玄铁C910微架构学习(11)——缓存系统的数据预取技术 https://zhuanlan.zhihu.com/p/487605742复制
玄铁C910采用多级缓存的内存层次结构,每一个核心配有单独的L1 ICache和L1 DCache,多核间共享一个L2 Cache。
本专栏在之前的《玄铁C910微架构学习(2)——指令高速缓存》中详细介绍了L1 Icache的结构和工作原理,L1 ICache大小为64KB,采用2路组相联结构,缓存行大小为64Byte。而玄铁C910的L1 Dcache的大小也为64KB,采用2路组相联结构,缓存行大小为64Byte;共享的L2缓存大小为1MB,采用16路组相联的结构,缓存行大小同样为64Byte。
之前介绍的指令高速缓存中有提到Icache中支持指令预取技术,采用预取下一行缓存行的策略;而对于数据缓存,则支持更为复杂的预取策略,本篇文章将给大家介绍玄铁C910中的Dcache和L2Cache中数据预取的工作原理和实现过程,并分析这些预取技术对于性能的影响。
关于Dcache和L2Cache的结构本专栏后续帖子会进行详细的介绍,本文将着重介绍数据预取技术。
处理器和内存之间的性能差异导致“内存墙”的出现,而现代处理器通过多级缓存的内存层次结构,依赖内存访问的局部性来减少可观察到的内存访问时间,但不同级别的缓存对应的访问时间不同,离处理器越远的缓存所需的访问时间越长。当某一级缓存未命中时,从下一级缓存或内存获取缓存行的代价还是很大。因此,现代处理器大多采用数据预取技术,预测未来的内存访问,并在显式访问之前发出对应内存块的访问请求,提前将内存块取到缓存中,提高缓存的命中率。
预取可以提高缓存的命中率,但是预取的及时性和准确性也会对性能有一定的影响,预取不及时或者预取的地址错了会造成缓存资源的浪费,因为预取的缓存块会替换缓存中潜在的有用的缓存块,如果预取的地址错了,导致该预取的缓存块没有被使用,但是又替换了原来有用的缓存块,那么将影响处理器的性能。如果太早完成预取,预取的块还没有被使用可能就被再次替换了,太晚的话可能会使得预取没有发挥作用。因此,若要有效提高处理器性能,需要搭配高精度的预取策略。
预取可以分为软件预取和硬件预取,软件预取指的是处理器支持预取指令,通过指令的形式告知硬件需要进行预取的地址;而硬件预取则是指由硬件根据预取策略来决定预取的地址。目前玄铁C910没有加入预取指令,仅支持硬件预取,因此下文主要介绍玄铁C910的硬件预取机制。
玄铁C910支持多模式(multi-mode)和多数据流(multi-stream)的数据预取机制,通过对数据流进行模式匹配,有效地预取数据回填L1或L2缓存。主要有两种预取模式,一种是全局预取模式,适用于简单但连续的数据流,支持任意步长,并且预取的最大深度为64个缓存行。另一种模式是多流预取模式,适用于复杂的场景,该模式下最多支持8个具有不同步长的数据流,并预取的最大深度为32个缓存行。
预取的操作主要分为三个步骤,第一步是步幅的计算,从Load指令中找到正确模式,并计算出步幅。第二步是预取控制,它决定了预取策略并且评估置信度,预取的策略负责设置预取的深度,并动态调整预取的开始和停止。最后一步,往总线中发出请求,进行数据的预取。
数据预取的部分的源码主要集中在gen_rtl代码中的lsu部分,相关逻辑主要包含在下列文件中:
| 文件名 | 文件内容 |
|---|---|
| ct_lsu_pfu_gpfb.v | 全局预取模式相关控制逻辑 |
| ct_lsu_pfu_gsdb.v | 全局预取模式的步幅计算和检查的控制逻辑 |
| ct_lsu_pfu_pfb_entry.v | 多流预取模式中的pfb |
| ct_lsu_pfu_pfb_l1sm.v | 控制L1缓存预取请求的相关逻辑 |
| ct_lsu_pfu_pfb_l2sm.v | 控制L2缓存预取请求的相关逻辑 |
| ct_lsu_pfu_pfb_tsm.v | 控制预取请求的相关逻辑 |
| ct_lsu_pfu_pmb_entry.v | 多流预取模式中的pmb |
