目录
1、发布订阅
1.1 什么是发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息并且可以订阅任意数量的频道。
发布订阅(Pub/Sub):目前广泛使用的通信模型,它采用事件作为基本的通信机制,提供大规模系统所要求的松散耦合的交互模式:订阅者(如客户端)以事件订阅的方式表达出它有兴趣接收的一个事件或一类事件;发布者(如服务器)可将订阅者感兴趣的事件随时通知相关订阅者------是不是与设计模式里面的观察者模式一个妈妈生的?
最经典的应用场景就是微博和公众号,任何粉丝只要关注(订阅)了某一个人的微博或者公众号,该微博或者公众号就有有状态更新,都会将消息推送(发布)到粉丝....
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
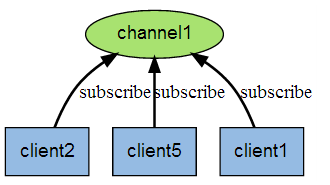
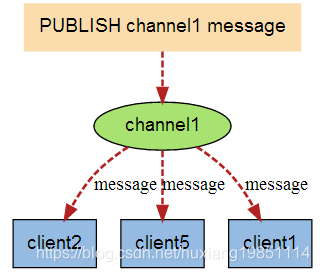
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
1.2 客户端实例演示
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
redis 127.0.0.1:6379> SUBSCRIBE redisChatReading messages... (press Ctrl-C to quit)1) "subscribe"2) "redisChat"3) (integer) 1复制
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
redis 127.0.0.1:6379> PUBLISH redisChat "Redis is a great caching technique"(integer) 1redis 127.0.0.1:6379> PUBLISH redisChat "Learn redis by runoob.com"(integer) 1# 订阅者的客户端会显示如下消息1) "message"2) "redisChat"3) "Redis is a great caching technique"1) "message"2) "redisChat"3) "Learn redis by runoob.com"复制

下表列出了 redis 发布订阅常用命令:
| 序号 | 命令及描述 |
|---|---|
| 1 | PSUBSCRIBE pattern... 订阅一个或多个符合语法的频道。---> PSUBSCRIBE redisChat* 订阅所有以redisChat开头的频道 |
| 2 | PUBLISH channel message 将信息发送到指定的频道。 |
| 3 | PUNSUBSCRIBE pattern ... 退订所有给定模式的频道。 |
| 4 | SUBSCRIBE channel ... 订阅给定的一个或多个频道的信息。 |
1.3 Java API演示
1.3.1 引入jedis依赖
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.3</version> </dependency>复制1.3.2 Publisher (发布者)
package com.ydt.redis.pubsub;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;public class Publisher extends Thread{ private final JedisPool jedisPool; public Publisher(JedisPool jedisPool) { this.jedisPool = jedisPool; } @Override public void run() { BufferedReader reader = new BufferedReader(new InputStreamReader(System.in)); Jedis jedis = jedisPool.getResource(); //连接池中取出一个连接 while (true) { String line = null; try { line = reader.readLine(); if (!"quit".equals(line)) { jedis.publish("mychannel", line); //从 mychannel 的频道上推送消息 } else { break; } } catch (IOException e) { e.printStackTrace(); } } }}复制
1.3.3 Subscriber(订阅者)
package com.ydt.redis.pubsub;import redis.clients.jedis.JedisPubSub;//订阅者需要继承JedisPubSub,来重写它的三个方法public class Subscriber extends JedisPubSub { public Subscriber(){} @Override public void onMessage(String channel, String message) { //收到消息会调用 System.out.println(String.format("receive redis published message, channel %s, message %s", channel, message)); } @Override public void onSubscribe(String channel, int subscribedChannels) { //订阅了频道会调用 System.out.println(String.format("subscribe redis channel success, channel %s, subscribedChannels %d", channel, subscribedChannels)); } @Override public void onUnsubscribe(String channel, int subscribedChannels) { //取消订阅 会调用 System.out.println(String.format("unsubscribe redis channel, channel %s, subscribedChannels %d", channel, subscribedChannels)); }}复制
