CPU的多核架构和多CPU架构都会影响到Redis的性能
CPU架构
多核架构
- 一个CPU处理器一般有多个运行核心,如何在Linux查看物理CPU个数、核数、逻辑CPU个数
- 每个运行核心是一个物理核,每个物理核都可以运行应用程序
- 每个物理核都有私有的一级缓存L1(指令缓存、数据缓存)以及私有的二级缓存L2
- 物理核的私有缓存只能被当前物理核使用,访问L1、L2的延迟不超过10纳秒(访内存延迟一般在百纳秒级别)
- 数据和指令如果在L1和L2保存的话,就能提高Redis的性能,不过L1、L2一般大小只是KB级别
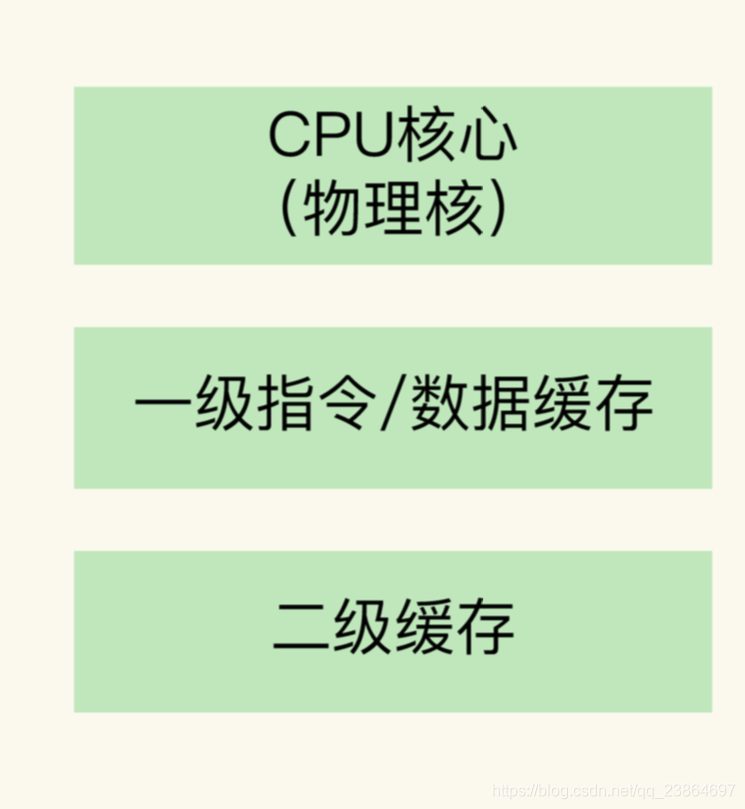
- 不同的物理核还会共用三级缓存L3,L3可以达到几MB和几十MB,相对较大
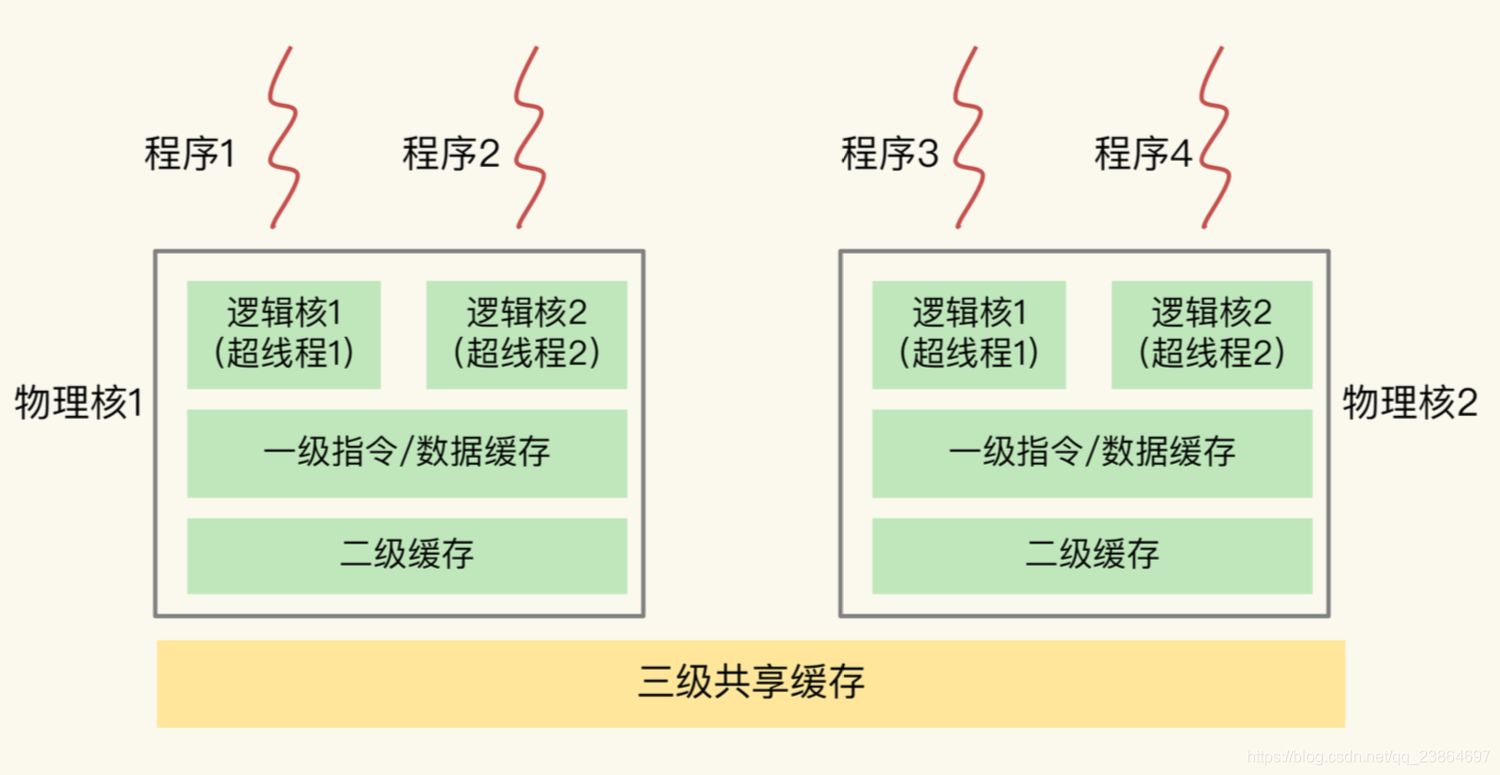
- 主流的CPU处理器中,每个物理核通常会运行两个超线程,也叫逻辑核
- 同一个物理核的逻辑核会共享L1、L2缓存
- 一个CPU处理器会有10-20多个物理核
物理核、逻辑核、L1、L2 关系
多CPU架构
一般为了提升服务器的处理能力,服务器上通常还会有多个CPU处理器,即多CPU Socket
- 每个处理器都有自己的物理核(包括L1、L2缓存)、L3缓存,以及连接的内存
- 不同处理器间通过总线连接
