http://arthurchiao.art/blog/ceph-osdi-zh/复制
本文翻译自 2006 年 Sage Weil 的论文:Ceph: A Scalable, High-Performance Distributed File System (PDF)。
标题直译为:《Ceph:一个可扩展、高性能的分布式文件系统》。
本文对排版做了一些调整,以更适合网页阅读。
和大多数分布式存储系统只支持单一的存储类型不同,Ceph 同时支持三种:
Ceph 最早是计划做文件系统(上面第一种)的,并将大部分精力都投入于此,但文件 系统一方面很难搞(尤其是 POSIX 语义和性能),另一方面且更重要的是:需求并不非 常强烈。
与此同时,云计算开始起飞:
随着云计算的兴起,块存储和对象存储的需求越来越强烈,此君审时度势果断调转方向 ,尤其是搭上随后几年 OpenStack 的快车,将块存储和对象存储发展地比较成熟。例如虚 拟机镜像的存储,很多使公司都不用 OpenStack 自带的块存储组件,而是用 Ceph。而对象 存储方面,Ceph 一开始就是兼容 OpenStack Swift(OpenStack 自带的对象存储组件)协 议的。
不管是出于避免重复早轮子还是快速占领市场的目的,Ceph 这里的做法都很值得借鉴。例 如,Ceph 的对象存储并没有自己再设计一套 API,而是选择兼容两个业内主流的 API(事 实上的标准),分别对应公有云和私有云:
因此使用这两个 API 的用户,只要将认证配置成 Ceph 集群,其他几乎不用动(某些 S3 高级或新特性的支持还是有滞后的,这也可以想得到),就可以切换到 Ceph,切换成本 很低。
Ceph 的三种存储类型目前在业内的使用频率:块存储 > 对象存储 > 文件系统。 如果你没有用文件系统,那大可跳过文中 metadata server(MDS,只有 CephFS 会用到 )相关的部分(第 3、4 节)。另外注意这是 2006 年的文章,Ceph 的最新行为请参考官 方最新文档,或相应版本的代码。
最后很有意思的一点:本文在成果自夸时所用的形容词是我看过的所有学术论文(和 商业文档)中最(略显)夸张的。
和 Amazon Dynamo、Google Bigtable 等脱胎于一线大厂的分布式存储都是先在生产环境 稳定运行才发表的文章不同,Ceph 来自实验室,Weil 的博士研究(这也是为什么很 多人批评 Ceph 的设计太理想化),最终走入了生产。从学术走向生产,其实比从生产 走向学术更加困难,因为它离一线的真实需求更远,而需求是地表最强驱动力。从这一点来 说,Ceph 能发展到今天还是挺不容易的(当然,后面被 Redhat 收购后资源投入和市场宣 传轻松了很多),也必定有很多独特的优势。
翻译仅供个人学习交流。由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问, 请查阅原文。
以下是译文。
我们开发了 Ceph —— 一个具备良好的性能、可靠性和可扩展性的分布式文件系统。
在由不可靠的(unreliable)对象存储设备(object storage device,OSD)组成的 异构和动态集群上,Ceph 用伪随机数据分布函数(pseudo-random data distribution function,即下文将介绍的 CRUSH)代替了常用的分配表(allocation table)方式, 从而最大程 度上将数据和元数据的管理分离开来。
另外,Ceph 将数据复制、故障检测和故障恢复都下放到了半自治的(semi-autonomous )、运行着特殊的本地对象文件系统(specialized local object file system)的 OSD,从而充分利用了设备智能(device intelligence)。
Ceph 的动态、分布式元数据集群(dynamic distributed metadata cluster)提供了极强 的元数据管理能力,并且能无缝地适配到范围广泛的通用和科学计算文件系统负载。
性能测试显示,在不同类型的负载下,Ceph 都展现出了优良的 I/O 性能和可扩展的元数 据管理能力,能够支持每秒 250K 次以上的元数据操作。
长久以来,系统设计人员都在想方设法提高文件系统的性能,因为经验已经证明,对于非常 广泛的一类应用来说,这是提高应用的整体性能的关键。科学计算和高性能计算领域尤 其如此,它们驱动了分布性存储系统的性能和可扩展性的提升,并且通常提前若干年就能预 测到一些通用的需求。
传统方式,以 NFS [20] 为代表,提供了一个简单直接的模型:服务器暴露一个 文件系统层级(file system hierarchy),客户端将其映射成本地目录(local name space)。虽然使用广泛,但已经证明,这种客户端/服务器模型固有的中心式设计是性能扩 展的重大障碍。
较新一些的分布式文件系统已经采用了基于对象的存储架构。这种架构中,传统的硬盘已 经被智能的对象存储设备(object storage device,OSD)所取代,一个 OSD 由 CPU 、网卡、底层磁盘或 RAID 及其本地缓存构成 [4, 7, 8, 32, 35]。
传统客户端的访问接口是在块级别(block-level)读写字节范围(byte ranges) ;对象存储架构中,OSD 已经将接口替换为读写更大的(通常大小不同的)有名字的对象 (named objects),而将更底层的块分配决定权交给设备本身。客户端通常和 metadata server(MDS)交互来执行元数据操作(open、rename),但直接和 OSD 通信来执行文 件 I/O (read、write),因此可以极大提升整体的可扩展性。
但是,采用这种模型的系统还是会遇到扩展性的限制,因为元数据的操作几乎没有、甚至 根本没有进行分散(distribution)(到不同节点)。传统文件系统的一些设计原则( 如 allocation list 和 inode table)限制,以及没有把智能下放到 OSD,进一步 限制了扩展性和性能,增加了可靠性的成本。
本文提出 Ceph:一个性能和可靠性优良(excellent)、扩展性无与伦比的( unparalleled)的分布式文件系统。
我们的架构基于如下假设:PB 级的存储系统本质上是动态的。因此,
Ceph 用生成函数(generating function)替代了 allocation table,从而实现了数据和 元数据操作的解耦。这使得 Ceph 可以利用 OSD 提供的智能将很多方面的复杂度进行分散 ,例如:
Ceph 元数据集群采用了一种高度自适应的分布式架构,显著提升了元数据访问的可扩展 性,而这进一步提升了整个系统的可扩展性。后面会讨论哪些负载类型的假设促使我们将架 构设计成了这样,以及架构的目标,分析它们对系统的可扩展性和性能的影响,最后会介绍 现在已经实现的设计原型(prototype)的性能。
Ceph 有三个主要组件,如图 1 所示:
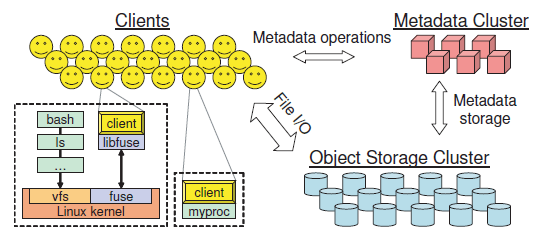
图 1 Ceph 系统架构
consistency 和 coherency 中文都是“一致性”,但前者一般指副本之间的一致性,后者 一般指缓存一致性,为避免歧义,接下来尽量对这两个词不作翻译。类似的还有文中的 safety 和 security。译者注
说 Ceph 的接口是 准 POSIX 的(near-POSIX)是因为,我们发现如果要更好的和应用的 需求对接、提升系统的性能,那完全可以对这套接口进行扩展,选择性地放宽一致性的语 义。
Ceph 架构的首要目标是:
可扩展性是从多个方面衡量的,包括整体存储容量和系统吞吐,单个客户端、目录或文件 的性能等。
我们的目标负载(workload)会包括一些极端场景:成千上万的机器并发地读或写同一 个文件,或者在相同的目录并发地创建文件。这样的场景在超级计算集群中的科学计算应用 中比较常见,而未来的通用目的 workload 也逐渐有这个趋势。更重要的是,我们意识 到分布式文件系统的负载本质上是动态的,随着应用和数据随时间不断变化,数据和元 数据的访问量变化也非常大。
Ceph 在解决了扩展性的同时还取得了很高的性能、可靠性和可用性,这依赖的是底层的 三个设计特性:
Ceph 将文件的数据存储和元数据管理进行了最大程度的解耦。元数据操作( open、rename 等)由 metadata server 统一管理,客户端直接和 OSD 通信执行文件 I/O(read、write)。
