几年前一个客户的Oracle数据库经常HANG,老白帮他分析了一下,结论是存储老化,性能不足以支撑现有业务了。正好用户手头有个华为S5600T正好从核心系统中换下来放着没用,就把这个存储换上去了。换了新存储后,系统总体确实有所改善。数据库不会动不动就HANG住,不会出现系统HANG的问题了,但是还是觉得比较慢。出问题时候的AWR报告的片段如下:
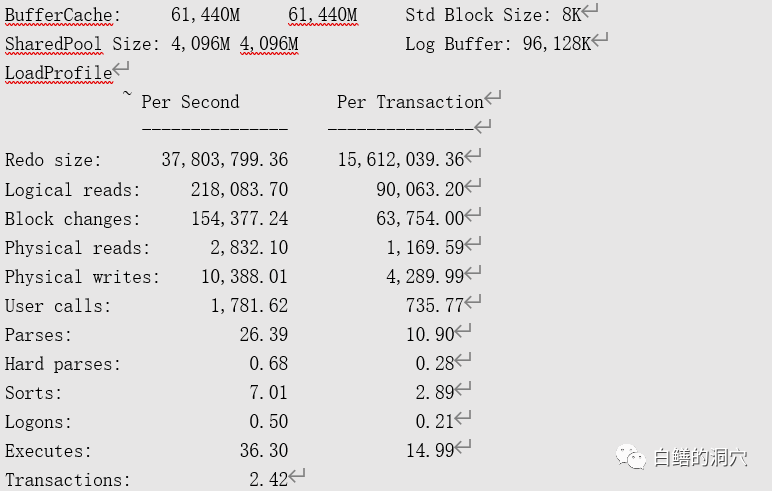
从负载上看,每秒的REDO SIZE 37M,还是很高的。逻辑读的数量不大,不过BLOCK CHANGES很高,物理写高达1万+,超过80M/秒,系统的写压力比较大。从这个系统上看,应该是存在大批量的数据写入操作。接下来看看命中率的情况:

命中率情况还是不错的,因为主要是写操作,因此DB CACHE的命中率也不高,从上面的LOAD PROFILE看,物理读实际上也不大,每秒不到20M。再来看看TOP EVENT:
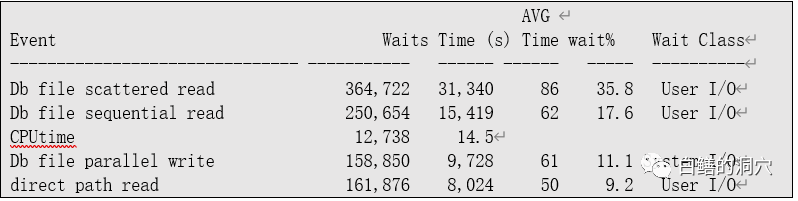
可以看出,读写操作的平均延时超过50毫秒,肯定是存在性能问题的。从AWR数据上看,很明显,本系统是一个写IO很大的系统,每秒REDO的量达到了 36M/秒以上,每秒的物理写超过1万,这在普通的Oracle数据库系统中是比较少见的。从主要等待事件上看,也主要集中在IO上,从WAIT CLASS分类看,USER I/O也排在第一位,平均等待时间为59MS,SYSTEMI/O的平均等待也达到40MS,从这些指标上看IO是明显存在问题的。
既然IO存在明显的问题,那么我们就需要马上采集下操作系统IO的情况:
|
APE:/ # sar -d 3 2AIX APE 3 5 00CD36454C00 System configuration: lcpu=32 drives=111 mode=Capped 14:52:11 device %busy avque r+w/s Kbs/s avwait avserv 14:52:14 hdisk44 49 0.0 85 4096 10.0 6.0 hdisk43 65 0.1 138 7329 15.2 4.6 hdisk39 99 0.2 149 8589 40.6 6.7 hdisk38 30 0.8 303 3081 86.5 1.0 hdisk40 99 0.5 210 11196 60.9 4.7 hdisk42 99 0.9 346 13998 76.2 2.9 |
从上述指标上看,IOPS和吞吐量都不算太高,但是平均响应时间(avwait+avserv)确实很高,达到几十毫秒。这和AWR报告看到的数据是吻合的。于是找存储工程师参与分析。存储管理员认为存储没问题,负载很轻,从存储监控上看到的响应时间也很正常,在几个毫秒。这恐怕是DBA经常遇到的问题了,到底是存储工程师在推诿呢还是实际情况就是这样的,存储没问题,但是OS层面表现出慢呢?对于sar的数据,很多DBA总是先去看busy%这个指标,一看很多盘都已经是99% busy了,那可不得了了,存储出现瓶颈了。实际上对于现在的系统而言,busy%这个指标的可参考性并不大,后面的指标更能看出问题。Avque指的是平均队列的长度,有多少IO在队列中等待。再后面一列是IOPS,再后面是吞吐量,最后两列一列是平均等待时间,也就是在队列中等待IO的时间,和平均服务时间,也就是IO请求发出后,从后端返回的时间。我们通过这些指标实际上是可以区分IO等待是在前端系统端还是后端存储端的。AVSERV是存储到OS之间的端到端服务时间,从上面的指标上看,确实也不大,只有几个毫秒,所以说存储工程师的说法可能是对的,存储端并不慢。而avwait是IO在前端的等待时间,这个指标是相当高的,这说明很可能IO并没有下到存储上,而是在前端OS层面出现了等待。对于AIX系统而言,这个等待很大可能是和QUEUE_DEPTH参数设置不当有关的。为了进一步确认是否QUEUE_DEPTH不足引起了问题,在AIX系统上,可以用iostat–D去分析:
|