1.3.4 SubThread(订阅频道)
package com.ydt.redis.pubsub;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;public class SubThread extends Thread { private final JedisPool jedisPool; private final Subscriber subscriber = new Subscriber(); private final String channel = "mychannel"; public SubThread(JedisPool jedisPool) { super("SubThread"); this.jedisPool = jedisPool; } @Override public void run() { System.out.println(String.format("subscribe redis, channel %s, thread will be blocked", channel)); Jedis jedis = null; try { jedis = jedisPool.getResource(); //取出一个连接 jedis.subscribe(subscriber, channel); //通过subscribe 的api去订阅,入参是订阅者和频道名 } catch (Exception e) { System.out.println(String.format("subsrcibe channel error, %s", e)); } finally { if (jedis != null) { jedis.close(); } } }}复制
1.3.5 测试
package com.ydt.redis.pubsub;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;public class PubSubDemo { public static void main( String[] args ) { // 连接redis服务端 JedisPool jedisPool = new JedisPool(new JedisPoolConfig(), "192.168.223.128", 6379); System.out.println(String.format("redis pool is starting, redis ip %s, redis port %d", "192.168.223.128", 6379)); SubThread subThread1 = new SubThread(jedisPool); //订阅者1 subThread1.start(); SubThread subThread2 = new SubThread(jedisPool); //订阅者2 subThread2.start(); Publisher publisher = new Publisher(jedisPool); //发布者 publisher.start(); }}复制
1.4 Redis发布订阅和rabbitmq的区别
可靠性redis :没有相应的机制保证消息的可靠消费,如果发布者发布一条消息,而没有对应的订阅者的话,这条消息将丢失,不会存在内存中(临时内存,没有消费者就直接清除,有消费者就直接消费掉);rabbitmq:具有消息消费确认机制,如果发布一条消息,还没有消费者消费该队列,那么这条消息将一直存放在队列中,直到有消费者消费了该条消息,以此可以保证消息的可靠消费;实时性redis:实时性高,redis作为高效的缓存服务器,所有数据都存在在服务器中,所以它具有更高的实时性消费者负载均衡rabbitmq队列可以被多个消费者同时监控消费,但是每一条消息只能被消费一次,由于rabbitmq的消费确认机制,因此它能够根据消费者的消费能力而调整它的负载(主要通过Routing Key);redis发布订阅模式,一个频道可以被多个消费者同时订阅,当有消息到达时,会将该消息依次发送给每个订阅者;持久性redis:redis的持久化是针对于整个redis缓存的内容,它有RDB和AOF两种持久化方式(redis持久化方式,可以提前看本课件第三节),可以将整个redis实例持久化到磁盘,以此来做数据备份,防止异常情况下导致数据丢失。rabbitmq:队列,消息都可以选择性持久化,持久化粒度更小,更灵活;队列监控rabbitmq实现了后台监控平台,可以在该平台上看到所有创建的队列的详细情况,良好的后台管理平台可以方便我们更好的使用;redis没有所谓的监控平台。总结redis: 轻量级,低延迟,高并发,低可靠性;rabbitmq:重量级,高可靠,异步,不保证实时;rabbitmq是一个专门的AMQP协议队列,他的优势就在于提供可靠的队列服务,并且可做到异步,而redis主要是用于缓存的,redis的发布订阅模块,可用于实现及时性,且可靠性低的功能。复制
2、批量操作
概要理论
Redis 的 pipeline(管道)功能在命令行中没有,但 redis 是支持 pipeline 的,而且在各个语言版的 client 中都有相应的实现。 由于网络开销延迟,就算 redis server 端有很强的处理能力,也会由于收到的 client 消息少,而造成吞吐量小。当 client 使用 pipelining 发送命令时,redis server 必须将部分请求放到队列中(使用内存),执行完毕后一次性发送结果!
