https://blog.mygraphql.com/zh/notes/low-tec/network/bpf-trace-net-stack/复制
现代人好像都很忙,忙着跟遥远的人社交,却很容易忽视眼前的人事,更别提那些不直接体现出价值的基础认知了。要花时间认真看一编文章前,都要问一个问题:WHY。这才会有 TLDR; 的出现。终身学习是个口号,但也仅仅是个口号。看看身边的那些放満书的人,有几个真去阅读?社会人大都有现实地认为,持续学习只应该发生在考试前。在社会卷时,就好好做个社会人。
故事是这样的:
话说,在风口上的微服务(Micro-Service)很美好,云原生(Cloud Native) 很美好,服务网格(Istio) 很美好,旧爱非阻塞事件响应编程(epoll)很美好。但出现性能优化需求的时候,性能工程师会把上面的“美好”会替换为“复杂”。是的,没太多人在架构设计或重构前会花太多时间在性能上和那些开箱即用的基础架构上。直到一天遇到问题要救火……
终于,为救火,我们还要看基础架构是如何工作的。但从何入手?直接看源码? git clone,开始读源码? 很大可能,最后会迷失在源码的海洋中。
YYDS,Linus Torvalds 说过:
https://lwn.net/Articles/193245/
In fact, I’m a huge proponent(支持者) of designing your code around the data, rather than the other way around, and I think it’s one of the reasons git has been fairly successful (*)…
(*) I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important. Bad programmers worry about the code. Good programmers worry about data structures and their relationships.
—— Linus Torvalds
可见,了解软件的数据结构是了解软件运行机理的关键。但个人认为,这对于单体架构软件是正确的。但对于现代具有复杂组件架构的系统来说,只了解数据结构不足够,还要了解数据结构是如何在子系统间流转。
下面,我们关注一下,Istio/Envoy 下,从内核到用户进程,有什么重要数据结构,数据和事件是如何在子系统间协作,最后完成任务的。了解了这些,在系统需要调优之时,就有了观察点和优化可能点了。而不是完全看作黑盒,从网上找各种“神奇”配置来盲目碰运气。
大家知道,网络数据来源于网线、光纤、无线电波上的比特(bit),然后到网卡,到内核,最后到应用进程 socket。事情好像很简单。但如果是 SRE/DevOps 或是 Performance Engineer ,需要做细致的监控和优化时,这些显然是不够的。引用本文主要参考作者的原话:
Optimizing and monitoring the network stack is impossible unless you carefully read and understand how it works. You cannot monitor code you don’t understand at a deep level.
除非您仔细阅读并了解其工作原理,否则无法优化和监控网络堆栈。 您无法深入监控您不理解的代码。
—— Joe Damato
《网络包的内核漂流记》尝试分析和跟踪一个网络包在内核各子系统间的流转和触发的协作。
开始前先做个预告,《网络包的内核漂流记》 系统(将)包括:
为免吓跑人,还是老套路,多图少代码。不过有的图有点点复杂。🚜
本文图很多,也很有很多细节直接嵌入到图中。其中有到源码的链接、图例等。可以这样说,我写作的大部时间不是花在文字上,是在图上,所以用电脑去读图,才是本文的正确打开方法。手机与微信号,只是个引流的阳谋。
虽然不是写书,不过还是说明一下吧,不然阅读体验不太好。:

开始前简单过一下术语,以减少后面的误解:
upstream: 流量方向中的角色:[downstream] –> envoy –> [upstream]。这里我避免用中文词 上/下游,因为概念上没有统一,也容易和英文误解。downstream: 流量方向中的角色:[downstream] –> envoy –> [upstream]需要注意的是,upstream 与 downstream 是个相对于观察者的概念。
如场景:
service A–调用–>service B–调用–>service C:
如果站在
service C上,我们在把service B叫 downstream;如果站在
service A上,我们把service B叫 upstream。
以上只是部分术语,其它术语我将在首次使用时作介绍。
被跟踪的架构很简单:
|
|
即有两个 pod,分别叫 downstream_pod、trace_target_pod。他们均有 app 和 sidecar。跟踪开始后,触发 downstream_app 向 target_pod 发送 http 请求。
被跟踪的环境地址信息:
downstream_pod IP: 172.30.207.163
