https://zhuanlan.zhihu.com/p/156761279复制
最近在性能压测时总是触发系统主动throttling, 我们都知道throttling是系统自我保护的一种手段, 大方向上可以认为这是期望的结果. 如果止步于认为这是正常现象, 就会错失很多精彩, 现象背后的逻辑是什么? 理清了背后的逻辑, 是不是还可能发现优化的空间? 我们可以有一个看似正确的逻辑推断, 但最后的分析一定要落到实处.
测试对象是一个典型的分布式块存储服务, 用户请求发往leader节点, leader通过一致性协议将该请求转发到2个replica上, 当系统达成多数派后, 也就是3节点有2个节点已经持久化完成(3-2), leader就可以返回客户端成功, 在3节点都持久化完成后(3-3), 该请求的状态机完全结束.
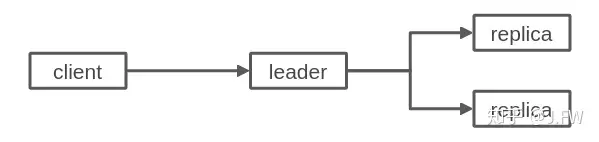
有多种场景可以触发throttling, 比如为了控制系统中还未响应(没有达成3-2)的请求数, 这种请求数太多的时候就会触发throttling, 在压测环境下这种情况很少发生, 经过一些简单的分析, 触发throttling的原因是有太多的请求已经达成3-2, 但是还未达成3-3. 这种throttling的必要性在于未完成3-3的请求还要继续占有资源, 另外这种请求往往意味着2个replica处理能力不匹配, 如果不进行throttling, 那么同步延迟可能会越来越大.
用较简单的步骤/环境复现问题是分析中很重要的一步, 这里将leader和2个replica放在同一台机器上仍能复现出相同的问题, 这就很大程度上排除了很多环境的因素, 比如leader到2个replica上的rdma网络状况是否不同. 为了进一步简化问题, 我们把replica上的处理逻辑进一步简化, 这样2个replica的处理能力几乎完全相同:
另外通过fio可以验证, optane上的写清求可能发生乱序, 也就是先发的请求完成时间却更晚, 但这个概率非常小, 并且即使发生了乱序, 也是在少数几个io之间, 不会出现大范围的乱序.
我们将分布式存储抽象成2条队列:
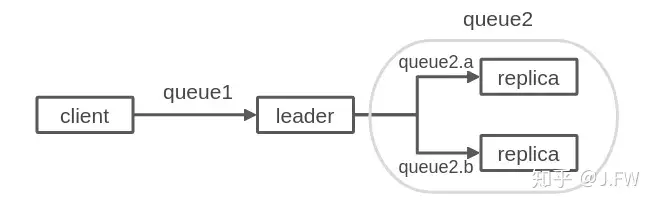
这里因为queue1和queue2的服务时间相差较大, 所以很容易想到请求会积压在queue2上. 这里需要注意的是怎么衡量server的服务时间, 以replica server为例, 如果把服务时间算成leader发出请求到收到响应, 那是不对的, 因为这里面还有排队时间.
2个replica只要处理能力不一样, 如果没有外部的throttling等因素, 按照排队论慢的那个replica必然会出现队列堆积, 因为压测时的上限是由快的replica决定的, 快的都已经打满, 慢的必然堆积.
是否排队主要取决于以下因素:
上面3个因素中, 服务达到时间是2个replica最可能的不同点.
现在很多系统为了降低延迟和提高吞吐,往往通过用户态的polling来取代内核的通知机制, 一个server可能是这个样子:
while (1) {
rdma->poll();
aio->poll();
others->poll();
}复制当rdma poll结束之后, 会继续运行aio, others等等的poll函数. 因为是单线程的, 直至下次rdma poll之前, 这段时间内新的rdma请求并没有取出, rdma接收端的receive window没更新直接就导致了rdma发送端必须停止发送. 另一方面, server都是能够同时处理多个请求的, 一次poll的请求如果不够, 相当于浪费了server的处理能力. 解决方法本身相对简单.