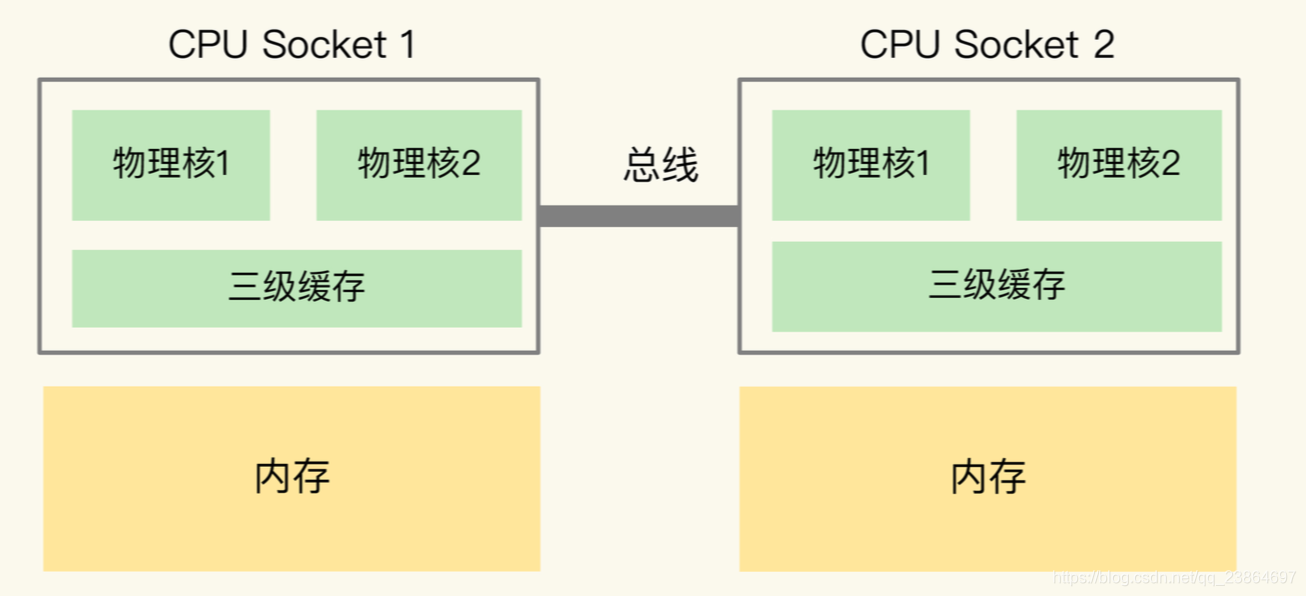
- 多CPU架构上,应用程序可以在不同的处理器上运行,比如:Redis可以在CPU Socket 1上运行一段时间,然后在CPU Socket2上运行一段时间
- 应用程序先在Socket 1上运行,且把数据保存内存,然后被调度到 Socket 2 上运行,应用程序再进行内存访问时,就需要访问之前 Socket 上连接的内存,这种访问是远端内存访问。
- 和访问 Socket 直接连接的内存相比,远端内存访问会增加应用程序的延迟。
非统一内存访问架构(Non-Uniform Memory Access,NUMA 架构):多CPU 架构下,应用程序访问所在 Socket 的本地内存和访问远端内存的延迟不一致
CPU架构的影响
- L1、L2缓存的指令和数据访问速度很快,充分利用L1、L2缓存,有效缩短应用程序的执行时间
- 在NUMA架构下,应用程序切换CPU Socket执行,可能会出现远端内存访问,增加执行时间
CPU多核对Redis的影响
在一个CPU核上运行时,应用程序需要记录自身使用的软硬件信息(栈指针、CPU核的寄存器等),这些信息是运行时信息,同时应用程序访问最频繁的信息还会缓存在L1、L2 上,提升速度。
多核CPU场景下,一旦应用程序需要在一个新的CPU核上运行,那么运行时信息就需要重新加载到新的CPU核上,新的CPU核的L1、L2缓存也需要重新加载数据和指令,这会导致程序的运行时间增加