基于对象的存储很早就宣称要将底层的块分配(block allocation)决定权交给每个设备, 以提高文件系统的可扩展性。但是,和当前的那些基于对象的文件系统 [4, 7, 8, 32] 只 是将很长的块列表(block list) 变成较短的对象列表(object list) 不同, Ceph 完全去掉了 allocation list。
在 Ceph 中,文件数据变成了名字可以预测的对象,然后用一个精心设计的、称为 CRUSH [29] 的数据分布函数将对象分配到存储设备上。这使得任何一方都可以计算 (而不是查询)组成一个文件的所有对象的名字和位置,而无需再维护和分发对象列 表,简化了系统的设计,降低了元数据集群的工作量。
典型的文件系统中元数据操作可能会占一半的负载 [22],因此有效的元数据管理对整 体的系统性能至关重要。
Ceph 采用了一种全新的、基于 Dynamic Subtree Partitioning(动态子树分割)[30] 的 元数据集群架构,可以自适应地、智能地在几十甚至上百个 MDS 之间分发管理文件系统 目录结构的任务。(动态的)层级化分割保留了每个 MDS 的负载的局部性(locality) ,使得更新和预取(prefetch)更加高效。更重要的是,如何在不同 MDS 之间分发负载完 全取决于当前的访问特点(access pattern),使得 Ceph 在任何负载特点下都可以高效地 利用可用的 MDS 资源,取得和 MDS 数量呈近乎线性的扩展性。
由几千台设备组成的大型系统本质上是动态的:它们是增量搭建的,新的节点会加进来,老 的节点会淘汰出去,节点故障是家常便饭,大量的数据会创建、移动和删除。 这些因素对数据分布(distribution of data)提出的要求是:能随着可用的资源而动 态变化,维持期望的数据复制级别(desired level of data replication)。
Ceph 将数据迁移、复制、故障检测和故障恢复的职责都下放给了存储数据的 OSD 集群,从 高层看,所有 OSD 对客户端和 metadata server 呈现的是单个的、逻辑的对象仓库。 这种方式使得 Ceph 可以充分利用到每个 OSD 提供的智能(CPU 和内存),实现可靠的、 高可用的、线性扩展的对象存储。
接下来介绍 Ceph client、metadata server 集群的操作,以及分布式的对象仓库,以及它 们是如何受架构的关键特性影响的。另外,还会介绍到我们的原型当前的状态。
本节通过描述 Ceph 客户端(第 3、4 节都是指 CephFS 客户端,简称客户端,译者注)操 作来介绍 Ceph 组件的整体操作(overall operations)及其和应用的交互。
Ceph 客户端给应用提供一个文件系统接口。在目前的原型中,客户端代码完全运行在 用户态,可以通过链接的方式使用,也可以通过 FUSE [25](一个用户态文件系统接口)挂 载成文件系统。
每个客户端维护自己的数据缓存,独立于内核页或缓冲区缓存(kernel page or buffer caches),使得链接到客户端的应用可以直接访问。
当进程打开一个文件时,客户端会向 MDS 发送一个请求。MDS 会遍历文件系统层级,将文 件名翻译成文件的 inode 信息,其中包括一个唯一的 inode 号、文件 owner、模式、大小 ,以及其他一些每个文件各自的元数据(per-file metadata)。如果文件存在并且被授予 了访问权限,MDS 会返回 inode、文件大小和 striping 策略(将文件数据映射到对象。 stripe:使…带有条纹,种类,军阶,译者注)。
MDS 可能还会赋予客户端一个 capability(如果客户端没有),规定可以执行哪些操作 。capability 现在包括四个比特位,控制客户端的读、缓存读(cache read)、写和缓冲 写(buffer write)。将来还会包括一些安全参数(security keys),只有客户端向 OSD 证明它已经获得授权,才能读写数据 [13, 19](现在的原型信任所有的客户端)。 文件 I/O 中接下来 MDS 参与的内容仅限于管理 capability,以保持文件的一致性和正确 的语义。
Ceph 对一系列 striping 策略(将文件数据映射到对象列表)进行了通用化。为避免使用 allocation table,对象的名字仅由 inode number 和 stripe number 构成。对象副本通 过 CRUSH —— 一个全局皆知的映射函数(见 5.1 节)—— 分配给 OSD。
例如,如果一个或多个客户端打开一个文件准备读取,MDS 会赋予这些客户端读和将文件内 容进行缓存的 capability。有了 inode number、布局(layout)、文件大小信息之后,客 户端就可以定位到文件所对应的所有对象,从相应的 OSD 集群中直接读取。任何不存在的 对象或字节范围(byte ranges)都定义为文件“空洞”(holes),或者零值(zeros)。
类似的,如果一个客户端打开一个文件准备写,它会被授予写和对写进行缓冲的 capability,文件中生成的任何的内容都会写到合适的 OSD 中合适的对象里。
关闭文件时,客户端放弃 capability,向 MDS 返回新的文件大小(写的最大 offset), 因此重新定义了这个文件对应的对象集合(set of objects)。
POSIX 语义明确地要求:
当一个文件被多个客户端打开,这些客户端都是写操作、或有读有写时,MDS 会撤回之前授 予的的任何对读进行缓存(read caching)和对写进行缓冲(write buffering) capability,强制客户端对这个文件的 I/O 是同步的。也就是说,每个应用的读或写操作 会被阻塞,直到收到 OSD 的确认(acknowledge),因此有效地将更新顺序化(update serialization)和同步(synchronization)的负担交给了存储这些对象的 OSD。
当写会跨对象边界时,客户端需要向这些受影响的对象获取独占锁(由相应的 OSD 授权), 然后快速提交写和释放锁操作,以取得期望的顺序化。对象锁的使用方式类似,通过异步的 获取锁然后 flush 数据的方式,减少大的写入操作的延迟。
毫无疑问,同步 I/O 操作是性能杀手,会增加延迟(尤其是数据很小的读和写) —— 和 OSD 通信至少需要一次来回。
虽然读写共享(read-write sharing)在通用计算中相对比较少见 [22],但在科学计算中 很常见 [27],后者对性能的要求非常高。因此,人们经常会放松一致性的约束,不 再严格遵守一些非常严格、但应用又用不到的标准。 虽然 Ceph 通过一个全局开关也提供了这种功能,而且很多分布式文件系统还押宝在这项优 化上,但这毕竟是一个不精确的、也不令人满意的解决方案:要么性能受损,要么在系 统级丢失了一致性(consistency is lost system-wide)。
正是出于这个原因,高性能计算(HPC)社区提出了一系列对 POSIX I/O 接口的高性能计算 扩展 [31],Ceph 实现了其中的一个子集。这其中就包括 open() 接口的一个 O_LAZY flag,允许应用显式地对共享写文件(shared-write file)放松通常的 coherency 限制。 感知性能的、自己维护一致性的应用(例如,HPC 中一种常见方式就是写到同一文件的不同 位置 [27])就可以缓冲写(buffer write)或缓存读(cache read),而本来是只能执行 同步 I/O 的。
应用甚至可以通过两个额外的调用进行显式同步:
lazyio_propagate:将给定字节范围 flush 到对象仓库lazyio_synchronize:保证之前的 propagation(写传导)完成才允许接下来的读因此,Ceph 同步模型通过同步 I/O 提供了正确的读写(read-write)和共享写( shared-write)语义,保持了简单性;另一方面,通过放松一致性的限制给感知性能的分布 式应用扩展了应用接口。
客户端和文件系统命名空间的交互是由 metadata server 集群来管理的。读操作( readdir、stat 等)和更新操作(unlink、chmod 等)MDS 都是同步应用的,以保 证顺序性、一致性、正确的 security 和 safety。为保持简单,没有授予客户端 metadata 锁或租约。尤其是对于 HPC,callback 只能带来很小的好处,但会带来很大的潜在复杂度 的提升。
