https://zhuanlan.zhihu.com/p/138888698复制
RAID (Redundant Array of Inexpensive Disks)由加州伯克利大学的几位教授在上世纪八十年代提出, 刚开始的设想是使用廉价的硬盘, 但是随着越来越多硬盘产商进入这个领域, 它们希望赚取更多的利润, 恰好需要使用 RAID 技术的都是一些有钱的主, 企业级硬盘 (Enterprise Drive) 在数据中心大行其道, Inexpensive 变得没有那么重要, 慢慢地 RAID 就变成了 Redundant Array of Independent Disks). 虽然换成了 Independent, 但是后面我们会知道想要做到也并不容易. 其实RAID的核心在于前两个字, 使用多个硬盘 (Array) 来提升容量 (Capacity)和性能 (Performance), 使用额外的 (Redundant) 的硬盘来保证完整性 (Integrity).
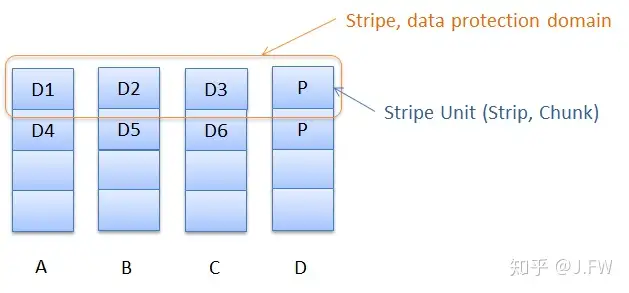
RAID 以 Stripe 为单位对数据提供保护, Stripe 又划分成 Stripe Unit 分布到所有的成员硬盘中, 往往一个 Stripe 会包含多份数据以及校验和. 在基本的 RAID 实现里, 通过一个简单的映射把 RAID 虚拟出来的逻辑磁盘地址对应到相应的物理硬盘和 LBA 上, 以下图为例, D1, D2 到 Dn 形成一个连续的地址空间. 在复杂的 RAID 实现里, 特别是一些实现压缩, 去重的商用系统, RAID 内部会维护一个虚拟磁盘地址到物理磁盘的映射, 这种简单的映射关系不复存在.
最根本地, Stripe 是 RAID 的基本组成部分, Stripe 之间并不强制也不排斥有额外的关系.
不同的使用者往往会有不同的需求, 有的看重性能, 有的更看重数据保护能力, 所以就出现了不同的 RAID 级别. SNIA (Storage Networking Industry Association) 对 RAID 进行了标准化工作, 当然有的厂商会有一些自己的实现.
SNIA 标准化了 0-6 共 7 个级别的 RAID
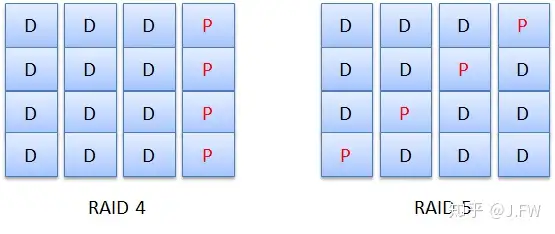
RAID 4 和 RAID 5 的唯一差别就是校验和 (Parity) 的放置位置. RAID 4 使用一块单独的盘来放校验和, 而 RAID 5 却把校验和分散到不同的盘上.
