https://zhuanlan.zhihu.com/p/542132384
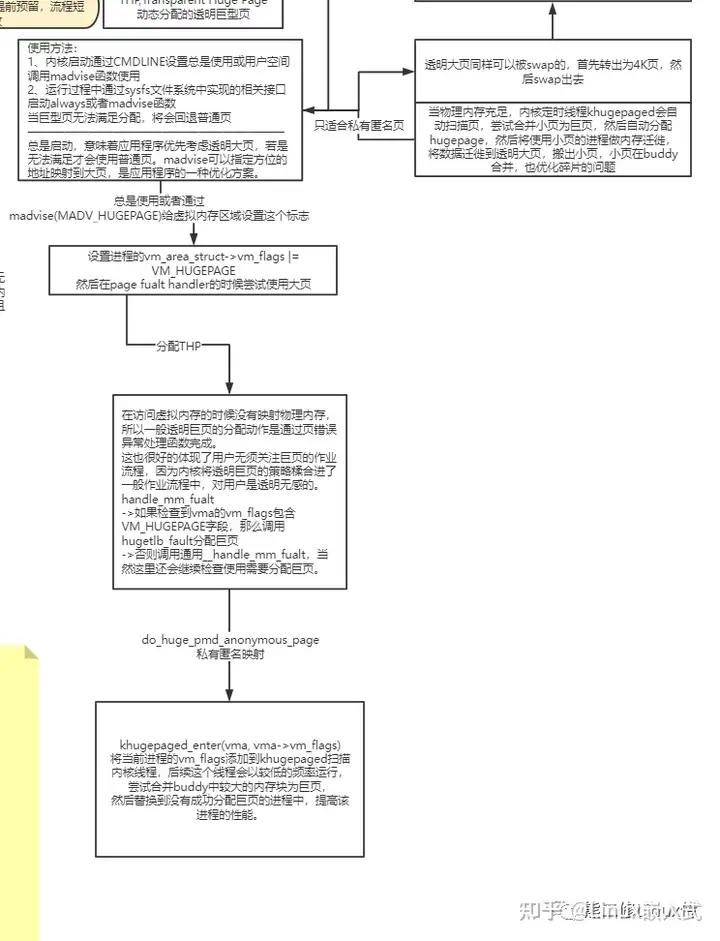
前言:
巨页的提出初衷是提供对内存使用量大的进程在某些场合下能拥有更好的性能的一种策略。巨页的定义有些含糊,按照最初提出patchset的人的意思,只要大于系统默认PAGE_SIZE的页,都可以称之为巨页。巨页从2.6发展到现在,已经证明了它存在的价值,合入主线成为内核繁多子系统中一个成熟的板块,巨页子系统默认使能,但是要使用它,用户可能需要做一些动作。
【文章福利】小编推荐自己的Linux内核源码交流群:【869634926】整理了一些个人觉得比较好的学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前50名可进群领取!!!并额外赠送一份价值600的内核资料包(含视频教程、电子书、实战项目及代码)!!!