因此,Ceph 只对最常见的 metadata 访问场景进行了优化。
一次 readdir 之后紧接着对每个文件进行 stat(例如,ls -l)是非常常见的访问 模式,而且对大目录是显而易见的性能杀手。
一次 readdir 在 Ceph 中只需要一次 MDS 请求,它能获取到整个目录,包括 inode 内 容。默认情况下,如果一次 readdir 之后紧跟着一个或多个 stat,会返回(前面的 readdir 操作之后)缓存的简单的信息(briefly cached information);否则,这些信 息被丢弃。虽然牺牲一点 coherence ,因为其中的某个 inode 可能会在期间被修改而无法 察觉,但换来的是巨大的性能提升,我们还是乐意为之的。readdirplus [31] 扩展就是 为这个场景设计的,它会返回 lstat 结果以及目录项(一些操作系统相关的 getdir 实现已经这么做了)。
Ceph 本可以通过将 metadata 缓存更长的时间来进一步放松一致性的限制,和 NFS 的早期 版本很像,典型情况下缓存 30s。但是,这种方式破坏了 coherency,而 coherency 对很 多应用来说都是非常关键的,例如通过 stat 确定一个文件是不是更新过了。这种场景下 ,这些应用要么工作不正常,要么就是等到老的缓存失效。
因此,我们对这些影响性能的接口进行了扩展,保证行为的正确性(和 POSIX 预期行为是 一致的,译者注)。举个例子:对一个被多个客户端打开进行写操作的文件进行 stat 操 作。为了返回正确的文件大小和修改时间,MDS 撤回所有的 write capability,以立即停 止更新操作,然后从所有的 writer 收集最新的 size 和 mtime 信息。stat 返回最大的 那个值,然后重新向 writers 颁发写 capability,继续它们的写入。 虽然停止多个 writer 的写看上起比较重量级,但保证正确的顺序性是非常必要的。(对于 单个 writer 的情况,不需要停止写操作就可以获取正确的信息)。
对于那些不需要 coherency 特性的应用 —— 也就是需求和 POSIX 接口不符 —— 可以使用 statlite [31],它可以指定一个掩码,表示 inode 的哪些比特位是不需要保持 coherency 的。
Metadata 操作经常占据了文件系统多达一半的负载,并且还在关键路径上,因此 MDS 集群 对于系统的整体性能非常关键。
Metadata 管理也对分布式系统的扩展性提出了挑战:虽然容量(capacity)和聚合 I/O 性 能可以随着存储节点的增加几乎无限制地扩展,但 metadata 操作却涉及到更多的依赖 ,使得 consistency 和 coherence 的扩展性更加难。
Ceph 中文件和目录的元数据非常小,几乎只由目录项(文件名)和 inode(80 字节)构成 。和传统文件系统不同,Ceph 不需要记录文件分配信息的元数据(file allocation metadata)—— 对象名是根据 inode number 构建出来的,然后利用 CRUSH 分散到不同 OSD 上。这简化了 metadata 负载,允许 MDS 高效地管理非常庞大的文件集,而和文件的大小 无关。
我们的设计还力求最小化元数据相关的磁盘 I/O,通过使用一个两级存储策略(two-tiered storage strategy),使用 Dynamic Tree Partition [30] 最大化 locality 和缓存效率 。
虽然 MDS 集群的目标是用内存缓存提供大部分的请求,但是 metadata 的更新必须要写入 到磁盘,以保证数据的 safety。
我们利用了许多大容量、有上限(bounded)、惰性 flush 的 journal,这些 journal 使 每个 MDS 用一种非常高效和分布式的方式,流式地将更新的元数据快速写到 OSD 集群。 每个 journal 有几百兆大小,并且会吸收(absorb)重复的(repetitive)元数据更新( 对大部分来说都比较常见),因此当它最终将 journal entries 写到磁盘之前 ,有些更新就已经标记为过期了。
虽然我们目前的原型还没有实现 MDS 的恢复过程,但 journal 的设计中,当 MDS 发生故 障时,其他节点会快速的扫描 journal,恢复失败的节点中内存缓存(为了快速恢复)的内 容,进而恢复文件系统状态。这种这几同时实现了两方面好处:
尤其是,inode 直接嵌入在目录中,使得 MDS 通过单次 OSD 读操作就可以预取到全部的目 录信息,充分利用其中提供的 directory locality [22]。
每个 directory content 写入 OSD 的方式,和 metadata journal 以及文件数据使用的 striping 和分布策略一样。
inode number 是 MDS 批量分配的,在目前的原型中是不可变的,但将来可能会改为文件删 除后 inode 就会回收的方式。
一个多用途的 anchor table [28] 保存了使用很少、但被多个硬链接所引用、使用 inode number 全局可寻址的的 inode —— 这个 table 处理的场景完全和常规的单链接文件场景分 开。
An auxiliary anchor table [28] keeps the rare inode with multiple hard links globally addressable by inode number—all without encumbering the overwhelmingly common case of singly-linked files with an enormous, sparsely populated and cumbersome inode table.
我们的 primary-copy 缓存策略使得对任意一份 metadata,只有一个权威的 MDS 负责管理 缓存一致性和更新顺序化。
大部分现有的分布式文件系统,都是采用某种形式的基于静态子 树分割的方案进行权威的委派的(delegate authority)(通常方式是强制一个管理员将数 据集切割成较小的静态 “volumes”);一些近期的和试验性质的文件系统已经开始利用哈希 函数分散目录和文件元数据 [4],在负载分发的同时尽量减少 locality 损失。但是,这两 种方式都有严重的局限性:
Ceph 的 MDS 集群基于动态子树分割策略 [30],能在节点之间自适应地按层级(hierarchically )分发缓存的元数据 (cached metadata),如图 2 所示。
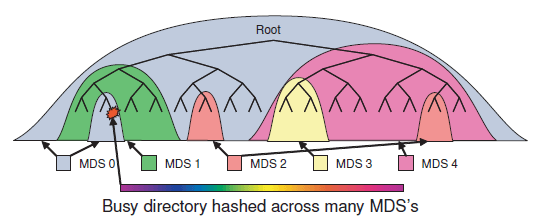
图 2 Ceph 动态将目录层级子树映射到 MDS,目录成为热点后会动态分散到多个 MDS 节点
每个 MDS 都会使用指数时间衰退的计数器(counters with an exponential time decay) ,测量目录层级(directory hierarchy)内的元数据热度(popularity )。
每次操作时,受影响的 inode 以及它向上直到根目录的所有祖先节点上的计数器都会增加 。最终呈现给 MDS 的就是一棵能反映最近一段时间负载分布的权重树(weighted tree)。 MDS 会定期地比较负载的高低,并迁移目录层级中大小合适的子树,以保持负载的均衡分布 。共享的长期存储和精心设计的命名空间锁使得这种元数据迁移只需将内存缓存中的部分内 容转移到新的权威,而对 coherence lock 或客户端 capability 影响最小。
为 safety 起见,导入的元数据会写入新 MDS 的 journal,导入和导出双方还有额外的 journal entry 保证权威的转移(transfer of authority)能够抵御其他的故障干扰(和 两阶段提交类似)。
The resulting subtree-based partition is kept coarse to minimize prefix replication overhead and to preserve locality.
