https://zhuanlan.zhihu.com/p/375686108复制
2021年4月,英特尔(Intel)正式推出代号Ice Lake-SP的双路处理器,与2020年6月中旬发布、代号Cooper Lake-SP的四至八路处理器,共同构成第三代至强可扩展处理器(3rd Gen Intel Xeon Scalable processor)家族。

与前两代相比,第三代至强可扩展处理器最主要的任务,就是增加服务器的CPU核芯数,并直接从最少8核芯的银牌系列起步,去掉了核芯数最少的铜牌系列。
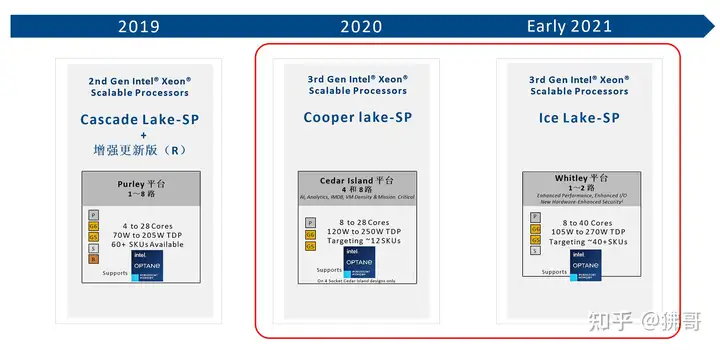
注意中间有字母的小色块,第三代至强可扩展处理器家族已经没了铜牌(Bronze)系列
但是,4~8路的Cooper Lake-SP,和1~2路的Ice Lake-SP,增加核数的方式,全然不同——因为它们本来就不是一回事儿,从制程到架构都不一样。
Cooper Lake-SP与前代Cascade Lake-SP一样采用14纳米制程、最多28核芯56线程,旨在以四路替代双路,用更多的CPU提供更多的核芯。
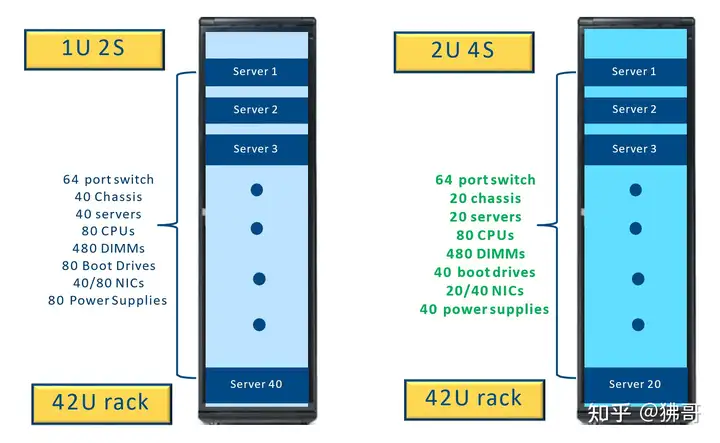
四路替代双路,提供同样核心所用的服务器和网络设备等都减少,意味着需要管理的设备变少,机柜成本也下降
这种思路可以看作是第二代至强可扩展处理器家族中Platinum 9200系列的延续。代号Cascade Lake-AP的至强Platinum 9200系列,采用把2个28核die封装在一起的MCM(MultiChip Module,多芯片模块)方式,将单个CPU的核芯数量增加到56个。所以,2个Platinum 9200系列处理器组成的双CPU系统,本质上还是用UPI(Ultra Path Interconnect)互连起来的四路平台,只不过两两封装为一体(胶水)而已。
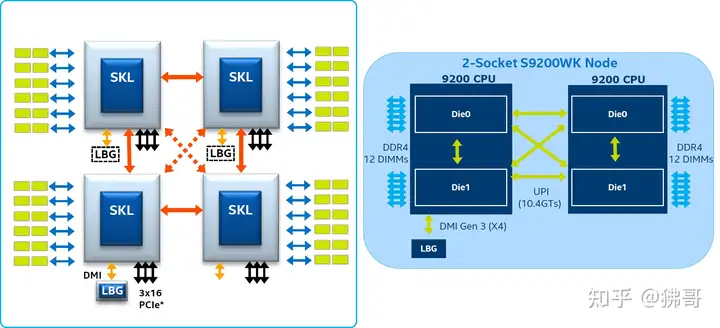
把2个全核die封装在一起的一大弊端,就是CPU的热设计功耗(Thermal Design Power,TDP)飙升到350~400W,对服务器的散热设计提出了更高的要求,1U的紧凑型平台,基本要标配(冷板式)液冷了。
在第二代至强可扩展处理器推出的2019年,英特尔已经在推动2U四路服务器设计。继而,在2020年推出四路起步的Cooper Lake-SP,在10nm制程到位前,先以四路堆积更多的核数,抵御竞争对手双路系统的攻势。

