https://zhuanlan.zhihu.com/p/138888453复制
EXT3 has been infamous for its slowness in our product for a long time, it's heard many times we should upgrade to a more modern filesystem such as EXT4. Since it is the interface of I/O stack to the users, it is reasonable to blame EXT3 when we encountered the slow response from filesystem. However, without any thorough understanding of the problem, it is too soon to draw a correct conclusion. After all, there are many layers on I/O stack, and filesystem is just one of them, so we'd better to have a thorough look at the whole stack, from the application layer down to the disk. The simplified IO stack is as follows:
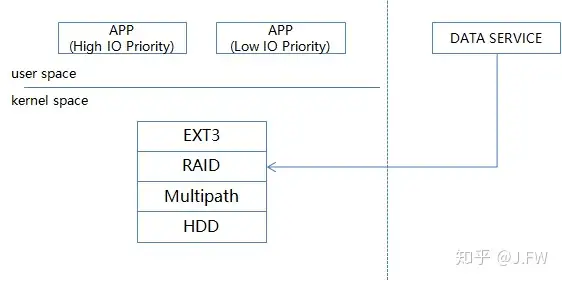
The IO stack has the following layers, from the bottom up:
The data service on the right is not our focus here, the userspace applications on the left fall into two catagories, we should try best to satisify the one with high IO priority or the custom might be impacted, the others such as tar the log files are of low impact.
One thing not mentioned yet is that a NVRAM is used for performance, HDD itself cannot afford the required performance.
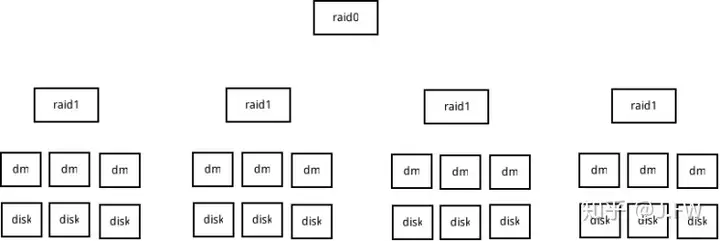
The RAID for the APP is as follows:
The access time of HDD is a measure of the time it takes before the drive can actually transfer data. It is composed of 2 parts typically, the seek time and rotational latency. Usually I/O scheduler attempts to merge and dispatch the I/O requests in a specific order in order to the reduce the seek and rotational time. However, nowadays even with the sequential I/O, the performance of inside and outside track are not the same as the bit density is constant so that the long outside tracks have more bits than inside tracks, then outside tracks have better performance.
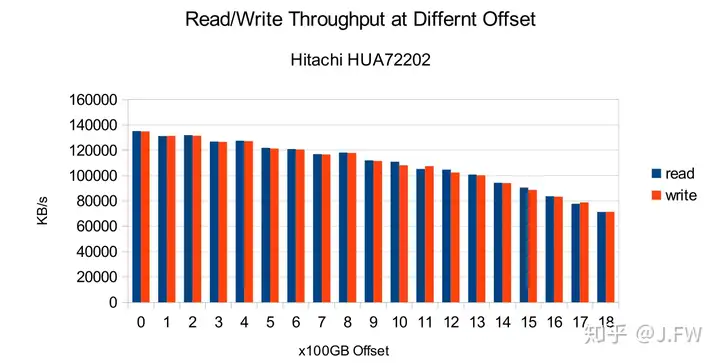
From the test results, it's clear that the throughput varies a lot at the different offset, we should take this into consideration if throughput matters.
Now we know the disk performance characteristic, the next step is to understand it across the whole I/O stack. As we are testing the sequential I/O, the ideal throughput of the filesystem can be calculated with this formula:
We call the raid1 above subarray, and raid0 array. In our RAID, there is an extra sector for each stripe unit, so for the 4KB (8 sectors) stripe unit, it has to access 9 sectors.

We can draw these conclusions according to the test results above:
The stripe unit size of raid1 is 4KB. In order to service the requests larger than the SU size, raid1 breaks them into 4KB pieces, then submits them individually. So the plugging mechanism in block layer is likely to be the answer. A patch is made, briefly speaking, it tries to submit the under layer requests together if they come from the same up layer request. It doesn't mean to make things better, its purpose is not to make things worse.