target_pod IP: 172.21.206.207
target_sidecar(Envoy) Inbound listen port: 127.0.0.1:15006
target_sidecar(Envoy) 进程 PID: 4182
target_sidecar(Envoy) 主线程TID: 4182
target_sidecar(Envoy) 主线程名: envoy
target_sidecar(Envoy) 工作线程0 TID: 4449
target_sidecar(Envoy) 工作线程0 名: wrk:worker_0
target_sidecar(Envoy) 工作线程1 TID: 4450
target_sidecar(Envoy) 工作线程1 名: wrk:worker_1
target_app endpoint: 172.21.206.207:8080 / 127.0.0.1:8080
复制在开始 事件链路初探 前,先了解一下基础知识: 内核调度点与协作。
Linux 内核调度如果要说清楚,是一本书一个章节的。由于本人学识有限,本文的篇幅有限,不想深度展开,但说说基本的还是需要的。

图:线程状态图(来自:https://idea.popcount.org/2012-12-11-linux-process-states/)
🛈 注意,本小节是个题外话,不直接和本文相关,本文不涉及 Runnable 状态下 ON/OFF CPU 的分析,不喜可跳过。
光有线程状态其实对性能分析还是不足的。对于 Runnable 的线程,由于 CPU 资源不足排队、cgroup CPU limit 超限、等情况,可以再分为:
。 Brendan Gregg 的 [BPF Performance Tools] 一书中有这个图:
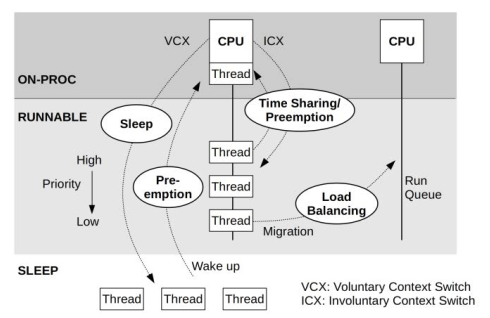
图:ON/OFF CPU 线程状态图(from [BPF Performance Tools] )
介绍几个术语:
先上个图吧:

图:内核调度点与协作
图中信息量不少,不用担心。本文只关注红点部分。
如果你和我一样,在第一次看到上面的 finish_task_switch 和 try_to_wake_up 时一面茫然,那么没关系。在看过 Kaiwan N Billimoria 的 [Linux Kernel Programming] 一书后,终于略懂一二。总结如下。
Process Runing ON CPU (正在CPU上运行的线程) 在处理定时触发的 timer interrupt soft IRQ TIMER_SOFTIRQ 调用 task_tick_fair() 去计算 Process Runing ON CPU 是否应该被重新调度(即考虑抢占。即由于 CPU 资源不足有优先权更高的线程在等待排队、cgroup CPU limit 超限、等情况。如果线程需要被 off-cpu(抢占)那么会标记 TIF_NEED_RESCHED 位。Process Runing ON CPU 在以下调度点可能触发真实的调度(即 off-cpu)
关于 BPF 跟踪和分析问题的启动步骤,个人有一个小经验,也是从 Brendan Gregg 的 [BPF Performance Tools] 一书得来的。
由于这次,我关注的是网络事件如果触发 epoll/Envoy 的事件驱动。其中可以想到,关键中间路径是 Linux 的唤醒机制。如果可以分析到,等待 epoll 事件发生的应用线程(本例中即 Envoy Worker)是如何被唤醒的,那么就可以向上串联应用,向下串联内核网络栈了。
offwaketime 是 BCC BPF 工具包的一个内置小工具。它可以记录线程挂起时的函数调用堆栈,同时也记录相关唤醒线程唤醒挂起线程时的函数调用堆栈。这话写得太学究气了,想接地气,细说,还是移步大师大作:Brendan Gregg 的 Linux Wakeup and Off-Wake Profiling。
运行:
|
|
输出很多,重要摘录如下:
kubelet 会连接 pod 端口做健康检查。所以 kubelet 也是 Envoy 的 Downstream。下面看这个 downstream 如何唤醒 Envoy:
1 waker: kubelet 1172 2 b'[unknown]' 3 b'[unknown]' 4 b'entry_SYSCALL_64_after_hwframe' 5 b'do_syscall_64' 6 b'__x64_sys_connect' <<<<<<<<<<<<<<< kubelet connect Envoy 7 b'__sys_connect' 8 b'inet_stream_connect' 9 b'release_sock' 10 b'__release_sock' 11 b'tcp_v4_do_rcv' <<<<<<<<<<<<<<<< `sk->sk_backlog_rcv` point to 12 b'tcp_rcv_state_process' <<<<<<<<<<<<<<< `sk->sk_state` == TCP_SYN_SENT 13 b'tcp_rcv_synsent_state_process' <<<<<< read `SYN/ACK` from peer(Envoy) at TCP backlog 14 