采用散热器高低、纵横搭配(低的为T型,将CPU发出的热量通过热管导出到横向的远程散热片,增大散热面积)来解决四路CPU散热问题的2U服务器。基于这一类2U四路服务器产品,阿里云等服务商在2020年推出了基于Cooper Lake-SP的新一代云计算实例
4个CPU要(在整体性上)抗衡2个CPU,就需要强化CPU之间的通信,所以每处理器的UPI数量,从Cascade Lake-SP(CLX)的3个,倍增至Cooper Lake-SP(CPX)的6个,四路系统中任意2个CPU之间都有2条UPI直连。PCIe的规格和数量不变,内存也仍然是(每CPU)6通道,只有规格“与时俱进”,提升到DDR4 3200。

Ice Lake-SP(ICX)终于用上了10纳米制程,单个CPU(die)的核芯数量从28个增至40个,相应的,I/O能力也有不同程度的增长:
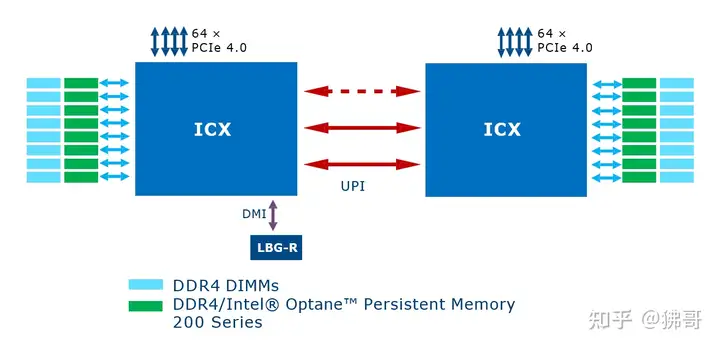
核芯、内存通道、PCIe等数量的增加,都要从至强可扩展处理器的2D Mesh架构说起。
前两代至强可扩展处理器(Skylake-SP和Cascade Lake-SP),都是6×6的2D Mesh,UPI和PCIe等互连单元占去一条边上的6个,再减去网格另外两条边上的各一个3通道内存控制器,剩下正好是28个(36 - 6 - 2)核芯。

每CPU两侧各8个DIMM插槽(双路就是两个CPU之间16个)是Ice Lake-SP平台相比前代的主要外观特征
要增加CPU的核心数,就要扩大2D Mesh的网格规模。Ice Lake-SP增加了1行2列,变成7×8的网格架构。
2D Mesh架构有两大特点:

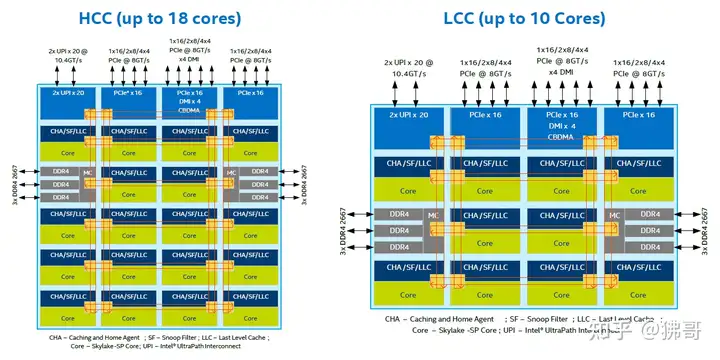
Skylake的6×6矩阵(XCC)
所以,如果核芯数量不是很多,矩阵的规模小一些会比较好。譬如第一代至强可扩展处理器(Skylake-SP),就有XCC(eXtreme Core Count,最多核or极多核)、HCC(High CC,高内核数)和LCC(Low CC,低内核数)之分:
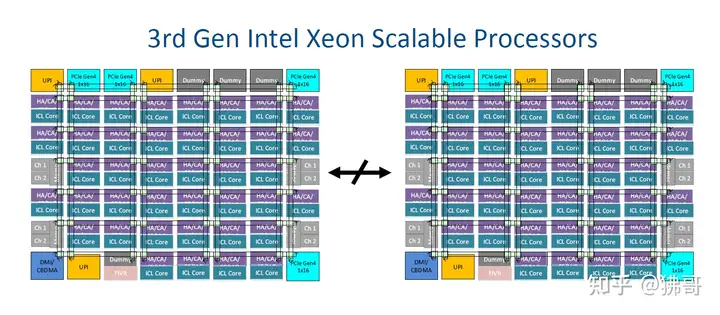
Ice Lake-SP也有XCC和HCC之分,我还没看到HCC的架构(也许就是之前的6×6?),但XCC应该是7×8无疑。下面就以两个XCC的完全体简单对比一下。
Skylake-SP/Cascade Lake-SP的I/O单元都集中在矩阵的一半(里的边缘位置),另一半(6×3)的18个全都是核芯,离内存控制器仍不算远,因为矩阵的规模不大。