Pipeline 在某些场景下非常有用,比如有多个 command 需要被“及时的”提交,而不需要“及时的”响应,那么 pipeline 就可以充当这种“批处理”的工具;而且在一定程度上,可以较大的提升性能,性能提升的原因主要是 TCP 连接中减少了“交互往返”的时间
2.1 普通模式与 PipeLine 模式
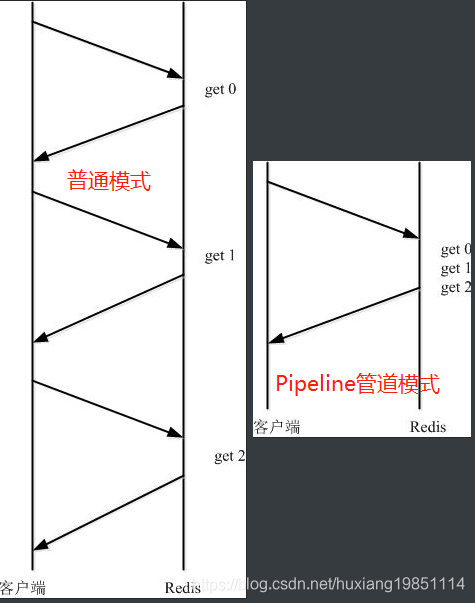
很明显,减少了连接次数,节省了网络资源
下面,我们通过一个demo看下具体效果,分别以两种方式往redis中插入10000条数据
pom.xml
<dependencies> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.0.5.RELEASE</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.3</version> </dependency> <!-- spring-redis --> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> <version>1.6.4.RELEASE</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> <version>2.4.2</version> </dependency> </dependencies>复制spring配置文件
<!--Jedis连接池的相关配置--> <bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"> <property name="maxTotal"> <value>200</value> </property> <property name="maxIdle"> <value>50</value> </property> <property name="testOnBorrow" value="true"/> <property name="testOnReturn" value="true"/> </bean> <bean id="jedisPool" class="redis.clients.jedis.JedisPool"> <constructor-arg name="poolConfig" ref="jedisPoolConfig" /> <constructor-arg name="host" value="127.0.0.1" /> <constructor-arg name="port" value="6379" type="int" /> <constructor-arg name="timeout" value="30000" type="int" /> </bean>复制测试代码
@Test public void testGeneralAndPipeline(){ JedisPool jedisPool = (JedisPool) context.getBean("jedisPool"); Jedis jedis = jedisPool.getResource(); Logger logger = Logger.getLogger(ClusterTest.class); long start = System.currentTimeMillis(); for (int i = 0; i < 10000; i++) { jedis.set(String.valueOf(i), String.valueOf(i)); } long end = System.currentTimeMillis(); logger.info("the general total time is:" + (end - start)); Pipeline pipe = jedis.pipelined(); // 先创建一个 pipeline 的链接对象 long start_pipe = System.currentTimeMillis(); for (int i = 0; i < 10000; i++) { pipe.set(String.valueOf(i), String.valueOf(i)); } pipe.sync(); // 获取所有的 response long end_pipe = System.currentTimeMillis(); logger.info("the pipe total time is:" + (end_pipe - start_pipe)); }复制
执行结果:
16:03:17,592 INFO ClusterTest:114 - the general total time is:263416:03:17,692 INFO ClusterTest:123 - the pipe total time is:77复制
可以很明显的看到,差别是巨大的!