b'tcp_send_ack' <<<<<<<<<<< send `ACK`, to finish 3 handshake 15 b'__tcp_send_ack.part.0' 16 b'__tcp_transmit_skb' 17 b'ip_queue_xmit' 18 b'__ip_queue_xmit' 19 b'ip_local_out' 20 b'ip_output' 21 b'ip_finish_output' 22 b'__ip_finish_output' 23 b'ip_finish_output2' 24 b'__local_bh_enable_ip' <<<<<<<<<< Task from user process done, kernel try run SoftIRQ by the way. 25 b'do_softirq.part.0' 26 b'do_softirq_own_stack' 27 b'__softirqentry_text_start' 28 b'net_rx_action' 29 b'process_backlog' 30 b'__netif_receive_skb' 31 b'__netif_receive_skb_one_core' 32 b'ip_rcv' <<<<<<<<<<<<< Receive IP packet(TCP SYNC) from `kubelet` to `Envoy` 33 b'ip_rcv_finish' 34 b'ip_local_deliver' 35 b'ip_local_deliver_finish' 36 b'ip_protocol_deliver_rcu' 37 b'tcp_v4_rcv' <<<<<<<<<<< `Envoy` side listener socket sk->sk_state == TCP_LISTEN 38 b'tcp_child_process' 39 b'sock_def_readable' <<<<<<<<<<< `Envoy` side listener trigger Readable event 40 b'__wake_up_sync_key' 41 b'__wake_up_common_lock' 42 b'__wake_up_common' 43 b'ep_poll_callback' <<<<<<<<<<< `Envoy` side epoll wakeup logic 44 b'__wake_up' 45 b'__wake_up_common_lock' 46 b'__wake_up_common' 47 b'autoremove_wake_function' <<<<<<<<<<< wakeup Envoy's wrk:worker_0 thread 48 try_to_wake_up <<<<<<<<<<< this line not output by `offwaketime`, It is the kprobe of `offwaketime`. I add it here manually for easy to understanding. 49 -- -- 50 b'finish_task_switch' <<<<<<<<<<< Envoy's wrk:worker_0 thread block waiting, TASK_INTERRUPTIBLE 51 b'schedule' 52 b'schedule_hrtimeout_range_clock' 53 b'schedule_hrtimeout_range' 54 b'ep_poll' 55 b'do_epoll_wait' <<<<<<<<<<< Envoy's wrk:worker_0 thread waiting on epoll event 56 b'__x64_sys_epoll_wait' 57 b'do_syscall_64' 58 b'entry_SYSCALL_64_after_hwframe' 59 b'epoll_wait' 60 b'event_base_loop' 61 b'Envoy::Server::WorkerImpl::threadRoutine(Envoy::Server::GuardDog&, std::__1::function<void ()> const&)' 62 b'Envoy::Thread::ThreadImplPosix::ThreadImplPosix(std::__1::function<void ()>, absl::optional<Envoy::Thread::Options> const&)::{lambda(void*)#1}::__invoke(void*)' 63 b'start_thread' 64 target: wrk:worker_0 4449 65 201092复制
发生时序为:
被唤醒者) 进入挂起状态(TASK_INTERRUPTIBLE)前的函数堆栈。唤醒者(kubelet) 发起唤醒时的函数堆栈。倒序的,为方便和 64 -> 50 行的被唤醒者 函数堆栈串接。可见,这次唤醒 Envoy wrk:worker_0 线程的正好是它的 downstream 线程。这是一个特例,只是由于 downstream 线程和 Envoy 运行于同一主机上。真实情况是,唤醒线程可以是主机上的所有无相干的 on-cpu 的线程。下面道来。