除了镜像, 其他的冗余都是通过校验和来实现的, 当然镜像也可以看作是一种校验和. 校验和的算法各种各样, 先来看一种比较基本的, 假设我们有 4 份数据 D1, D2, D3, D4, 需要定义一种校验和 P, 在任意的数据 Di 不能读取的情况下, 使用 P 去恢复 Di. P 可以这样定义:
P = D1 + D2 + D3 + D4复制正确性很容易证明, 因为 D1, D2, D3, D4, P 值都可以通过其他的 4 个数据计算而得. 如果需要像 RAID 6 那样使用 2 种校验和, 那么另一个校验和 Q 可以怎么定义呢:
Q = D1 + 2 ∗ D2 + 3 ∗ D3 + 4 ∗ D4复制同样地, D1, D2, D3, D4, P, Q 都可以通过任意 4 个数据计算而得, 所以能够容忍任意 2 块坏盘的情况. 那么 Q 定义成这样行不行:
Q = D1 + 1 ∗ D2 + 3 ∗ D3 + 4 ∗ D4复制在 P, Q 的定义中都使用了(D1 + D2), 如果 D1, D2 都丢失的话, 就不能够重新计算出来了. 所以简单地说, 一个正确的 Q 需要保证 g1, g2, ..., gn 各不相等:
P = D1 + D2 + ⋯ + Dn
Q = g1 ∗ D1 + g2 ∗ D2 + ⋯ + gn ∗ Dn复制在 Full Stripe Write 的情况下, 所有的数据都已存在, 可以用来直接计算 P, Q. 如果是 Partial Stripe Write 的情况下应该怎么办呢? 一种可行的办法是把 Stripe 的其它数据先读出来, 比如说在只有 D1 改变的情况下怎么更新 P:
P′ = D1′ + D2 + D3 + D4复制这样需要额外地访问 3 次磁盘操作分别读出 D2, D3, D4. 这种方式叫做 Additive, 还有一种 Subtractive 的方式同样能计算新的 P 值:
P′ = D1′ + D2 + D3 + D4
P = D1 + D2 + D3 + D4
P ′ = D1 ′ + P − D1复制这样的话就只需要 2 次磁盘操作读出 D1 和原来的 P 值. 什么时候用 Additive 或者 Subtractive, 取决于更新了几个 Stripe Unit, 当整个 Stripe 一起更新的时候, 显然不会使用 Subtractive, 但是只更新某一个的时候, 往往 Subtractive 会更有优势, 当然总存在一个平衡点.
上述算法虽然逻辑上没有问题, 但在计算机上却不能实现, 因为这些操作有可能会有溢出, 也就是说, 校验和的长度会超过数据的长度. 很多产品, 包括 Linux Raid, 使用的是 Reed-Solomon Codes. 这种算法其实不只能实现 RAID 6, 它是一种通用的 Erasure Code, 也使用在大于 2 个冗余的情况.
Reed-Solomon Codes 是基于有限域 (Finite Field, Galois Field) 的, 有关有限域的详细信息可以查找相应的教材或者论文, 这里列出的这些信息可能不够严谨, 只是方便理解:
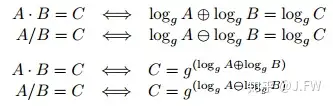
RAID 6 最后计算 P, Q 的值是使用这两个方程式, 我们已经知道 g^0, g^1, ..., g^(n-1)都不相同, 所以能够容忍任意 2 块磁盘的丢失.
RAID 6 还能够恢复单块磁盘的 corruption 问题, 通过重新计算 P’, Q’值, RAID 6 还能够确定是哪块盘发生了 corruption, 当然只能是单盘出现 corruption.

关于这种算法的更多细节可以查看 H. Peter Anvin 的这篇文档.
RAID 不但可以创建在裸盘上, 还可以创建在其他 RAID 上. 为了平衡 Performance 和 Reliability, 往往会创建 Nested RAID, 比如说先创建多个 RAID 1, 然后再通过 RAID 0 组合起来. RAID xy 或者 RAID x+y, 指的就是下面先组成 RAID x, 然后再组 RAID y, 上面所说的就是 RAID 10. 常用的 Nested RAID 有 RAID 10, RAID 50 和 RAID 60.