After applying the plugging mechanism, we can see that the throughput is improved for the sequential I/O, especially for reads, it's very close to optimal.
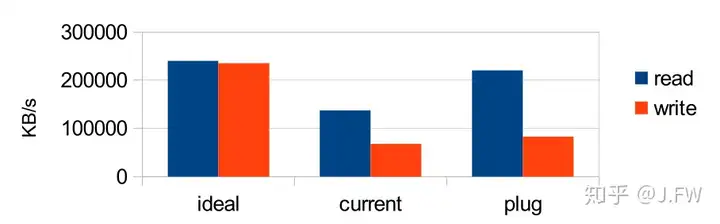
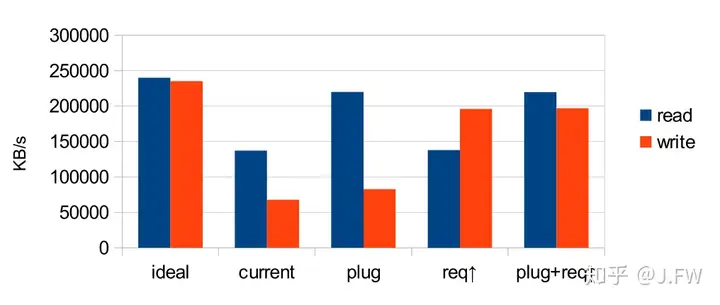
However for writes, there is still huge room to optimize. If we use iostat or any kind of I/O monitorers, we can see that the requests are not large enough to the underlayer for the sequential writes. It looks impossible to have small requests after enabling plugging mechanism. After some debugging, I found that there is a constraint of raid, which causes the system at most have these amount of data in flight to disk: 400 * 4KB = 1600KB It's a pretty small value especially in the case of 4 subarrays, please note that all the subarrays compete for this same pool. That's why we see the drop on the super array, but for one subarray. After setting it to a larger value, the throughput sequential write boosts too.
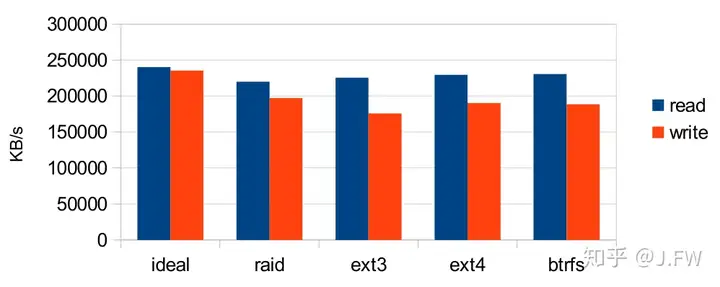
I also did a basic comparison between EXT3, EXT4 and BTRFS. From the test results, we can see that EXT3 filesystem might not be the best choice, especially for the write tests.
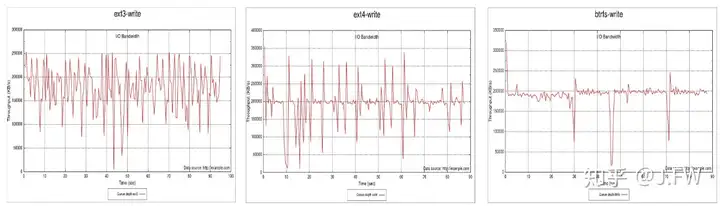
The comparison between EXT3, EXT4 and BTRFS deserves a separate analysis, I am not going that further. However we can explore a little bit from the plotting of the fio results. EXT3 had more deviation, EXT4 and BTRFS was more consistent, although consistence has no strict relation with throughput.