多核 CPU 环境下对 Redis 性能进行调优的案例
需求
对 Redis 的 99% 尾延迟进行优化,要求 GET 尾延迟小于 300 微秒,PUT 尾延迟小于 500 微秒。
尾延迟:把所有请求的处理延迟从小到大排序,99% 的请求延迟小于的值就是 99% 尾延迟。比如有 1000 个请求, 假设按请求延迟从小到大排序后,第 991 个请求的延迟实测值是 1ms,而前 990 个请求 的延迟都小于 1ms,所以,这里的 99% 尾延迟就是 1ms。
条件
主要避免可能导致延迟增加的情况
- 使用 GET/PUT 复杂度为 O(1) 的 String 类型进行数据存取
- 关闭了 RDB 和 AOF
- Redis 实例中没有保存集合类型的其他数据,没有 bigkey 操作
结果
在一台有 24 个 CPU 核的服务器上运行 Redis 实例,GET 和 PUT 的 99% 尾延迟分别是 504 微秒和 1175 微秒,明显大于我们设定的目标
原因
检测 Redis 实例运行时的服务器 CPU 的状态指标值发现,CPU 的 context switch 次数比较多。
-
在 CPU 多核的环境中,一个线程先在一个 CPU 核上运行,之后又切换到另一个 CPU 核上运行,这时就会发生 context switch。
-
context switch 是指线程的上下文切换,这里的上下文就是线程的运行时信息。