kubelet 发送 TCP 数据到 Envoy, 触发 Envoy 端 socket 的 ReadReady 事件waker: kubelet 169240 b'[unknown]' b'[unknown]' b'entry_SYSCALL_64_after_hwframe' b'do_syscall_64' b'__x64_sys_write' b'ksys_write' b'vfs_write' <<<<<<<< `kubelet` write socket b'__vfs_write' b'new_sync_write' b'sock_write_iter' b'sock_sendmsg' b'inet_sendmsg' b'tcp_sendmsg' b'tcp_sendmsg_locked' b'tcp_push' b'__tcp_push_pending_frames' b'tcp_write_xmit' b'__tcp_transmit_skb' b'ip_queue_xmit' b'__ip_queue_xmit' b'ip_local_out' b'ip_output' b'ip_finish_output' b'__ip_finish_output' b'ip_finish_output2' <<<<<<< ip level sent done b'__local_bh_enable_ip' <<<<<<<<<< Task from user process done, kernel try run SoftIRQ by the way. b'do_softirq.part.0' b'do_softirq_own_stack' b'__softirqentry_text_start' b'net_rx_action' b'process_backlog' b'__netif_receive_skb' b'__netif_receive_skb_one_core' b'ip_rcv' <<<<<<<<<<<<< Receive IP packet(TCP data) from `kubelet` to `Envoy` b'ip_rcv_finish' b'ip_local_deliver' b'ip_local_deliver_finish' b'ip_protocol_deliver_rcu' b'tcp_v4_rcv' <<<<<<<<<<< `Envoy` side downstream socket event(downstream TCP data segment) b'tcp_v4_do_rcv' b'tcp_rcv_established' b'tcp_data_queue' <<<<<<<<<<< `Envoy` side downstream socket TCP segment enqueue to backlog b'tcp_data_ready' b'sock_def_readable' <<<<<<<<<<< `Envoy` side downstream socket raise ReadReady event b'__wake_up_sync_key' b'__wake_up_common_lock' b'__wake_up_common' b'ep_poll_callback' b'__wake_up' b'__wake_up_common_lock' b'__wake_up_common' b'autoremove_wake_function' -- -- b'finish_task_switch' b'schedule' b'schedule_hrtimeout_range_clock' b'schedule_hrtimeout_range' b'ep_poll' b'do_epoll_wait' <<<<<<<<<<<<<< `Envoy` epoll waiting b'__x64_sys_epoll_wait' b'do_syscall_64' b'entry_SYSCALL_64_after_hwframe' b'epoll_wait' b'event_base_loop' b'Envoy::Server::WorkerImpl::threadRoutine(Envoy::Server::GuardDog&, std::__1::function<void ()> const&)' b'Envoy::Thread::ThreadImplPosix::ThreadImplPosix(std::__1::function<void ()>, absl::optional<Envoy::Thread::Options> const&)::{lambda(void*)#1}::__invoke(void*)' b'start_thread' target: wrk:worker_0 4449 197复制