当元数据复制到多个 MDS 节点时,inode 信息会分为三组,每组有不同的一致性语义:
immutable fields 不会变,但 security 和 file locks 是受独立的状态机管理的,每个 状态机有不同的状态集合和状态转移,为不同访问和更新模式(different access and update patterns)最小化锁竞争。例如,在遍历树进行 security check 时需要 owner 和 mode,但是这个两个字段变化非常少,因此需要的状态就只有几个;而 file lock 反映的 是类型更广泛的客户端端访问模式,因为 MDS 授予客户端 capability 是受它控制的。
将目录层级分割到多个节点上可以平衡一大类负载,但对于多个客户 端同时访问同一文件或目录的这种热点或突发访问,它不能保证永远能应对。
Ceph 利用元数据的热度信息(knowledge of metadata popularity)在必要时 做热点的分散,在通常情况下,这不需要额外的开销,也不会破坏 directory locality。
被大量读的目录(例如,很多 open)的内容会选择性地复制到多个 MDS 节点以分散负载 。对于非常大的或写负载非常高的目录(例如,很多文件创建操作),目录内容会通过对文 件名做哈希分散到其他节点,用牺牲目录 locality 换来负载的均衡分布。
这种自适应的方式使得 Ceph 集合了多个粒度的分割方案,可以对不同的场景和文件系统的 不同部分分别利用最合适的粗粒度或细粒度分割。
每个 MDS 的响应里都有更新之后的权威信息,以及相关的 inode 及其祖先是否被复制到其 他节点信息,这使得客户端可以了解到元数据的分割信息。接下来,对于给定的一个路径( path),基于已知的最深前缀(based on the deepest known prefix of a given path) ,元数据操作就会分成两类:
普通的客户端学习到的是非热点的(未复制的)元数据位置,能够直接和合适的 MDS 进行 正常的通信。而访问热点元数据的客户端,会被告知不同的或是多个 MDS 节点,有效的将 每个 MDS 上的客户端数量限制在一个范围内,在潜在的热点来临之前就将其分散了。
从高层看,Ceph 客户端和 metadata server 将对象存储集群(可能有成千上万个 OSD) 视为一个单一的、逻辑的对象仓库和命名空间(single logical object store and namespace)。
通过以分布式的方式(distributed fashion)将对象复制、集群扩展、故障检测和故障恢 复的管理下放到 OSD,Ceph 的 RADOS(Reliable Autonomic Distributed Object Store, 可靠的、自治的分布式对象存储)拥有了线程扩展的能力 —— 不管是用容量(capacity)还是 用聚合性能(aggregate performance)衡量。
Ceph 必须将 PB 级的数据分布在上千个存储设备组成的、不断进化的集群上,这样集群的 存储和带宽资源才能得到有效利用。
为避免不平衡(例如,新加入的设备大部分都是空闲的)或负载不对称(例如,新热点数 据只出现在新设备上),我们采用了如下的数据分布策略:
这套随机算法非常健壮,在任何类型的负载上都工作良好。
对象到 OSD 的映射分两步:
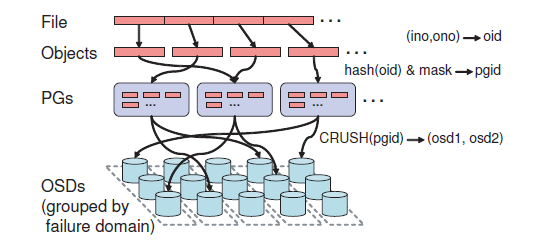
图 3 文件映射(strip)到多个对象
Ceph 首先会用一个简单的哈希函数将对象映射到 PG,其中有一个位掩码( bit mask)控制 PG 数量。我们选取这个值使得每个 OSD 有 100 个 PG 左右(量 级),以平衡 OSD 利用率和每个 OSD 维护的复制相关的元数据(replication related metadata)。
然后,通过 CRUSH(Controlled Replication Under Scalable Hashing ,基于可扩展哈希的、受控的复制)[29] 将 PG 映射到 OSD。CRUSH 是一个伪随机数 据分布函数,能够高效地将 PG 映射到一个存储对象副本的 OSD 列表。
和传统方法(包括其他基于对象的文件系统)不同的是,这里数据的放置(placement) 不依赖任何块或对象列表的元数据(block or object list metadata)。
CRUSH 只需要两个信息来定位一个对象:
这种方式有两个好处:
因此,CRUSH 同时解决了两个问题:
在设计中,集群的小变动对现有 PG mapping 的影响非常小,因此最小化了设备故障或集群 扩容时需要迁移到数据量。
cluster map hierarchy 和集群的物理或逻辑结构,以及潜在的故障源都是对应的。 例如,一套机柜列、机柜、服务器、OSD 组成的存储集群,可能就会形成一个四层结构。
每个 OSD 还有一个权重,控制它应该被分配的相对数据量。
CRUSH 基于 placement rules(放置规则)将 PG 映射到 OSD,其中放置规则定义了复 制级别(level of replication)和放置的限制。例如,系统可以将 PG 复制到 3 个 OSD ,落到同一个机柜 row(限制 inter-row 复制流量),但分到不同的机柜(为了最小化电 源或边界交换机故障所受的影响)。
cluster map 还维护了 down 和 inactive 的设备列表,以及一个 epoch number(纪 元号,表示相对时间),每次 OSD cluster map 都变化,epoch 都会加 1。 所有的 OSD 请求都会带 client 的 map epoch,因此所有的参与方都可以就当前的数 据分布达成一致共识。
互相合作的 OSD 之间会共享 map 的增量更新,如果 client 的 map 过期了, OSD 响应中会把这些更新带上(piggyback on OSD replies)。
Lustre [4] 这样的系统假设:通过 RAID 或者 fail-over to SAN 这样的机制能够打造 出足够可靠的 OSD。与此不同,Ceph 的假设是:对于 PB/EB 级的存储系统,故障 是常态而不是意外(failure will be the norm rather than exception)。
为了保持系统的可用性,以及以可扩展的方式保证数据的 safety,RADOS 使用 primary-copy replication [2] 的一个变种管理自己的数据复制,以最小化对性能的 影响。数据以 PG 为单位复制,每个 PG 会映射到一个有序的、包含 N 个 OSD 的列表 (对于 N 方复制)。
client 将写请求发送给对象的 PG 对应的 OSD 列表中第一个状态正常的( non-failed)OSD(primary OSD),这个 OSD 会给对象和 PG 分配一个新版本号,然后 将请求转发给其他的副本 OSD。当所有副本都应用了这次更新并向 primary OSD 返回响 应之后,primary OSD 才将更新应用到本地,然后应答给 client 表示写完成。
读操作会定位到 primary OSD。
这种方式简化了副本同步或串行化对客户端复杂度的影响,因为在有其他写操作或故障恢复 的情况下,这会非常繁琐。另外,还将复制消耗的带宽从客户端侧移动到 OSD 集群内部网 络,通常后者的资源更充足。
副本 OSD 故障的情况这里不作讨论(见 5.5 节),随后的恢复过程能可靠地恢复副本的一 致性。
在分布式系统中,为什么数据要写到共享存储本质上有两个原因。
首先,客户端希望它们的更新对其他客户端可见。这要求系统比较快:写操作应该越快生效 越好,尤其是多个客户端同时写,或有度有写导致客户端必须串行操作的时候。
第二,客户端希望它们写的数据已经非常可靠地做了副本,落到了磁盘上,能够经受掉电 或其他故障。
在更新操作的应答机制上,RADOS 将同步(synchronization)和** safety** 解耦,使 Ceph 同时实现了:
图 4 展示了一次对象写入操作过程中的各种消息。
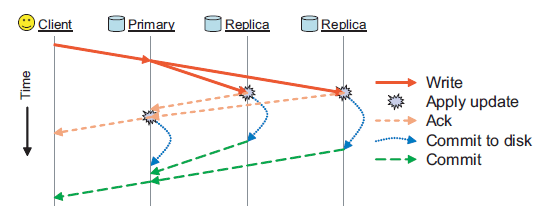
图 4 写操作示意图
primary OSD 将更新发送给副本 OSD,等所有 OSD 都将更新应用到内存中的缓冲区( in-memory buffer cache)后,primary OSD 会回一个 ack,这样使用同步 POSIX 调用的客户端就可以返回了。
当数据安全地(safely)写到磁盘后,primary OSD 会再发送一个 commit 消息给 客户端(可能是几秒钟之后了)。
我们等到数据发送到全部副本之后才向客户端返回 ack,是为了容忍 OSD 挂掉的情况, 虽然这增加了客户端的响应延迟。