-
context switch 发生后,Redis 主线程的运行时信息需要被重新加载到另一个 CPU 核 上,而且,此时,另一个 CPU 核上的 L1、L2 缓存中,并没有 Redis 实例之前运行时频繁访问的指令和数据,所以,这些指令和数据都需要重新从 L3 缓存,甚至是内存中加载。
-
这个重新加载的过程是需要花费一定时间的。而且,Redis 实例需要等待这个重新加载的过程完成后,才能开始处理请求,所以,这也会导致一些请求的处理时间增加。
-
如果在 CPU 多核场景下,Redis 实例被频繁调度到不同 CPU 核上运行的话,那么,对 Redis 实例的请求处理时间影响就更大了。
-
每调度一次,一些请求就会受到运行时信息、 指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求。
分析到这里,我们就知道了刚刚的例子中 99% 尾延迟的值始终降不下来的原因。
优化
所以要避免 Redis 总是在不同 CPU 核上来回调度执行。通过 taskset 命令 让一个程序(一个 Redis 实例)固定运行在一个 CPU 核上。
taskset -c 0 ./redis-server
- 1

在 CPU 多核的环境下,通过绑定 Redis 实例和 CPU 核,可以有效降低 Redis 的尾延迟,也能降低平均延迟、提升吞吐率, 进而提升Redis 性能。
