighbor swp51 peer-group ISL
neighbor swp52 peer-group ISL
address-family ipv4 unicast
neighbor ISL activate
redistribute connected route-map DC_LOCAL
maximum-paths 64
exit-address-family
复制Spine 节点:
log file /var/log/frr/frr.log
ip prefix-list ACCRT 5 permit 10.1.0.0/16 le 26
ip prefix-list ACCRT 10 permit 10.0.254.0/24 le 32
route-map DC_LOCAL permit 10
match ip-address ACCRT
router bgp 65500
bgp router-id 10.0.254.254
bgp log-neighbor-changes
bgp no default ipv4-unicast
timers bgp 3 9
neighbor peer-group ISL
neighbor ISL advertisement-interval 0
neighbor ISL timers connect 5
neighbor swp1 remote-as 65000
neighbor swp1 peer-group ISL
neighbor swp2 remote-as 65001
neighbor swp2 peer-group ISL
neighbor swp3 remote-as 65002
neighbor swp3 peer-group ISL
neighbor swp4 remote-as 65003
neighbor swp4 peer-group ISL
bgp bestpath as-path multipath-relax
address-family ipv4 unicast
neighbor ISL activate
redistribute connected route-map DC_LOCAL
maximum-paths 64
exit-address-family
复制将配置模板化,避免具体 IP:
redistribute connected 替换 network <IP>route-maps 安全策略但以上还不够通用,下一章继续。
本章将展示如何通过 remote-as 彻底去掉配置中的接口的 IP 地址,这将使得 BGP 的配 置非常:
非常便于自动化。
要实现这个目标,首先需要理解一个和路由同样古老的概念:unnumbered interfaces ,以及我们如何将它适配到 BGP。
remote-asBGP 基于 TCP/IP 协议,因此需要一个 IP 地址才能建立连接。
在没有为(本地)接口分配 IP 地址的情况下,如何确定远端节点的地址呢?要回答这 个问题,需要理解一个稍微有点冷门的 RFC 协议,以及 IPv6 提供的无状态配置工具( stateless configuration tools)。同时,这也涉及到了路由问题的核心(real heart of routing)。
第二个问题是,每个 BGP 配置都需要知道对端 ASN。但依赖这个 ASN 只是为了以此判断 session 是被 iBGP 还是 eBGP 规则管理。
是否真需要给每个接口配置一个 IP 地址?
考虑一个简单的两级 Clos:4 个 spine,32 个 leaf,这种规模的网络很常见。对于这个网 络,需要 4 * 32 * 2 = 256 个 IP 地址。如果 leaf 数量变成 96 —— 这种规模也很常见 —— 那总 IP 数量就是 4 * 96 * 2 = 768 个。如果 spine 数量增加到 16 个,那 IP 数量 就变成 3072 个。
可以看到,这种方式下,所需的 IP 数量随着 spine 和 leaf 数量及接口数量的增加而 急剧增加。而这些 IP 除了 建立 BGP session 之外没有任何其他用途。为什么不想办法 干掉它们呢?
关于 Numbered Interfaces 的哲学思考(Philosophical Aside)
在传统三层网络中,为每个可寻址的接口(addressable interface endpoint)分配一个 IP 地址是很常见的操作。但这也引出一个问题:这些 IP 地址到底是属于一个接口,还 是这台 node?