默认情况下,客户端还会在提交之前对写进行缓冲(buffer writes),以避免一个 PG 对应的所有 OSD 因为掉电同时挂掉带来的数据丢失风险。
在这种场景下恢复时,RADOS 在接受新更新之前,允许重放(replay)之前一段时间内已经 确认过的(因此是有序的)更新。
及时的故障检测对维护数据的 safety 非常重要,但随着集群扩大到几千台设备,故 障检测变得越来越难。
对于某些特定类型的故障,例如磁盘错误和数据损坏,OSD 可以主动上报。但对于那些会导 致 OSD 失联的故障,就需要使用主动监控(active monitoring),RADOS 的做法是:让共享 PG 的 OSD 互相监控彼此。
在大部分情况下,副本同步的流量(existing replication traffic)都可以被动证 明(passive confirmation)节点还活着,而且这种证明不需要额外通信开销。如果 peer 节点一段时间内没有收到一个 OSD 过来的流量,就会向其显式地发送 ping 包。
RADOS 将 OSD liveness 分为两个维度:
不响应的 OSD 会先被置为 down,接下来的任何 primary 职责(更新顺序化,复制 )都临时地转发给每个 PG 对应的下一个 OSD。
如果这个 OSD 没有很快恢复,就会标记为“停止向这个 OSD 分布数据”(marked out of the data distribution),另外一个 OSD 会加入到 PG 的 OSD 列表,同步这个 OSD 的数据。在故障的 OSD 上有 pending 操作的客户端会重新将请求提交给新的 primary OSD。
很多网络异常都会导致 OSD 连接的短暂抖动,因此我们引入了一个小 monitor 集群,统一 收集故障汇报(failure reports)信息,过滤掉短时的(transient)或系统性的问题(例 如网络分裂)。Monitor(现在只实现了一部分)使用选举、主动 peer 监控、短期租约和 两阶段提交等技术来提供对 cluster map 的一致的、可用的访问。
当有故障或恢复导致 map 变化时,受影响的 OSD 会递增自己在 map 中的版本号,然 后在 OSD 之间的通信上捎带上这些变动信息,分发给整个集群。
分布式检测可以在不给 monitor 增加负担的情况下实现快速检测,而检测的结果又提交给 monitor 集中解决出现的不一致问题。
最重要的是,Ceph 将 OSD 标记为 down 而不是 out 的设计,使得在发送系统性问题 (例如一半的 OSD 突然断电)的时候,避免了大范围的数据搬移(re-replicate)。
OSD cluster map 会因为 OSD 故障、OSD 恢复和显式地集群变更(例如部署新节点)而变 化。Ceph 以同样的方式处理这些 map 变更。
为使恢复更快,OSD 为每个对象维护了一个版本号和每个 PG 最近改动的日志( 更新或删除的对象的名字和版本,和 Harp [14] 的 replication log 类似)。
当一个 active OSD 收到一个更新过的 cluster map,它会遍历本地所有的 PG,计算 CRUSH mapping,确定每个 OSD 是该作为 primary OSD 还是 replica OSD。
如果一个 PG 的 OSD 成员列表变了,或者如果一个 OSD 刚启动,那这个 OSD 必须和 PG 的其他 OSD 进行同步(peer)。对于 replicated PG,它需要向 primary OSD 提供它自 己当前的 PG 版本号。如果一个 OSD 是 PG 的 primary OSD,它需要收集当前(以及 之前的)replica OSD 的 PG 版本信息。
如果 primary OSD 缺失了 PG 最近的更新,那为了确定正确的(最近的)PG 内容,它 需要从 PG 对应的当前或前一个 OSD 那里获取最近的 PG 改动(或者一个完整的内容 summary,如果需要)的 log。然后,primary OSD 会向每个副本发送一个增量 log 更新( 或者一个完整的内容 summary,如果有需要),然后所有的参与方就都知道了 PG 的内容应 该是什么样的,即使它们本地存储的对象可能还不匹配。
只有当 primary OSD 确定了正确的 PG 状态,并且将它共享给其他副本后,开始接受 到这个 PG 内的对象的 I/O 操作。然后,OSD 就可以独立从它们的 peer 那里获取它们丢失 的或是过期的对象。
如果一个 OSD 收到的是对一个过期或丢失的对象的请求,那它会延迟处理这个请求,并且 将这个对象放到恢复队列的前端(优先处理)。例如,
osd1 挂了,被标记为 down,然后 osd2 接管,作为 pgA 的 primary OSDosd1 恢复后,它启动时会请求最新的 map,monitor 会将这个 OSD 置为 uposd2 收到(osd1 up 事件导致的)map 更新,意识到自己不再是 gpA 的 primary OSD,就会将 pgA 的版本号发给 osd1osd1 会从 osd2 获取 pgA 的 log,告诉 osd2 它维护的内容是最近的,更新 过的对象在后台恢复之后,osd1 就开始处理新请求因为故障恢复完全是由每个 OSD 驱动的,因此一个 OSD 故障受影响的那些 PG (很可 能)会在不同 OSD 上并行恢复。这种方式基于 Fast Recovery Mechanism (FaRM) [37],可 以减少恢复时间,提高总体的数据安全性(safety)。
很多分布式存储系统使用 ext3 这样的本地文件系统来管理底层存储 [4, 12],但我们发 现对于对象负载(object workload),这些本地文件系统的接口和性能都很差 [27]。
当前的内核接口限制了我们判断对象的更新是否已经安全地(safely)提交到了磁盘的能力。
同步写(synchronous writes)或日志技术(journaling)提供了期望的安全性(safety) ,但会带来很大的延迟和性能损失。更重要的是,POSIX 接口无法支持原子的数据和元数 据(例如,attribute)更新事务,而这对于维持 RADOS 的一致性非常重要。
因此,每个 OSD 用 EBOFS(an Extent and B-tree based Object File System)管理它的 本地对象存储。
EBOFS 完全在用户态实现,直接和裸块设备交互,这使得我们可以自己定义低层的对 象存储接口和更新语义,从而将更新的顺序化(update serialization)(为了同步)和 磁盘提交(为了安全性)分离开来。 EBOFS 支持原子事务(例如,对多个对象进行写和属性更新),更新函数在内存中的缓存更 新之后就返回,提供异步的磁盘提交通知。用户态的实现除了提供更好的灵活性和更简单的 实现之外,也避免了和 Linux VFS 和 页缓存(page cache)的笨重的交互,这两者都是为 不同的接口和负载设计的。
大部分内核文件系统都是惰性地(lazily)将更新 flush 到磁盘,但EBOFS 是主动地调 度磁盘写操作,并且如果后面的更新会覆盖前面的更新,那前面的 pending 更新可能会在 flush 之前就被取消了。这使得我们的低层磁盘调度器有一个更长的 I/O 队列,可以提高 调度的效率。用户态的调度器还使得按优先级排序更容易(例如,client I/O 和恢复相比 ),或者提供 QoS 保证 [36]。
EBOFS 的核心设计是一个健壮的、灵活的、功能完整的 B-Tree 服务,用于定位对象在磁 盘中的位置、管理块分配、对 PG 进行索引。
块分配是以范围(extent)——(开始位置,长度)—— 为粒度进行的,而不是以块列表( block list)的方式,这样可以使元数据更紧凑。 磁盘上空闲的块范围(block extent)按位置排序,按大小管理在一起,使得 EBOFS 可以 在限制长期的碎片的同时,快速的定位写位置附近的空闲空间,或者磁盘中的数据。 除了每个对象的(per object)块分配信息这个例外,出于性能和简单考虑,其他的元数据 都保持在内存中(元数据很小,即使对于非常大的 volume)。
最后,EBOFS 主动执行写时复制(Copy on Write,COW):除了超级块的更新之外,其 他数据都是写到磁盘上还未分配的区域。
我们选取了一系列微指标(microbenchmarks)对原型的性能、可靠性和可扩展性进行了测 试。
测试集群信息:
EBOFS 提供了优异的性能和安全语义(safety semantics),且聚合 I/O 性能可以随 OSD 集群的规模而扩展,这得益于 CRUSH 产生的平衡的数据分布,以及复制和故障恢复功能的 下放(到 OSD)。