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
巨页从用户使用的角度可以划分为两大类型:
传统巨页和透明巨页。
两者从内存来源、内存管理、内存使用、性能权衡等诸多方面均有所差异,如果扣细节,应该要像CMA一样分成几个章节讲解,但是在编写文章之前稍作思考,巨页在核心层面上其实比较简单,不应该把简单的事情复杂化,所以,本文将会摘简描述其实现原理,最后以实践结尾,探索巨页美妙的故事。
另外,文章末尾备注来自LWN关于巨页的参考文献,若是对细节有所追求的知友,可自行前往查阅。
如下图:
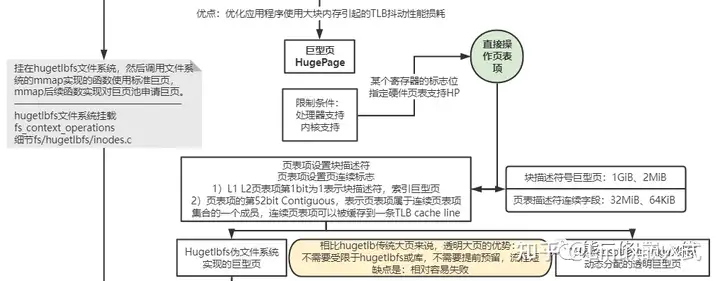
巨页能在提高某些应用场合使用大块内存的性能,但巨页的实现受限于平台架构的支持。从ARM64来说,4几页表:
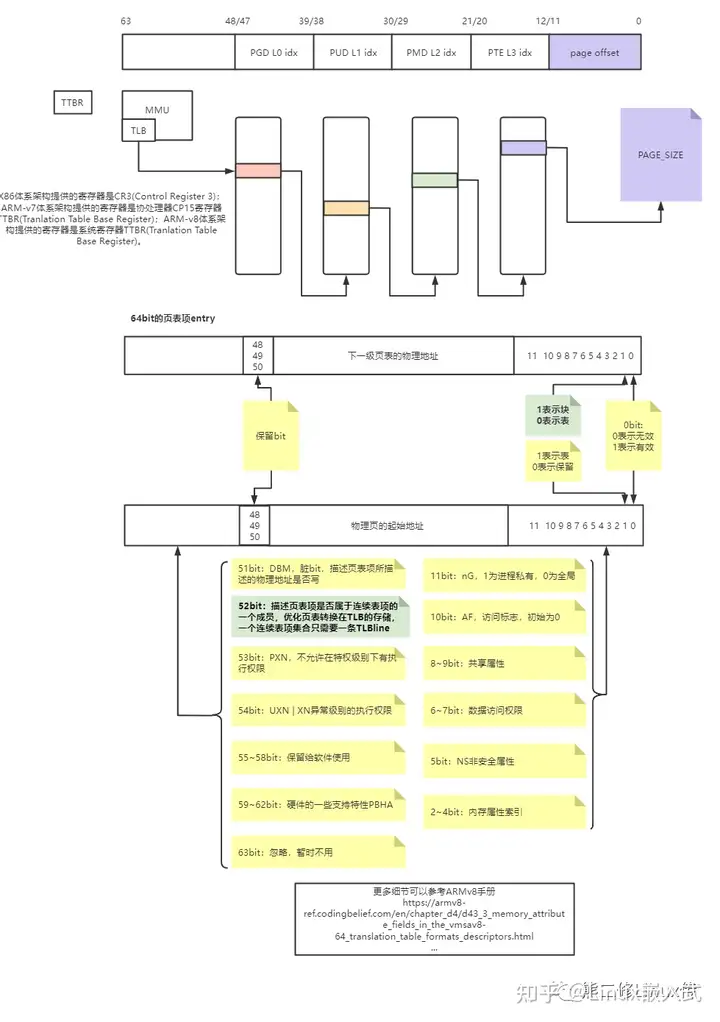
通过设置L1 L2的页表项的52bit + 01bit为巨页,分别支持1GiB、2MiB*N大小的巨页。
所以,到这里,我们也可以理解,文章后面所描述分配的巨页,实际上就是设置L1 pud或者L2 pmd页表项,映射某个大小的物理地址范围。
看到一副画,我们先看个全貌,心里有个底子,知道这是一副大概描述什么内容的画面。
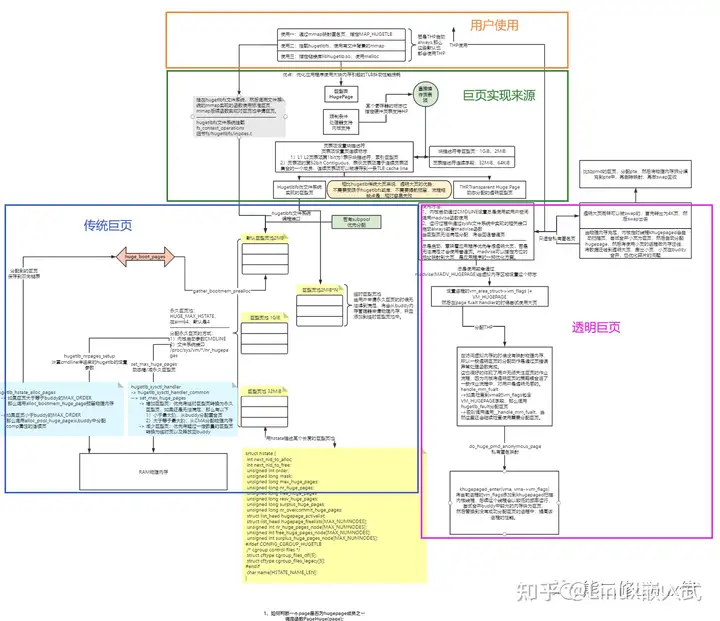
画面导读:
1)传统巨页
传统巨页是指在系统中提前预留巨页,用户必须显式地通过hugetlbfs文件系统实现的mmap底层接口或者通过libhugetlbfs.so的库指定使用巨页。为什么称呼为传统,从我目前的理解来看,一是因为传统巨页是最早提出的巨页策略;二是因为这个巨页的使用比较繁琐,需要系统提前预留巨页,而且受限"hugetlbfs",获取内存的流程相对复杂。
2)透明巨页