与此相关的一个更实际的问题是:如果一台 node 收到一个 ARP 请求,请求的 IP 是 node 的另外一个接口上的 IP,而并不是接收到 ARP 包的这个接口的 IP,那 node 需要 回 ARP 应答吗? 路由器的回答是 NO。如果想让路由器支持,必须打开“ARP 代理”(proxy-arp)功能。 Linux 的回答是 YES,它这样设计是为了使通信范围尽量大。
ICMP 的设计进一步强化了接口必须有 IP 地址的思想。数据包转发失败的时候,ICMP 只 汇报有问题的 endpoint 的 IP 地址。它并不会报告其他信息,比如 endpoint 的域名( DNS name)。这(打印 IP 地址)有什么帮助?traceroute 可以据此判断出哪台 node 的哪个接口出了问题。
最后,给一根网线两端的接口配置同一网段的两个 IP 地址,是穷人验证网线是否工 作正常的方式。
Unnumbered Interface:没有配置 IP 地址的接口。
注意,这种情况下,接口并不是没有 IP 地址,而是从 node 的其他接口借 IP 地址来用。 但是,如果被借的那个接口挂了,这个 IP 自然也就不可用了。因此,为了保证借来的 IP 永 远可用,被借的接口便永远不能挂,这个接口就是:loopback interface。
路由器能够在 unnumbered interface 上应答 ARP,因为接口可以借 IP。ICMP 和 traceroute 也能正常工作。那么,这样不就无法区分出一个包是从哪个接口进入 路由器的吗?
Clos 网络的任意两个 node 之间只有一条链路,也即,任何两个 node 之间都只有唯一的 一对接口。因此不会出现上面提到的问题。如果有多条链路,的确会无法区分从哪个接口 进入路由器,但是多条链路的情况在 Clos 网络中是非常罕见的,原因在第一章分析过。
那么,路由协议是怎么处理 unnumbered interface 的呢?OSPF(运行在 IP 协议之上)可 以正常工作,其 RFC 里面描述了这方面的设计。大部分厂商的实现可能不支持,但 FRRouting 支持。Unnumbered OSPF 已经在很多生产环境部署。IS-IS,不依赖 IP 协议, 也可以在 unnumbered interface 场景下正常工作。
BGP 到底是如何在接口没有 IP 的情况下正常工作的呢?
在路由协议的世界里有一个“鸡生蛋蛋生鸡”问题。如果路由协议是用来通告路由可达信息的 ,那么它本身是如何知道对端的可达信息的呢?一些协议通过引入一个链路特定的组播地 址(link-specific multicast address)来解决(组播会限制在链路层)。BGP 不能这样 做,因为它依赖 TCP,而 TCP 需要的是单播而不是组播包。BGP 的解决方式是:连接路 由器的接口使用一个共享的子网。
同子网的接口之间通信只需要二层,不需要三层。子网之内的路由称为 connected route ,因为子网内都是在链路层直接可达的。
回到 BGP peer 如何管理通信的问题,传统 eBGP 就是通过 connected route 发现邻居的 ,无需其他配置。
那么,我们如何在没有用户配置,以及接口没有配置 IP 地址的情况下,发现对端的 IP 地 址的呢?
这就涉及到了 IPv6,以及一个有点晦涩的标准,RFC 5549。
IPv6 的架构设计是:无需显式配置,网络就可以尽量正常地工作。因此,IPv6 网络中的每个 link 都会自动分配一个 IP 地址,并且是(在链路层)是唯一的,一般是根据 MAC 地址算出来 的。这个地址叫链路本地地址(Link Local Address,LLA)。LLA 只能被直连的邻居 访问,并且必须是通过这个 LLA 接口(即不支持 ARP 代理之类的)。