先来看一个由 14 个节点组成的 OSD 集群的 I/O 性能。图 5 显示了每个 OSD 的吞吐量随 写数据大小(write size)和副本数量(replication)的变化。负载是在另外的 20 台节 点上由 400 个客户端生成的。
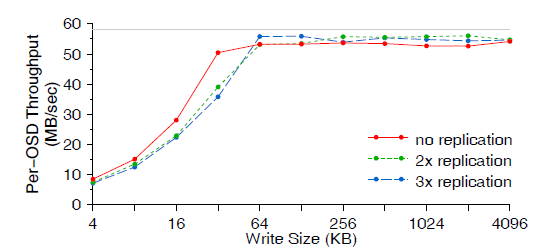
图 5 单个 OSD 的吞吐量
可以看出,最终的性能受限于裸盘带宽(raw disk bandwidth),大约为 58MB/sec。 OSD 数量相同的情况下,副本复制会使磁盘 I/O 增大到两倍或三倍,相应地客户端的数据 写入速率会降低。
图 6 是 EBOFS 和通用文件系统(ext3, ReiserFS, XFS)的对比。测试中客户端同 步地写入大文件(这些文件会被 Ceph 分割(strip)成 16MB 的对象),然后客户端再将 文件读出来。
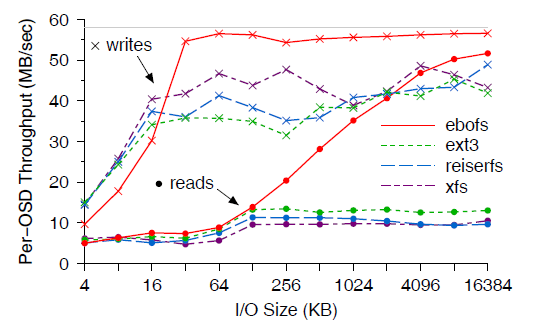
图 6 EBOFS 和通用文件系统性能对比。EBOFS 在 write size 变大时 ,数据在磁盘上的布局尺度(连续空间)也会变大,因此具有更好的读性能。
读写小文件时,EBOFS 受限于粗糙的多线程(coarse threading)和锁机制,性能比其他几 种文件系统要差。但是,当文件大于 32KB 时,EBOFS 几乎打满了可用的磁盘带宽;尤其在 读的时候,EBOFS 的性能远好于其他几种文件系统,因为数据在磁盘上的布局(连续空间) 和写入大小(write sizes)是匹配的 —— 即使在文件非常大的时候。
以上性能是在一个新文件系统(fresh file system)上进行测试的。早期的设计显示 EBOFS 产生的碎片比 ext3 要小得多,但我们还没有测试过在老文件系统(aged file system)表现如何。不过我们预计即使在老文件系统上 EBOFS 的性能不会比其他几种文件 系统差。
图 7 显示了不同写大小和副本数量的情况下,单个客户端的写延迟。
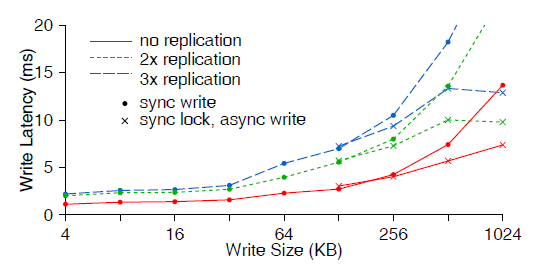
图 7 客户端写延迟
因为 primary OSD 会将更新同时转发(retransmit)给其他副本,因此小文件写只会引入 很小的延迟上升,即使副本数量多于 2 个。对于大文件写入,转发(retransmission )的 代价就很大了;1MB 写(图中没画出)时,一个副本会增加 13ms;三个副本会增加 33ms(2.5 倍)。有几种办法可以解决这个问题:
一种方式是,Ceph 客户端对 128KB 以上的写,先获取独占锁执行同步写,再异步地 将数据 flush 到磁盘,从而部分地降低副本带来的延迟。
另外还有一种方式:写共享的应用(write-sharing applications)可以使用 O_LAZY 放 宽一致性的限制,因此客户端可以缓存小文件的写,累积到一定大小后再异步地写到 OSD; 客户端看到的延迟只有数据 flush 到磁盘之前在缓冲区等待的时间。
Ceph 的数据性能随 OSD 数量几乎线性扩展。CRUSH 产生伪随机分布的数据,因此 OSD 利用率可以用二项分布或正态分布(binomial or normal distribution)精确地建模 —— 这正是人们期望从完美的随机过程中获得的特性 [29]。
OSD 利用率的方差随 PG 数量的增多而降低:每个 OSD 100 个 PG 时,标准差是 10%; 1000 个 PG 时标准差是 3%。
图 8 展示了分别使用 CRUSH、简单哈希和线性分散(striping)策略来分布数据时,单个 OSD 写吞吐性能随 OSD 数量的变化。图中包括两组 PG 数量测试:4096 个和 32768 个 。
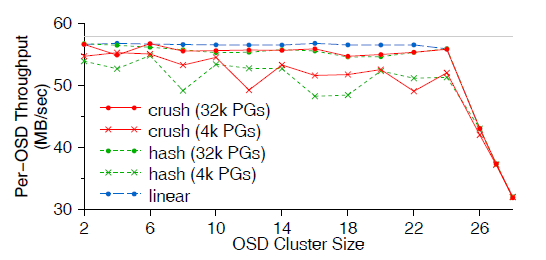
图 8 不同数据分布算法下的 OSD 写吞吐
线性分散(striping)可以完美地平衡负载,实现最大的吞吐,因此作为性能对照组; 但和简单哈希一样,它无法应对设备故障和 OSD 集群变化的情况。
CRUSH 或哈希产生的数据放置(data placement)是随机的,因此 PG 数量少的时候吞吐 会比较低,OSD 利用率的方差比较大,进而导致测试中每个客户端的负载(请求队列长度 )会有差别。小概率情况下,设备可能会被打爆(overfilled or overutilized),导 致性能下降,CRUSH 可以通过将部分负载 offload 到指定的 OSD 来解决这一问题。但与简 单哈希和线性策略不同,CRUSH 在集群扩展时能够最小化数据迁移,同时保持平衡的数据分 布。
CRUSH 的计算复杂度是 O(log n)(对于 n 个 OSD 组成的集群),耗时仅为几十毫 秒级别,允许集群扩展到成千上万的 OSD。
Ceph MDS 集群提供了良好的扩展性和增强的 POSIX 语义。
我们通过特殊的负载测试了元数据的性能,这些负载不会产生真实的数据 I/O。这些实验中 ,OSD 仅用于元数据的存储。
首先来看元数据更新(mknod、mkdir 等)的延迟。
测试中单个客户端生成大量文件和目录,为保证 safety,MDS 必须同步地将这些文件和目 录 journal 到 OSD 集群。我们考虑两种情况:
图 9 显示了元数据更新的延迟,左侧是随元数据副本的数量变化(0 表示没有 journaling )。
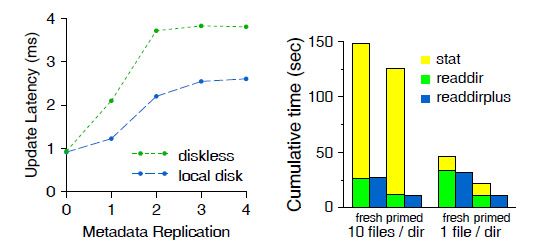
图 9 元数据更新(写)延迟
journal 首先会写到 primary OSD,然后复制到其他的副本 OSD。
在有本地磁盘的情况下,从 MDS 到 local primary OSD (第一跳)只需要很少时间,后面 的过程和无磁盘是类似的。两种情况下,两个以上副本都只增加了很少的的额外延迟,因为 副本更新都是并行进行的。
元数据的读行为(readdir、stat、open 等)要更复杂一些。
图 9 右边展示的是一个客户端用 readdir 访问 10K 个嵌套的目录,并对每个文件执行 stat 操作的累计时间。
MDS 缓存可以减少 readdir 次数,因为 inode 内容嵌入在目录里面,单次的 OSD 操作 就可以将完整的目录内容加载到 MDS cache。
但随后的 stat 没有受影响。正常情况下,stat 的累计时间占据了大目录的大部分时间。
随后的 MDS 交互过程可以通过 readdirplus 减少交互次数,它显式地将 stat 和 readir 放到了同一个操作中,或者通过放宽 POSIX 限制,允许紧跟着 readdir 的 stat 从客户端缓存(默认)中提供服务。
我们在 Lawrence Livermore National Laboratory (LLNL) 的 alc Linux 集群中 430 个 节点上进行了元数据可扩展性测试。图 10 显示了单个 OSD 吞吐随 MDS 集群大小的变化。
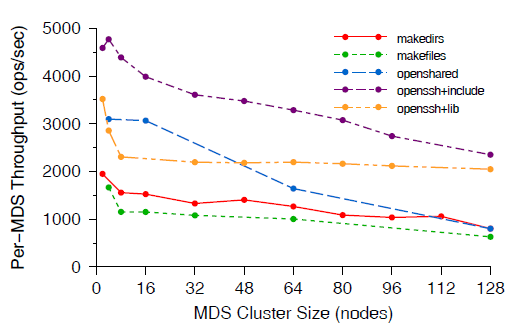
图 10 单个 OSD 吞吐随 MDS 节点数量的变化
mkdirs 测试组中,每个客户端创建一个 4 层深的目录。每个子目录有 10 个文件和一 个子目录。小集群的平均吞吐为每 MDS 2000 ops/sec,到 128 MDS 的大集群时,吞 吐降到每 MDS 1000 ops/sec(50%效率)(总吞吐 10K ops/sec)makefiles 测试组中,每个客户端都在同一目录内创建几千个文件。当检测到很高的 写入频率之后,Ceph 会对共享目录进行哈希,放宽目录的 mtime 一致性,将负载分布 到所有 MDS 节点上openshared 组展示读共享,每个客户端不停地打开和关闭十个共享文件openssh 组,每个客户端重放(replay)一段录制好的编译过程的 trace。其中一组使 用了 /lib 这个中等共享程度的目录,而另一组使用了/usr/include 这个重度读的 共享目录openshared 和 openssh+include 组有最重度的读共享,因此可扩展性在所有组中是 最差的,我们认为这是由于客户端选择副本的机制比较差造成的openssh+lib 扩展性比 mkdirs 略好,因为它涉及的元数据改动更少,共享也更少虽然我们认为网络资源和我们的消息层线程竞争进一步降低了大 MDS 集群的性能,但由于 这套计算集群留给我们的测试时间有限,所以未能就这些问题展开深入研究。
图 11 是 mkdirs 组中,MDS 集群有 4、16、64 个节点的情况下,单个 MDS 吞吐和延迟 的关系。
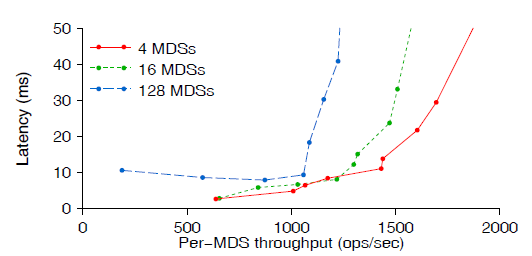
图 11 mkdirs 组中延迟和 per-MDS 吞吐的关系