透明巨页是指系统无须提前预留巨页,无须提前准备,进程分配内存在系统使能透明巨页策略的情况下,会自动默认优先使用巨页,用户无法觉察。优势也比较明显,就是为了优化传统巨页带来繁琐的流程,缺点是在系统内存紧凑的时候容易分配失败。
3)用户使用
传统巨页,用户的使用受限于hugetlbfs,只能通过hugetlbfs实现的mmap底层接口或者链接libhugetlbfs.so库指定。但是透明巨页则没有这个限制,透明巨页的使用有两种方式:
never,禁止使用透明巨页
always,总是使用透明巨页
madvise,通过madvise使用透明巨页
如果启动"always",那就是系统默认进行在分配巨页的时候,所需要的内存大于2MiB,将会默认分配巨页,请注意,分配的内存并一定都是巨页,巨页是按照某个配置项设置的"伪对齐",比如我自己实践的虚拟机,默认2MiB对齐(pmd中间页表项)。为什么说"伪对齐",举个例子,通过malloc分配3MiB,其中2MiB是巨页,剩下的1MiB就是buddy的普通页。
传统巨页的实现核心是提前预留巨页内存,但是在通过hugetlbfs分配传统巨页无法满足的时候,系统会从buddy分配物理内存,生成临时巨页,这些巨页因为也是通过hugetlbfs的方式使用,也属于传统巨页。所以传统巨页从触发巨页的方式可能分为三种路径:
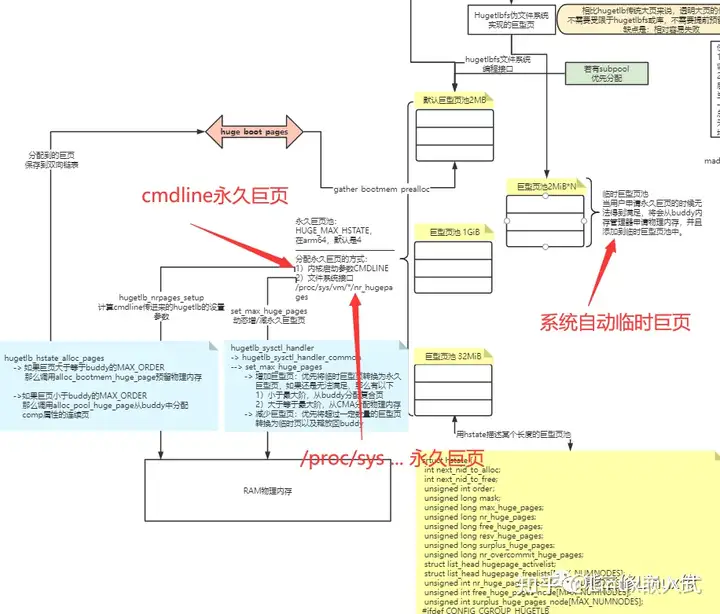
1)内核启动过程中通过cmdline传递永久巨页
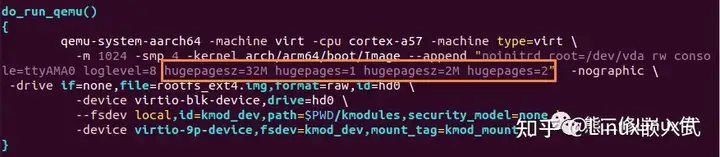
预留两种大小的巨页,32M*1 + 2M*2,启动内核,读取巨页信息:
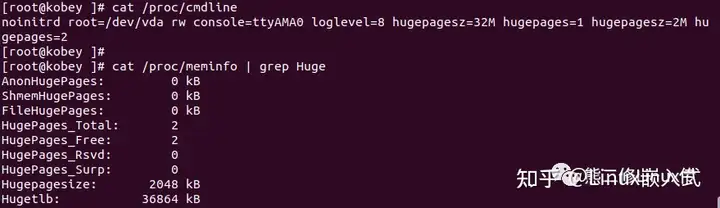
可以看到,系统预留了两种大小的巨页,无异常。
cmdline预留巨页的方式是如何实现的呢?