为了使得服务器可以自动发现路由器邻居(neighboring routers),引入了一个新的链路 层协议,称为路由器通告(Router Advertisement,RA)。启用后,RA 会定期通告接 口的 IPv6 地址,包括 LLA。因此各节点就可以自动发现其他节点的 IPv6 地址了。
现在,服务器和路由器都已经广泛支持 LLA 和 RA。
另外需要注意的是,使用 IPv6 LLA 并不需要部署 IPv6 网络;这种方案也并不涉及任何隧 道协议。IPv6 LLA 只是用于 BGP 创建连接。只需要开启 LLA 和 RA 功能即可。
LLA 和 RA 解决了 peer IP 的自动发现和 BGP 连接的建立,但是没有说明节点如何才能到 达 RA 里的路由。 在 BGP 中,这是通过 RA 里面的 NEXTHOP 属性实现的。如果 IPv4 路由可以使用 IPv6 地 址作为下一跳,那 unnumbered interface 的目标就能够实现。
BGP 支持多协议,单个连接上允许多种协议族的路由通告与撤回。因此,BGP IPv4 UPDATE 消息可以通过 IPv6 TCP 连接发送,反之亦然。这种方式也不需要任何的隧道技术。
BGP UPDATE 消息说,NEXTHOP 的协议必须与路由通告消息本身所使用的协议相同,即, IPv4 路由只能通告 IPv4 下一跳,IPv6 路由只能通告 IPv6 下一跳。如果接口上没有 IPv4 地址,那 IPv4 下一跳是哪里呢?这就进入了 RFC 5549。
RFC 5549 解决的问题是:通过纯 IPv6 网络通告 IPv4 路由,并路由 IPv4 包( advertisement of an IPv4 route and routing of an IPv4 packet over a pure IPv6 network)。即,它提供了一种下一跳是 IPv6 地址的 IPv4 路由(carray IPv4 routes with an IPv6 nexthop)。
原理上来说这其实很好理解,因为二层网络中下一跳 IP 只是用来获 取对端的 MAC 地址(IPv4 ARP,IPV6 ND)。因此只要有同一接口上的任意一个地址(不管 是 IPv4 还是 IPv6),就可以获取到对端 MAC,然后就可以将包发送到下一跳。
BGP 网络自动初始化过程:
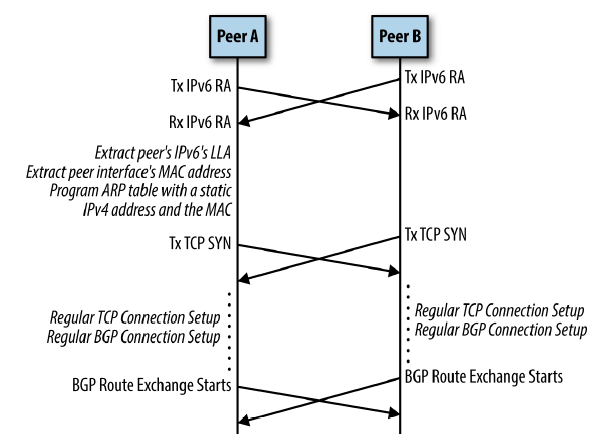
图 4-1 BGP unnumbered packet timeline sequence
在 FRRouting 中,BGP 会将最优路由发送到一个叫路由信息数据库(Routing Information Base,RIB)的进程(在 FRRouting 中这个进程是 zebra)。
RIB 存储所有协议类型的路由,如果到同一路由有多条路径,RIB 会选择距离最短的一条 。
我们假设收到一条路由通告,路由为 10.1.1.0/24。通过消息中的 NEXTHOP 可以拿到对 端的 MAC 地址。接下来 RIB 会在路由表里将下一跳设为一个保留的(或看起来非法的) IPv4 地址 169.254.0.1,然后在 ARP 表里将这个 IP 地址对应的 MAC 地址设为对端接口的 MAC 地址。
ROUTE: 10.1.1.0/24 via 169.254.0.1 dev swp1
ARP: 169.254.0.1 dev swp1 lladdr 00:00:01:02:03:04 PERMANENT
复制至此,就可以正常转发到这个 IPv4 网段的路由了(虽然路由器两端的接口都没有配置 IPv4 地址)。
如果一段时间内没有收到这条路由的通告,就认为这条路由失效了,会删去上面的两行配置 。
总结:
