https://blog.mygraphql.com/zh/posts/low-tec/trace/trace-quick-start/复制
程序员有两个世界:
It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts.
– Sherlock Holmes in “A Scandal in Bohemia” by Sir Arthur Conan Doyle
在获得数据之前先进行理论分析是一个重大错误。 荒谬的是,人们开始扭曲事实以适应理论,而不是理论去适应事实。
—— 福尔摩斯(Sherlock Holmes)在亚瑟·柯南·道尔爵士(Arthur Conan Doyle)创作的《波西米亚丑闻》
当我们发现应用程序的功能或性能不如预期时,常用应用或操作系统跟踪的方法来定位问题。这里的跟踪包括以下方法:
本文讨论第二种方法 。
一直以来,如何在资源受限的生产环境,或性能测试环境中跟踪有问题的应用程序都是一个难题。最常见的一个题目是,我的程序慢在哪个地方?聪明的程序员和 DevOps 们不断发明了各种工具:DTrace / SystemTAP / perf ,今天我要介绍的是 eBPF 技术和它的工具栈。
大家知道,即使的编程语言从汇编发展到现在的Java/GO,有一个基本的编程单位的不变的 —— 函数(方法)。即使我们以为已经用了 OOP(面向对象)、AOP、Serverless ,函数依然是编译器、CPU 指令(X86下的 callq)内部的单位,只是内部的函数名字和我们在源码中看到的名字有一定的前后缀等映射关系。
一般,应用或内核中会存在一个符号表(Symbol Tables)记录了应用中的函数和其在应用中的地址
通过跟踪这些函数的调用信息,如调用入参、返回值、调用次数,响应时间分布,就可以为问题定位提供明确和可信的方向。下面是一个符号表的例子:
|
|
发现,bash 有一个内部函数readline。bash 通过它读取每个行 shell 命令。只要监控这个函数的入参,就可以监控系统中的所有 bash 发起的命令。
在 Java 世界,可以通过 java instrument 来实现函数的修改或监听。在更广义的世界 CPU 指令世界,有相近的方法去修改或监听CPU指令。之前说了,一般,源码中的函数,是会编译为一个X86下的 callq 指令。只要我们替换函数的入口为一个断点指令(int3);然后在断点处理程序中调用定制的监听程序;之后再调用实际的原程序。
如 trace 前的 bash 进程 :
# gdb -p 31817
[...]
(gdb) disas readline
Dump of assembler code for function readline:
0x000055f7fa995610 <+0>:
<rl_pending_input> cmpl $0xffffffff,0x2656f9(%rip) # 0x55f7fabfad10
0x000055f7fa995617 <+7>: push %rbx
0x000055f7fa995618 <+8>: je 0x55f7fa99568f <readline+127>
0x000055f7fa99561a <+10>: callq 0x55f7fa994350 <rl_set_prompt>
0x000055f7fa99561f <+15>: callq 0x55f7fa995300 <rl_initialize>
0x000055f7fa995624 <+20>: mov
<rl_prep_term_function>
0x000055f7fa99562b <+27>: test
0x261c8d(%rip),%rax
# 0x55f7fabf72b8
%rax,%rax
[...]
复制用 uprobes 技术 trace 了 readline 函数后:
# gdb -p 31817
[...]
(gdb) disas readline
Dump of assembler code for function readline:
>>>> 0x000055f7fa995610 <+0>: int3 0x000055f7fa995611 <+1>: cmp $0x2656f9,%eax <<<<
0x000055f7fa995616 <+6>: callq *0x74(%rbx)
0x000055f7fa995619 <+9>: jne 0x55f7fa995603 <rl_initialize+771>
0x000055f7fa99561b <+11>: xor
%ebp,%ebp
0x000055f7fa99561d <+13>: (bad)
0x000055f7fa99561e <+14>: (bad)
0x000055f7fa99561f <+15>: callq 0x55f7fa995300 <rl_initialize>
0x261c8d(%rip),%rax
# 0x55f7fabf72b8
[...]
复制Linux 的历史悠久。有好几种的 trace 技术:
| 技术 | 需源程序预留 | 用户进程/内核 |
|---|---|---|
| kprobes | NO | 内核 |
| uprobes | NO | 用户进程 |
| Tracepoints | YES | 内核 |
| USDT | YES | 用户进程 |
而 eBPF 就是使用上面的技术,监听函数的调用,然后抽象为一个事件源(Event Sources):
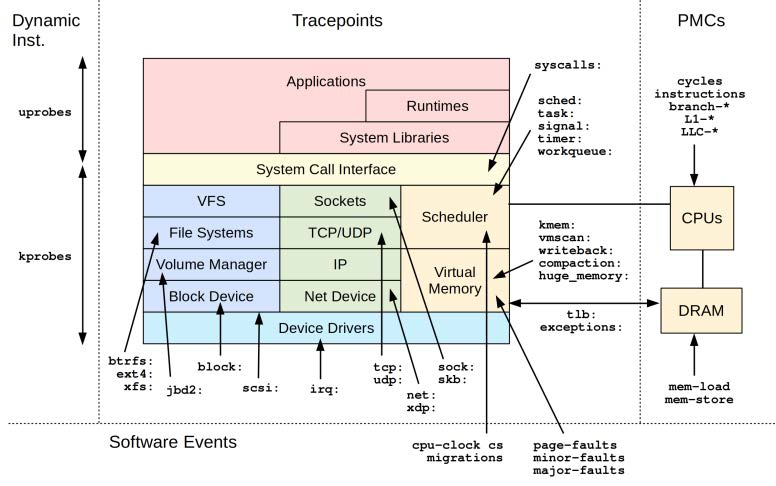
eBPF 打开了跟踪的大門。但門槛太高,于是,我们需要一些封装好的库或工具集。比较成熟的有 BCC 和 ebpftrace。如果你的的 Linux 发行版本中足够新,这两个工具都可以直接安装。
作为一个自吹为干货,实为抄袭😅的文章,还是上点例子好。
假设我们是 bash 的开发,或者,我们了解 bash 的源码,已经知道,bash 通过自己的 readline 函数读取终端的命令。这时,只需要用 uprobe 方法监听 readline 函数的返回值。
以下假设我们在开始监听后,在其它终端中输入了ls / 和 find / 命令。
|
|
你可以通过 bpftrace -l 'uprobe:/bin/bash' 或 readelf 了解一个可执行文件或 so 文件的函数列表。
BCC 的 cachestat 脚本,通过 kprobe 技术,监听内核的 add_to_page_cache_lru等函数,可以计算出缓存命中率。这个功能在定位数据库 IO 问题时,由为实用(我曾经用它定位 Cassandra 数据库的IO问题)。
|
|
无论现代网络硬件和软件如何发展,丢包分析是个永远逃不了的 DevOps 工作。对于 TCP,部分丢包(不是全部对应)可以直接反映在 TCP 重传上。这时,监听内核的 TCP 重传对由为重要。
|
|
可见,列出的发生重传时,丢包的 TCP 连接的双端的 IP 和端口。
以上是最简单的例子。eBPF 世界,才刚开始。后面,我计划说说 eBPF 的应用场景,和它与其它工具如 perf 的比较。再见!Keep tracing !
[BPF Performance Tools]