大的集群负载分布不平衡,导致更低的 per-MDS 吞吐(但更高的总吞吐)和更高一些的试 验。虽然没有达到完美的线性扩展,但在 128 个节点的 MDS 集群中取得了 250K ops/sec 的元数据操作性能(128 x 2K ops/sec)。因为元数据事务和数据 I/O 是独立 的,而且元数据大小也独立于文件大小,因此,这个元数据性能可以对应到几百 PB 级的存 储,具体取决于平均文件大小。
例如,LLNL 的 Bluegene/L 科学计算应用创建 checkpoint,涉及 64K 节点,每 个节点两个处理器,每个处理器写到同一目录的不同文件(和 makefiles 测试类似)。 虽然当前的存储系统峰值元数据操作只有 6K ops/sec,需要 2 分钟完成每个 checkpoint ,但如果是 128 个 MDS 节点的话,只需 2 秒就可以完成。
如果每个文件为 10MB 大小(以 HPC 的标准来说非常小),OSD 保持 50 MB/s 的带宽, 一个集群就可以达到 1.25TB/s 的写入,足以使 25K 个 OSD 达到饱和(如果带复制的话 ,50K)。250GB 的 OSD 就可以使这个系统达到 6PB 的存储。
更重要的是,Ceph 的动态元数据分布使得每个 MDS 集群(不管多大)都可以根据当前的负 载重新分配资源 —— 即使之前所有的客户端已经被定向到了同一个 MDS —— 使得它比任何静 态分割策略更加的灵活和自适应。
我们惊奇地发现,用分布函数(distribution function)替换文件系统的元数据分配表 (allocation metadata)竟给设计带来如此大的简化。
虽然这给分布函数本身带来了更多的要求,但一旦我们了解了这些真实的需求,CRUSH 就可 以提供所需的扩展性、灵活性和可靠性。这极大简化了元数据设计,同时还赋予了客户端和 OSD 完整并且独立的数据分布式知识(complete and independent knowledge of the data distribution)。而 OSD 拥有了这些知识之后,我们就可以将数据复制、数据迁移、故障 检测、故障恢复的职责下放给它们,通过这种分散机制充分利用它们的 CPU 和内存。
RADOS 给未来的(与我们的 OSD 模型匹配的)改进留下了很多余地,例如比特错误检测( Google File System [7])和基于负载的数据动态复制(AutoRAID [34])。
虽然已有的内核文件系统作为本地对象存储很方便(很多其他系统就是这么做的[4,7,9]) ,但我们很早就意识到,专门针对对象存储定制(裁剪)的文件系统会取得更好的性能[27] 。
但我们没有预料到的是现有文件系统接口和我们的需求之间的不一致性,这一点在开发 RADOS 复制和可靠性机制的时候才变得明显起来。
EBOFS 在用户态开发非常地快,性能非常满意,提供的接口也能够完美地满足我们的需求。
我们学到的重要一课是:MDS 负载均衡器对整体扩展性的重要性,以及选择哪些元数 据进行迁移、迁移到哪里、什么时候迁移等等问题的复杂度。
虽然实际上看起来我们的设计和目标都比较简单,但在上百个 MDS 上对动态负载进行分布 实施起来还是有很多细微之处的。最明显地,MDS 的性能受很多因素的限制,包括 CPU、内 存(和缓存效率)、网络或 I/O,任何一个因素都有可能在某时刻成为瓶颈。
另外,总体吞吐和公平之间的平衡(balance between total throughput and fairness) 是很难量化的,特定情况下的元数据不平衡分布反而会提升系统的整体吞吐 [30]。
客户端接口的实现比预计的要困难。虽然 FUSE 的使用极大地简化了实现,因为绕开了内核 ,但它也引入了自己的一些麻烦之处。
DIRECT_IO 绕过了内核页缓存,但并不支持 mmap,我们不得不修改 FUSE 来让它将干 净的页面标记为过期(invalidate clean pages)作为临时解决方式。
FUSE 坚持使用自己的安全检测(security checks),这导致了具有复制行为的 getattrs(stats),即使对于简单的应用调用(simple application calls)也是如 此。
最后,内核和用户空间的基于页的 I/O(page-based I/O)限制了整体的 I/O 速度。 虽然直接链接到客户端避免了 FUSE 的问题,但用户空间的大量系统调用又会导致一些新问 题的出现(大部分我们还没仔细研究),这样来看,一个内核客户端模块是无法避免的了。
High-performance scalable file systems have long been a goal of the HPC community, which tends to place a heavy load on the file system [18, 27]. Although many file systems attempt to meet this need, they do not provide the same level of scalability that Ceph does. Largescale systems like OceanStore [11] and Farsite [1] are designed to provide petabytes of highly reliable storage, and can provide simultaneous access to thousands of separate files to thousands of clients, but cannot provide high-performance access to a small set of files by tens of thousands of cooperating clients due to bottlenecks in subsystems such as name lookup. Conversely, parallel file and storage systems such as Vesta [6], Galley [17], PVFS [12], and Swift [5] have extensive support for striping data across multiple disks to achieve very high transfer rates, but lack strong support for scalable metadata access or robust data distribution for high reliability. For example, Vesta permits applications to lay their data out on disk, and allows independent access to file data on each disk without reference to shared metadata. However, like many other parallel file systems, Vesta does not provide scalable support for metadata lookup. As a result, these file systems typically provide poor performance on workloads that access many small files or requiremany metadata operations. They also typically suffer from block allocation issues: blocks are either allocated centrally or via a lock-based mechanism, preventing them from scaling well for write requests from thousands of clients to thousands of disks. GPFS [24] and StorageTank [16] partially decouple metadata and data management, but are limited by their use of block-based disks and their metadata distribution architecture.