2.2 适用场景
有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进 redis 了,那这种场景就不适合。----总时间长,单条响应快
还有的系统,可能是批量的将数据写入 redis,允许一定比例的写入失败,那么这种场景就可以使用了,比如10000条一下进入 redis,可能失败了2条无所谓,后期有补偿机制就行了,比如短信群发这种场景,如果一下群发10000条,按照第一种模式去实现,那这个请求过来,要很久才能给客户端响应,这个延迟就太长了,如果客户端请求设置了超时时间5秒,那肯定就抛出异常了,而且本身群发短信要求实时性也没那么高,这时候用 pipeline 最好了。---总时间短,单条响应跟总时间一样,自然比普通模式响应要慢
2.3 源码解析
第一阶段:
循环调用set方法,将所有的command命令写入输出流,但是输出流一直没有调用flush命令将数据刷入缓存!
protected Connection sendCommand(final Command cmd, final byte[]... args) { try { connect(); Protocol.sendCommand(outputStream, cmd, args); pipelinedCommands++; return this; } catch (JedisConnectionException ex) { ....... } private static void sendCommand(final RedisOutputStream os, final byte[] command, final byte[]... args) { try { os.write(ASTERISK_BYTE); os.writeIntCrLf(args.length + 1); os.write(DOLLAR_BYTE); os.writeIntCrLf(command.length); os.write(command); os.writeCrLf(); for (final byte[] arg : args) { os.write(DOLLAR_BYTE); os.writeIntCrLf(arg.length); os.write(arg); os.writeCrLf(); } } catch (IOException e) { throw new JedisConnectionException(e); } }复制
第二阶段:
调用sync方法,一次性将outputStream里面的数据通过Socket刷入redis serverr
public List<Object> getAll(int except) { List<Object> all = new ArrayList<Object>(); flush(); while (pipelinedCommands > except) { try { all.add(readProtocolWithCheckingBroken()); } catch (JedisDataException e) { all.add(e); } pipelinedCommands--; } return all;}protected void flush() { try { outputStream.flush(); } catch (IOException ex) { broken = true; throw new JedisConnectionException(ex); } }复制
对比普通模式:
每一次set的时候都会调用flush方法,将输出流中的字节数据刷入redis server
public String set(final String key, final String value) { checkIsInMultiOrPipeline();//检查是否管道模式批量提交 client.set(key, value); return client.getStatusCodeReply();}public String getStatusCodeReply() { flush(); pipelinedCommands--; final byte[] resp = (byte[]) readProtocolWithCheckingBroken(); if (null == resp) { return null; } else { return SafeEncoder.encode(resp); } }复制
2.4 Pipelining的局限性
