https://zhuanlan.zhihu.com/p/138887556复制
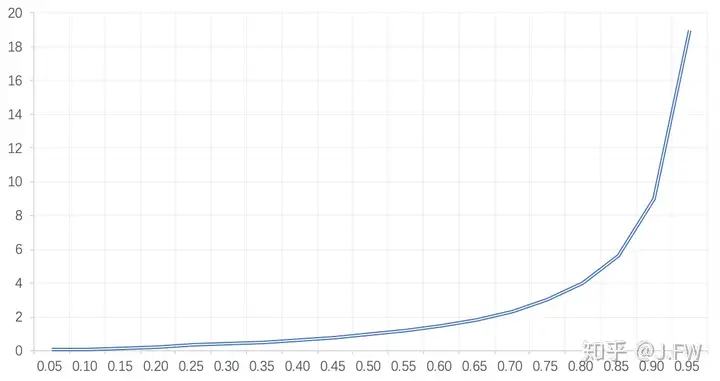
队列广泛应用在性能分析领域, 通过观察队列可以知道当时系统的繁忙程度和请求的延时, 甚至可以用排队论去做容量规划等. 对存储有一定了解的同学都或多或少听说过, 当iostat的util大于70%以后, 响应时间会如下图所示大幅升高, 但是用fio去压测的时候, 观测的结果却并不相同. 这是为什么呢?
相信大家都有这样的经历, 系统卡顿时马上运行iostat来看一下是否慢I/O导致.
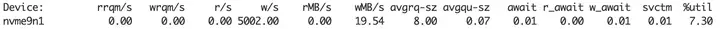
除了和I/O直接相关的几个统计数据之外, iostat提供了这些通用的队列统计:
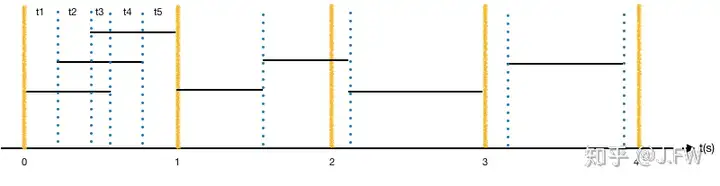
先抛开具体实现, 我们先看一下iostat的输出应该是怎么样的. 下图中请求使用黑色的横线表示, 两端分别是进队列时间和请求完成时间, 这里没有画出请求的处理时间.
iostat的实现分2部分:
内核使用disk_stats结构来记录队列信息, 暂且不区分读写I/O, 可以简化如下:
struct queue_stat {
uint64_t ios; // 完成的IO个数
uint64_t ticks; // 所有req花费的时间总和, 用于计算await
uint64_t io_ticks; // 队列非idle状态的时间, 用于计算util
uint64_t time_in_queue; // 按队列长度加权的时间, 用于计算avgqu-sz
uint64_t stamp; // stat最后更新的时间
};
void enqueue(req) {
// part_round_stats()
if (in_flight) {
time_in_queue = in_flight * (now - stamp);
io_ticks = now - stamp;
}
stamp = now;
in_flight++;
}
void dequeue(req) {
ios++;
ticks += now - req->start_time;
// part_round_stats()
time_in_queue += in_flight * (now - stamp);
io_ticks = now - stamp;
stamp = now;
in_flight--;
}复制如果只在request enqueue/dequeue的时候更新统计信息, 那么对于上图第1秒的统计来说, 因为后面的那个I/O并没有结束所以统计不到, 导致的明显问题就是util在第1秒的时候小于100%, 而第2秒的util因为该I/O又大于100%, 所以当用户态程序iostat去读取比如/proc/diskstats的时候, 内核会通过part_round_stats()补上对应统计. 注意: 当用户态iostat进程去读取diskstats文件时, 内核是能够感知这个操作并进行订正. 如果队列统计信息是在用户态收集, 并通过共享内存方式供类似iostat的进程访问, 由于没有这个订正操作, 就会出现大于100%的情况.
iops = ios / duration;
avgqu-sz = time_in_queue / duration;
await = ticks / ios;
util = io_ticks / duration;复制以图中第0秒为例, ticks和time_in_queue表示的都是该区间内所有I/O花费的时间之和, 也就是说如果所有I/O都没有跨越时间边线的话:
avgqu-sz = time_in_queue / duration
= ticks / duration
= (ticks / ios ) * (ios / duration)
= await * iops复制这就是对Little's Law的直观印象. 那么在await已经记录的情况下, 真的需要再去统计time_in_queue用于avgqu-sz的计算吗? 注意上面说的part_round_stats()订正手段, 这是和计算time_in_queue一致的.
另外我们可以看一下平均服务时间service time怎么计算而得:
svctm = io_ticks / ios
= (io_ticks / duration) / (ios / duration)
= util / iops复制为了更精确地了解队列的运行情况, 下面我们会实现一个生产者消费者队列
首先我们测试一下在请求匀速到达的情况:
void produce_uniform(int iops, int svctm) {
req.svctm = svctm;
for (int i = 0; i < iops; ++i) {
queue_.enqueue(req);
busywait(US_P_S / iops); // waiting
}
}
void consume() {
while (!done) {
queue_.dequeue(req);
busywait(req.svctm); // working
}
}复制我们以如下进行如下测试:
for (int qdepth: {16})
for (int iops : {10000})
for (int svctm : {50, 70, 80, 90, 95, 98, 100}) { do_test(); }复制