在内核启动过程中,解释cmdline并且保存到一个全局boot_param的数组中
start_kernel
-> ...
-> do_early_param
-> __setup("hugepages=", hugetlb_nrpages_setup);
然后在hugetlb_init->hugetlb_init_hstates->hugetlb_hstate_alloc_pages分配永久巨页内存:
如果巨页大于等于buddy最大阶的连续页,那么就从memblock中分配内存,回忆一下,memblock分配内存的行为是什么?就是找memory数组中找到合适大小的内存块,挂到reserved中管理,这种类型reserved中的内存在最后不会释放到buddy,所以,也符合"永久属性"。
如果巨页小于buddy最大阶的连续页,那么就从buddy中分配内存,并且设置首页page的flags字段为comp复合页,末页设置HUGETLB_PAGE_DTOR字段,这样后续可以通过page知道当前复合页是巨页属性。
(看上去memblock在工作的时候还能选择buddy?不是说memblock消失在buddy的开始吗,这个疑点以后有机会再翻翻代码,或者有知道的道友可以告知我一下,谢谢)。
不管是memblock还是buddy的途径分配巨页,最后都是放到全局双向链表huge_boot_pages中暂存。
预留巨页后,还需要管理巨页:
hugetlb_init->gather_bootmem_prealloc,遍历huge_boot_pages,然后调用prep_new_huge_page将巨页按照大小分配保存到struct hstate描述的巨页池中。
2)通过/proc/sys/vm/nr_hugepages在内核启动后动态调整巨页池大小
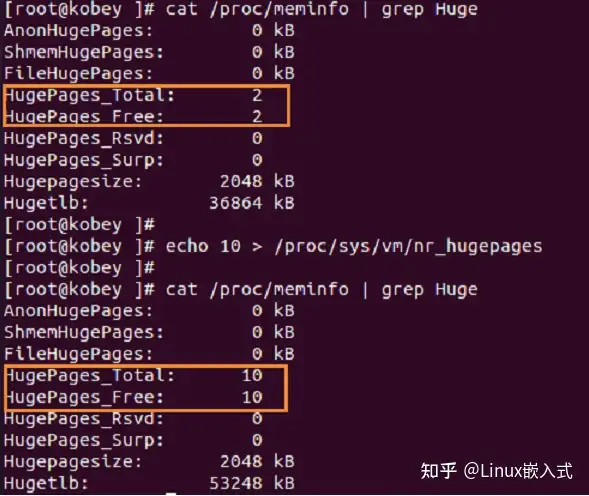
那么这种方式的巨页又是如何实现的呢?