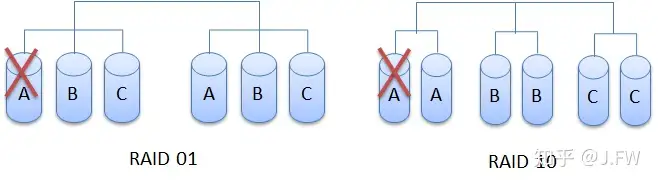
都是 RAID 0 和 RAID 1 的组合, RAID 10 和 RAID 01 的可靠性却不一样. 从下图可以看出, 在 RAID 01 的情况, 只要有一块盘出现问题, 则马上退化为没有任何保护的 RAID 0, 也就是说 RAID 01 只能够容忍一块坏盘. RAID 10 则不一样, 一块盘的错误只会引起一个子 RAID 1 退化成 RAID 0, 而对于其他的子 RAID 1 却没有任何影响, 在这种情况下, 即使 B 和 C 中再有一块坏盘都没问题.
除了以上所述的那些标准级别, 不同的厂商完全可以实现自己特有的 RAID. RAID 本质上就是提供数据保护, 对上层应用并没有其他的 Commitment, 怎么保护数据, 提供多少冗余等等都可以自己决定. 当只需要一份 Parity 的时候, 除了像 RAID 4/5 那样使用 XOR 并没有什么可以改进的地方, 但是当需要两份及以上 Parity 的时候, 除了 RAID 6 使用两个独立的函数对同一行计算 P, Q 外, 还有很多其他的选择.
对同一数据使用 2 个不同函数可以实现 2 份冗余, 那么使用同一函数对 2 个不同数据是不是也可以实现 2 份冗余呢? 首先这两份不同的数据必须是线性无关的, 也就是说任何两份数据都不会包含 2 个相同的数据块, 这跟 RAID 6 计算 P, Q 的函数是同样的要求. Diagonal Parity 方法就是除了使用 XOR 计算每行的 P 之外, 还对每条对角线上的数据也使用 XOR 计算出另外一个 P, 我们称之为 DP. NetApp 的 RAID-DP 用的就是这种方法, 同颜色的块用于计算 DP.
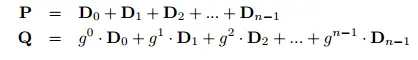
RAID-DP 在计算 P, DP 的时候用的都是 XOR, 相比较 RAID 6 的 P, Q 在计算方面会有一定的优势. 不过 RAID 6 很容易扩展到 3 个或多个冗余, 这种对角线的方式会略显复杂.
References:
[1] https://aptiris.com/products/whitepapers/RAID_DP.pdf
[2] http://www.emc.com/collateral/white-paper/h13036-wp-xtremio-data-protection.pdf
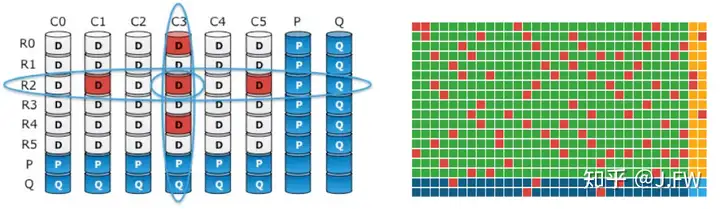
RAID-DP 通过对角线引入了另外一个维度, 正交其实应该是更直观的二维方式. 2D RAID 就是这么做的, 除了对每一行计算 P(r), 对每一列也计算一个 P(c). 可以很容易看出, P(r)和 P(c)比 RAID 6 的 P, Q 包含了更多的信息. 2D RAID 可以处理任意 3 块盘的错误, 甚至可以处理更多的坏盘, 只要不出现如下情况.
2D RAID 很早之前就提出来了, 最近 EMC DSSD 的发布似乎让 2D RAID 又普及了一把, 他们把这种 RAID 称作 CUBIC RAID. DSSD 在行和列 2 个维度上都使用了 RAID 6, 并且还对 P, Q 的行和列分别再做了 RAID 5. 我们可以来看看 DSSD 白皮书上给的效果图, CUBIC RAID 能够修复右边的错误.
只要愿意, 3D, 4D 都可以实现, 有兴趣的可以看看 RAID CUBE.
