网络基本功(十五):细说网络性能监测与实例(上)复制
网络路径性能检测主要包括三方面的内容:带宽测量能够获知网络的硬件特性,如网络的最大容量,吞吐量测量能够获得网络实际可提供的最大容量,数据流测量能够了解真实占用的网络容量。
本文介绍在评估网络性能是否合理时,需要收集的数据及收集方式。涉及工具包括:ping, pathchar, bing, ttcp, netperf, iperf, netstat。
带宽测量:
ping
ping这一工具返回的时间,虽然通常被描述为传输延时,实际上是发送,传输,队列延时之和。上一节中,我们通过ping来粗略计算带宽。这一过程可通过如下方式改进:首先计算链路近端的路径行为,然后计算远端路径,然后用两者差异来估算链路带宽。
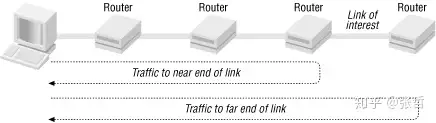
这一过程需要四次使用ping。首先,用两个不同大小报文ping近端链路。减掉传输大报文中额外数据的传输时间以外,时间差可估算传输以及队列延时。接下来,用同样两个报文ping远端链路。再次用大报文和小报文的时间差来估算开销。最后,用两次差值的差值就是在最后一段链路中传输额外数据的时间值。这是一个往返时间,除以2就是额外数据在单向链路传输所用时间。带宽则是额外数据总量除以单向传输时间。
下表是第二跳和第三跳的时间值,报文大小为100和1100字节。
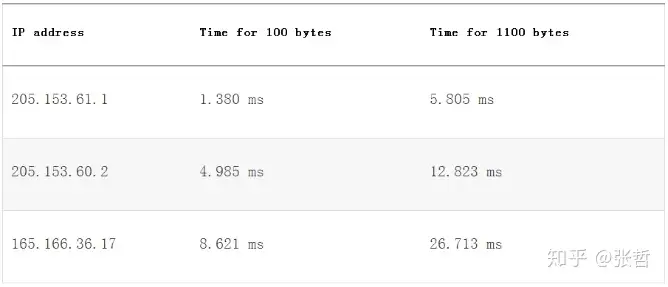
下表显示了带宽计算结果,用time difference除以2,用8000bit除以这个值,再乘1000(毫秒转换为秒)。结果是bps转换为Mbps。
pathchar
将上述过程自动话完成的一个工具是pathchar。pathchar在路径的一端即能检测各链路的带宽。方法与之前描述的ping相类似,但是pathchar使用各种大小不一的报文。如下例所示:
bsd1# pathchar 165.166.0.2
pathchar to 165.166.0.2 (165.166.0.2)
mtu limited to 1500 bytes at local host
doing 32 probes at each of 45 sizes (64 to 1500 by 32)
0 205.153.60.247 (205.153.60.247)
| 4.3 Mb/s, 1.55 ms (5.88 ms)
1 cisco (205.153.60.2)
| 1.5 Mb/s, -144 us (13.5 ms)
2 165.166.36.17 (165.166.36.17)
| 10 Mb/s, 242 us (15.2 ms)
3 e0.r01.ia-gnwd.Infoave.Net (165.166.36.33)
| 1.2 Mb/s, 3.86 ms (32.7 ms)
4 165.166.125.165 (165.166.125.165)
| ?? b/s, 2.56 ms (37.7 ms)
5 165.166.125.106 (165.166.125.106)
| 45 Mb/s, 1.85 ms (41.6 ms), +q 3.20 ms (18.1 KB) *4
6 atm1-0-5.r01.ncchrl.infoave.net (165.166.126.1)
| 17 Mb/s, 0.94 ms (44.3 ms), +q 5.83 ms (12.1 KB) *2
7 h10-1-0.r01.ia-chrl.infoave.net (165.166.125.33)
| ?? b/s, 89 us (44.3 ms), 1% dropped
8 dns1.InfoAve.Net (165.166.0.2)
8 hops, rtt 21.9 ms (44.3 ms), bottleneck 1.2 Mb/s, pipe 10372 bytes
复制pathchar的运行过程中,首先显示的信息描述探测如何进行。从第三行输出开始,可看到pathchar使用从64到1500字节的45中不同大小报文。对于每一跳使用32种不同报文组合进行测试。因此,共8跳生成了11,520个测试报文加上相应回复信息。
显示中给出了带宽和延时。pathchar也包括了队列延时信息(如本例中5和6)。如上述信息,pathchar并不总是能成功估算出带宽(如链路4和7)或是延时(如链路1)。
在pathchar运行过程中,每发送一个报文就启动一次倒计时:显示内容如下所示:
1: 31 288 0 3
复制1指示跳数并且随着路径上后续跳数而增加。下一个数字是倒计时值,给出这一链路剩余的探测组数。第三个值是当前发送报文大小。第二个和第三个值改变都非常迅速。倒数第二个值是目前为止丢弃报文数,最后一个是该链路的平均往返时间。
当一条的探测完成时,这一行内容被带宽,传输延时,往返时间所取代。pathchar使用观测到的最小延时来改进带宽估算值。
bing
pathchar的一个替代工具是bing。pathchar估算的是一条路径上各链路的带宽,而bing用来测量点到点的带宽。通常,如果你不知道路径上的各条链路,需要首先执行traceroute命令。之后可以运行bing来指定链路的近端和远端。下例显示了第三跳的带宽:
bsd1# bing -e10 -c1 205.153.60.2 165.166.36.17
BING 205.153.60.2 (205.153.60.2) and 165.166.36.17 (165.166.36.17)
44 and 108 data bytes
1024 bits in 0.835ms: 1226347bps, 0.000815ms per bit
1024 bits in 0.671ms: 1526080bps, 0.000655ms per bit
1024 bits in 0.664ms: 1542169bps, 0.000648ms per bit
1024 bits in 0.658ms: 1556231bps, 0.000643ms per bit
