概述
以前IB特有的技术比如RDMA,协议卸载等,现在已经也可以在以太网上用上了,此类差异并不本质,因此要比就要从二层及以下进行比较,就可以清楚看到这两种网络的差异。
对比
Ethernet
以太网设计初衷是,多个不同的系统,如何让他们之间流畅的进行信息交换?这是一种典型的network,它的设计中优先考虑的是兼容性与分布式。
infiniband
InfiniBand,作为标准制定的初衷是为了解决高性能计算场景中突破集群中数据传输瓶颈痛点应运而生的一种互连标准,从制定之初就定位为高端应用,互连互通不是主要矛盾,高性能通信才是主要切入点,所以,相对于Ethernet技术而言,由于定位的差异导致InfiniBand与生俱来就有很多和Ethernet的不同,主要表现在带宽、时延、网络可靠性、组网方式、和组网方式上。
要解决的问题是,在一套系统内部,如何将多个分开的部件整合起来,如同一台设备一样工作。我们可以把这种网络称为一种fabric,是一种互联技术。
带宽
自InfiniBand诞生以来,很长一段时间InfiniBand网络速率的发展都是快于Ethernet的。
主要原因就是因为InfiniBand应用于高性能计算中服务器之间的互连;
Ethernet面向更多的是终端的设备互连,带宽上没有太高的需求。
时延
此处主要分为两部分进行对比:
- 一部分在交换机上
作为网络传输模型中的二层技术,Ethernet交换机普遍采用了MAC查表寻址和存储转发的方式(有部分产品借鉴了InfiniBand的Cut-though技术)由于需要考虑诸如IP、MPLS、QinQ等复杂业务的处理,导致Ethernet交换机处理流程较长,一般会在若干us(支持cut-though的会在200ns以上);
而InfiniBand交换机二层处理非常简单,仅需要根据16bit的LID就可以查到转发路径信息,同时采用了Cut-Through 技术大大缩短了转发时延至100ns以下,远远快于Ethernet交换机。- 网卡层面
采用RDMA技术,网卡转发报文不需要经过CPU,大大加快了报文在封装解封装处理的时延,一般InfiniBand的网卡收发时延(write,send)在600ns,而基于Ethernet上的TCP UDP应用的收发时延会在10us左右,相差十几倍之多。
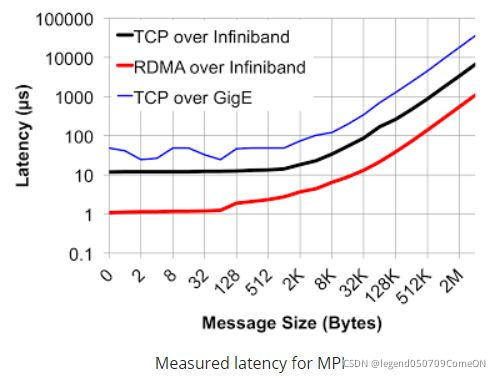
可靠性
在高性能计算领域,丢包重传对整体性能的影响非常大,
所以需要一个高可靠的网络协议从机制层面来保证网络的无损特性,从而实现其高可靠特性。
- infiniband
InfiniBand是一个完整的网络协议,有自己定义的一至四层格式;
报文在网络上的收发是基于端到端的流控来实现的,也就是说报文从发送端是否可以发送是受接收端调度控制的,这样就可以保证报文从发送到接受都不会出现拥塞,这样不仅实现了真正意义上的无损网络,同时由于网络上没有拥塞而使得业务流在InfiniBand的网络上传输不会出现缓存积累,这样时延抖动也就控制到了最小,从而构造了一个理想纯净的网络;- ethernet
Ethernet构造的网络没有基于调度的流控机制,导致报文在发出的时候是不能保证对端是否会出现拥塞的;
因此,为了能够吸收网络内瞬时流量的突增,需要在交换内开辟多大数十MB的缓存空间用于暂时存储这些报文,
而缓存的实现是非常占用芯片面积的,这使得同等规格的Ethernet的交换机芯片面积明显大于InfiniBand芯片,不仅成本高而且功耗大,除此之外,由于没有端到端的流控机制,导致网络在略极端情况下,会出现缓存拥塞而导致的丢包,使得数据转发性能大幅波动。
PS:
TCP 的流控应该不是端到端的流控,而是 socket层 缓冲区的流控,实际网卡的队列的大小是没有流控的。

组网方式
- ethernet
Ethernet的组网方式需要IP配合ARP协议来自动生成MAC表项的,需要网络内的每个服务器来定时发送报文保证表项的实时更新。
- 网络内节点的增加删除都要通知到网络中的每一个节点,当网络内的节点数量增加到一定程度的情况下,这样网络会产生广播风暴从而使得网络带宽被严重浪费;