CPU 的 NUMA 架构对 Redis 性能的影响
为了提升 Redis 的网络性能,可以把操作系统的网络中断处理程序和 CPU 核绑定。
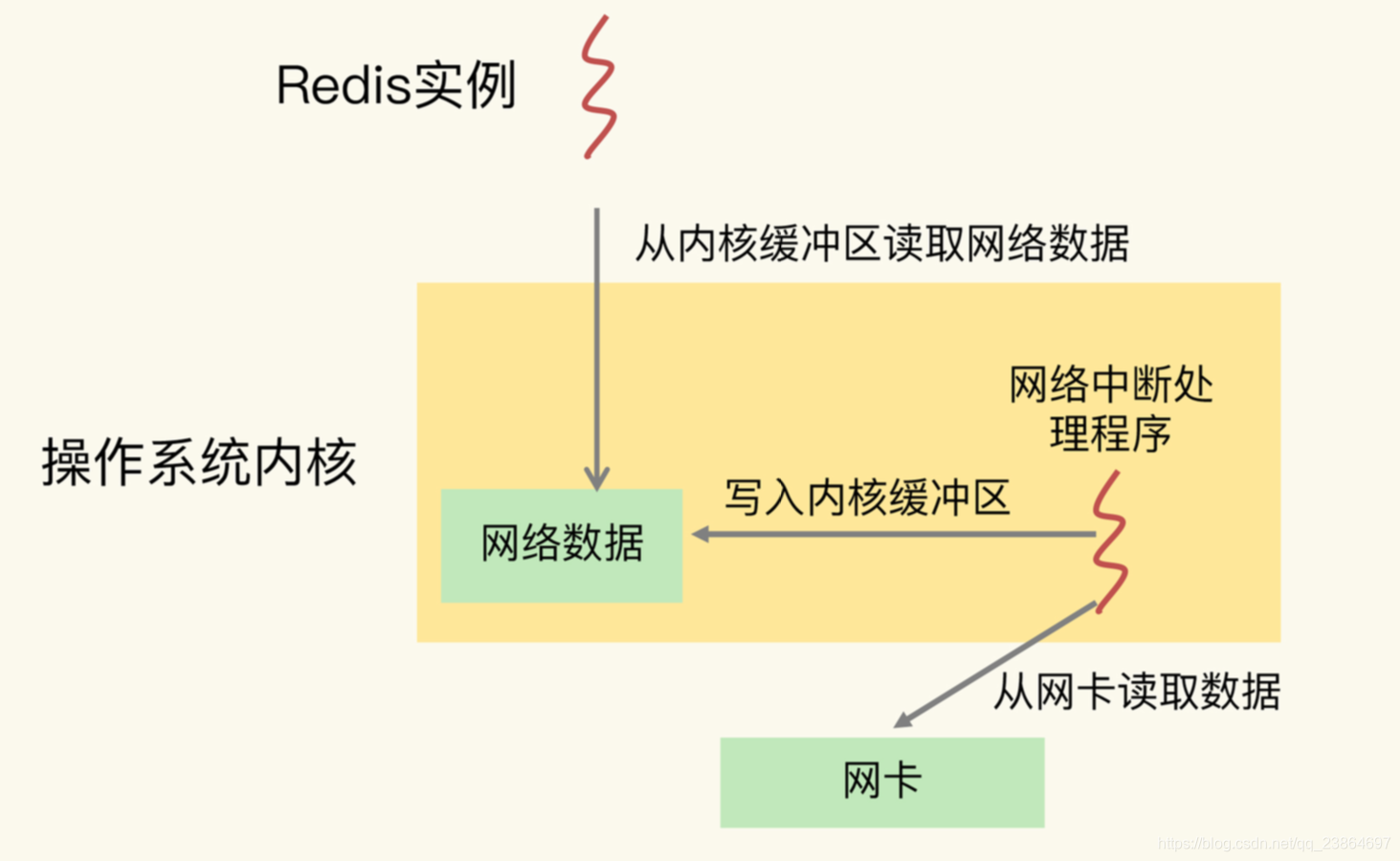
Redis 实例和网络中断程序的数据交互
- 网络中断处理程序从网卡硬件中读取数据,并把数据写入到操作系统内核维护的一块内存缓冲区。
- 内核会通过 epoll 机制触发事件,通知 Redis 实例,Redis 实例再把数据从内核的内存缓冲区拷贝到自己的内存空间,如下图所示:
在 CPU 的 NUMA 架构下,当网络中断处理程序、Redis 实例分别和 CPU核绑定 后,就会有一个潜在的风险:如果网络中断处理程序和 Redis 实例各自所绑的 CPU 核不同
在同一个 CPU Socket 上,那么,Redis 实例读取网络数据时,就需要跨 CPU Socket 访问内存,这个过程会花费较多时间。
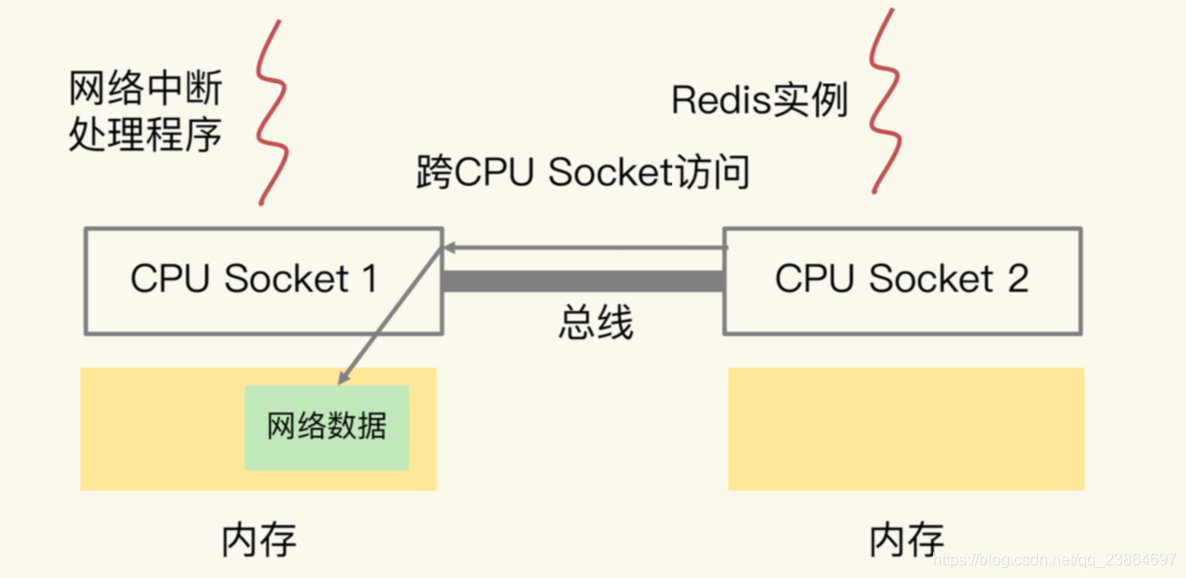
- 图中的网络中断处理程序被绑在了 CPU Socket 1 的某个核上,而 Redis 实例则被绑在了 CPU Socket 2 上。
- 网络中断处理程序读取到的网络数据,被保存在 CPU Socket 1 的本地内存中,当 Redis 实例要访问网络数据时,就需要 Socket 2 通过 总线把内存访问命令发送到 Socket 1 上,进行远程访问,时间开销比较大。