Pipelining只能用于执行连续且无相关性的命令,当某个命令的生成需要依赖于前一个命令的返回时,就无法使用Pipelining了。通过 LUA Scripting功能,可以规避这一局限性
2.5 事务与 LUA Scripting
2.5.1 事务实现
Pipelining能够让Redis在一次交互中处理多条命令,然而在一些场景下,我们可能需要在此基础上确保这一组命令是连续执行的。比如获取当前累计的count
127.0.0.1:6379> SET count 100OK127.0.0.1:6379> INCR count(integer) 101127.0.0.1:6379> get count"101"复制
如果在GET和SET命令之间插进来一个INCR count,就会使客户端拿到的count不准确。
Redis的事务可以确保复数命令执行时的原子性。
也就是说Redis能够保证:一个事务中的一组命令是绝对连续执行的,在这些命令执行完成之前,绝对不会有来自于其他连接的其他命令插进去执行。
通过MULTI和EXEC命令来把这两个命令加入一个事务中:
127.0.0.1:6379> MULTIOK127.0.0.1:6379> set name laohuQUEUED127.0.0.1:6379> set age 18QUEUED127.0.0.1:6379> set sex manQUEUED127.0.0.1:6379> EXEC1) OK2) OK3) OK复制
Java实现:
@Test public void testMulti() throws InterruptedException { for (int i = 0; i < 10; i++) { if( i == 0 ){ jedis.set("" + i, i +""); }else { jedis.set("" + i, (i + Integer.valueOf(jedis.get((i-1)+""))) + ""); } Thread.sleep(10000);//此处有人捣乱? } } @Test public void testTransaction() throws InterruptedException { Transaction transaction = jedis.multi(); int last = 0; for (int i = 0; i < 10; i++) { if( i == 0 ){ transaction.set("" + i, i +""); }else { transaction.set("" + i, (i + last) + ""); } last = i +last; } transaction.exec(); }复制
-
Redis在接收到MULTI命令后便会开启一个事务,这之后的所有读写命令都会保存在队列中但并不执行
-
直到接收到EXEC命令后,Redis会把队列中的所有命令连续顺序执行,并以数组形式返回每个命令的返回结果。
-
可以使用DISCARD命令放弃当前的事务,将保存的命令队列清空。
-
需要注意的是,Redis事务不支持回滚:如果一个事务中的命令出现了语法错误,大部分客户端驱动会返回错误
2.6.5版本以上的Redis也会在执行EXEC时检查队列中的命令是否存在语法错误,如果存在,则会自动放弃事务并返回错误。 但如果一个事务中的命令有非语法类的错误(比如对String执行HSET操作),无论客户端驱动还是Redis都无法在真正执行这条命令之前发现,所以事务中的所有命令仍然会被依次执行。
在这种情况下,会出现一个事务中部分命令成功部分命令失败的情况,然而与RDBMS(关系型数据库)不同,Redis不提供事务回滚的功能,所以只能通过其他方法进行数据的回滚。
2.4.2 通过事务实现CAS
Redis提供了WATCH命令与事务搭配使用,实现CAS乐观锁的机制。
127.0.0.1:6379> watch countOK127.0.0.1:6379> MULTIOK127.0.0.1:6379> INCR countQUEUED127.0.0.1:6379> INCR count #这一步执行完后,开启另外一个窗口,执行INCR count,修改该key,让事务执行时返回失败QUEUED127.0.0.1:6379> EXEC(nil)127.0.0.1:6379> get count"101"复制
WATCH的机制是:在事务EXEC命令执行时,Redis会检查被WATCH的key,只有被WATCH的key从WATCH起始时至今没有发生过变更,EXEC才会被执行。
如果WATCH的key在WATCH命令到EXEC命令之间发生过变化,则EXEC命令会返回失败
