文章首发于公众号:BiggerBoy
原文链接
一个Redis生产事故的复盘,整理这篇文章分享给大家。本期文章分析Redis中的bigkey相关问题,主要从以下几个点入手:
什么是bigkey?
在Redis中数据都是key-value的形式存储的。bigkey是指key对应的value所占的内存空间比较大。
例如一个String类型的value最大可以存512MB的数据,一个list类型的value最多可以存储2^32-1个元素。
如果按照数据结构来细分的话,一般分为字符串类型bigkey和非字符串类型bigkey。
也有叫bigvalue的,被问到时不要惊讶。
但在实际生产环境中出现下面两种情况,我们就可以认为它是bigkey。
1.字符串类型: 它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
2.非字符串类型: 哈希、列表、集合、有序集合,它们的big体现在元素个数太多。
一般来说,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
bigkey的危害
bigkey的危害体现在几个方面:
1.内存空间不均匀(平衡)
例如在Redis Cluster中,大量bigkey落在其中一个Redis节点上,会造成该节点的内存空间使用率比其他节点高,造成内存空间使用不均匀。
2.请求倾斜
对于非字符串类型的bigkey的请求,由于其元素较多,很可能对于这些元素的请求都落在Redis cluster的同一个节点上,造成请求不均匀,压力过大。
3.超时阻塞
由于Redis单线程的特性,操作bigkey比较耗时,也就意味着阻塞Redis可能性增大。这就是造成生产事故的罪魁祸首!导致Redis间歇性卡死、影响线上正常下单!
4.网络拥塞
每次获取bigkey产生的网络流量较大,假设一个bigkey为1MB,每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾,而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey可能会对其他实例造成影响,其后果不堪设想。图12-3演示了网络带宽bigkey占用的瞬间。
5.过期删除
有个bigkey,它安分守己(只执行简单的命令,例如hget、lpop、zscore等),但它设置了过期时间,当它过期后,会被删除,如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。
bigkey的产生
一般来说,bigkey的产生都是由于程序设计不当,或者对于数据规模预料不清楚造成的,来看几个例子:
**(1) 社交类:**如果对于某些明星或者大v的粉丝列表不精心设计下,必是bigkey。
**(2) 统计类:**例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey。
**(3) 缓存类:**将数据从数据库load出来序列化放到Redis里,这个方式很常用,但有两个地方需要注意,第一:是不是有必要把所有字段都缓存;第二:有没有相互关联的数据,有的同学为了图方便把相关数据都存一个key下,产生bigkey。
如何发现bigkey
redis-cli --bigkeys 可以命令统计bigkey的分布。
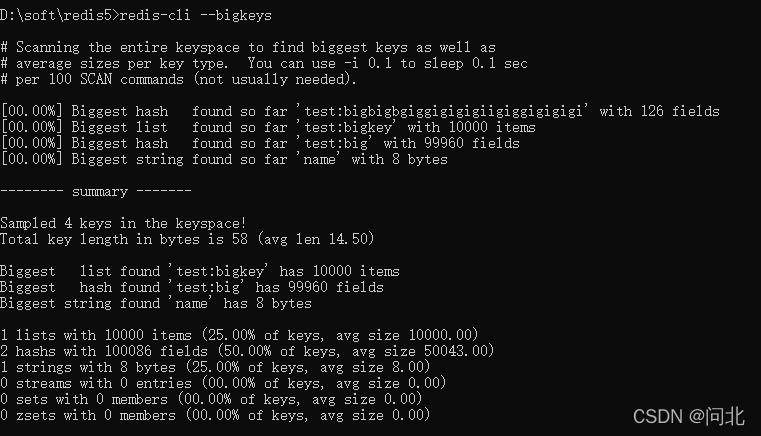
但是在生产环境中,开发和运维人员更希望自己可以定义bigkey的大小,而且更希望找到真正的bigkey都有哪些,这样才可以去定位、解决、优化问题。
判断一个key是否为bigkey,只需要执行 debug object key 查看serializedlength属性即可,它表示key对应的value序列化之后的字节数,
例如我们执行如下操作:
> debug object test:bigkey:hash