| ct_lsu_pfu_sdb_cmp.v | 计算步幅的相关逻辑 |
| ct_lsu_pfu_sdb_entry.v | 多流预取模式的步幅计算和检查的控制逻辑 |
| ct_lsu_pfu.v | 数据预取的顶层 |
当机器模式隐式操作寄存器(MHINT)中的DPLD位(Dcache预取使能位)或L2PLD位(L2Cache预取使能位)开启时,预取单元会读取Lsu中到达da阶段(load流水线中data alignment阶段,正常情况下可以得到访问缓存的结果,具体可以参考本系列的加载存储单元介绍)的指令的相关信息,来判断是否进行预取操作,仅对于需要进行预取的load指令(如果该指令触发了异常或者属于split类型的指令或者访问地址的页uncacheable就不进行预取)才会进行相关判断。
产生步幅的过程主要分为三个部分:
1、计算步幅:通过计算多次访问地址之间的差值得到步幅。
2、检查步幅,再次计算步幅,并与之前计算得到的步幅进行比较。
3、监视步幅,持续不断地检查步幅,调整置信度。
整个产生步幅的过程主要由下列状态机(图1)进行控制。
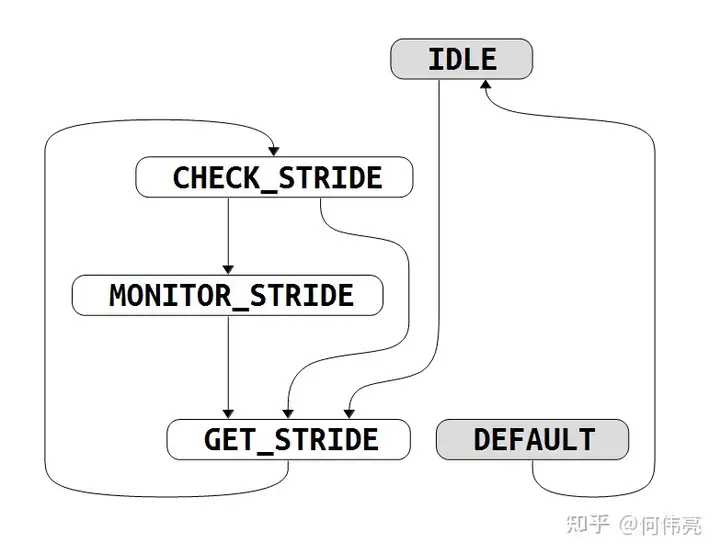
IDLE:该状态为初始状态,在该状态下等待预取的开启,当机器模式隐式操作寄存器(MHINT)开启与预取相关的位时,则会跳转到 GET_STRIDE 进行步幅的计算。
GET_STRIDE:等待步幅的计算,当步幅计算完成后(根据entry_addr_cmp_info_vld和normal_stride信号判断)跳转到CHECK_STRIDE 进行步幅的检查。
CHECK_STRIDE:检查步幅,当步幅检查成功后(根据check_stride_success信号判断)跳转到MONITOR_STRIDE 监视步幅,同时会将置信度重置为2‘b10,同时会向gpfb(主要用于控制向总线发出预取请求)发出请求,并将步幅传递;当步幅检查发现不一致时,跳转到 GET_STRIDE 重新计算步幅。
MONITOR_STRIDE:监视步幅,在该状态下也会不断地检查步幅,每成功检查一次,置信度会加一;每一次检查不成功时,置信度会减一,当置信度减为0时,会跳转回 GET_STRIDE 重新等待下一次步幅计算,同时需要向gpfb发出pop请求,及时停止当前预取。

取连续的三个load指令的地址,通过计算他们的差值得到预取的步幅,因此需要将三个地址存起来进行判断。sdb_cmp.v中管理了三个用于存储地址的entry,其中addr0是静态的不会与其它entry的addr进行位置互换,而addr1和addr2的位置可以进行互换。
在gsdb.v中管理了一项newest_pf_inst存储所有经过da阶段的指令中最新指令的iid,每一次有load指令经过da阶段,都会与这一项进行比较,永远将较新指令的iid存储下来。当lsu的da阶段发现发生了cache miss时,会产生一个pfu_act_vld信号给预取单元进行激活,同时将发生cache miss的指令的iid与newest_pf_inst进行比较,判断该指令是不是最新的load指令,如果是才会激活步幅的计算,如果不是则不进行步幅计算。
如果此时entry0没有存储有效的地址,则将当前da阶段的load指令的访问地址写到entry0中,同时会将该指令的iid(用于区分指令的先后顺序,流水线中的每一条指令都有一个唯一的iid)写到entry0中,后续到达da阶段的需要预取的load指令,通过判断其iid来确定该指令与entry0中的指令的关系,如果该指令比entry0中的指令新(代表程序中该指令的执行顺序应该在entry0之后),那么该指令将会进入entry1中。后续再进来的指令如果比entry1中的指令旧,则将原来entry1中的指令移到entry2中,新进来的指令进入到entry1中(代码中的dp_set信号是entry的写使能信号)。
//addr0 is static, addr1 and addr2 can change