Java模拟场景,100个人下单,100个库存,加上watch和不加的区别
@Test public void testWatch() throws Exception { jedis.set("test_count", "100"); ExecutorService executorService = Executors.newCachedThreadPool(); for (int i = 0; i < 200; i++) { Thread.sleep(100); executorService.execute(new Runnable() { @Override public void run() { go(); } }); } } private void go(){ JedisPool jedisPool = (JedisPool) context.getBean("jedisPool"); Jedis jedis = jedisPool.getResource(); try { String key_s = "user_name";// 抢到的用户 String key = "test_count";// 商品数量 String clientName = UUID.randomUUID().toString().replace("-", "");// 用户名字 while (true) { try { /*jedis.watch(key);// key加上乐观锁*/ System.out.println("用户:" + clientName + "开始抢商品"); System.out.println("当前商品的个数:" + jedis.get(key)); int prdNum = Integer.parseInt(jedis.get(key));// 当前商品个数 if (prdNum > 0) { Transaction transaction = jedis.multi();// 标记一个事务块的开始 transaction.set(key, String.valueOf(prdNum - 1)); List<Object> result = transaction.exec();// 原子性提交事物 if (result == null || result.isEmpty()) { System.out.println("用户:" + clientName + "没有抢到商品");// 可能是watch-key被外部修改,或者是数据操作被驳回 } else { jedis.sadd(key_s, clientName);// 将抢到的用户存起来 System.out.println("用户:" + clientName + "抢到商品"); break; } } else { System.out.println("库存为0,用户:" + clientName + "没有抢到商品"); break; } } catch (Exception e) { e.printStackTrace(); } finally { /*jedis.unwatch();// exec,discard,unwatch命令都会清除连接中的所有监视*/ } } // while } catch (Exception e) { System.out.println("redis bug:" + e.getMessage()); } finally { // 释放jedis连接 try { jedis.close(); } catch (Exception e) { System.out.println("redis bug:" + e.getMessage()); } } }复制
2.4.3 LUA Scripting
通过EVAL与EVALSHA命令,可以让Redis执行LUA脚本。这就类似于RDBMS的存储过程一样,可以把客户端与Redis之间密集的读/写交互放在服务端进行,避免过多的数据交互,提升性能。
Scripting功能是作为事务功能的替代者诞生的,事务提供的所有能力Scripting都可以做到。Redis官方推荐使用LUA Script来代替事务,以兼容性能和避免管道事务执行的无序性问题
@Testpublic void testLua(){ StringBuffer sb = new StringBuffer(); for (int i = 0; i < 5; i++) { sb.append("redis.call('set','lua"+i+"','hello lua"+i+"');"); } sb.append("return redis.call('get' ,'lua3')"); System.out.println(jedis.eval(String.valueOf(sb)));}复制