Grid-based file systems such as LegionFS [33] are designed to coordinate wide-area access and are not optimized for high performance in the local file system. Similarly, the Google File System [7] is optimized for very large files and a workload consisting largely of reads and file appends. Like Sorrento [26], it targets a narrow class of applications with non-POSIX semantics.
Recently, many file systems and platforms, including Federated Array of Bricks (FAB) [23] and pNFS [9] have been designed around network attached storage [8]. Lustre [4], the Panasas file system [32], zFS [21], Sorrento, and Kybos [35] are based on the object-based storage paradigm [3] and most closely resemble Ceph. However, none of these systems has the combination of scalable and adaptable metadata management, reliability and fault tolerance that Ceph provides. Lustre and Panasas in particular fail to delegate responsibility to OSDs, and have limited support for efficient distributed metadata management, limiting their scalability and performance. Further, with the exception of Sorrento’s use of consistent hashing [10], all of these systems use explicit allocation maps to specify where objects are stored, and have limited support for rebalancing when new storage is deployed. This can lead to load asymmetries and poor resource utilization, while Sorrento’s hashed distribution lacks CRUSH’s support for efficient data migration, device weighting, and failure domains.
Ceph 的一些核心组件还没实现,包括 MDS 故障恢复和几个 POSIX 调用。目前在考虑两个 安全架构和协议变种(security architecture and protocol variants),但也还没实现 [13, 19]。我们也计划研究 client callbacks on namespace to inode translation metadata 的可行性。对于文件系统的静态部分,这可以在无需 MDS 交互的情况下允许 open(for read)。另外还计划了 MDS 的其他一些优化项,包括对目录层级的任意一个 子树进行快照的能力 [28]。
虽然同一目录或文件进行大量访问时,Ceph 会对元数据进行复制,但目前还不会对数据进 行类似的复制。我们计划让 OSD 根据每个对象的负载大小动态地调整副本数量,将读请求 分散到 PG 的多个 OSD 之间。这会优化数据集中访问时的扩展性,也有助于通过 D-SPTF [15] 类似的机制实现更细粒度的 OSD 负载均衡。
最后,我们正在开发一些服务,可以按类型聚合流量,也可以支持 OSD-managed 基于预留 方式的带宽和延迟保证。除了向应用提供 QoS 保证,这还有助于平衡常规负载的 RADOS 复 制和恢复操作。
计划对 EBOFS 进行一些改进,包括优化的分配逻辑、数据擦洗(data scouring)、校验和 和其他比特位错误检测机制,提高数据的安全性(safety)。
Ceph 以一种独特的方式来应对存储系统面临的三大难题 —— 扩展性、性能和可靠性。我们 没有使用几乎所有存储系统都在用的分配表(allocation lists)方式,(而是通过其他方 式)最大化数据和元数据管理的分离,使二者可以独立扩展。这种方式就是 CRUSH,一个产 生伪随机分布的数据分布函数,允许客户端计算而不是查找(calculate object locations instead of looking them up)对象的位置。
CRUSH 将数据进行跨故障域(failure domains)复制,以提高数据的安全性(safety); 同时,Ceph 能高效地应对大规模存储集群固有的动态性,例如设备故障、集群扩展和集群 物理重构(cluster restructuring)都是司空见惯的事情。
RADOS 利用智能的 OSD 管理数据复制、故障检测和恢复、底层磁盘分配、调度和数据迁移 ,而无需任何中心式服务(central servers)的接入。
虽然对象可以当做文件存储在通用文件系统上,但 EBOFS 针对 Ceph 的负载类型和接 口需求提供了更合适的语义和更好的性能。
最后,Ceph 的元数据管理架构解决了高度可扩展存储系统中的一些最为困难的(the most vexing problems)问题:如何提供一个兼容 POSIX 语义的、单一的均匀目录层级( single uniform directory hierarchy obeying POSIX semantics),其性能能够随着 metadata server 的数量扩展。
Ceph 的动态子树分割是一种独特的、可扩展的方式,既提供了很高的效率,又具备自适应 负载变化的能力。
Ceph 使用 LGPL 协议,代码见 http://ceph.sourceforge.net/。
This work was performed under the auspices of the U.S. Department of Energy by the University of California, Lawrence Livermore National Laboratory under Contract W-7405-Eng-48. Research was funded in part by the Lawrence Livermore, Los Alamos, and Sandia National Laboratories. We would like to thank Bill Loewe, Tyce McLarty, Terry Heidelberg, and everyone else at LLNL who talked to us about their storage trials and tribulations, and who helped facilitate our two days of dedicated access time on alc. We would also like to thank IBM for donating the 32-node cluster that aided in much of the OSD performance testing, and the National Science Foundation, which paid for the switch upgrade. Chandu Thekkath (our shepherd), the anonymous reviewers, and Theodore Wong all provided valuable feedback, and we would also like to thank the students, faculty, and sponsors of the Storage Systems Research Center for their input and support.