APE:/ # iostat -D System configuration: lcpu=32 drives=111 paths=4 vdisks=0 hdisk44 xfer: %tm_act bps tps bread bwrtn 21.9 4.1M 160.3 2.1M 2.0M read: rps avgserv minserv maxserv timeouts fails 28.8 5.6 0.1 1.2S 0 0 write: wps avgserv minserv maxserv timeouts fails 131.5 0.4 0.2 1.7S 0 0 queue: avgtime mintime maxtime avgwqsz avgsqsz sqfull 68.1 0.0 9.2S 12.0 0.0 160.3
|
AIX系统的iostat -D是一个十分强大的IO性能分析工具。我们从read这行开始看,平均每秒28.8次读,平均存储上返回的服务时间是5.6毫秒,最小是0.1毫秒,最大1.2秒,没有超时和错误(如果这两列有值,就要十分关注了)。再来看write,平均每秒131.5,平均存储的服务响应时间是0.4毫秒,这个值为什么比读的平均值小这么多呢?大家印象里的写的成本要远大于读。实际上这是存储系统的特点,因为读数据的时候有可能命中在CACHE里,也有可能需要从物理磁盘上去读,所以根据命中率不同以及物理盘的性能不同,肯定都会比直接从CACHE中读要慢一些,而写入操作,只要写缓存没有满,那么些IO的延时基本上等同于CACHE的写IO延时,这是十分快的。大家可以关注最后一行的指标,是IO在队列里的延时情况,平均是68.1毫秒!!!最小是0毫秒,这个应该是不需要排队直接从后端存储获取数据或者写入数据了,最大高达9.2秒,平均队列的深度12。大家关注下最后一个指标:sqfull的指标值,这是设备的缓冲队列满的次数(累计值),如果这个指标大于0,说明QUEUE_DEPTH参数的设置是不足的,出现了大量IO队列满的情况。从上述数据我们可以比较肯定队列等待可能是问题的主要原因了。下面我们来看看实际上HDISK的设置是什么样的:
|
APE:/ # lsattr -El hdisk44 clr_q no Device CLEARS its Queue on error True location Location Label True lun_id 0x4000000000000 Logical Unit Number ID False max_transfer 0x40000 Maximum TRANSFER Size True node_name 0x2100f84abf591cca FC Node Name False pvid 00cd36456aecb23e0000000000000000 Physical volume identifier False q_err yes Use QERR bit True q_type simple Queuing TYPE True queue_depth 1 Queue DEPTH True reassign_to 120 REASSIGN time out value True rw_timeout 30 READ/WRITE time out value True scsi_id 0xe0 SCSI ID False start_timeout 60 START unit time out valueTrue ww_name 0x2008f84abf591cca FC World Wide Name False |
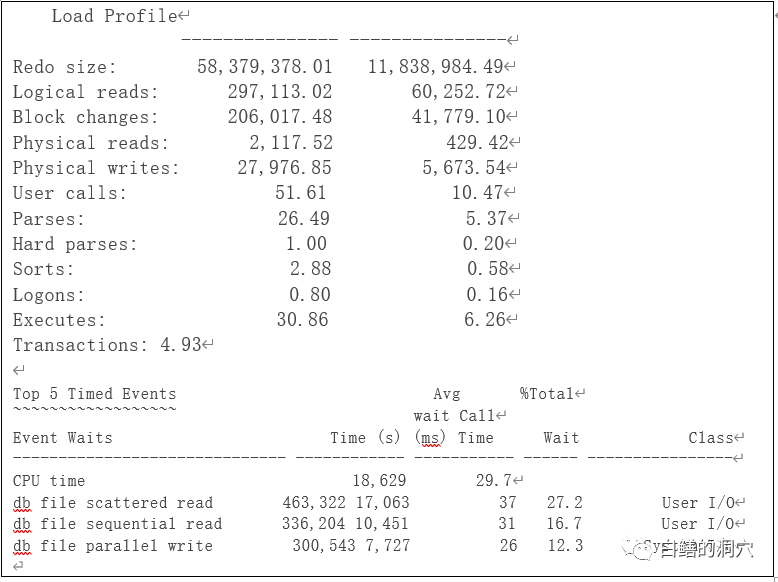
看上去IO的性能是不是好了很多,REDO量也上去了,从每秒37M提高到57M左右。其实这时候IO还是有问题,现在压力下放到存储上,存储上看到明显的性能问题了。下面可以进一步优化,比如QUEUE DEPTH是不是还可以再加大。另外数据能否存放到更多的盘上。给客户的建议是再多分配2-3个RAID 组,把部分数据分散到多个RAID 组上。实际上队列深度以前一直是困扰小型机上IO性能的一个问题。这个参数设置太小会有排队问题,设置太大也并不一定好,如果你的后端存储能力不足,而设置的队列深度太大,最终整体IO性能也不见得好。LINUX上,队列深度缺省是128,通过LINUX的调度策略来智能化调度,因此这个问题在LINUX上不多见。不过如果后端存储是高端的全闪存阵列,那么128的队列深度还是不能发挥出后端存储的能力的,这时候我们还是需要调整队列深度的。