Value at:00007FCD1AC28870 refcount:1 encoding:hashtable serializedlength:3122200 lru:5911519 lru_seconds_idle:8788
- 1
- 2
可以发现serializedlength=3122200字节,约为2.97M,同时可以看到encoding是hashtable,也就是hash类型。
那么可以通过strlen来看一下字符串的字节数为2247394字节,约为2MB;
再来看一个string类型的
执行如下操作:
> debug object test:bigkey:string
Value at:0x7fc06c1b1430 refcount:1 encoding:raw serializedlength:1256350 lru:11686193
lru_seconds_idle:20
- 1
- 2
- 3
可以发现serializedlength=1256350字节,约为1.19M,同时可以看到encoding是raw,也就是字符串类型。
那么可以通过strlen来看一下字符串的字节数为2247394字节,约为2MB:
> strlen test:bigkey:string
(integer) 2247394
- 1
- 2
serializedlength不代表真实的字节大小,它返回对象使用RDB编码序列化后的长度,值会偏小,但是对于排查bigkey有一定辅助作用,因为不是每种数据结构都有类似strlen这样的方法。
实际生产的操作方式
在实际生产环境中发现bigkey的两种方式如下:
被动收集
许多开发人员确实可能对bigkey不了解或重视程度不够,但是这种bigkey一旦大量访问,很可能就会带来命令慢查询和网卡跑满问题,开发人员通过对异常的分析通常能找到异常原因可能是bigkey,这种方式虽然不是被笔者推荐的,但是在实际生产环境中却大量存在,建议修改Redis客户端,当抛出异常时打印出所操作的key,方便排bigkey问题。
主动检测
scan+debug object:如果怀疑存在bigkey,可以使用scan命令渐进地扫描出所有的key,分别计算每个key的serializedlength,找到对应bigkey进行相应的处理和报警,这种方式是比较推荐的方式。
如何优化bigkey
由于开发人员对Redis的理解程度不同,在实际开发中出现bigkey在所难免,重要的是,能通过合理的检测机制及时找到它们,进行处理。
作为开发人员在业务开发时应注意不能将Redis简单暴力的使用,应该在数据结构的选择和设计上更加合理,避免出现bigkey。
1. 拆分
基本思路就是,让 key/value 更加小。在设计之初就思考可不可以做一些优化(例如拆分数据结构)尽量让这些bigkey消失在业务中。当出现bigkey已经影响到正常使用了,则考虑重新构建自己的业务key,对bigkey进行拆分。
对于list类型,可以将一个大的list拆成若干个小list:list1、list2、…listN
对于hash类型,可以将数据分段存储,比如一个大的key,假设存了1百万的用户数据,可以拆分成200个key,每个key下面存放5000个用户数据
2. 局部操作
如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来。
例如,对于hash类型有时候仅仅需要hmget,而不是hgetall;对于list类型可以使用range取一个范围内的元素;删除也是一样,尽量使用优雅的方式来处理,而不是暴力的使用del删除。(下面会重点讲如何优雅删除bigkey)
3.lazy free
可喜的是,Redis在4.0版本支持lazy delete free的模式,删除bigkey不会阻塞Redis。
如何优雅删除bigkey
因为 redis 是单线程的,删除比较大的 keys 就会阻塞其他的请求。
当发现Redis中有bigkey并且确认要删除时(业务上需要把key删除时),如何优雅地删除bigkey?