Ice Lake-SP采用Sunny Cove微架构,新的核芯功能更强大,L1和L2 Cache容量也更大,IPC性能据称有20%的提升
Ice Lake-SP则把矩阵的4条边都用上,一方面是可以容纳增加的I/O单元(如内存控制器),一方面让I/O单元(如PCIe和UPI)的分布更为均匀。Skylake-SP/Cascade Lake-SP有一条边完全不布置CPU核芯的做法得以延续,哪怕是放上了3个占位的Dummy,而不是用来把核芯数量扩展到43个——或许42个更为合适,因为紧邻UPI单元的那个(Dummy位)离内存控制器过于遥远。

6×6 → 7×8,红框内可理解为增加的12个核心
如果把这3个Dummy位换成核芯,会拖累整个CPU的平均内存访问时延,拉开与Cascade Lake-SP的差距。现在已经有40个核芯了,再增加2~3个的意义,不是很大。
可以简单的认为,与Skylake-SP/Cascade Lake-SP相比,Ice Lake-SP净增了两列6个核心(6×2),也就是40与28的差值。
既然顶着“第三代至强可扩展处理器”名头的是两种差异很大的产品,那么,从型号上怎么区分Ice Lake-SP和Cooper Lake-SP呢?
至强可扩展处理器的命名规则并没有变,它只是“扩展”了:在4位数字后面的字母后缀,如果有H,就代表适用四路和八路平台的Cooper Lake-SP,目前共有10余款,分属铂金和金牌系列,包括一些后缀为HL的机型。
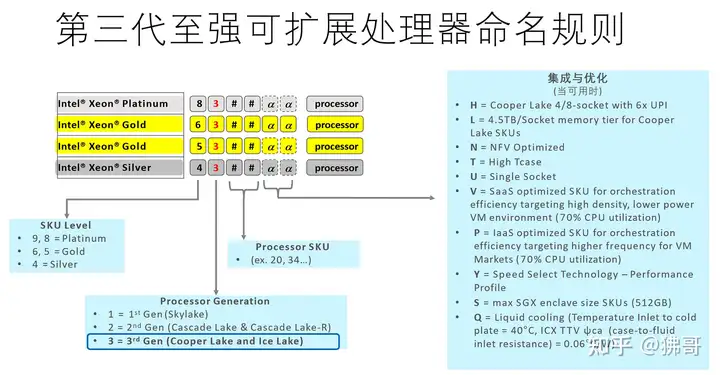
L代表每插槽可以支持4.5TB内存的大内存型Cooper Lake-SP,而Ice Lake-SP每插槽可以支持多达6TB内存——当然,这些都需要傲腾持久内存的配合。