测试结果表明,和访问 CPU Socket 本地内存相比,跨 CPU Socket 的内存访问延迟增加了 18%,这自然会导致 Redis 处理请求的延迟增加。
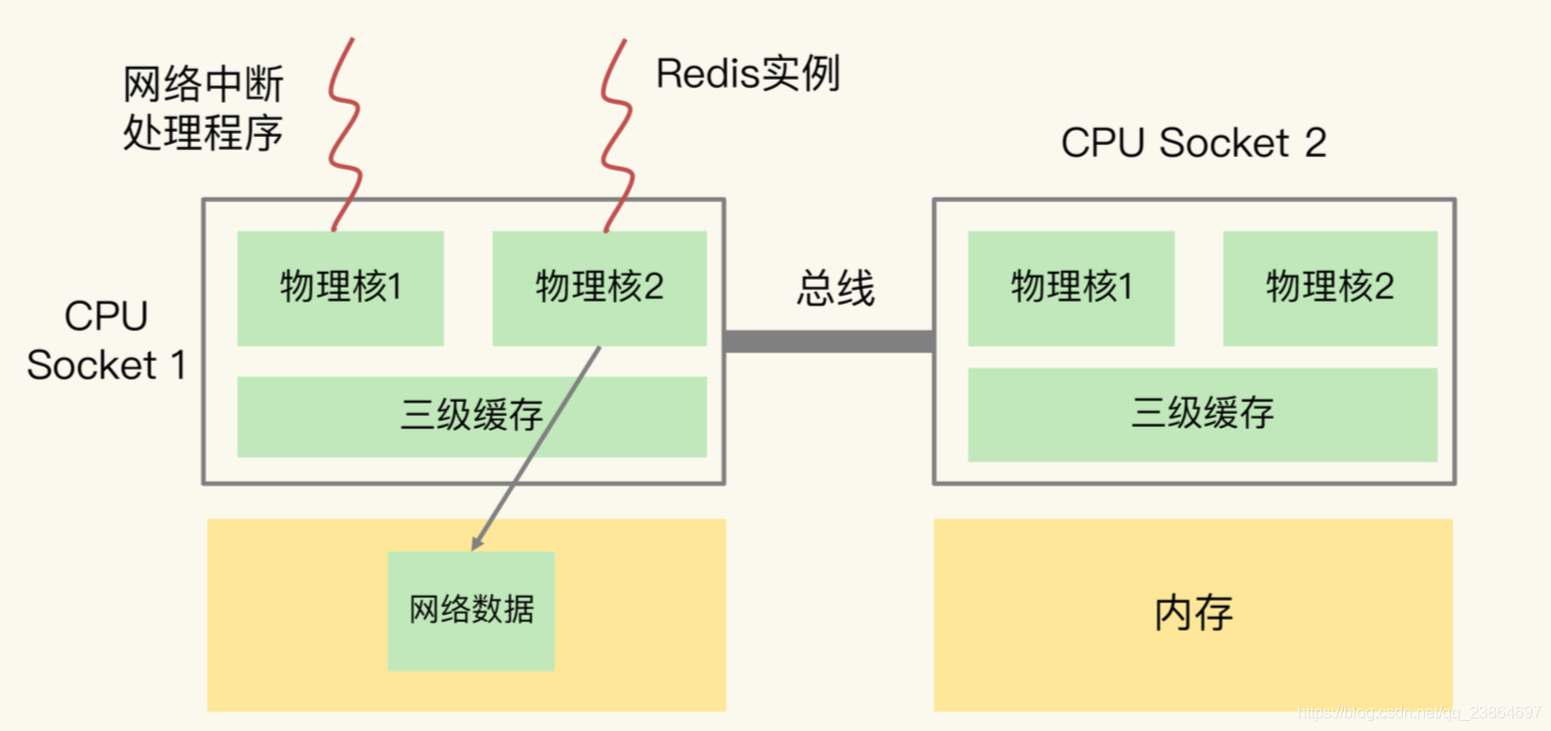
为了避免 Redis 跨 CPU Socket 访问网络数据,我们最好把网络中断程序和 Redis 实例绑在同一个 CPU Socket 上,这样一来,Redis 实例就可以直接从本地内存读取网络 数据了,如下图所示:
需要注意的是,在 CPU 的 NUMA 架构下,对 CPU 核的编号规则如下:
- 先给每个 CPU Socket 中每个物理核的第一个逻辑核依次编号
- 再给每个 CPU Socket 中的物理核的第二个逻辑核依次编号
假设有 2 个 CPU Socket,每个 Socket 上有 2 个物理核,每个物理核有 2 个逻辑核,总共 8个逻辑核。如下所示:
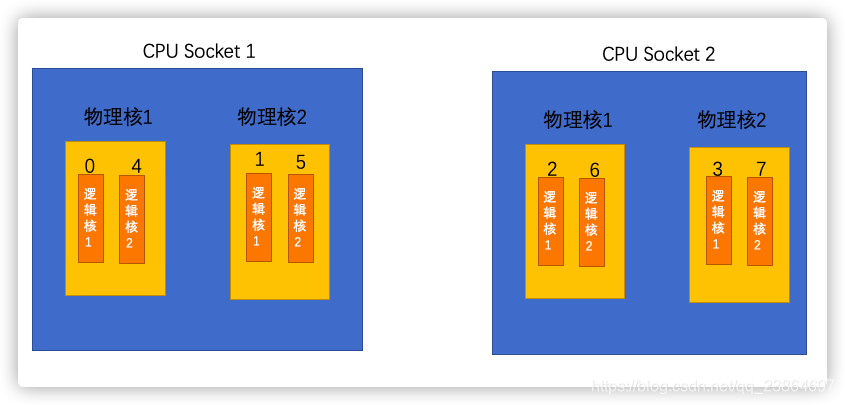
执行 lscpu 命令,查看到这些核的编号
lscpu
Architecture: x86_64
NUMA node0 CPU(s): 0-1,4-5
NUMA node1 CPU(s): 2-3,6-7
...
