一、Linux内核协议栈性能瓶颈
在x86体系结构中,接收数据包的传统方式是CPU中断方式,即网卡驱动接收到数据包后通过中断通知CPU处理,然后由CPU拷贝数据并交给内核协议栈。在数据量大时,CPU中断方式会产生大量 CPU中断,导致CPU负载较高。
(1)硬件中断导致的线程、进程切换
硬件中断请求会抢占优先级较低的软件中断,频繁到达的硬件中断和软中断意味着频繁的线程切换,随着而来的就是运行模式切换、上下文切换、线程调度器负载、高速缓存缺失(Cache Missing)、多核缓存共享数据同步、竞争锁等一系列的CPU性能损耗。
(2)内存拷贝
网卡驱动位于内核态,网络驱动接收到数据包后会经过内核协议栈的处理,然后再拷贝到用户态的应用层缓冲区.从内核态到用户态的数据拷贝是耗时操作,数据拷贝的时间会占数据包处理流程时间的50%以上。
(3)多处理器平台CPU漂移
一个数据包可能中断在CPU0,内核态处理在CPU1,用户态处理在 CPU2,跨多个物理核(Core)处理会导致大量的 CPU Cache命中缺失,造成局部性失效。对于NUMA架构,还会出现跨NUMA节点的内存访问,极大地影响CPU性能。
(4)缓存失效
传统服务器大多采用页式虚拟存储器,内存页默认为4K的小页,在存储空间较大的处理机上会存在大量的页面映射项。同时由于TLB缓存空间有限,最终导致TLB快表的映射项频繁变更,产生大量的TLB命中缺失。
二、Kernel Bypass简介
1、Kernel Bypass简介
Kernel Bypass(内核旁路)是绕过Linux内核(TCPIP协议栈)的技术,不使用Linux内核子系统的功能,采用自己实现的相同功能的代码来处理,从用户空间直接访问和控制设备内存,避免数据从设备拷贝到内核,再从内核拷贝到用户空间。
Kernel Bypass目前主流实现方案如DPDK、SolarFlare。
2、Kernel Bypass优点
Kernel Bypass技术本身为高性能低延迟而设计,因此最大优点是高性能、低延迟。
3、Kernel Bypass缺点
Kernel Bypass技术的缺点如下:
(1)改变了现有操作系统的工作方式,很难与现有操作系统集成。
(2)由于网络数据不经过内核网络协议栈,相关网络应用程序需要重新实现由操作系统提供的功能。
(3)由于操作系统没有相关网络硬件的控制权,操作系统提供的网络管理部署工具不再可用。
(4)破坏了操作系统内核提供的安全性。在容器场景中,资源的抽象和隔离主要由操作系统内核提供。
(5)需要消耗1个或者多个CPU核来专门处理网络包。
三、DPDK
1、DPDK简介
DPDK(Data Plane Development Kit)是Intel提供的数据平面开发工具集,为Intel Architecture处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持,专注于网络应用中数据包的高性能处理。
DPDK应用程序是运行在用户空间上利用自身提供的数据平面库来收发数据包,绕过Linux内核协议栈对数据包处理过程。Linux内核将DPDK应用程序看作是一个普通的用户态进程,包括编译、链接、加载方式和普通程序一样。DPDK程序启动后只能有一个主线程,然后创建一些子线程并绑定到指定CPU核心上运行。