References:
[1] http://www.emc.com/collateral/data-sheet/h14869-ds-dssd-d5-cubic-raid.pdf
[2] http://www.eecs.berkeley.edu/Pubs/TechRpts/2015/EECS-2015-4.pdf
RAID-Z 实现了 3 种级别, RAID-Z1, RAID-Z2, RAID-Z3 分别对应到 RAID 5, RAID 6 和 RAID 7. RAID Z 的 2 个主要优点:
严格意义上来说, RAID-Z 并不是一种新的 RAID, 上面的 2 个优点也并不是因为 RAID 实现的不同, 反而可以说是 ZFS 提供的功能. 在 ZFS 之前, RAID 和文件系统是完全独立的两个产品, RAID 只需要提供文件系统使用的块设备接口, 但是在 ZFS 里却完全集成了 RAID 的功能, 也就是说 ZFS 自己能够提供数据保护. 只有在文件系统内部集成 RAID, 才能够更好的提供上面的 2 个优点, 否则实现起来会比较困难.
RAID 作为一种存储实现, 最基本的服务就是保证数据的可靠性和完整性, 没有这个前提, 容量和性能就没有太多的意义. 那么我们之前说 RAID 5 能容忍一块坏盘, RAID 6 最多支持两块坏盘到底是什么意思呢?
如果磁盘要么完全正常工作, 要么完全停止工作, 那么事情会简单很多, 可惜这种 fail-stop 模型并不真实存在. 真实的世界可以描述为 fail-partial 模型, 无论是 HDD 还是 SSD, 数据访问的时候:
对于 Drive 本身能够检测的错误, 不管是完全读不出数据还是 LSE, 上层软件都很容易处理. 这也是 RAID 最擅长的地方, 如果读不出数据, 通过 Parity 去重新 rebuild 丢失的数据就可以了. 但是对于 Drive Silent Corruption 的情况, RAID 就需要有更多的考量.
我们首先来看看这些错误发生的概率到底是个什么量级:
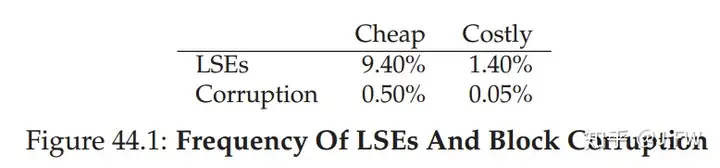
这是从大量在生产环境中的硬盘搜集到的数据, 可以看出 LSE 发生的概率还是很高的, 但是 Corruption 的情况也不能忽视. 虽然贵的硬盘有贵的道理, 但还是不能从根本上抑制错误的发生. SSD 因为使用的相对比较晚, 还没看到有人发布相应的数据, 但可以肯定的是在 SSD 上, LSE 和 Corruption 不可避免. 这不完全是 Drive 介质的原因, HDD 可能会因为机械原因导致 LSE, SSD 也可能因为 Flash 的原因导致 LSE, 而且 Flash 随着擦写次数的增多, LSE 也会明显的增加. 至于 Corruption, HDD 和 SSD 更没有本质的区别. 一般来说, 介质出问题并不会导致 Corruption, 因为对于每份数据, 或者一个 sector, 或者一个 page, 在 Drive 上会同时存放一个 ECC, 好一点的 Drive 上 ECC 的检测甚至纠错能力都是很强的, 即使介质发生了很多错误, ECC 至少能够检测出这种错误从而返回一个 LSE, 多强的 ECC 能检测多少错误, 这都是数学上可以计算出来的. 那么 Corruption 错误会从哪里来呢? 在数据存放到介质之前, 错误可能就已经发生了, 有可能是 Drive 的控制器或者里面的内存 Cache 等引入的, 甚至在数据进入 Drive 的控制器之前就发生了. 所以一般好的 Drive, 在数据一进来就先进行比如 CRC 之类的计算, 并在以后进行检验, 从而可以最大限度地控制 Corruption 的发生.