其实在Redis中,无论是什么数据结构,del命令都能将其删除。
但是相信通过上面的分析后你一定不会这么做,因为删除bigkey通常来说会阻塞Redis服务。
下面给出一组测试数据分别对string、hash、list、set、sorted set五种数据结构的bigkey进行删除,bigkey的元素个数和每个元素的大小不尽相同。
删除时间测试
下面测试和服务器硬件、Redis版本比较相关,可能在不同的服务器上执行速度不太相同,但是能提供一定的参考价值
1.字符串类删除测试
下表展示了删除512KB~10MB的字符串类型数据所花费的时间,总体来说由于字符串类型结构相对简单,删除速度比较快,但是随着value值的不断增大,删除速度也逐渐变慢。

2.非字符串类删除测试
下表展示了非字符串类型的数据结构在不同数量级、不同元素大小下对bigkey执行del命令的时间,总体上看元素个数越多、元素越大,删除时间越长,相对于字符串类型,这种删除速度已经足够可以阻塞Redis。
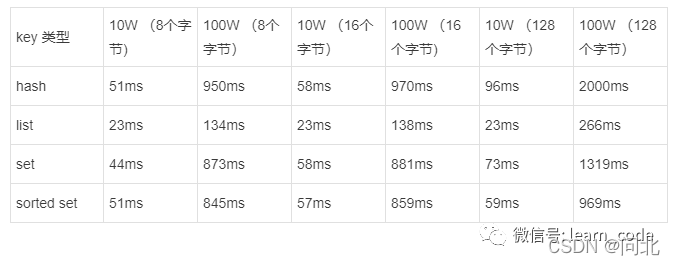
从上分析可见,除了string类型,其他四种数据结构删除的速度有可能很慢,这样增大了阻塞Redis的可能性。
如何提升删除的效率
既然不能用del命令,那有没有比较优雅的方式进行删除呢?Redis提供了一些和scan命令类似的命令:sscan、hscan、zscan。
1.string
字符串删除一般不会造成阻塞
del bigkey
2.hash、list、set、sorted set
下面以hash为例子,使用hscan命令,每次获取部分(例如100个)fieldvalue,再利用hdel删除每个field(为了快速可以使用Pipeline):
public void delBigHash(String bigKey) {
Jedis jedis = new Jedis(“127.0.0.1”, 6379);
// 游标
String cursor = “0”;
while (true) {
ScanResult<Map.Entry<String, String>> scanResult = jedis.hscan(bigKey, cursor, new ScanParams().count(100));
// 每次扫描后获取新的游标
cursor = scanResult.getStringCursor();
// 获取扫描结果
List<Entry<String, String>> list = scanResult.getResult();
if (list == null || list.size() == 0) {
continue;
}
String[] fields = getFieldsFrom(list);
// 删除多个field
jedis.hdel(bigKey, fields);
// 游标为0时停止
if (cursor.equals(“0”)) {
break;
}
}
// 最终删除key
jedis.del(bigKey);
}
/**
获取field数组
@param list
@return
*/
private String[] getFieldsFrom(List<Entry<String, String>> list) {
List<String> fields = new ArrayList<String>();
for(Entry<String, String> entry : list) {
fields.add(entry.getKey());
}
return fields.toArray(new String[fields.size()]);
}
请勿忘记每次执行到最后执行del key操作。
实战代码
1.JedisCluster示例
/**
* 刪除 BIG key
* 应用场景:对于 big key,可以使用 hscan 首先分批次删除,最后统一删除
* (1)比直接删除的耗时变长,但是不会产生慢操作。
* (2)新业务实现尽可能拆开,不要依赖此方法。
* @param key key
* @param scanCount 单次扫描总数(建议值:100)
* @param intervalMills 分批次的等待时间(建议值:5)
*/
void removeBigKey(final String key, final int scanCount, final long intervalMills)
实现
JedisCluster jedisCluster = redisClusterTemplate.getJedisClusterInstance();
// 游标初始值为0
String cursor = ScanParams.SCAN_POINTER_START;
ScanParams scanParams = new ScanParams();
scanParams.count(scanCount);
while (true) {
// 每次扫描后获取新的游标
ScanResult<Map.Entry<String, String>> scanResult = jedisCluster.hscan(key, cursor, scanParams);
cursor = scanResult.getStringCursor();
// 获取扫描结果为空
List<Map.Entry<String, String>> list = scanResult.getResult();