hugetlb_sysctl_handler
-> hugetlb_sysctl_handler_common
-> hugetlb_sysctl_handler_common
-> set_max_huge_pages
在函数set_max_huge_pages中调整巨页池的大小:
若是增加巨型页:优先将临时巨型页转换为永久巨型页,如果还是无法满足,那么有以下
1)小于最大阶,从buddy分配复合页
2)大于等于最大阶,从CMA分配物理内存
若是减少巨型页:优先将超过一定数量的巨型页转换为临时页以及释放回buddy。
3)永久也无法满足分配的时候,系统将会自动从buddy中申请内存填充临时巨页。
瞄了一眼,核心函数应该是dequeue_huge_page_nodemask,偷个懒,不想去跟了。
前面也描述了,透明巨页只需要用户打开使能透明巨页的开关,进程使用大块内存的时候将会默认自动选择巨页。内核完成了这套流程的代码,用户是不可能见的。对这些细节有兴趣的道友请自行查阅本文末尾备注的参考文献。透明巨页的实现核心主要是设置进程的
vm_area_struct->vm_flags |= VM_HUGEPAGE
当进程分配内存,读写内存的时候,在page_fualt_handler中填充物理页,这个时候就会动态分配巨页。
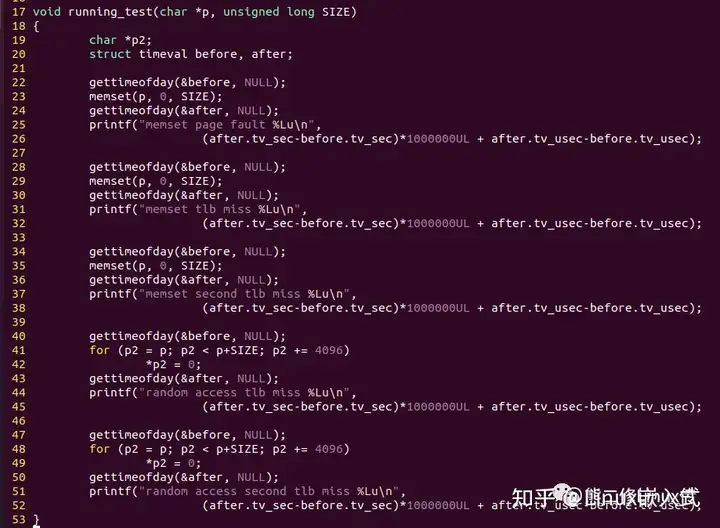