- 因此需要引入Vlan机制划分虚拟网络,限制网络规模,而由于Ethnernet网络本身表项学习机制的不足会导致环路网络,又必须引入STP等协议保证网络转发路径不会出现环路,增加了网络的配置的复杂度。
- SDN
随着SDN技术兴起,由于Ethernet网络设定之初的理念是以兼容为基础的缘故,基因中就不具备SDN的特质,导致SDN部署在ethernet网络上需要重新改变报文格式(VXLAN[5])或者改变交换机的转发机制(openflow[6])这样的方式对Ethernet进行改造来满足SDN的要求。
- infiniband
- SDN
InfiniBand来说是天生具备了SDN理念的,
每个InfiniBand的二层网络内有会有一个子网管理器来配置网络内节点的ID(LocalID),
然后通过控制面统一计算转发路径信息,下发至InfiniBand交换上;
这样组成一个InfiniBand的二层组网需要做任何配置既可以完成网络配置,同时没有泛洪的问题,也省去了Vlan和环网破环的操作,可以轻松部署一个规模几万台服务器的超大二层网络。这是Ethernet所不能具备的。
类比
可以把以太网想象成一个快递包裹分发网络;
而IB网络,则可以想象成一个城铁轨道交通网络。
以太网类似一个快递包裹分发网络;
这个网络中所有的快递中转站(交换机/路由器)都是独立运作,根据一套公认的规则(网络协议)进行分拣并投递对。
每个中转站(网络设备)设备来说,第一,它可能看到发送到任何地址的包裹(分布式,异构的),所以它收到每个包都要算算该怎么发出去合适(这就要花时间,引入延迟),如果业务太繁忙,收不下来了,就间断粗暴的把包裹丢弃(丢包)。
B网络你可以想象成一个城铁轨道交通网络。这是因为IB的底层是基于VCT(Virtual Cut Through)技术。
所以IB的一个数据包,与以太网的包裹相比更像是一列火车(每节车厢是个叫做flit的数据单元)。为什么这么类比?不像以太网在转发时必须先在入队列上包裹收下来,然后丢到出队列等待再发出去。
- IB网络是直接然后再在过每个中转站的时候,车屁股还没进站,车头已经向下一站出发了!所以它的延迟才能做到这么低。
- 同轨道交通网络一样,这些中转站(交换机)之所以能做到这么快的让车辆通过,是因为目的地车站是确定且有限的(IB网络的地址数量,称为LID号,是有限的,地址空间65535个),所有列车怎么走在网络开始运行前都提前决定好了(路由表提前算好),所以在每个中转站的扳道工只需要简单查一下线路图(实现就是个普通的数组查询),“到10号站的车该走n2出口”就行了,而不像快递网络一样去查“xxx区xxx号xxx大厦”该怎么走(实现中用哈希或者CAM)
综上总结
- Ethernet的时延高的原因是:
转发时,收包,入收包队列;发包,入发包队列;
转发时,在每个查找到目的地的路线图(路由、邻居表现等)
infiniband 的缺点
- 地址空间限制
- 成本高
- 需要调度中心
如同轨道交通网络一样,需要有个叫做subnet manager的调度中心来进行管理和调度,所以IB天生就是一个SDN网络。
当然,IB的SDN它不看任何数据包,而是负责维护所有中转站的那张线路图(线性转发表),除了保证调度策略高效稳定,还需要额外考虑轨道交通中避免死锁问题(这个是以太网不需要考虑的)。
infiniband 的应用场景
有很高的性能要求的时候,IB网络仍然是首选,这也是为什么IB网络是当前高性能计算行业的主要网络方案,但这个市场相对来说比较小。
当前的主流的数据中心网络都是要解决多个异构系统的互联问题,即使是单一的大规模应用场景,包括云计算、大数据等,主流也都是以高吞吐量场景,也就是多个节点做多个事情,对节点之间的通信延迟没有很高的要求,更看重的是灵活的接入与扩容。所以这些场景用以太网就非常合适。
这就是为什么看着IB网络各项技术指标都很好,但是普及率远远不及以太网的原因。
参考
知乎文章,讲解 infiniband 和 ethernet 的区别:
https://www.zhihu.com/question/31960853
https://zhuanlan.zhihu.com/p/163104439
- 4