真实的场景下I/O的到达时间是很难遵从均匀分布的, 一般可以认为遵从某种随机分布, 特别是泊松分布. 为了实现泊松分布, 我们直接计算下次发生的时间点. 如果事件到达符合泊松分布, 那么事件到达时间的间隔符合指数分布, Knuth早有算法生成, fio代码里面也使用该算法. 我们使用这种方法
void produce_fio_poisson(int iops) {
req.svctm = svctm;
std::random_device rd;
std::mt19937_64 gen(rd());
uint64_t FRAND64_MAX = -1UL;
for (int i = 0; i < iops; ++i) {
queue_.enqueue(req);
uint64_t next = (int64_t)(US_P_S / iops) * -logf((gen() + 1.0) / (FRAND64_MAX + 1.0));
busywait(next);
}
}复制


现在我们把服务时间也调成指数分布
void consume_exp() {
std::random_device rd;
std::mt19937_64 gen(rd());
std::exponential_distribution<> d(1);
while (!done) {
queue_.dequeue(req);
svctm = d(gen) * req.svctm;
busywait(svctm);
}
}复制

在上面的测试中我们可以看到max_inflight已经到16, 那么有很大可能某一时刻待处理请求是超过16的, 只是因为队列qdepth的约束而没有进入队列, 现在考虑调高qdepth到256

维基百科上M/M/1 queue的定义
An M/M/1 queue is a stochastic process whose state space is the set {0,1,2,3,...} where the value corresponds to the number of customers in the system, including any currently in service. - Arrivals occur at rate λ according to a Poisson process and move the process from state i to i + 1. - Service times have an exponential distribution with rate parameter μ in the M/M/1 queue, where 1/μ is the mean service time. - A single server serves customers one at a time from the front of the queue, according to a first-come, first-served discipline. When the service is complete the customer leaves the queue and the number of customers in the system reduces by one. - The buffer is of infinite size, so there is no limit on the number of customers it can contain.
当存储只是HDD这种机械硬盘的时候, 它的行为是比较确定的. 但是当存储的实现越来越复杂的时候, 特别是软件的比重越来越大的时候, 请求的服务时间就不一定遵循指数分布了. 假设软件有一个bug, 会导致如下10%的请求处理时间明显更高, 我们来看一下结果.
void consume_jitter() {
std::random_device rd;
std::mt19937_64 gen(rd());
std::exponential_distribution<> d(1);
static uint64_t i = 0;
while (!done) {
queue_.dequeue(req);
svctm = d(gen) * req.svctm;
if (i++ % 100 < 10) {
svctm += req.svctm * 5;
}
busywait(svctm);
}
}复制