Intel 对不同厂商的 4 块企业级 SSD 放置在强辐射环境下进行了测试, 结果如下:
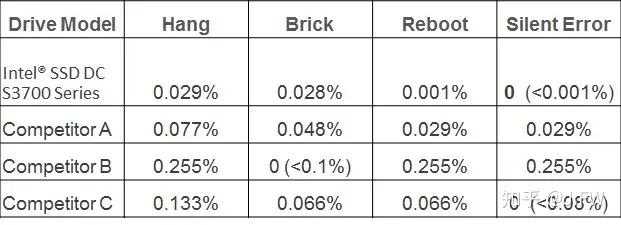
References:
[1] http://pages.cs.wisc.edu/~remzi/OSTEP/file-integrity.pdf
LSE 好处理, 因为只是读不到数据, RAID 可以通过 Parity 来重新计算出原来写入的数据. 但是碰到 Corruption 怎么办呢? 要想发现这种 Silent Disk Corruption, 常用的方法就是使用 Checksum. 虽然在前面 RAID 6 的时候提到过它其实是能够检测一块盘上的 Corruption 问题, 但 Checksum 更简单, 也更有效, 我们可以对每个 Stripe 或者每一个 Stripe Unit 都做 Checksum, 当然这会引入额外的开销.
还有个问题就是 Checksum 放在何处. Checksum 一般都是几十个字节大小, 而不管是 HDD 还是 SSD, 都存在最小的访问单元 Sector, 目前 Sector 最小 512 个字节, 但是越来越多的硬盘只支持 4KB 的 sector. 用户数据都是 Sector 的整数倍, 所以只能把 Checksum 放在额外的空间:
除了空间的开销之外, 还需要处理另外 2 种错误:
如果 Data 和 Checksum 分开放的话, 这两种错误出现的概率会非常低, 因为这需要两次写都犯同一个错误. 特别是像 ZFS 一样, Checksum 放在文件系统的 metadata 里面, 不仅解决了这个问题, 同时也解决了空间开销的问题.
我们都知道 RAID 是按 Stripe 组织的, Stripe 里面的 Parity 是通过 Data 计算生成的. 如果 Parity 跟 Data 不匹配的话, 会出现什么问题? 正常情况也不会怎么样, 因为 Read 操作一般是不会验证 Parity 的, 运气好的话, 该 Stripe 再次被写, Parity 又成功更新了. 但是如果另外的某块 Data Stripe Unit 读不出来了, 需要通过 Parity 来重新生成该 Data, 那么问题就来了, 这个时候就会生成错误的数据.

比如要修改 D1, RAID 5 需要同时修改 D1 -> D1’, P -> P’, 在 D1’成功写入, P1’还未写入的时候发生掉电或者当机, 那么 RAID 就会处于不一致的状态, 这个时候 D3 再坏了的话, Recover D3 时就会出现 Corruption. 当然 RAID 能发现这种情况然后进入 unclean 的状态, 只要尽快 Resync Parity 也就没事了. 万一 Resync 未完时 D3 就坏了, 依然没有办法区分到底是 D 正确还是 P 正确. 简单地说, 只要另一块盘 D3 不能访问了, Write Hole 就已经存在. LWN在这里描述了该问题.
Write Hole 这个问题不只存在 RAID 5 中, 甚至有时候还被称为 RAID 5 Write Hole, 但在 RAID 1, RAID 6 上都存在.
上面的例子是 Partial Stripe Write, 如果是 Full Stripe Write, 是不是还会出现这个问题呢? 显然是一样的. 那么怎么解决这个问题呢? Write Hole 的核心问题就是一个写操作被拆分成了多个, 所以终极的解决办法就是要保证 Write Atomicity. 文件系统通过 Journal 实现了事务操作, RAID 当然也是可以的. 但是需要注意的是, 这个日志会带来很大的开销, 所以日志文件系统比如 EXT3 一般只针对 Metadata 做 Journal, 而不对 Data 本身做 Journal. 不过随着 SSD 的广泛使用, 这样的开销慢慢变得可以接受, 已经有人在给 Linux MD 提供 Journal 实现了, 细节可以参考这里.