以 IPv6 作为下一跳的 IPv4 路由毕竟还是和通常的不太一样,因此 RFC 5549 定义了一个 新的能力,叫 extended nexthop,然后通过 peering session 进行协商,以判断两边 的 BGP 能力。
每个 eBGP peer 在发送路由通告之前,都会将 NEXTHOP 设为自己的 IP 地址。
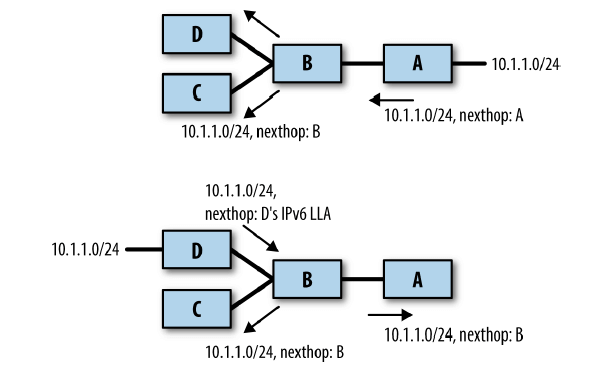
图 4-2 基于 RFC 5549 的互操作
图 4-2,假设路由器 B 和 D 支持 RFC 5549,A 和 C 不支持。由于 A 和 C 不支持,因此 B 和 A 之间的接口以及 B 和 C 之间的接口,都需要配置 IPv4 IP 地址。
当 A 通告到 10.1.1.0/24 可达时,nexthop 地址必须填它自己的 IPv4 地址。当 B 收 到这个消息,进一步通告给 D 和 C 时,分两种情况:
反向的类似。
remote-as 指定 BGP session 类型以上配置消除了显示配置 IP 地址。接下来看如何通过 remote-as 配置 ASN。
配置 ASN 有两个主要目的:
在数据中心内不存在跨管理域的问题,因此安全不是 ASN 的主要目的。因此,数据中心中 ASN 的主要目的就是判断 iBGP 还是 eBGP 控制着 session。
判断方法:从 BGP OPEN 消息中的 ASN 判断。
通过避免接口的 IP 地址,以及通过 remote-as 指定 ASN 的类型(iBGP or eBGP),配 置可以简化成下面这样。可以看到,除了 router bgp <id> 和 bgp router-id <ip> 这两行需要单独配置之外,其他所有配置都是一样的,不管是对 Spine 还是 Leaf 节点。
// leaf01 configuration
log file /var/log/frr/frr.log
ip prefix-list DC_LOCAL_SUBNET 5 permit 10.1.0.0/16 le 26
ip prefix-list DC_LOCAL_SUBNET 10 permit 10.0.254.0/24 le 32
route-map ACCEPT_DC_LOCAL permit 10
match ip-address DC_LOCAL_SUBNET
router bgp 65000
bgp router-id 10.0.254.1
neighbor peer-group ISL
neighbor ISL remote-as external
neighbor swp51 interface peer-group ISL
neighbor swp52 interface peer-group ISL
address-family ipv4 unicast
neighbor ISL activate
redistribute connected route-map ACCEPT_DC_LOCAL
复制// spine01 configuration
log file /var/log/frr/frr.log
ip prefix-list DC_LOCAL_SUBNET 5 permit 10.1.0.0/16 le 26
ip prefix-list DC_LOCAL_SUBNET 10 permit 10.0.254.0/24 le 32
route-map ACCEPT_DC_LOCAL permit 10
match ip-address DC_LOCAL_SUBNET
router bgp 65534
bgp router-id 10.0.254.254
neighbor peer-group ISL
neighbor ISL remote-as external
neighbor swp1 interface peer-group ISL
neighbor swp2 interface peer-group ISL
