介绍
寄存器
最靠近 CPU 的控制单元和逻辑计算单元的存储器,就是寄存器了,它使用的材料速度也是最快的,因此价格也是最贵的,那么数量不能很多。
存储器的数量通常在几十到几百之间,每个寄存器可以用来存储一定的字节(byte)的数据。比如:
- 32 位 CPU 中大多数寄存器可以存储 4 个字节;
- 64 位 CPU 中大多数寄存器可以存储 8 个字节。
寄存器的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写,CPU 时钟周期跟 CPU 主频息息相关,比如 2 GHz 主频的 CPU,那么它的时钟周期就是 1/2G,也就是 0.5ns(纳秒)。
CPU 处理一条指令的时候,除了读写寄存器,还需要解码指令、控制指令执行和计算。如果寄存器的速度太慢,则会拉长指令的处理周期,从而给用户的感觉,就是电脑「很慢」。
CPU Cache
CPU Cache 用的是一种叫 SRAM(Static Random-Access Memory,静态随机存储器) 的芯片。
SRAM 之所以叫「静态」存储器,是因为只要有电,数据就可以保持存在,而一旦断电,数据就会丢失了。
在 SRAM 里面,一个 bit 的数据,通常需要 6 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间下,能存储的数据是有限的,不过也因为 SRAM 的电路简单,所以访问速度非常快。
CPU 的高速缓存,通常可以分为 L1、L2、L3 这样的三层高速缓存,也称为一级缓存、二次缓存、三次缓存。

L1 高速缓存
L1 高速缓存的访问速度几乎和寄存器一样快,通常只需要 2~4 个时钟周期,而大小在几十 KB 到几百 KB 不等。
每个 CPU 核心都有一块属于自己的 L1 高速缓存,指令和数据在 L1 是分开存放的,所以 L1 高速缓存通常分成指令缓存和数据缓存。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L1 Cache 「数据」缓存的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index0/size 32K复制
而查看 L1 Cache 「指令」缓存的容量大小,则是:
$ cat /sys/devices/system/cpu/cpu0/cache/index1/size 32K复制
L2 高速缓存
L2 高速缓存同样每个 CPU 核心都有,但是 L2 高速缓存位置比 L1 高速缓存距离 CPU 核心 更远,它大小比 L1 高速缓存更大,CPU 型号不同大小也就不同,通常大小在几百 KB 到几 MB 不等,访问速度则更慢,速度在 10~20 个时钟周期。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L2 Cache 的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index2/size 256K复制
L3 高速缓存
L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,大小也会更大些,通常大小在几 MB 到几十 MB 不等,具体值根据 CPU 型号而定。
访问速度相对也比较慢一些,访问速度在 20~60个时钟周期。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L3 Cache 的容量大小:
$ cat /sys/devices/system/cpu/cpu0/cache/index3/size 3072K复制
内存
内存用的芯片和 CPU Cache 有所不同,它使用的是一种叫作 DRAM (Dynamic Random Access Memory,动态随机存取存储器) 的芯片。
相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造价比 SRAM 芯片便宜很多。