在绑核时,一定要注意 NUMA 架构下 CPU 核的编号方法,这样才不会绑错核,否则,网络中断程序和 Redis 实例就可能绑在了不同的 CPU Socket
- 在 CPU 多核的场景下,用 taskset 命令把 Redis 实例和一个核绑定,可以减少 Redis 实例在不同核上被来回调度执行的开销,避免较高的尾延迟;
- 在多 CPU 的 NUMA 架构下,如果你对网络中断程序做了绑核操作,建议你同时把 Redis 实例和网络中断程序绑在同一个 CPU Socket 的不同核上,这样可以避免 Redis 跨 Socket 访问内存中的网络数据的时间开销。
绑核存在的风险
Redis 除了主线程以外,还有用于 RDB 生成和 AOF 重写的子进程、Redis 的后台线程。
当我们把 Redis 实例绑到一个 CPU 逻辑核上时,就会导致子进程、后台线程和 Redis 主线程竞争 CPU 资源,一旦子进程或后台线程占用 CPU 时,主线程就会被阻塞,导致 Redis 请求延迟增加。
针对这种情况,我来给你介绍两种解决方案,分别是一个 Redis 实例对应绑一个物理核和优化 Redis 源码。
方案一:一个 Redis 实例对应绑一个物理核
在给 Redis 实例绑核时,我们不要把一个实例和一个逻辑核绑定,而要和一个物理核绑定,也就是说,把一个物理核的 2 个逻辑核都用上。
我们还是以 NUMA 架构为例,NUMA node0 的 CPU 核编号是 0 到 5、12 到 17。其中,编号 0 和 12、1 和 13、2 和 14 等都是表示一个物理核的 2 个逻辑核。所以,在绑核时,我们使用属于同一个物理核的 2 个逻辑核进行绑核操作。例如,我们执行 下面的命令,就把 Redis 实例绑定到了逻辑核 0 和 12 上,而这两个核正好都属于物理核 1。
taskset -c 0,12 ./redis-server
和只绑一个逻辑核相比,把 Redis 实例和物理核绑定,可以让主线程、子进程、后台线程 共享使用 2 个逻辑核,可以在一定程度上缓解 CPU 资源竞争。
但是,因为只用了 2 个逻 辑核,它们相互之间的 CPU 竞争仍然还会存在。如果你还想进一步减少 CPU 竞争,我再 给你介绍一种方案。
方案二:优化 Redis 源码
这个方案就是通过修改 Redis 源码,把子进程和后台线程绑到不同的 CPU 核上。
如果你对 Redis 的源码不太熟悉,也没关系,因为这是通过编程实现绑核的一个通用做 法。学会了这个方案,你可以在熟悉了源码之后把它用上,也可以应用在其他需要绑核的 场景中。
接下来,我先介绍一下通用的做法,然后,再具体说说可以把这个做法对应到 Redis 的哪部分源码中。
通过编程实现绑核时,要用到操作系统提供的 1 个数据结构 cpu_set_t 和 3 个函数 CPU_ZERO、CPU_SET 和 sched_setaffinity,我先来解释下它们。
- cpu_set_t 数据结构:是一个位图,每一位用来表示服务器上的一个 CPU 逻辑核。 CPU_ZERO 函数:以 cpu_set_t 结构的位图为输入参数,把位图中所有的位设置为 0。
- CPU_SET 函数:以 CPU 逻辑核编号和 cpu_set_t 位图为参数,把位图中和输入的逻辑 核编号对应的位设置为 1。
- sched_setaffinity 函数:以进程 / 线程 ID 号和 cpu_set_t 为参数,检查 cpu_set_t 中 哪一位为 1,就把输入的 ID 号所代表的进程 / 线程绑在对应的逻辑核上。
那么,怎么在编程时把这三个函数结合起来实现绑核呢?很简单,我们分四步走就行。
- 第一步:创建一个 cpu_set_t 结构的位图变量;
- 第二步:使用 CPU_ZERO 函数,把 cpu_set_t 结构的位图所有的位都设置为 0;
- 第三步:根据要绑定的逻辑核编号,使用 CPU_SET 函数,把 cpu_set_t 结构的位图相 应位设置为 1;
- 第四步:使用 sched_setaffinity 函数,把程序绑定在 cpu_set_t 结构位图中为 1 的逻 辑核上。
下面,我就具体介绍下,分别把后台线程、子进程绑到不同的核上的做法。
先说后台线程。为了让你更好地理解编程实现绑核,你可以看下这段示例代码,它实现了
为线程绑核的操作:
//线程函数
void worker(int bind_cpu){
cpu_set_t cpuset; //创建位图变量
CPU_ZERO(&cpu_set); //位图变量所有位设置0
CPU_SET(bind_cpu, &cpuset); //根据输入的bind_cpu编号,把位图对应为设置为1
sched_setaffinity(0, sizeof(cpuset), &cpuset); //把程序绑定在cpu_set_t结构位图
