https://zhuanlan.zhihu.com/p/454928730复制
最近在做某国产化平台相关的适配, 不管NUMA的性能和实现方式都和Intel有较大不同, 作为比较对象, 理解Intel的NUMA实现是很有必要的. 虽然从软件角度, 打开NUMA会带来额外的复杂度, 但是从硬件角度, 关闭NUMA其实更复杂, 本文尝试分析关闭NUMA时Intel平台的内存编址.
Interleaving是一种基本的编址方式, 可以将连续的物理内存地址映射到不同的内存模块, 比如[0, 256)映射到模块0, [256, 512)映射到模块1, 物理内存分配一般以4KB或者更大粒度的页为分配单位, 这样即使是单线程的程序也能充分发挥底层内存模块的并发性. Interleaving按照内存的层次一般分为Socket, Channel和Rank等, DIY过电脑的同学可能还记得双通道, 也就是Channel Interleaving, 本文主要关心Socket Interleaving, 也就是关闭NUMA时的内存编址. Interleaving的基本思想见下图:
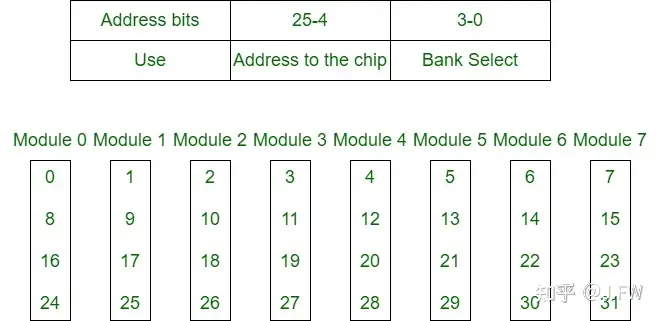
这里以Intel(R) Xeon(R) CPU E5-2682 v4为例, 基于Broadwell EP架构, 其他Intel的CPU应该大致相同. 测试机器插了2个CPU, 内存Interleaving的信息可以从对应的PCI配置空间拿到, 具体到Broadwell EP, 其PCI设备地址是固定的.
#xxd /sys/bus/pci/devices/0000:ff:0f.4/config
0000000: 8680 fc6f 0000 0000 0100 8008 0000 8000 ...o............
0000010: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000020: 0000 0000 0000 0000 0000 0000 8680 e06f ...............o
0000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000040: 1111 1111 1111 1100 0000 0000 0000 0000 ................
0000050: 0000 0000 0000 0000 0000 0000 0000 0000 ................
0000060: c107 0804 0044 1155 c007 0804 0000 0000 .....D.U........
0000070: c007 0804 0000 0000 c007 0804 0000 0000 ................
0000080: c007 0804 0000 0000 c007 0804 0000 0000 ................
0000090: c007 0804 0000 0000 c007 0804 0000 0000 ................
00000a0: c007 0804 0000 0000 c007 0804 0000 0000 ................
00000b0: c007 0804 0000 0000 c007 0804 0000 0000 ................
00000c0: c007 0804 0000 0000 c007 0804 0000 0000 ................
00000d0: c007 0804 0000 0000 c007 0804 0000 0000 ................
00000e0: c007 0804 0000 0000 c007 0804 0000 0000 ................
00000f0: c007 0804 0000 0000 c007 0804 0000 0000 ................复制Interleaving的信息从地址0x60开始, 具体格式如下, 因为当前机器内存插法是balanced, 只有一个有效region.
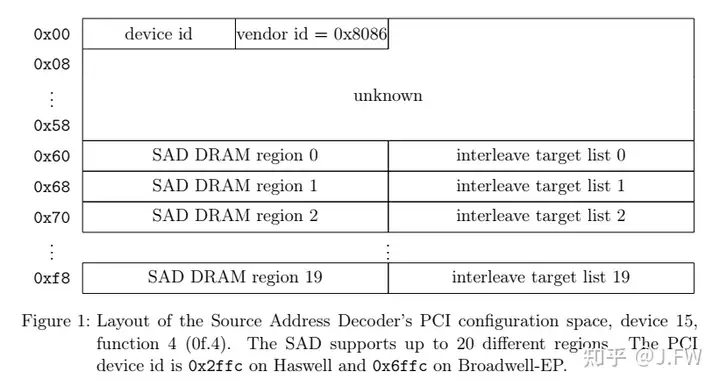
继续看其中SAD region的编码:

这里只有一个有效SAD Region, 它的值为c107 0804, 我们来计算一下上面的这些值:
再来看一下target list的编码, target list用于找到内存地址对应的numa node.