DRAM 存储一个 bit 数据,只需要一个晶体管和一个电容就能存储,但是因为数据会被存储在电容里,电容会不断漏电,所以需要「定时刷新」电容,才能保证数据不会被丢失,这就是 DRAM 之所以被称为「动态」存储器的原因,只有不断刷新,数据才能被存储起来。
DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问的速度会更慢,内存速度大概在 200~300 个 时钟周期之间。
SSD/HDD 硬盘
SSD(Solid-state disk) 就是我们常说的固体硬盘,结构和内存类似,但是它相比内存的优点是断电后数据还是存在的,而内存、寄存器、高速缓存断电后数据都会丢失。内存的读写速度比 SSD 大概快 10~1000 倍。
当然,还有一款传统的硬盘,也就是机械硬盘(Hard Disk Drive, HDD),它是通过物理读写的方式来访问数据的,因此它访问速度是非常慢的,它的速度比内存慢 10W 倍左右。
由于 SSD 的价格快接近机械硬盘了,因此机械硬盘已经逐渐被 SSD 替代了。
存储器的层次关系
现代的一台计算机,都用上了 CPU Cahce、内存、到 SSD 或 HDD 硬盘这些存储器设备了。
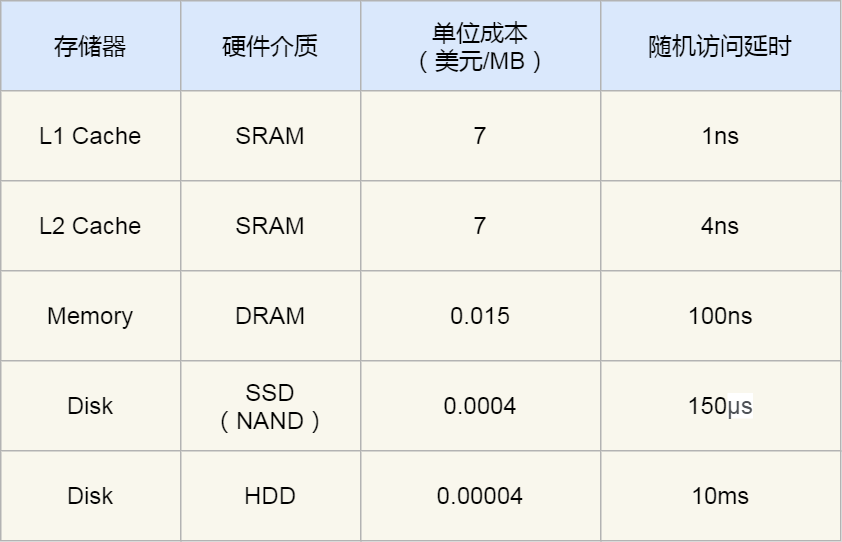
其中,存储空间越大的存储器设备,其访问速度越慢,所需成本也相对越少。
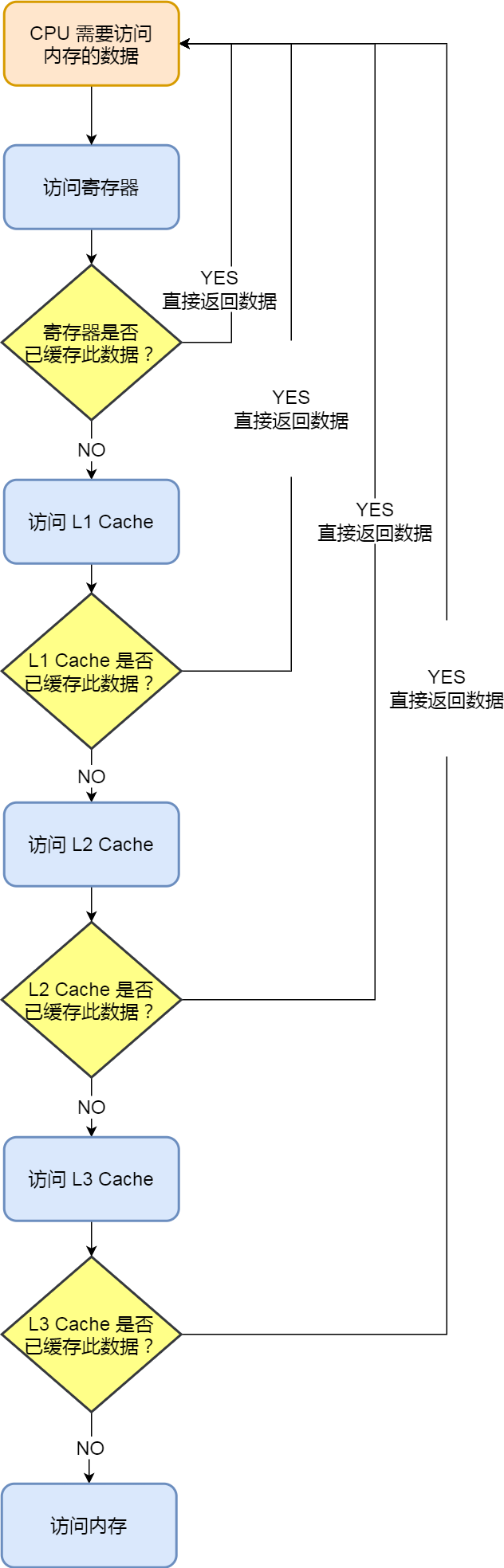
CPU 并不会直接和每一种存储器设备直接打交道,而是每一种存储器设备只和它相邻的存储器设备打交道。
比如,CPU Cache 的数据是从内存加载过来的,写回数据的时候也只写回到内存,CPU Cache 不会直接把数据写到硬盘,也不会直接从硬盘加载数据,而是先加载到内存,再从内存加载到 CPU Cache 中。

所以,每个存储器只和相邻的一层存储器设备打交道,并且存储设备为了追求更快的速度,所需的材料成本必然也是更高,也正因为成本太高,所以 CPU 内部的寄存器、L1\L2\L3 Cache 只好用较小的容量,相反内存、硬盘则可用更大的容量,这就我们今天所说的存储器层次结构。
另外,当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据。
速度比较
L1 cache reference ......................... 0.5 ns Branch mispredict ............................ 5 ns L2 cache reference ........................... 7 ns Mutex lock/unlock ........................... 25 ns Main memory reference ...................... 100 ns Compress 1K bytes with Zippy ............. 3,000 ns = 3 µs Send 2K bytes over 1 Gbps network ....... 20,000 ns = 20 µs SSD random read ........................ 150,000 ns = 150 µs Read 1 MB sequentially from memory ..... 250,000 ns = 250 µs Round trip within same datacenter ...... 500,000 ns = 0.5 ms Read 1 MB sequentially from SSD* ..... 1,000,000 ns = 1 ms Disk seek ........................... 10,000,000 ns = 10 ms Read 1 MB sequentially from disk .... 20,000,000 ns = 20 ms Send packet CA->Netherlands->CA .... 150,000,000 ns = 150 ms复制