}
int main(){
pthread_t pthread1
//把创建的pthread1绑在编号为3的逻辑核上
pthread_create(&pthread1, NULL, (void *)worker, 3);
}
对于 Redis 来说,它是在 bio.c 文件中的 bioProcessBackgroundJobs 函数中创建了后台 线程。bioProcessBackgroundJobs 函数类似于刚刚的例子中的 worker 函数,在这个函 数中实现绑核四步操作,就可以把后台线程绑到和主线程不同的核上了。
和给线程绑核类似,当我们使用 fork 创建子进程时,也可以把刚刚说的四步操作实现在 fork 后的子进程代码中,示例代码如下:
int main(){
//用fork创建一个子进程
pid_t p = fork();
if(p < 0){
}
//子进程代码部分
else if(!p){
cpu_set_t cpuset; //创建位图变量
CPU_ZERO(&cpu_set); //位图变量所有位设置0
CPU_SET(3, &cpuset); //把位图的第3位设置为1
sched_setaffinity(0, sizeof(cpuset), &cpuset); //把程序绑定在3号逻辑核
//实际子进程工作
exit(0);
}
}
对于 Redis 来说,生成 RDB 和 AOF 日志重写的子进程分别是下面两个文件的函数中实现 的。
rdb.c 文件:rdbSaveBackground 函数;
aof.c 文件:rewriteAppendOnlyFileBackground 函数。
这两个函数中都调用了 fork 创建子进程,所以,我们可以在子进程代码部分加上绑核的四 步操作。
使用源码优化方案,我们既可以实现 Redis 实例绑核,避免切换核带来的性能影响,还可 以让子进程、后台线程和主线程不在同一个核上运行,避免了它们之间的 CPU 资源竞争。 相比使用 taskset 绑核来说,这个方案可以进一步降低绑核的风险。
问题
在一台有 2 个 CPU Socket(每个 Socket 8 个物理核)的服务器上,我们部署了有 8 个 实例的 Redis 切片集群(8 个实例都为主节点,没有主备关系),现在有两个方案:
- 在同一个 CPU Socket 上运行 8 个实例,并和 8 个 CPU 核绑定;
- 在 2 个 CPU Socket 上各运行 4 个实例,并和相应 Socket 上的核绑定。
我更倾向于的方案是:在两个CPU Socket上各运行4个实例,并和相应Socket上的核绑定。这么做的原因主要从L3 Cache的命中率、内存利用率、避免使用到Swap这三个方面考虑:
1、由于CPU Socket1和2分别有自己的L3 Cache,如果把所有实例都绑定在同一个CPU Socket上,相当于这些实例共用这一个L3 Cache,另一个CPU Socket的L3 Cache浪费了。这些实例共用一个L3 Cache,会导致Cache中的数据频繁被替换,访问命中率下降,之后只能从内存中读取数据,这会增加访问的延迟。而8个实例分别绑定CPU Socket,可以充分使用2个L3 Cache,提高L3 Cache的命中率,减少从内存读取数据的开销,从而降低延迟。
2、如果这些实例都绑定在一个CPU Socket,由于采用NUMA架构的原因,所有实例会优先使用这一个节点的内存,当这个节点内存不足时,再经过总线去申请另一个CPU Socket下的内存,此时也会增加延迟。而8个实例分别使用2个CPU Socket,各自在访问内存时都是就近访问,延迟最低。
3、如果这些实例都绑定在一个CPU Socket,还有一个比较大的风险是:用到Swap的概率将会大大提高。如果这个CPU Socket对应的内存不够了,也可能不会去另一个节点申请内存(操作系统可以配置内存回收策略和Swap使用倾向:本节点回收内存/其他节点申请内存/内存数据换到Swap的倾向程度),而操作系统可能会把这个节点的一部分内存数据换到Swap上从而释放出内存给进程使用(如果没开启Swap可会导致直接OOM)。因为Redis要求性能非常高,如果从Swap中读取数据,此时Redis的性能就会急剧下降,延迟变大。所以8个实例分别绑定CPU Socket,既可以充分使用2个节点的内存,提高内存使用率,而且触发使用Swap的风险也会降低。
其实我们可以查一下,在NUMA架构下,也经常发生某一个节点内存不够,但其他节点内存充足的情况下,依旧使用到了Swap,进而导致软件性能急剧下降的例子。所以在运维层面,我们也需要关注NUMA架构下的内存使用情况(多个内存节点使用可能不均衡),并合理配置系统参数(内存回收策略/Swap使用倾向),尽量去避免使用到Swap。