if (CollectionUtils.isEmpty(list)) {
break;
}
// 构建多个删除的 key
String[] fields = getFieldsKeyArray(list);
jedisCluster.hdel(key, fields);
// 游标为0时停止
if (ScanParams.SCAN_POINTER_START.equals(cursor)) {
break;
}
// 沉睡等待,避免对 redis 压力太大
DateUtil.sleepInterval(intervalMills, TimeUnit.MILLISECONDS);
}
// 执行 key 本身的删除
jedisCluster.del(key);
构建的 key
/**
* 获取对应的 keys 信息
* @param list 列表
* @return 结果
*/
private String[] getFieldsKeyArray(List<Map.Entry<String, String>> list) {
String[] strings = new String[list.size()];
for(int i = 0; i < list.size(); i++) {
strings[i] = list.get(i).getKey();
}
return strings;
}
redisTemplate 的写法
估计是 redis 进行了一次封装,发现还是存在很多坑。
语法如下:
/**
* 获取集合的游标。通过游标可以遍历整个集合。
* ScanOptions 这个类中使用了构造者 工厂方法 单例。 通过它可以配置返回的元素
* 个数 count 与正则匹配元素 match. 不过count设置后不代表一定返回的就是count个。这个只是参考
* 意义
*
* @param key
* @param options
* @return
* @since 1.4
*/
Cursor<V> scan(K key, ScanOptions options);
注意的坑
实际上这个方法存在很多需要注意的坑:
(1)cursor 要关闭,否则会内存泄漏
(2)cursor 不要重复关闭,或者会报错
(3)cursor 经测试,直接指定的 count 设置后,返回的结果其实是全部,所以需要自己额外处理
参考代码如下:
声明StringRedisTemplate
@Autowired
private StringRedisTemplate template;
- 1
- 2
核心代码
public void removeBigKey(String key, int scanCount, long intervalMills) throws CacheException {
final ScanOptions scanOptions = ScanOptions.scanOptions().count(scanCount).build();
//TRW 避免内存泄漏
try(Cursor<Map.Entry<Object,Object>> cursor =
template.opsForHash().scan(key, scanOptions)) {
if(ObjectUtil.isNotNull(cursor)) {
// 执行循环删除
List<String> fieldKeyList = new ArrayList<>();
while (cursor.hasNext()) {
String fieldKey = String.valueOf(cursor.next().getKey());
fieldKeyList.add(fieldKey);
if(fieldKeyList.size() >= scanCount) {
// 批量删除
Object[] fields = fieldKeyList.toArray();
template.opsForHash().delete(key, fields);
logger.info("[Big key] remove key: {}, fields size: {}",
key, fields.length);
// 清空列表,重置操作
fieldKeyList.clear();
// 沉睡等待,避免对 redis 压力太大
DateUtil.sleepInterval(intervalMills, TimeUnit.MILLISECONDS);
}
}
}
// 最后 fieldKeyList 中可能还有剩余,不过一般数量不大,直接删除速度不会很慢
// 执行 key 本身的删除
this.opsForValueDelete(key);
} catch (Exception e) {
// log.error();
}
}
这里我们使用 TRW 保证 cursor 被关闭,自己实现 scanCount 一次进行删除,避免一个一1一个删除网络交互较多。使用睡眠保证对 Redis 压力不要过大。
以上就是本期的全部内容,再回顾一下,本期带大家一起分析了 redis bigkey的定义、如何产生、危害以及如何发现线上是否存在bigkey、如何消除bigkey,最后详细分析了如何优雅删除bigkey,并给出了删除的解决方案,希望工作中遇到类似问题时能给你提供一个解决思路。
创作不易,如果对你有帮助,请记得三连哦,这对我是很大的鼓励~
</article>复制