CPU L1 Cache 随机访问延时是 1 纳秒,内存则是 100 纳秒,所以 CPU L1 Cache 比内存快 100 倍左右。
SSD 随机访问延时是 150 微妙,所以 CPU L1 Cache 比 SSD 快 150000 倍左右。
最慢的机械硬盘随机访问延时已经高达 10 毫秒,我们来看看机械硬盘到底有多「龟速」:
- SSD 比机械硬盘快 70 倍左右;
- 内存比机械硬盘快 100000 倍左右,即 10W 倍;
- CPU L1 Cache 比机械硬盘快 10000000 倍左右,即 1000W倍;
性能分析
先来看看 CPU 的速度,就拿我的电脑来说,主频是 2.6G,也就是说每秒可以执行 2.6*10^9 个指令,每个指令只需要 0.38ns(现在很多个人计算机的主频要比这个高,配置比较高的能达到 3.0G+)。
一级缓存读取时间为 0.5ns,它的速度可以赶上 CPU,程序本身的 locality 特性加上指令层级上的优化,cache 访问的命中率很高,这最终能极大提高效率。
分支预测错误需要耗时 5ns,换算成人类时间大约是 13s,这个就有点久了,所以你会看到很多文章分析如何优化代码来降低分支预测的几率。所以if和switch判断时概率大的放上面可以提高性能。(微乎其微的提升,但是也要注意)
二级缓存时间就比较久了,大约在 7ns,可以看到的是如果一级缓存没有命中,然后去二级缓存读取数据,时间差了一个数量级。
互斥锁的加锁和解锁时间需要 25ns。
然后就到了内存,每次内存寻址需要 100ns。
一次 CPU 上下文切换(系统调用)需要大约 1500ns,也就是 1.5us(采用的是单核 CPU 线程平均时间)我们也知道上下文切换是很耗时的行为,毕竟每次浪费一个小时,也很让人有罪恶感的。上下文切换更恐怖的事情在于,这段时间里 CPU 没有做任何有用的计算,只是切换了两个不同进程的寄存器和内存状态;而且这个过程还破坏了缓存,让后续的计算更加耗时。
在 1Gbps 的网络上传输 2K 的数据需要 20us,可以看到网络上非常少数据传输对于 CPU 来说,已经很漫长。而且这里的时间还是理论最大值,实际过程还要更慢一些。
SSD 随机读取耗时为 150us,虽然我们知道 SSD 要比机械硬盘快很多,但是这个速度对于 CPU 来说也是像乌龟一样。I/O 设备 从硬盘开始速度开始变得漫长,这个时候我们就想起内存的好处了。尽量减少 IO 设备的读写,把最常用的数据放到内存中作为缓存是所有程序的通识。像 memcached 和 redis 这样的高速缓存系统近几年的异军突起,就是解决了这里的问题。
从内存中读取 1MB 的连续数据,耗时大约为 250us。
同一个数据中心网络上跑一个来回需要 0.5ms,如果你的程序有段代码需要和数据中心的其他服务器交互,在这段时间里 CPU 都已经狂做了半个月的运算。减少不同服务组件的网络请求,是性能优化的一大课题。
从 SSD 读取 1MB 的顺序数据,大约需要 1ms,SSD 读一个普通的文件,如果要等你做完,CPU 一个月时间就荒废了。尽管如此,SSD 已经很快啦,不信你看下面机械磁盘的表现。
磁盘寻址时间为 10ms,机械硬盘使用 RPM(Revolutions Per Minute/每分钟转速) 来评估磁盘的性能:RPM 越大,平均寻址时间更短,磁盘性能越好。寻址只是把磁头移动到正确的磁道上,然后才能读取指定扇区的内容。换句话说,寻址虽然很浪费时间,但其实它并没有办任何的正事(读取磁盘内容)。
从磁盘读取 1MB 连续数据需要 20ms,O 设备是计算机系统的瓶颈。
而从世界上不同城市网络上走一个来回,平均需要 150ms,不难理解,所有的程序和架构都会尽量避免不同城市甚至是跨国家的网络访问,CDN就是这个问题的一个解决方案:让用户和最接近自己的服务器交互,从而减少网络上报文的传输时间。