3、持久化
3.1 为什么需要持久化
因为Redis是内存数据库,它将自己的数据存储在内存里面,一旦Redis服务器进程退出或者运行Redis服务器的计算机停机,Redis服务器中的数据就会丢失。
为了避免数据丢失,所以Redis提供了持久化机制,将存储在内存中的数据保存到磁盘中,用于在Redis服务器进程退出或者运行Redis服务器的计算机停机导致数据丢失时,快速的恢复之前Redis存储在内存中的数据。
3.2 持久化方式
3.2.1 Redis持久化---RDB
RDB持久化是将某个时间点上Redis中的数据保存到一个RDB文件中,也叫快照持久化;
该文件是一个经过压缩的二进制文件,通过该文件可以还原生成RDB文件时Redis中的数据 ;
过程如下:
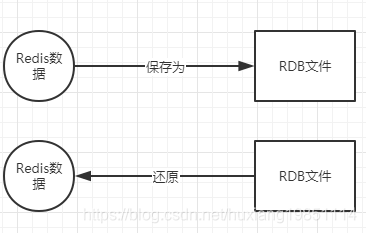
3.2.1.1 创建RDB文件
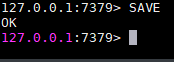
Redis提供了2个命令来创建RDB文件,一个是SAVE,另一个是BGSAVE。
SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求
BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求
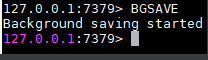
PS: 因为BGSAVE命令可以在不阻塞服务器进程的情况下执行,所以推荐使用BGSAVE命令
3.2.1.2 RDB文件创建方式
自动保存
触发机制有如下:
1、save m n
自动触发最常见的情况是在配置文件中通过配置save m n,指定当m秒内发生n次变化时,会触发bgsave。
save 900 1save 300 10save 60 10000复制
其中save 900 1的含义是:当时间到900秒时,如果Redis数据发生了至少1次变化,则执行bgsave;save 300 10和save 60 10000同理。当三个save条件满足任意一个时,都会引起bgsave的调用。
PS:1、Redis的save m n,是通过serverCron函数、dirty计数器、和lastsave时间戳来实现的。
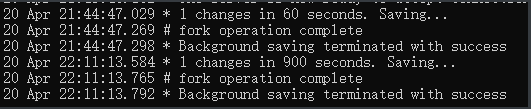
2、主从复制场景下,如果从节点执行全量复制操作,则主节点会执行 bgsave 命令,并将rdb文件发送给从节点 (主从复制后面会说到)
3、执行shutdown命令时也会触发自动保存

4、重启redis,执行debug reload时也会自动触发保存

手动保存
save和bgsave命令,推荐使用bgsave,不过说了等于没说,基本上都不会直接手动保存,~ ~
3.2.1.3 总结
优点:
RDB文件小,非常适合定时备份,用于灾难恢复。
因为RDB文件中直接存储的是内存数据,而AOF文件中存储的是一条条命令,需要执行命令。Redis加载RDB文件的速度比AOF快很多。
缺点:
RDB持久化方式不能做到实时/秒级持久化。实时持久化要全量刷内存到磁盘,成本太高,影响性能。RDB文件是二进制文件,随着Redis不断迭代有多个rdb文件的版本,不支持跨版本兼容。老的Redis无法识别新的RDB文件格式。
3.2.2 Redis持久化---AOF
3.2.2.1 AOF持久化概念
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库数据的 ,图示

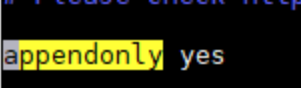
3.2.2.2 开启AOF
AOF持久化默认情况下是关闭的,使用前需要先开启,编辑redis.conf文件,修改如下:
执行命令生成如下文件:

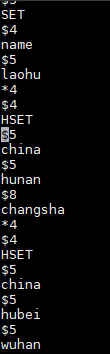
编辑打开,可以看到里面的所有命令:
3.3 文件同步方式
appendfsync配置主要是保证集群中数据的一致性
| 选项 | 安全性 | 效率 |
|---|---|---|
| everysec(推荐) | 安全性适中,故障停机,数据库也只会丢失一秒的命令数据 | 每秒同步一次 |
| always | 安全性最高,故障停机,数据库也只会丢失一个事件循环中所产生的命令数据 | 每一个命令 |
| no | 安全性最低,故障停机,数据库会丢失上次同步AOF文件之后的所有写命令数据 | 不主动同步,完全依赖操作系统,一般linux为30秒左右一次 |