DPDK(Data Plane Development Kit)是一个开源的、快速处理数据平面数据包转发的开发平台及接口,支持X86、ARM、Power PC硬件平台。
Intel在2010年启动了对DPDK技术的开源化进程,2010年9月通过BSD开源许可协议正式发布源代码软件包,并于2014年4月在www.dpdk.org上正式成立了独立的开源社区平台,为开发者提供支持。
DPDK提供了一个用户态的高效数据包处理库,通过环境抽象层、内核旁路协议栈、轮询模式的报文无中断收发、优化内存/缓冲区/队列管理、基于网卡多队列和流识别的负载均衡等多项技术,实现了在 x86处理器架构下的高性能报文转发能力,用户可以在Linux用户态开发各类高速转发应用,也适合与各类商业化的数据平面加速解决方案进行集成。
DPDK重载了网卡驱动,将数据包的控制平面和数据平面分离,驱动在收到数据包后不再硬中断通知CPU,而是让数据包通过内核旁路协议栈绕过Linux内核协议栈,并通过零拷贝技术存入内存,应用层的程序可以通过DPDK提供的接口读取数据包。
DPDK数据包处理方式节省了CPU中断时间、内存拷贝时间,并向应用层提供了简单易行且高效的数据包处理接口函数,使得网络应用的开发更加方便。但由于需要重载网卡驱动,因此DPDK目前只能用在部分采用Intel网络处理芯片的网卡设备中。DPDK 支持的网卡列表: https://core.dpdk.org/supported/,主流使用 Intel 82599(光口)和 Intel x540(电口)。DPDK 可以将数据包处理性能最多提高十倍。在单个英特尔至强处理器上获得超过 80 Mbps 的吞吐量,在双处理器配置中则可将该其提高一倍。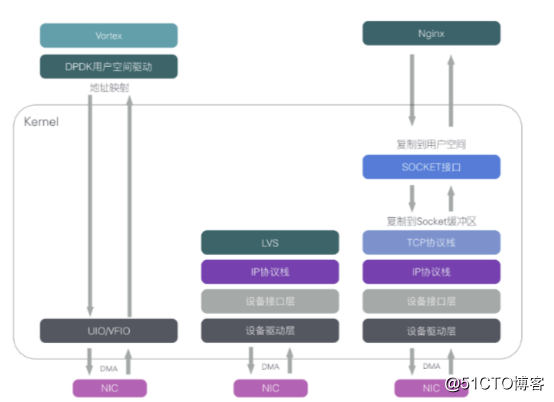
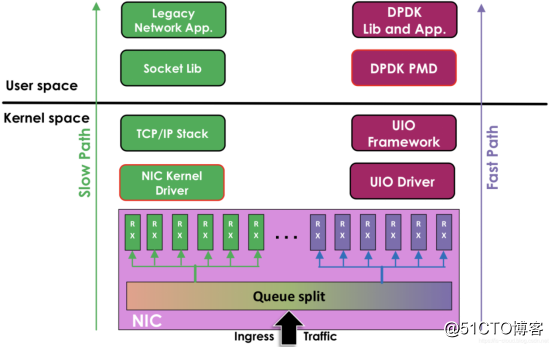
2、DPDK原理
3、DPDK架构
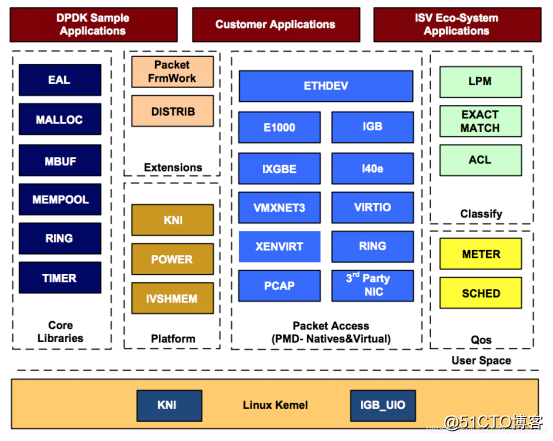
在Linux Kernel中,DPDK有KNI与IGB_UIO两个模块,在用户态由多个DPDK库组成,主要包括核心部件库(Core Libraries)、平台相关模块(Platform)、网卡轮询模式驱动模块(PMD-Natives&Virtual)、QoS库、报文转发分类算法(Classify)等,用户可以使用DPDK库开发应用程序。
4、UIO
传统的收发数据包方式,首先网卡通过中断方式通知Linux内核协议栈对数据包进行处理,内核协议栈先会对数据包进行合法性进行必要的校验,然后判断数据包目标是否为本机的Socket,满足条件则会将数据包拷贝一份向上递交到用户态Socket来处理。
为了使得网卡驱动(PMD Driver)运行在用户态,实现内核旁路,Linux提供了UIO(User Space IO)机制。使用UIO可以通过 read感知中断,通过 mmap实现和网卡设备的通讯。
UIO是用户态的一种IO技术,是DPDK能够绕过内核协议栈,提供用户态PMD Driver支持的基础。DPDK架构在Linux内核中安装了IGB_UIO(igb_uio.ko和kni.ko.IGB_UIO)模块,以此借助UIO 技术来截获中断,并重设中断回调行为,从而绕过内核协议栈后续处理流程,并且IGB_UIO会在内核初始化的过程中将网卡硬件寄存器映射到用户态。