这份代码是一份对巨页性能的测试代码,申请内存,然后分别做两次直接读写和随机读写,然后打印这些读写的耗时,从而大概感知系统对不同内存供给的情况下,对读写性能的影响。道友可以基于这份测试代码添加自己其他形式的实践,比如有文件背景的hugetlbfs等。这里作为代表性简单演示以下两种测试方案:
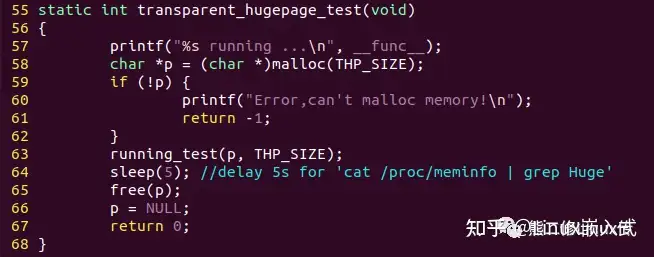
1)transparent_hugepage_test测试透明巨页的读写性能
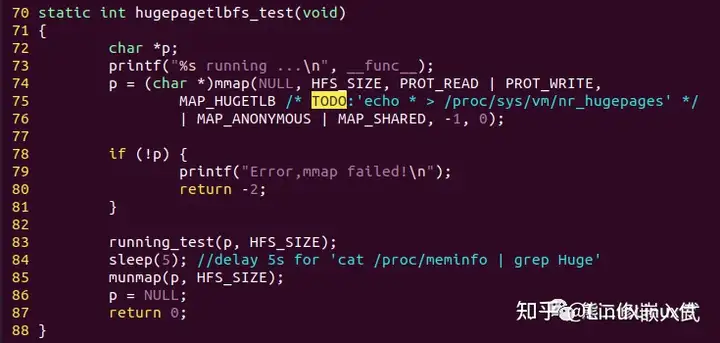
2)hugepagetlbfs_test测试传统匿名巨页读写性能,请注意测试传统巨页的时候必须在系统中提前预留内存,否则可能会发生段错误。
计算代码执行时间:
分配透明巨页:
分配传统巨页:
体验:
试一下没有启动透明大页的功能,分配100MiB内存,做一次读写,查看程序执行时间:
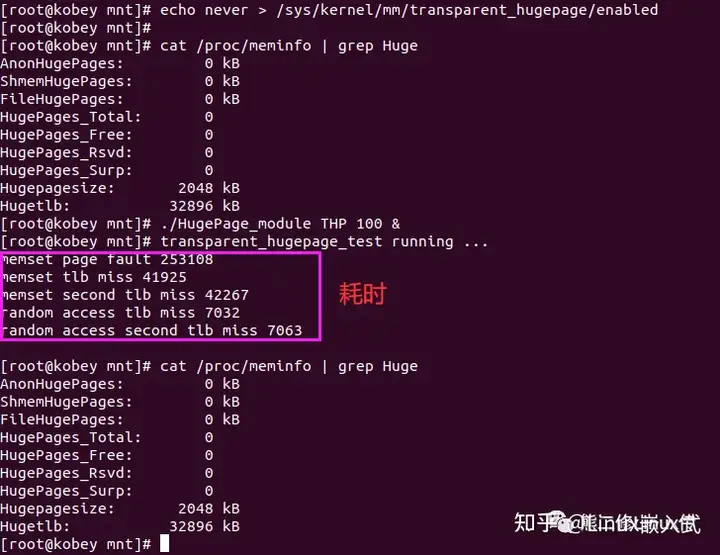
启动透明大页功能,再次分配100MiB内存,做一次读写,查看程序执行时间
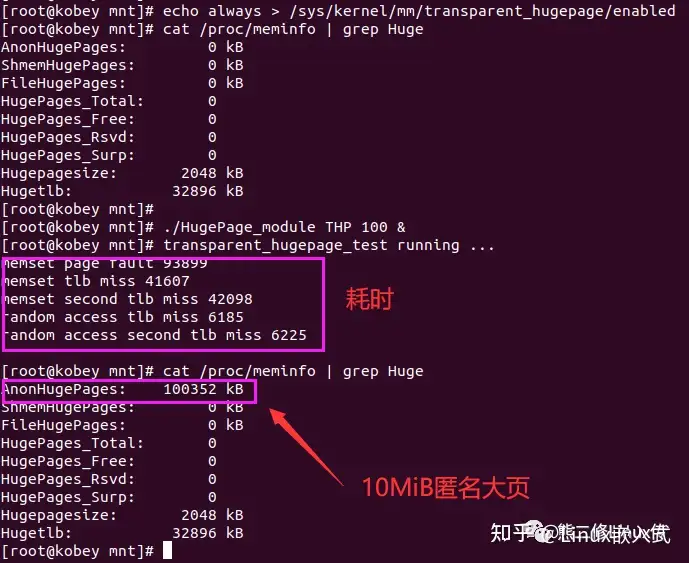
可以看到,效率有一定程度的提升。
本次实践的代码下载方式:
wget https://gitee.com/kobeya/linux-5.6/raw/master/03_kobey_codes/WgetCodes.sh
chmod +x WgetCodes.sh
选择20,即可下载使用。