然后是为不同应用场景优化的Ice Lake-SP产品。
先看不带后缀的,包括4款铂金系列,核心数量从32到40不等,L3 Cache最大60MB,热设计功耗在250~270瓦(W)之间。
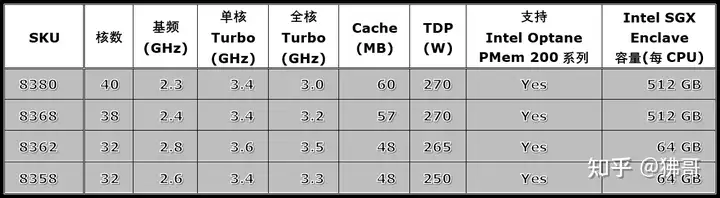
8款金牌6系列和2款金牌5系列,其中有高基频、核数少的6334,也有频率较低而核数多的6338和6330。
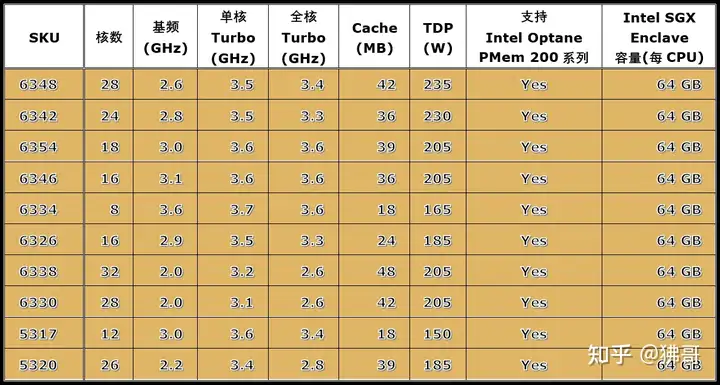
傲腾持久内存PMem 200系列在第三代至强可扩展处理器家族得到了广泛支持,银牌系列除外——只有1款支持。
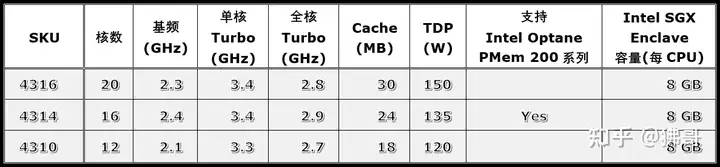
Y后缀代表支持Intel Speed Select Technology - Performance Profile 2.0 (Intel SST-PP) ,可以理解为一种更全面的变频技术。

N后缀代表为网络和NFV应用优化,核数较多,频率变化灵活,其中5318N还兼具Y后缀的特性。
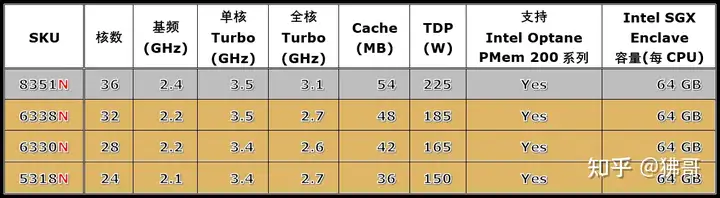
T后缀代表长生命周期(10年)和NEBS热设计友好,Tcase温度高,适合电信行业应用。

还有两款为云计算的虚拟机应用优化,都具有较多的核数。其中:

8352V还兼具Y后缀的特性。
14nm的Cooper Lake-SP最大TDP已经达到250W,10nm的Ice Lake-SP在大幅增加核芯数量之后来到了270W,下一代就奔着350W去了,液冷越来越接近必选项。

Q后缀即代表为液冷环境优化,与核数、Cache容量和TDP相同的8368相比,8368Q的运行频率要高100~300MHz,初步体现了液冷加持的效果。
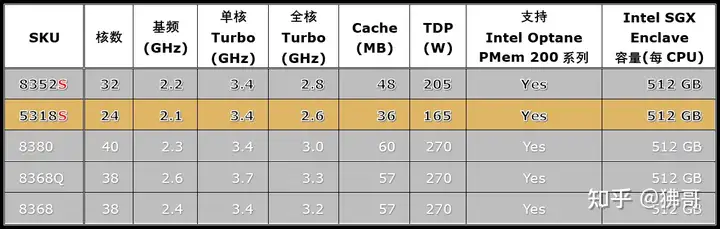
S后缀代表为SGX(Software Guard Extensions)提供最大的“飞地”(enclave)存储空间,单CPU可达512GB,双路系统就是1TB,不带S后缀的8380、8368和8368Q也在此列。

M后缀代表为AI处理和媒体工作负载优化,8352M运行频率不算高,在32核产品中是TDP最低的一档。

U后缀代表单路型,8351N也属于这类产品。