这样我们知道0044 1155对应到的8个target分别是{0, 0, 0, 0, 1, 1, 1, 1}. 从这个角度看, 这款CPU至多能支持到8个NUMA node.
最后看下该机器使用哪些地址位来决定:

这样我们知道当前配置使用地址位a18, a17, a16以及a8, a7, a9来决定物理地址到NUMA node的映射关系.
为了验证上面的理论, 我们设计一个测试程序:
int main()
{
const size_t sz = 4ULL * 1024 * 1024 * 1024;
void *buf = mmap(NULL, sz, PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS | MAP_HUGETLB, -1, 0);
size_t i = 0, j = 0;
size_t setsz = 1<<8; // a8 decides socket index
while (1) {
for (i = 0; i < sz; i += 1<<19) {
for (j = 0; j < 1<<16; j += 1<<9) {
memset(buf + i + j, 0, setsz);
}
}
}
munmap(buf, sz);
return 0;
}复制上面程序执行时, 用pcm-memory.x观察可以验证上面的分析
另外也可以看到, 即使在socket 1上没有写流量, 还是有和socket 0上接近的读流量, 而且这些读流量是该测试引起的, 也就是发生了预读, 只不过这些预读都是无效的.
|---------------------------------------||---------------------------------------|
|-- Socket 0 --||-- Socket 1 --|
|---------------------------------------||---------------------------------------|
|-- Memory Channel Monitoring --||-- Memory Channel Monitoring --|
|---------------------------------------||---------------------------------------|
|-- Mem Ch 0: Reads (MB/s): 652.12 --||-- Mem Ch 0: Reads (MB/s): 642.34 --|
|-- Writes(MB/s): 629.02 --||-- Writes(MB/s): 68.15 --|
|-- Mem Ch 1: Reads (MB/s): 636.40 --||-- Mem Ch 1: Reads (MB/s): 628.23 --|
|-- Writes(MB/s): 613.17 --||-- Writes(MB/s): 54.10 --|
|-- Mem Ch 2: Reads (MB/s): 651.87 --||-- Mem Ch 2: Reads (MB/s): 644.78 --|
|-- Writes(MB/s): 628.28 --||-- Writes(MB/s): 67.77 --|
|-- Mem Ch 3: Reads (MB/s): 638.41 --||-- Mem Ch 3: Reads (MB/s): 628.78 --|
|-- Writes(MB/s): 615.29 --||-- Writes(MB/s): 51.96 --|
|-- NODE 0 Mem Read (MB/s) : 2578.80 --||-- NODE 1 Mem Read (MB/s) : 2544.13 --|
|-- NODE 0 Mem Write(MB/s) : 2485.77 --||-- NODE 1 Mem Write(MB/s) : 241.98 --|
|-- NODE 0 P. Write (T/s): 502663 --||-- NODE 1 P. Write (T/s): 532451 --|
|-- NODE 0 Memory (MB/s): 5064.57 --||-- NODE 1 Memory (MB/s): 2786.11 --|
|---------------------------------------||---------------------------------------|
|---------------------------------------||---------------------------------------|
|-- System Read Throughput(MB/s): 5122.93 --|
|-- System Write Throughput(MB/s): 2727.74 --|
|-- System Memory Throughput(MB/s): 7850.68 --|
|---------------------------------------||---------------------------------------|
复制综上我们验证了在Intel的机器上, 连续的物理地址以较小粒度分布在不同的socket上, 测试机上是256B, 最小可以配置到64B的粒度. 应用程序向OS申请内存的最小单元是4KB的page, 该page必然会分布到多个socket上, 一般情况下应用访存会相对均匀地分布在不同socket, 反应到应用的性能上就显得比开NUMA更加稳定, 上面的测试用例是有意为之, 访存在socket间并不均匀.
当我们知道Intel的关NUMA实现后, 很容易有先入为主的想法, 以为其他平台也是类似实现, 但是因为各种原因, NUMA的实现往往差别很大, 这个以后再说.