1024 bits in 0.627ms: 1633174bps, 0.000612ms per bit
1024 bits in 0.682ms: 1501466bps, 0.000666ms per bit
1024 bits in 0.685ms: 1494891bps, 0.000669ms per bit
1024 bits in 0.605ms: 1692562bps, 0.000591ms per bit
1024 bits in 0.618ms: 1656958bps, 0.000604ms per bit
--- 205.153.60.2 statistics ---
bytes out in dup loss rtt (ms): min avg max
44 10 10 0% 3.385 3.421 3.551
108 10 10 0% 3.638 3.684 3.762
--- 165.166.36.17 statistics ---
bytes out in dup loss rtt (ms): min avg max
44 10 10 0% 3.926 3.986 4.050
108 10 10 0% 4.797 4.918 4.986
--- estimated link characteristics ---
estimated throughput 1656958bps
minimum delay per packet 0.116ms (192 bits)
average statistics (experimental) :
packet loss: small 0%, big 0%, total 0%
average throughput 1528358bps
average delay per packet 0.140ms (232 bits)
weighted average throughput 1528358bps
resetting after 10 samples.
复制输出从地址和报文大小信息开始,之后是探测pair。接下来,返回往返时间和丢失数据。最后,返回一些吞吐量的估测值。
吞吐量测量:
吞吐量不够的原因不仅在于硬件不足,还有可能是网络设计架构的问题。例如,广播域设置得太大,则即使硬件够磅也会造成问题。解决方案是重构网络,在充分理解数据流模式后,将这类域隔离开或是分段。
吞吐量通常是测量大块数据传输延时来完成的。通常需要在链路各端运行软件。一般这类软件运行在应用层,所以它不仅测量网络也测量了软硬件。
一个比较简单粗放的方式是用FTP。用FTP来传输一份文件并且看一下它report的数据。需要将结果转换成比特率,例如,这是文件传输的最后一行:
1294522 bytes received in 1.44 secs (8.8e+02 Kbytes/sec)
复制将1,294,522字节乘8转换成bit之后再除以时间,1.44秒。 结果为7,191,789 bps。
这种方法的不足在于磁盘访问时间可能对结果造成影响。如果需要提高精度则需要使用一些工具。
ttcp
运行这一程序首先需要在远端设备运行server,通常用-r和-s选项。之后运行client,用-t和-s选项,以及主机名或地址。数据从client端发送至server端,测量性能之后,在各端返回结果,之后终止client端和server端。例如,server端如下所示:
bsd2# ttcp -r -s
ttcp-r: buflen=8192, nbuf=2048, align=16384/0, port=5001 tcp
ttcp-r: socket
ttcp-r: accept from 205.153.60.247
ttcp-r: 16777216 bytes in 18.35 real seconds = 892.71 KB/sec +++
ttcp-r: 11483 I/O calls, msec/call = 1.64, calls/sec = 625.67
ttcp-r: 0.0user 0.9sys 0:18real 5% 15i+291d 176maxrss 0+2pf 11478+28csw
client端如下所示:
bsd1# ttcp -t -s 205.153.63.239
ttcp-t: buflen=8192, nbuf=2048, align=16384/0, port=5001 tcp -> 205.153.63.239
ttcp-t: socket
ttcp-t: connect
ttcp-t: 16777216 bytes in 18.34 real seconds = 893.26 KB/sec +++
ttcp-t: 2048 I/O calls, msec/call = 9.17, calls/sec = 111.66
ttcp-t: 0.0user 0.5sys 0:18real 2% 16i+305d 176maxrss 0+2pf 3397+7csw
复制该程序报告中显示了信息传输总量,标识了连接的建立,并且给出了结果,包括raw data,throughput,I/O call信息,执行时间。最有用的信息应该是transfer rate,892.71 KB/sec (or 893.26 KB/sec)。
这一数据反映了数据的传输速率,而不是链路的容量。将这一数据转化成带宽可能是有问题的,因为实际上传输了比这一值更多的比特数。这一程序显示18.35秒传送了16,777,216字节,但是这仅仅是数据。以太网报文封装还包括TCP,IP,以太网报文头,估算容量时,需要把这些值加上去。
吞吐量低通常意味着拥塞,但也并不总是如此。吞吐量也会取决于配置问题,如连接的TCP窗口大小。如果窗口大小不足,会严重影响到性能。
(未完待续)
Network Troubleshooting Tools
PS:在gitbook上看到一本好书,但是无奈gitbook不挂梯子访问太慢了。为了方便自己查阅,也方便知识共享,将文章转载到知乎专栏,由于没有联系到作者(据说是个女神)冒昧挂上来,如果有冒犯的地方,联系我我随时进行删除。谢谢。
作者:Zhang Jiawen