3.4 文件重写(压缩)
动机: 随着运行时间的增长,执行的命令越来越多,会导致AOF文件越来越大,当AOF文件过大时,redis会执行重写机制来压缩AOF文件
AOF文件重写并不需要对现有的AOF文件进行任何读取、分析或者写入操作,而是通过读取服务器当前的数据库数据来实现的 ,主要是将文件中无效命令剔除,如:
-
同一个key的值,只保留最后一次写入
-
已删除或者已过期数据相关命令会被去除
自动配置:
auto-aof-rewrite-min-size 64MB // 当文件小于64M时不进行重写auto-aof-rewrite-min-percenrage 100 // 当文件比上次重写后的文件大100%时进行重写复制
手动触发:

响应

重写的过程
-
从主进程中fork出子进程,并拿到fork时的AOF文件数据写到一个临时AOF文件中---》分离子进程
-
在重写过程中,redis收到的命令会同时写到AOF缓冲区和重写缓冲区中,这样保证重写不丢失重写过程中的命令---》过程写操作命令收集
-
重写完成后通知主进程,主进程会将AOF缓冲区中的数据追加到子进程生成的文件中---》追加写操作命令数据
-
redis会原子的将旧文件替换为新文件,并开始将数据写入到新的aof文件上---》替换旧AOF文件
效果图:
重写前: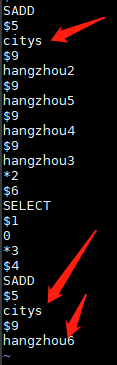 ----------》重写后
----------》重写后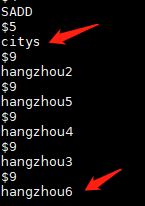
3.5 总结
AOF优缺点
优点:数据的完整性和一致性更高 缺点:因为AOF记录的内容多,文件会越来越大,数据恢复也会越来越慢,因为不管怎么压缩,它的命令基数总是在不断增长的。
RDB和AOF模式一般都会一起使用,毕竟数据的稳定性高于一切,两者同时持久化时,数据的恢复流程图如下:
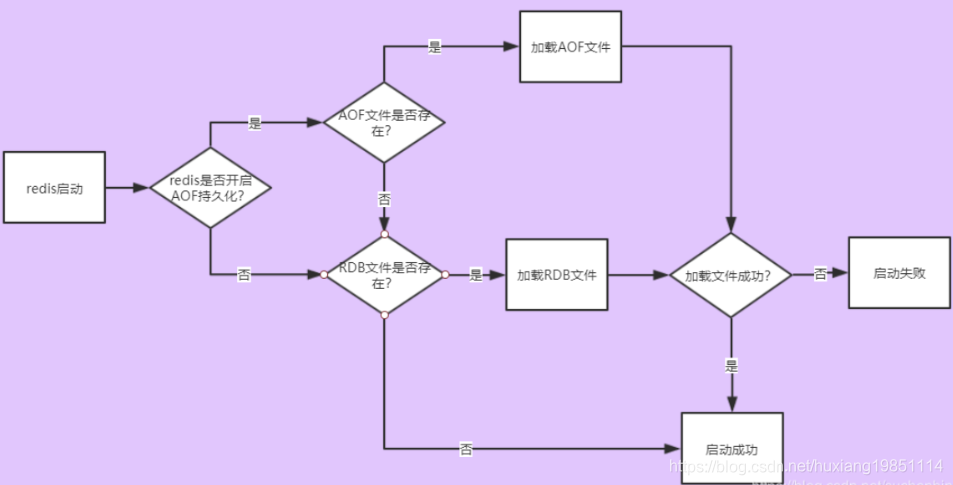
4、内存淘汰
4.1 最大内存设置
默认情况下,在32位OS中,Redis最大使用3GB的内存,在64位OS中则没有限制。
在使用Redis时,应该对数据占用的最大空间有一个基本准确的预估,并为Redis设定最大使用的内存。
否则在64位OS中Redis会无限制地占用内存(当物理内存被占满后会使用swap空间),容易引发各种各样的问题。
通过如下配置控制Redis使用的最大内存:
maxmemory 100mb复制
在内存占用达到了maxmemory后,再向Redis写入数据时,Redis会:
-
根据配置的数据淘汰策略尝试淘汰数据,释放空间
-
如果没有数据可以淘汰,或者没有配置数据淘汰策略,那么Redis会对所有写请求返回错误,但读请求仍然可以正常执行
异常信息:io.lettuce.core.RedisCommandExecutionException: OOM command not allowed when used memory > 'maxmemory'.复制
在为Redis设置maxmemory时,需要注意:
如果采用了Redis的主从同步,主节点向从节点同步数据时,会占用掉一部分内存空间
如果maxmemory过于接近主机的可用内存,会导致数据同步时内存不足。
所以设置的maxmemory不要过于接近主机可用的内存,留出一部分预留用作主从同步。
4.2 数据淘汰机制
Redis提供了5种数据淘汰策略:
-
volatile-lru:使用LRU算法进行数据淘汰(淘汰上次使用时间最早的,且使用次数最少的key),只淘汰设定了有效期的key
-
allkeys-lru:使用LRU算法进行数据淘汰,所有的key都可以被淘汰
-
volatile-random:随机淘汰数据,只淘汰设定了有效期的key
-
allkeys-random:随机淘汰数据,所有的key都可以被淘汰
-
volatile-ttl:淘汰剩余有效期最短的key
最好为Redis指定一种有效的数据淘汰策略以配合maxmemory设置,避免在内存使用满后发生写入失败的情况。
一般来说,推荐使用的策略是volatile-lru,并辨识Redis中保存的数据的重要性。
对于那些重要的,绝对不能丢弃的数据(如配置类数据等),应不设置有效期,这样Redis就永远不会淘汰这些数据。
对于那些相对不是那么重要的,并且能够热加载的数据(比如缓存最近登录的用户信息,当在Redis中找不到时,程序会去DB中读取),可以设置上有效期,这样在内存不够时Redis就会淘汰这部分数据。
配置方法:
maxmemory-policy volatile-lru #默认是noeviction,即不进行数据淘汰复制