另一种方法是 NVRAM, 通过 NVRAM 很容易实现事务性, 只要 Stripe 没达到一致的状态, NVRAM 里面的数据就不会删除. 但是 NVRAM 是一种特殊的设备, 在一般的 PC 机甚至服务器上都不会配置, 只有在 Hard RAID 的存储产品上被广泛使用. Soft RAID 一般比较难解决 Write Hole 的问题, 加上性能等等原因, 所以市场上很少见 Soft RAID 的产品, 像 Linux MD 在重要的产品上应该用得也不多.
除了以上两种方法, ZFS/RAID-Z 也给出了自己的解决方案. ZFS 的每次写操作都不会有 Overwrite , 原来的数据不会被修改, 新写的数据也只有在整个 Stripe 都完成的情况下, 才可以被看见, 所以能够保证更新的原子性. Btrfs 也是同样的方法. 细节可以参考Jeff Bonwick对RAID-Z的描述.
绝大部分 RAID 产品在读的时候并不会验证 Parity, 即使读的时候会去验证, 还有大量的数据没被使用, 那么怎么保证这些数据的正确性呢? 所以 RAID 都会实现 Scrubbing 的机制, 一般都会定时去Scrub 所有的数据. 由于存储容量越来越大, Scrubbing 是个非常耗时的过程, 不过收益也是明显的.
Scrubbing 对数据的可靠性起到很大作用, 如果不能尽早的发现比如 URE 之类的错误, 那么当其他盘发生错误并需要 Rebuild 的时候, 就会导致数据丢失.
Rebuild 是所有 RAID 都需要处理的, 随着硬盘容量越来越大, 硬盘的 Throughput 却没有跟进, Rebuild 所需的时间越来越长, 从原来的几分钟到现在的几个小时甚至更久. 假设一块 4TB 的 HDD 在 Rebuild 的时候 Throughput 为 100MB/s, 那么 Rebuild 的时间为:
(4TB/100MB)s = 40000s = 11h复制这就导致在 Rebuild 的过程中另一块盘出现的概率大大增加, RAID 5 被淘汰就是这个原因, 有人甚至预测 RAID 6 在 2019 年也将被淘汰. 虽然预测不一定准确, 但是趋势已经建立. 那么除了通过使用更高的保护级别比如 RAID 7 之外, 有哪些方法可以减少 Rebuild 的时间?
一般来说想尽快完成一个任务, 可以有这么几种方法:
很多文档都有提到 Rebuild 的时间变长会加速 RAID 的 Data Loss, 比如 RAID 5 的情况, 因为只能容忍一块坏盘, 在 Rebuild 的时候再有一块坏盘就会导致 Data Loss. 那么 Rebuild 的时间跟另一个坏盘出现的概率到底有没有关系, 有什么关系?
如果绝大多数的错误都是因为 Bit Error, 而盘的 Bit Error Rate 也是确定的话, 比如 one in 10^16 bits, 这个只跟读出的数据量有关, 那么跟 Rebuild 的时长又有什么关系呢? Rebuild 的过程中可以认为大部分的 I/O 都是因为 Rebuild 产生的, 这部份不管 Rebuild 时长都是固定的. Rebuild 时间越长, 其他正常的数据访问会增多, 但这应该只占 I/O 的一小部份.
TODO: 我还是没有理解 Rebuild Time 和 MTTDL 之间的关系, 也不清楚 Bit Error Rate 在 MTTF, MTBF 占的比重.
References:
[1] http://queue.acm.org/detail.cfm?id=1670144
因为没有 Journal 的支持, 当 RAID 被 unclean shutdown, RAID 并不知道哪些 Stripe 已经同步过了哪些还没有, 就只能全盘进行 resync, 这个过程非常缓慢. 由于只有被更新过的 Stripe 才会出现不一致的 Stripe (其他 LSE 等错误通过 Scrubbing 来处理), 如果能够记住有哪些更新还不确定已经完成, 那么在重启后只需要有针对性地 resync 这些 Stripe. Write-Intent (WI) Bitmap 就是提供这个功能的, 它能够大幅度减少需要 resync 的内容, 主要在以下两种情况下起作用:
WI Bitmap 的实现也很简单, 先把硬盘按照 64MB (可配置)划分为一个个 Chunk, 只要对应的 Chunk 有数据要写, 就先把相应的 Bitmap 置位, 如果有更新需要把新的 Bitmap 写到硬盘 (对应代码在bitmap_unplug()), 这样就保证了不会漏了需要 sync 的 Stripe. 不过也带来个问题就是, 这可能引起额外的 I/O, 有的时候这个 Overhead 甚至可能很高, 所以需要根据实际情况调整 Chunk 的大小.