neighbor swp3 interface peer-group ISL
neighbor swp4 interface peer-group ISL
address-family ipv4 unicast
neighbor ISL activate
redistribute connected route-map ACCEPT_DC_LOCAL
复制这种配置,很适合用 ansible 之类的工具在多台节点上推了。
下一章:
如何 BGP 配置之后,行为和预期的不一致,怎么排查?本章回答这些问题。
show ip bgp summaryshow ip bgp ipv4 unicast summaryshow ip bgp ipv6 unicast summaryshow ip bgp neighbors <neibhor_name>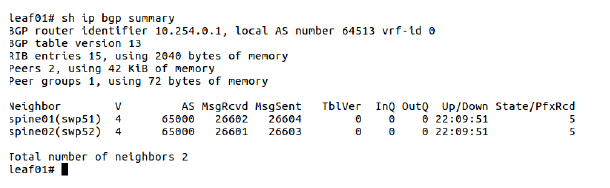
图 5-1 查看 BGP 网络信息
show ip gbpshow bgp ipv4 unicastshow ip gbp <prefix>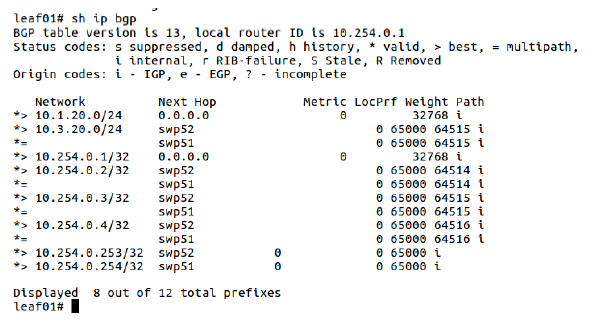
图 5-2 查看 BGP 路由信息
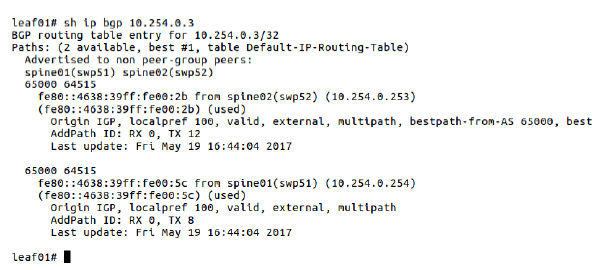
图 5-3 查看 BGP 路由详细信息
图 5-4 查看 BGP neighbor 详细信息
如图 5-4,两个 border leaf 节点 exit01 和 exit02 将数据中心网络连接到互联网 。Border leaf 的两个作用:
neigbor <neibhor_name> remove-private-AS allaggregate-address <summary-route> summary-only,其中 summary-only 关键字表示,禁止通告单条路由(individual routes),如果没有指定 这个选项,聚合之后的路由和原始路由都会通告出去。例如,如果计划对 spine01 进行升级,那要通知其他 peer 在计算最优路径时,要绕开 spine01。
第一章介绍过,现代数据中心都会有两个以上 Spine,中型到大型企业网一般都是 4 个 。如果是 4 个 spine,那维护一台时,网络仍然能提供 75% 的容量;如果是两台 spine, 那维护一台时,只能提供 50% 的容量。
如果服务器是双接入的(直连两个 ToR),那只有 50% 的链路利用率。大型互联网公司解 决这个问题的办法是:改用单接入(single-attach),庞大的机柜数量使得挂掉单个机柜 带来的影响足够小。另外还采用 16 或 32 spine,这样单个 spine 挂掉,只影响 1/16 或 1/32 的交换机间流量。
最常用的手段:将 node 的 ASN(重复)加在自己的路由通告里面,这样它的 AS_PATH 跳数就会比其他的路径要多,导致最优路径选择的时候,不会经过这个 node。
例如,要对 spine02 进行维护:
route-map SCHED_MAINT permit 10
set as-path prepend 65000 65000
neighbor ISL route-map SCHED_MAINT out
复制路由收敛之后,最优路径就会绕开 spine02:
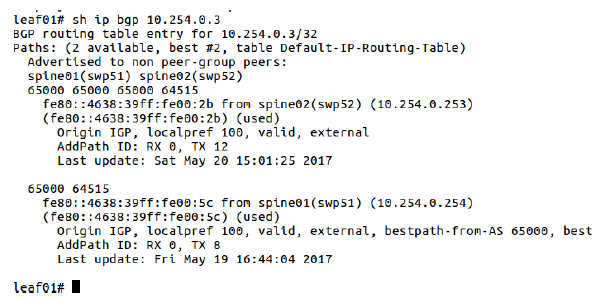
图 5-5 最优路由绕开了 spine02
这种方式是比较通用的;另外也有一些其他方式完成类似功能,但不是所有实现都支持。
打开 debug 开关,查看日志等。因实现而异。