UIO实现机制是对用户态暴露文件接口。当注册一个UIO设备uioX 时,就会出现系统文件/dev/uioX,对UIO设备文件的读写就是对网卡设备内存的读写。
5、DPDK特点
(1)轮询:在包处理时避免中断上下文切换的开销,
(2)用户态驱动:规避不必要的内存拷贝和系统调用,便于快速迭代优化
(3)亲和性与独占:特定任务可以被指定只在某个核上工作,避免线程在不同核间频繁切换,保证更多的cache命中
(4)降低访存开销:利用内存大页HUGEPAGE降低TLB miss,利用内存多通道交错访问提高内存访问有效带宽
(5)软件调优:cache行对齐,预取数据,多元数据批量操作
四、XDP
1、XDP简介
XDP(eXpress Data Path)不是一种Kernel Bypass实现方案,与Kernel Bypass实现方式完全相反,是一种依赖于eBPF的内核代码注入技术,能够在网络包到达内核协议栈前对网络包进行过滤或者处理。XDP将网络包处理流程放到Linux内核中位于网络协议栈前的位置,在处理网络数据包时,不用经过网络协议栈的复杂流程,同时又保留了操作系统控制网络硬件的能力。
XDP是近年发展起来的一种SDN技术,目前已经完全集成到Linux Kernel中,并且还在持续的演进。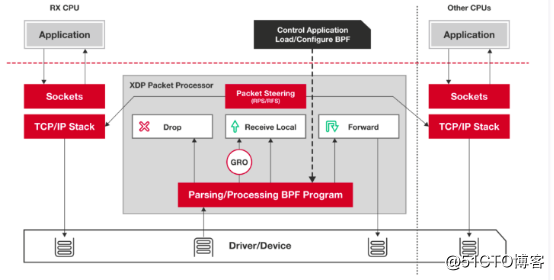
2、XDP网络数据处理流程
Linux内核网络栈根据iptables防火墙设置的规则决定对数据包的处理(丢弃、转发),XDP可以在数据包刚到达网卡就丢弃数据包,所以能够用来处理高速数据流量。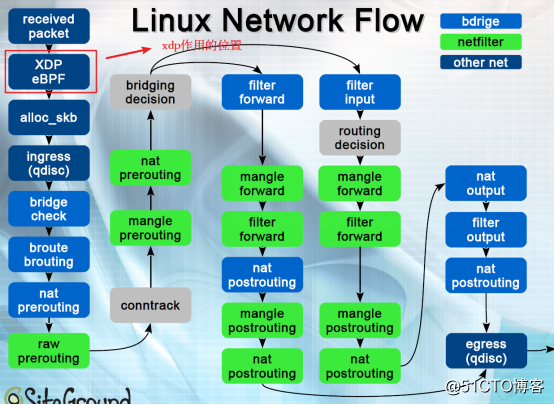
3、XDP组成
当一个数据包到达网卡,在内核网络栈分配缓冲区将数据包内容存到sk_buff结构体前,XDP程序执行,读取由用户态的控制平面写入到BPF maps的数据包处理规则,对数据包执行相应的操作,比如可以直接丢弃数据包,或者将数据包发回当前网卡,或者将数据包转发到其它网卡或者上层的虚拟网卡(进而将数据包直接转发给上层的容器或者虚拟机),或者将数据包传递给内核协议栈,再经过协议栈的逐层解析发送给用户程序,还可以直接将数据包通过AF_XDP特殊的socket直接转发给上层应用程序。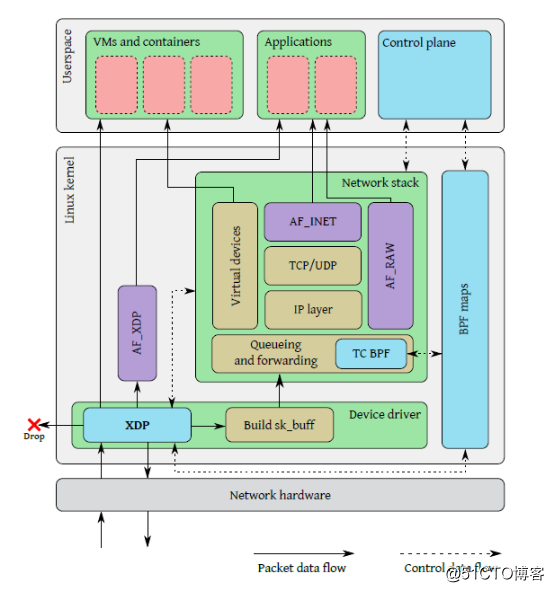
XDP驱动钩子:网卡驱动中XDP程序的一个挂载点,每当网卡接收到一个数据包就会执行XDP程序;XDP程序可以对数据包进行逐层解析、按规则进行过滤,或者对数据包进行封装或者解封装,修改字段对数据包进行转发等;
eBPF虚拟机:XDP程序是由用户编写用受限制的C语言编写的,然后通过clang前端编译生成BPF字节码,字节码加载到内核之后运行在eBPF虚拟机上,虚拟机通过即时编译将XDP字节码编译成底层二进制指令;eBPF虚拟机支持XDP程序的动态加载和卸载;
BPF maps(BPF映射):存储键值对,作为用户态程序和内核态XDP程序、内核态XDP程序之间的通信媒介,类似于进程间通信的共享内存访问;用户态程序可以在BPF映射中预定义规则,XDP程序匹配映射中的规则对数据包进行过滤等;XDP程序将数据包统计信息存入BPF映射,用户态程序可访问BPF映射获取数据包统计信息;
eBPF程序校验器:BPF程序校验器在将XDP字节码加载到内核前对字节码进行安全检查,比如判断是否有循环,程序长度是否超过限制,程序内存访问是否越界,程序是否包含不可达的指令。在程序加载到内核前静态的分析代码以确保代码会crash或者损坏运行的内核。