Chunklet RAID 是 HP 3Par 的技术, 区别于传统 RAID 的地方就是, 它先把硬盘按 1GB 大小划分成 Chunklets, 然后使用这些 Chunklet 来组 RAID. 从 Rebuild 的角度来看, 在某块盘出现问题的时候, 它有这些好处:
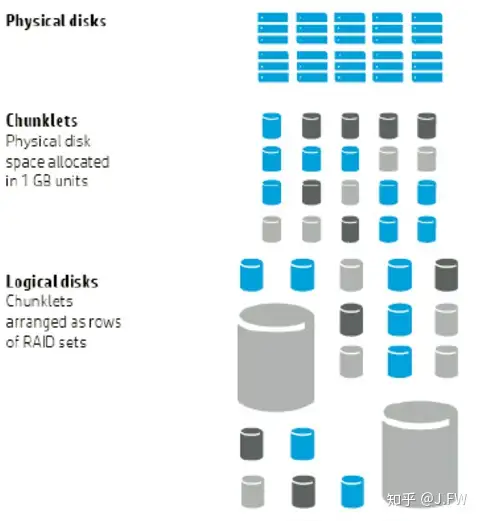
References:
[1] https://3pardude.com/2014/10/28/3par-chunklet-raid-architecture/
大部分 LSE 只是发生在某个或者几个块中, 硬盘的其他地方并没有问题, 但是当一块硬盘有一个 LSE 出现之后, 就可能会有越来越多的 LSE. 如果能够感知到这种情况, 并在硬盘完全报废之前就提前 Rebuild 到其他的 Spare 盘, 这样做有利于提高可靠性. 由于硬盘的大部分区域还是能够读取的, 就可以直接拷贝到 Spare 盘去, 从而省去 Rebuild 所需的 I/O 和计算.
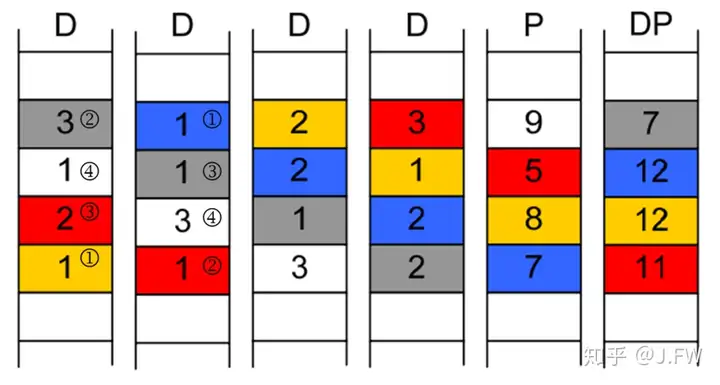
之前只是提到 RAID-DP 可以恢复两块坏盘, 其实对 Rebuild 也是可以改进的. 在 XtremIO 的对角线 RAID 的实现中, 他们提供了一种减少办法来减少所需的 I/O 个数. 如下图, D0 坏了需要修复, 那么可以按照方块右上角的顺序读入相应的数据并恢复 D0 对应的数据. 如果正常使用 D1-4, P 来修复的话,需要 4*5=20 次 I/O, 但这里只需要 14 次.
