https://www.zeekling.cn/articles/2022/04/10/1649579684900.html
由于Redis主线程是单线程的,所以会存在慢查询会导致redis请求延时,可以参考:
https://www.zeekling.cn/articles/2020/07/23/1595493094855.html
可以通过下面命令查找大value:
redis-cli -p 6379 -h 127.0.0.1 --bigkeys
redis-cli -p 6379 -h 127.0.0.1 --memkeys
RDB 和 AOF 的时候会存在 RDB 快照生成、AOF rewrite,耗费磁盘 IO 的过程。主进程 fork 子进程的时候,子进程是需要拷贝父进程的空间内存页表的,也是会耗费一定的时间的一般来说,如果父进程内存有 1 个 G 的数据,那么 fork 可能会耗费在 20ms 左右,如果是 10G~30G,那么就会耗费 20 * 10,甚至 20 * 30,也就是几百毫秒的时间。
info stats 中的 latest_fork_usec,可以看到最近一次 fork 的时长redis 单机 QPS 一般在几万,fork 可能一下子就会拖慢几万条操作的请求时长,从几毫秒变成 1 秒。
优化思路:fork 耗时跟 redis 主进程的内存有关系,一般控制 redis 的内存在 10GB 以内;否则 slave -> master 在全量复制等时候就可能会出现一些问题。
redis 将数据写入 AOF 缓冲区,单独开一个线程做 fsync 操作,每秒一次。但是 redis 主线程会检查两次 fsync 的时间,如果距离上次 fsync 时间超过了 2 秒,那么写请求就会阻塞everysec,最多丢失 2 秒的数据。一旦 fsync 超过 2 秒的延时,整个 redis 就被拖慢。
优化思路:优化硬盘写入速度,建议采用 SSD,不要用普通的机械硬盘,SSD 大幅度提升磁盘读写的速度。
主从复制可能会超时严重,这个时候需要良好的监控和报警机制。在 info replication 中,可以看到 master 和 slave 复制的 offset,做一个差值就可以看到对应的延迟量,如果延迟过多,那么就进行报警(可以写一个 shell 脚本去监控)
报错如下:
Increased maximum number of open files to 10032 (it was originally set to 1024).
句柄详解:http://www.freeoa.net/osuport/sysadmin/osfilehdnfd_1155.html
修改参数:
ulimit -n 10032 10032
报错提示:
WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
TCP backlog 队列设计初衷是为了缓存服务器无法立即处理的握手请求先回顾一下三次握手的过程:
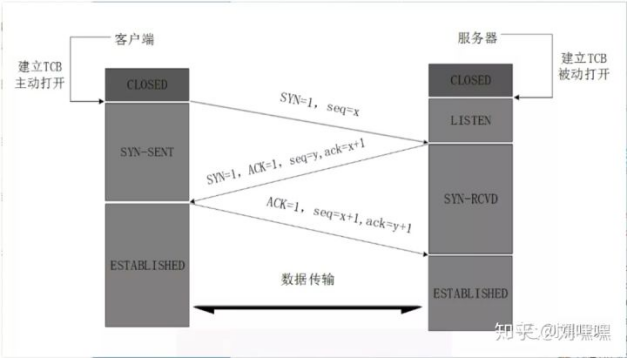
从服务器的视角来看,需要接受两个数据包(首个SYN,最后一个ACK)TCP backlog创建了两个队列来负责缓存已经收到的首个SYN和已经握手完成待应用层接收的连接负责缓存SYN的队列叫SYN QUEUE负责缓存已完成连接叫ACCEPT QUEUE.
举例子来说明:如果坐火车来说明的话,在春运时,火车站人满为患,进入火车站分为两步:
一、进入候车室入SYN QUEUE队列:SYN QUEUE队列的长度可以理解为候车室的大小专业术语叫做BACKLOG,当一个新的旅客到达时,安检员会根据候车室人数来决定是否允许旅客进入.
二、登上站台出SYN QUEUE队列,进入ACCEPT QUEUE队列:当站台可以容纳旅客的时候,检票员会将候车室的旅客按照先来后到的顺序,将旅客安置在站台,等候火车的到来,此时验证已经完成(你的车票已经被剪了),TCP已经完成的他的使命
三、挤进火车出ACCEPT QUEUE队列,当乘务员终于慢悠悠的打开车厢大门的时候,所有旅客有序进入火车中,握手完成
修改方法:
cat /proc/sys/net/core/somaxconn
echo 511 > /proc/sys/net/core/somaxconn
这个问题常见于低版本的redis,或者是client-output-buffer-limit replica没有使用默认值的时候
详细参见:https://www.zeekling.cn/articles/2022/02/27/1645957902937.html