现代数据中心颠覆了我们以往对计算和网络的所有认知。不管是 NoSQL 数据库、新 应用架构或微服务的出现,还是 Clos 网络用路由代替桥接做底层通信的方式,都为 以前既成的设计思想画上了句号。而这也影响了防火墙和负载均衡器等服务的部署。
本章将看到一种新网络模型:路由过程如何(从硬件交换设备)进入到了服务器内部, 以及我们如何对服务器做 BGP 配置以使它们和 ToR 或 leaf 通信。
传统来说,网络管理员的管理边界是 ToR,服务器内部的配置和管理由服务器管理员负责。 而在现代数据中心中,两种管理员已经开始合并为一种管理员,或者至少,网络管理员的管 理边界以及深入到了服务器内部。
传统数据中心中,桥接和路由的边界,以及 L2-L3 网关,都是部署防火 墙和负载均衡器的地方。这些物理边界和传统的客户端/服务器模型边界也是比较匹配的。
Clos 网络打破了这些自然边界,使得以上部署模型都失效了。
新的数据中心中,服务都是跑在物理服务器内的虚拟机内,或者是没有虚拟化的物理 服务器。这些虚拟机都能够快速的创建和删除,随着应用流量而扩缩容。
虚拟机会出现在数据中心的任意服务器内,因此 IP 不再会固定到单个机柜或路由器,多个 机柜可能会通告同一个 IP。通过路由的 ECMP 转发功能,包会被转发到最近的一个节点。 这种被多个实例同时通告的 IP 称为任播(Anycast) IP 地址。 它们属于单播(unicast)IP 地址,因此他们的目标是单个终点(作为对比,组播和广播的 目标是多个终点),但是,这个终点是路由过程(routing)决定的,从多个提供相关服务 的实例中选择一个。
ToR 如何发现或通告(discover or advertise)anycast IP?
置顶交换机和服务器做 BGP Peering 有两种模型:
接下来比较两种模型的异同。
两者相同的地方:
最常见的部署方式:所有服务器共用一个 ASN。
优点:
缺点:
第二种方案:直连相同 ToR 的服务器共用同一个 ASN,不同 ToR 下面的服务器使用不同 的 ASN。相当于每个机柜一个 ASN。
优点:服务器变成了新的 Clos 层(服务器和置顶交换机 full-mesh,确实是 Clos 架构的新的一层)。
缺点:和上面第一种方案缺点类似,不过现在每个 ASN 的范围缩小到了一个机柜。
第三种方案:每个服务器一个 ASN。我知道确实有一些人这样做,但是我觉得这样粒度细过 头了(overkill)。
优点:
缺点:
现在在网络层面,服务器也是一个路由器,和 leaf、spine 并没有区别,因此必须做好安全 控制。
第一,对服务器通告的路由,ToR 要能确定接受哪些,拒绝哪些。 例如:如果服务器通告了一个错误或非法路由,就会将部分流量引导到错误的地方。
第二,确保 ToR 不要将服务器当作(可以转发大量网络流量的)中间节点,服务器扛 不住这种硬件网络级别的流量。
第三,和服务器直连的路由器只通告默认路由,这样做是为 了避免路由器将太多路由通告到服务器,撑爆服务器的路由表,或影响最佳路由决策等等。
要满足以上条件,就需要用到我们第 3 章介绍的路由策略(routing policies)。例如, 下面是实现以上需求的路由策略:
ip prefix-list ANYCAST_VIP seq 5 permit 10.1.1.1/32
ip prefix-list ANYCAST_VIP seq 10 permit 20.5.10.110/32
ip prefix-list DEFONLY seq 5 permit 0.0.0.0/0
route-map ACCEPT_ONLY_ANYCAST permit 10
match ip address prefix-list ANYCAST_VIP
route-map ADVERTISE_DEFONLY permit 10
match ip address prefix-list DEFONLY