从上面的测试可以知道, 排队论是纯粹的数学问题. 对于数学问题, 都是由公式的, 所以不再通过程序模拟. 我们可以访问这个网站: https://www.supositorio.com/rcalc/rcalclite.htm
这里有一个很常见的问题, 提升单核处理能力和多核那个效果更好
还有一些问题这里不再一一举例, 比如:
同样, 对于排队网络, 比如M/M/1, -/M/1也是个数学问题.
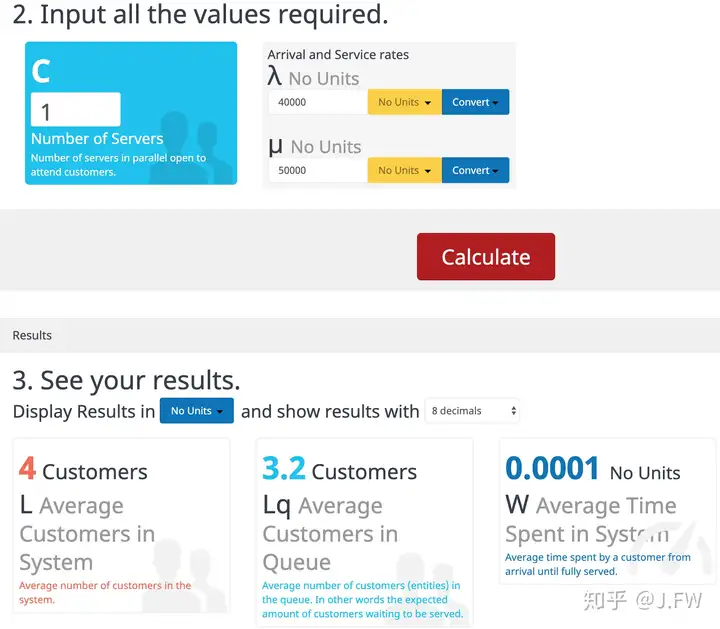
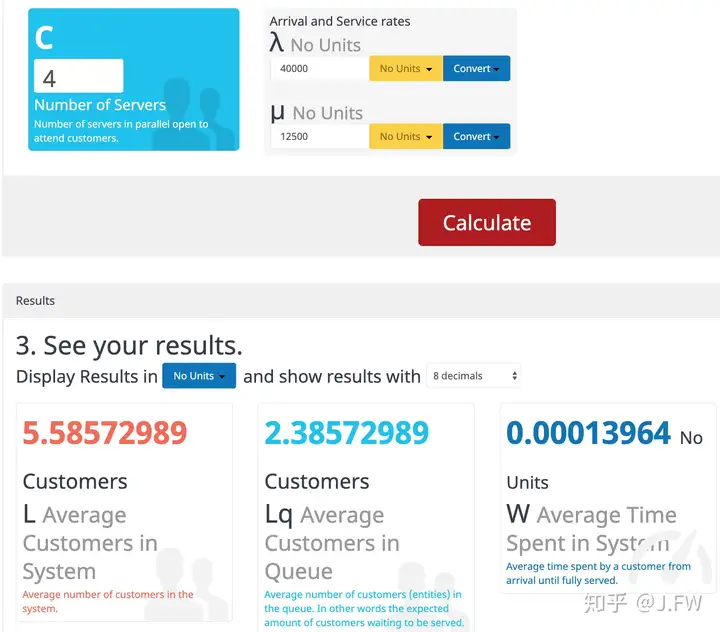
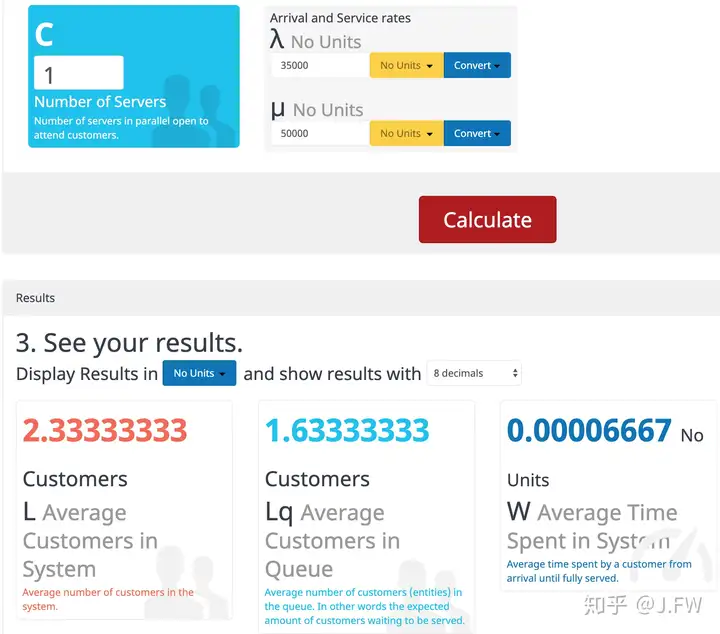
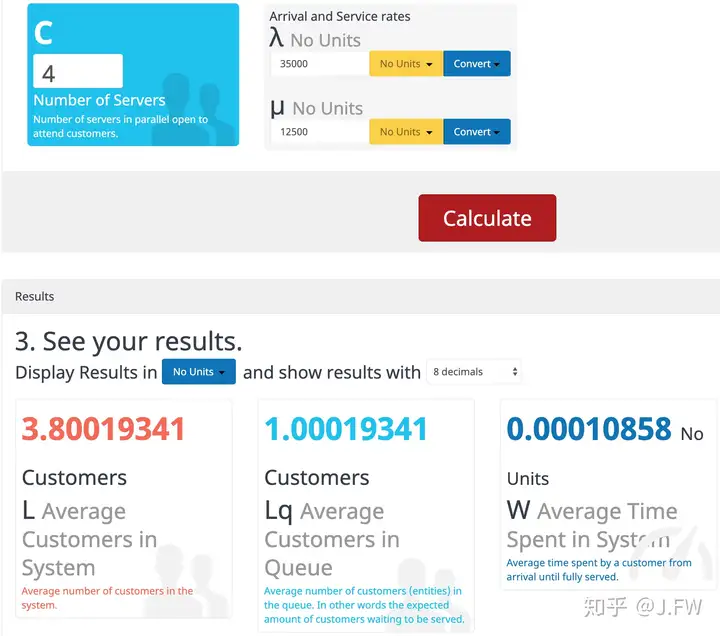
首先我们知道随机并不意味着没有规律, 不同的随机过程有着不同的统计规律, 如果我们知道队列到达和服务的统计规律, 那么数学上就可以预测队列的表现, 所以排队论可以用于容量规划和性能预测等, 只要能够找出相关的统计规律及其具体参数. 那么对于问题诊断来说, 队列统计能带来什么不能带来什么?
https://www.supositorio.com/rcalc/rcalclite.htm https://drkp.net/papers/latency-socc14.pdf https://en.wikipedia.org/wiki/M/M/1_queue https://people.eecs.berkeley.edu/~pattrsn/252S98/Lec13-queuing.pdf https://en.wikipedia.org/wiki/L