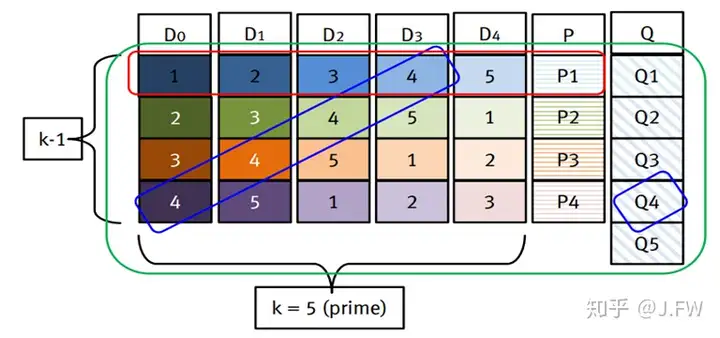
References:
[1] http://www.emc.com/collateral/white-paper/h13036-wp-xtremio-data-protection.pdf
SSD 因为性能上的巨大优势, 大有取代 HDD 之势. RAID 的这些特性同样适用于 SSD, 不过 SSD 有其特殊之处, 把传统的 RAID 直接或稍加修改应用到 SSD, 或者不能够最大限度的发挥 SSD 的能力, 或者暴露出 SSD 的劣势. 所以在 SSD 上应用 RAID, 首先需要了解 SSD 的特点:
我们都知道 RAID 里面的 I 指的是 Independent, 因为如果 RAID 组里面的硬盘是相关的话, 要坏一起坏, 那么再强的 RAID 级别也没有什么作用. 虽然说绝对的 Independent 很难做到, HDD RAID 的相关性至少还是比较小的. 可是对于 SSD 就是另外一回事了, 同一批次的 SSD 有着几乎相同的 P/E cycles, 而且传统 RAID 有意地把 I/O 均匀分配到每块盘上, 所以导致的结果就是所有的 SSD 都是接近的健康状态 (我能想到最浪漫的事, 就是和你一起慢慢变老:). Differential RAID 就是要解决这个问题. Diff RAID 通过控制 Parity 的分布来控制盘的 Aging, 因为每个随机[小]写都会导致 Parity 的更新, 所以 Parity 多的盘也就老的更快. 通过把不同 SSD 的寿命控制在不同 Level 上面, 通过有序地换盘来保持 RAID 的可靠性.
有人觉得盘一块一块换比较好, 也有人觉得一起换比较好, 也就是说把所有的盘都榨干了再换批新盘就好了, 当然了这个切换过程就不是 RAID 控制了. WeLe-RAID 就是这么想的.
Diff RAID 的核心是通过 Parity 来控制不同盘的 Aging, 这里面隐含了一个前提就是, 该 RAID Array 上有大量的 Partial Stripe Write, 如果都是 Full Stripe Write 的话, 每次写操作都会更新所有的盘, 不论数据盘还是校验盘, 也就是这种算法就会失效. 所以这种算法在软 RAID 上可能有意义, 所有的 All Flash Array 都会对尽量优化掉小写.
References:
[1] http://pages.cs.wisc.edu/~kadav/new/pdfs/diffraid-hs09.pdf
[2] http://link.springer.com/chapter/10.1007%2F978-3-642-24403-2_20#page-1
大部分主流的 All Flash Array (AFA) 产品, 包括 XtremIO, SolidFire 和 PureStorage, 都会集成压缩和去重的功能. 压缩和去重一般需要耗费更多的计算和 I/O, 特别是随机读操作, SSD 刚好擅长这方面. 所以虽然压缩和去重在 Backup to HDD 领域已经广泛应用, 但是在 Primary Storage 却很少应用到 HDD 上, 因为 HDD 的随机读性能跟不上. 压缩和去重的效果可以参考一下 SolidFire 的白皮书:

至于怎么去实现 Deduplication, 大部分厂商使用的技术跟 Backup 领域并没有什么太大区别.
References:
[1] http://info.solidfire.com/rs/538-SKP-058/images/SolidFire-Data-Efficiencies-Breif.pdf
这里列举了一些 AFA 实现中有意思的想法:
虽然 RAID 5 已经很少用了, RAID 6 在流行了多年以后也慢慢变得不堪重负, 但是通过增加冗余的思想来提高数据的可靠性肯定会一直存在