neighbor server route-map ACCEPT_ONLY_ANYCAST in
neighbor server route-map ADVERTISE_DEFONLY out
neighbor server default-originate
复制其中,
neighbor server route-map ACCEPT_ONLY_ANYCAST in 实现了:从 server 来的路由通告,只接受 ANYCAST_VIP 里面有的 anycast IPneighbor server route-map ADVERTISE_DEFONLY out 实现了:只对 server 通告默认路由部署防火墙和负载均衡器的 BGP 模型。有两种:
BGP 默认监听所有 IP 过来的 TCP 连接请求。动态邻居是 BGP 的一个特性,可以指定只监听特 定网段过来的连接请求。
例如,一个机柜里的服务器一般都是同一网段。假设为 10.1.0.0/26。那对 ToR 做以下 配置,它就只会接受 10.1.0.0/26 网段的过来的、ASN 是 65530 的 peer 的建立连 接请求。
neighbor servers peer-group
neighbor servers remote-as 65530
bgp listen range 10.1.0.0/26 peer-group servers
复制同理,对服务器做如下配置,可以限制它只和 ToR 建立连接:
neighbor ISL peer-group
neighbor ISL remote-as external
neighbor 10.1.0.1 peer-group ISL
复制但是,动态邻居特性目前不支持针对接口做配置,例如不支持 bgp listen interface vlan10 peer-group servers。
可以限制动态邻居的数量:neighbor listen limit <limit number>。
主要优点:和单接入服务器模型非常匹配,并且服务器要是通过 PXE(Preboot Execution Environment)启动的。如图 6-1。
图 6-1 BGP 动态邻居模型
路由器和服务器之间也支持 BGP unnumbered,和第四章介绍的路由器之间的 unnumbered 类似。这种方式的拓扑如图 6-2:
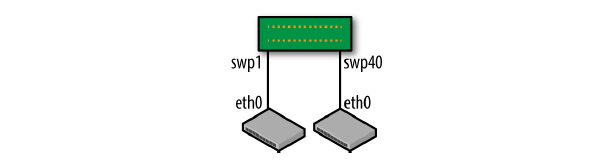
图 6-2 BGP unnumbered 模型
动态邻居模型基于共享子网,而 unnumbered 模型不需要共享子网。和路由器类似,服务器 的 IP 地址和接口是没有关系的,一般配置为 loopback 地址。每个服务器可以分配一个 /32 地址。因为通告 IPv6 LLA 和路由器做 peer,因此无需共享的子网。
ToR 配置:
neighbor peer-group servers
neighbor servers remote-as external
neighbor swp1 peer-group servers
neighbor swp2 peer-group servers
...
复制服务器配置:
neighbor eth0 remote-as external
复制优点:
缺点:
有办法解决这个问题,但这超出了本身讨论的范围。
至此,网络设计领域的老兵会意识到:服务器上跑的 BGP 其实只是一个 GBP speaker, 不需要最优路径计算、将路由添加到路由表等全套 BGP 功能。大型互联网公司也意识到 了这一点,因此他们会运行一些能作为 BGP speaker 的软件,例如 ExaBGP。
更注重全功能的软件有 FRRouting 和 BIRD。FRRouting 对 BGP unnumbered 和动态邻居两种模型 都支持。
本章展示了如何将 BGP 扩展到服务器内部。