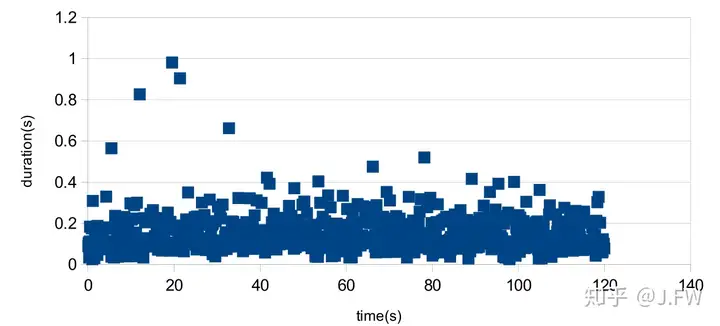
In order to measure the latency of the write/fsync operations, strace is used to capture the time spent in the syscalls. Strace is just good enough for the accuracy and overhead. In this test, I use another fio process in the background generating the I/O as many as possible, this is to simulate the case of I/O pressure. As write() is almost always short in the test (buffer write), I will plot the time of fsync() only. The latency is unacceptable, it takes about 20 seconds to complete one 4KB fsync().
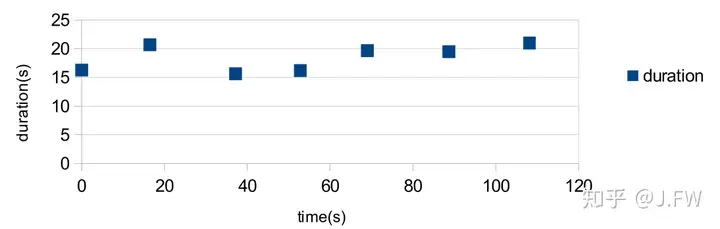
What if the iosched is switched to cfq for the RAID devices? The time spent for each fsync() is reduced to 2s from 20s, it's a huge improvement although 2s is still not good enough. The reason of this optimization is that cfq gives the synchronous requests more priority than the asynchronous requests.
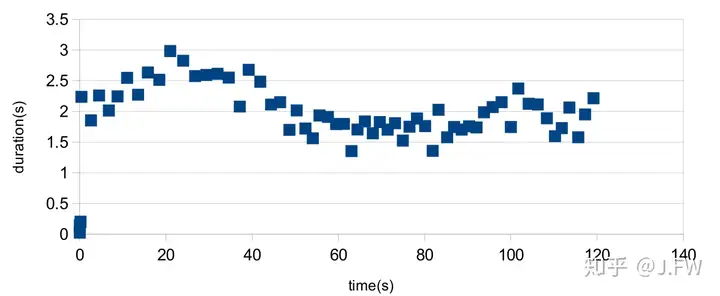
Now it's the time to think about this 2s latency. As we know, EXT3 supports several data integrity options including journal, ordered and writeback.
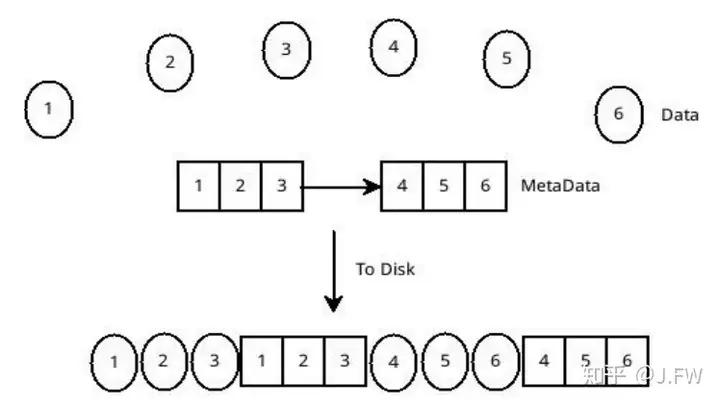
Ordered mode is currently used. The following is a very simplified version about EXT3 and JBD, which doesn't include many details. In order to maintain the internal filesystem integrity, EXT3/JBD employs the "handle" to track a series of low level operations which has to be atomic. For the sake of performance, these handles are grouped into "transactions" and committed to disk together. For each filesystem, there is only one kernel thread handling the transactions in FIFO. Let's see the situation of the filesystem mounted with data=ordered, there are 2 two restricts:
So that in order to fsync the Data 6 (D6), it not only has to flush M6, it also has to flush all D{1..6} and M{1..6}. But for data=writeback, it only has to flush D6 and M{1..6}.
This is the result of data=writeback test. Most of the requests are done in 0.4s, it's a big win if we can switch the mount option to data=writeback.