4、XDP优点
XDP优点如下:
(1)XDP与Linux内核网络协议栈集成,内核仍然具有对网络硬件的控制能力,保留了内核提供的安全性,并且现有网络配置管理工具可以直接使用。
(2)任何具备Linux驱动的网卡都可以使用XDP,只需要网卡驱动更新添加XDP的执行hook点。DPDK需要特殊硬件支持。
(3)XDP可以选择性使用内核网络协议栈的功能,如路由表、TCP stack。这样可以在加速关键网络数据的同时保留现有的配置接口
(4)与基于内核网络协议栈的程序交互时,不需要重新将网络数据包从用户空间注入到内核空间。
(5)对于主机上运行的应用程序是透明的。
(6)支持服务不中断的前提下动态的重新编程,可以在网络不中断前提下热升级XDP程序。
(7)不需要专属的CPU核来做包处理,低流量对应的就是低CPU使用率,相应的更加高效,且节省电力。
5、XDP使用场景
XDP的使用场景包括如下:
(1)DDoS防御
(2)防火墙
(3)基于XDP_TX的负载均衡
(4)网络统计
(5)复杂网络采样
(6)高速交易平台
五、Solarflare
1、Solarflare简介
Solarflare网卡支持OpenOnload网卡加速器,其Kernel Bypass实现方案如下:在用户空间实现网络协议栈,并使用LD_PRELOAD覆盖目标程序的网络系统调用,而在底层访问网卡时依靠EF_VI库。
Solarflare网卡提供3个层级的kernel bypass实现方案,onload不需要用户改代码,安装网卡驱动后,程序使用onload库启动就可以,简单易用;tcpdirect速度上比onload快一点,但需要用户修改代码;ef_vi会跳过所有协议栈,直接读取网卡的某条特定的RX队列。
Solarflare产品凭借高性能低延迟特点已经占领股票和期货高频交易硬件市场90%的份额,Solarflare X2522 plus低延迟光纤网卡广泛用于金融证券期货高频交易,价格在20000RMB以上。目前Solarflare最新产品为X2552、X2541、X2562超低延迟网卡。
2、onload
onload是Solarflare最经典的kernel bypass网络协议栈,属于透明kernel bypass,提供了兼容socket网络编程的接口,用户不需要修改自己的代码,只需在程序启动前preload libonload.so即可使用。
3、ef_vi
ef_vi是一个level 2的底层API,可以收发原始Ethernet帧,但没有提供上层协议的支持。ef_vi最大的特点是zero-copy:要求用户预先分配一些recv buffer提供给ef_vi使用,网卡收到包后会直接写入buffer,用户通过eventq poll接口获得已填充数据的buffer id即可开始处理接收数据,处理完后再把buffer交还ef_vi循环使用。
ef_vi API使用起来比较复杂,且缺乏上层协议支持,但能提供最好的性能。
4、tcpdirect
tcpdirect基于ef_vi实现了上层网络协议栈,提供了类似socket的API:zocket,能让用户读写tcp/udp的payload数据,同时也继承了ef_vi zero-copy的特性。tcpdirect要求使用huge pages。