ksoftirqd 线程处理接收到的,发向 Envoy socket 的数据, 触发 ReadReadywaker: ksoftirqd/1 18 b'ret_from_fork' b'kthread' b'smpboot_thread_fn' b'run_ksoftirqd' b'__softirqentry_text_start' b'net_rx_action' b'process_backlog' b'__netif_receive_skb' b'__netif_receive_skb_one_core' b'ip_rcv' b'ip_rcv_finish' b'ip_local_deliver' b'ip_local_deliver_finish' b'ip_protocol_deliver_rcu' b'tcp_v4_rcv' b'tcp_v4_do_rcv' b'tcp_rcv_established' b'tcp_data_ready' b'sock_def_readable' <-----https://elixir.bootlin.com/linux/v5.4/source/net/core/sock.c#L2791 b'__wake_up_sync_key' b'__wake_up_common_lock' b'__wake_up_common' b'ep_poll_callback' <----https://elixir.bootlin.com/linux/v5.4/source/fs/eventpoll.c#L1207 b'__wake_up' b'__wake_up_common_lock' b'__wake_up_common' b'autoremove_wake_function' -- -- b'finish_task_switch' b'schedule' b'schedule_hrtimeout_range_clock' b'schedule_hrtimeout_range' b'ep_poll' b'do_epoll_wait' b'__x64_sys_epoll_wait' b'do_syscall_64' b'entry_SYSCALL_64_after_hwframe' b'epoll_wait' b'event_base_loop' b'Envoy::Server::WorkerImpl::threadRoutine(Envoy::Server::GuardDog&, std::__1::function<void ()> const&)' b'Envoy::Thread::ThreadImplPosix::ThreadImplPosix(std::__1::function<void ()>, absl::optional<Envoy::Thread::Options> const&)::{lambda(void*)#1}::__invoke(void*)' b'start_thread' target: wrk:worker_1 4450 2066849复制
还记得上面说的:
可见,这次唤醒 Envoy wrk:worker_0 线程的正好是它的 downstream 线程。这是一个特例,只是由于 downstream 线程和 Envoy 运行于同一主机上。真实情况是,唤醒线程可以是主机上的所有无相干的 on-cpu 的线程。下面道来。
是的,这次是 ksoftirqd/1 去唤醒了。
至此,完成了调用链路初探。
像以前文章一样,我们先看看跟踪分析的结果,再看跟踪得出的数据和跟踪用的脚本。这样比较方便直观地理解整个实现。
一图胜千言,先看图吧。后面慢慢道来。下图是我用跟踪收集到的数据,加上一些认知和推理完成的。

图:Envoy 下 epoll 与内核调度协作
看图方法:
先说明一下图中的红点步骤:
do_epoll_wait,线程进程阻塞等待状态 TASK_INTERRUPTABLE_SLEEP。
waiting_task_queue队列ep_poll_callbacktry_to_wake_up把线程从waiting_task_queue队列移动到runnable_task_queue队列。即唤醒了线程,线程变为 RUNNABLE。
on-cpu线程还需要等待调度器才能上 cpu。do_epoll_wait函数上的线程,继续运行,获取唤醒的事件( fd(socket的文件描述符) 和 事件类型(Read/Writeable))。写用用户态的内存,以便返回后用户态线程可以读取事件。Envoy::FileEventImpl::assignEvents::eventCallback( fd=$fd )函数,处理事件,accept/读取/写入相关 socket。看到这里,你会问:步骤不多,为何图中画那么多东西,是作者要卖弄学问吗?嗯,或者部分原因是。但更重要的原因是,这些内核数据结构图和函数对后面的 BPF 程序分析至关重要。
有了上面的基础知识,相关下面的 bpftrace 程序就不难理解了:
|
|
程序不做解释了,双屏,一个看程序,一个看上面的图,就可以理解到了。
环境说明:
downstream_pod IP: 172.30.207.163
target_pod IP: 172.21.206.207
target_sidecar(Envoy) Inbound listen port: 0.0.0.0:15006
target_sidecar(Envoy) 进程 PID: 4182
target_sidecar(Envoy) 主线程TID: 4182
target_sidecar(Envoy) 主线程名: envoy
target_sidecar(Envoy) 工作线程0 TID: 4449
target_sidecar(Envoy) 工作线程0 名: wrk:worker_0
target_sidecar(Envoy) 工作线程1 TID: 4450
target_sidecar(Envoy) 工作线程1 名: wrk:worker_1
target_app endpoint: 172.21.206.207:8080 / 127.0.0.1:8080
复制值得注意的是,wrk:worker_0 和 wrk:worker_1 同时监听在同一个 socket(0.0.0.0:15006) 上,但使用了不同的 fd:
swapper/0 在 SoftIRQ 中处理网络包,推到 TCP 层try_to_wake_up 函数,唤醒了 worker_0 和 worker_1。从跟踪结果看,一个新TCP连接建立唤醒了两个线程。因两个线程均监听了同一 socket,虽然 fd 不相同。worker_0 争夺了连接的 socket 事件的处理权。worker_1算是做了无用的唤醒(惊群 thundering herd problem ?)。worker_0 accept socket 建立新的 socket,fd=42***waker: elapsed=20929 tid=0,comm=swapper/0: ep_poll_callback: fd=40, 0.0.0.0:15006 0.0.0.0:0 LISTEN socket=0xffff9f5e53bfbd40 try_to_wake_up: wakeupedPID=4182, wakeupedTID=4450, wakeupedTIDComm=wrk:worker_1 ***waker: elapsed=20929 tid=0,comm=swapper/0: ep_poll_callback: fd=36, 0.0.0.0:15006 0.0.0.0:0 LISTEN socket=0xffff9f5e53bfbd40 try_to_wake_up: wakeupedPID=4182, wakeupedTID=4449, wakeupedTIDComm=wrk:worker_0 -------- ***sleeper-wakeup: elapsed=20929 , pid=4182, tid=4449,comm=wrk:worker_0, event_count=1 ***** elapsed=20929 : tid=4449,comm=wrk:worker_0: BEGIN:EventFired:FileEventImpl::assignEvents::eventCallback() FileEventImpl*=0x55af6486fea0, fd=36, events=0x2 libevent: EV_READ inet_csk_accept: 172.30.207.163 38590 172.21.206.207 15006 sys_exit_accept4 fd=42复制
***waker: elapsed=20986 tid=10,comm=ksoftirqd/0: ep_poll_callback: fd=42, 172.21.206.207:15006 172.30.207.163:38590 ESTABLISHED socket=0xffff9f5e94e00000
try_to_wake_up: wakeupedPID=4182, wakeupedTID=4449, wakeupedTIDComm=wrk:worker_0
--------
***sleeper-wakeup: elapsed=20986 , pid=4182, tid=4449,comm=wrk:worker_0, event_count=1
***** elapsed=20986 : tid=4449,comm=wrk:worker_0: BEGIN:EventFired:FileEventImpl::assignEvents::eventCallback()
FileEventImpl*=0x55af6496d7a0, fd=42, events=0x22
libevent: EV_READ
libevent: EV_ET
复制ksoftirqd/0 在 SoftIRQ 中处理网络包,推到 TCP 层try_to_wake_up 函数,唤醒了 worker_0。没想到,BPF 最近会成为业界的一个热词。也有幸有前年开始了这个学习之旅。现在业界流行将 BPF/eBPF 用于加速网络,如 Cilium、xx Istio 加速器。也有的用于云监控,如 Pixie 。而暂时,还未有太多的大的成功普及。其原因值得深究。
反观 BCC/bpftrace/libbpf,等。经过多年磨练,已经比较成熟。它在跟踪应用和内核行为上表现优异。上生产,可以定位问题,在实验室,可以剖析复杂的程序。真是入得厨房出得厅堂。是居家旅行的必备良药。
学习上,多年一路走来,内核一直是心中的痛。无论读了多少本内核的书,看了多少优秀文章,也是很难串起来一些流程和数据结构。而有了BPF 后,更多的运行期黑盒变得可视化。如果内核的书和文章让你睡着,那么,试试自己手写和运行 BPF 跟踪内核。观察和实践才是学习的最好方法。现在不缺资讯,缺的是深刻的体会。
本文是在 2022 年 5.1 假期间完成的。很高兴,还可以卷到现在。或者是兴趣,或者是恐惧。总之。不知道能坚持到哪天,那么就好好珍惜今天吧。