assign entry_addr_dp_set[0] = entry_pf_inst_vld
&& !entry_addr_vld[0];
assign entry_addr_dp_set[1] = entry_pf_inst_vld
&& !entry_newer_than_ld_da[0]
&& (entry_addr_vld[0]
&& !entry_addr_vld[1]
|| entry_newer_than_ld_da[1]);
assign entry_addr_dp_set[2] = entry_pf_inst_vld
&& !entry_newer_than_ld_da[0]
&& (entry_addr_vld[0]
&& entry_addr_vld[1]
&& !entry_addr_vld[2]
|| entry_newer_than_ld_da[2]);
复制对后续到达da阶段的指令都进行上述操作,直到三个entry中的指令均被提交(退休单元中每一次提交了新的指令都会跟三个entry中的iid进行比较),这时可以保证三个entry中存储的地址是三个连续的访问地址。当三个entry均被提交时,会计算三个地址的差值得到两个步幅,通过比较两个步幅是否相等,判断这三次连续的访问地址(虚拟地址)是否等步幅,当计算得到的步幅相等、不等于零且没有跨2k时(因为两个步幅加起来不能跨4K),代表该步幅有效(产生normal_stride信号),下一周期会将该步幅存起来,存到entry_stride中,得到步幅。
always @(posedge entry_cmit_all_clk or negedge cpurst_b)
begin
if (!cpurst_b)
begin
entry_stride_neg <= 1'b0;
entry_stride[10:0] <= 11'b0;
end
else if(entry_stride_create_vld)
begin
entry_stride_neg <= entry_stride_neg_set;
entry_stride[10:0] <= entry_stride_0to1[10:0];
end
end
······
assign entry_cmit_all = &entry_cmit[2:0];
assign entry_stride_create_vld = entry_cmit_all
&& !entry_stride_keep
&& !entry_addr_cmp_info_vld;
assign entry_clr_addr_info_vld = entry_cmit_all
&& entry_addr_cmp_info_vld;
复制同时,因为预取的单位都是以缓存行为单位,在实际计算预取地址是将基地址加上步幅的高位作为地址,需要判断步幅是否跨过了一个缓存行,如果是则取原来的步幅的高位(高位指忽略低6位,因为缓存行的大小为64Byte,等于2的6次方),如果没有跨过一个缓存行,则需要将高位加一,即预取下一个缓存行。同时会产生一个entry_addr_cmp_info_vld信号,代表完成地址信息的比较,然后会清空三个entry。
assign entry_stride_neg_ge_cache_line = !(&entry_stride[10:6]);
assign entry_stride_pos_ge_cache_line = |entry_stride[10:6];
assign entry_stride_ge_cache_line = entry_stride_neg
? entry_stride_neg_ge_cache_line
: entry_stride_pos_ge_cache_line;
assign entry_strideh_6to0[6:0] = entry_stride_ge_cache_line
? entry_stride[6:0]
: 7'h40;
复制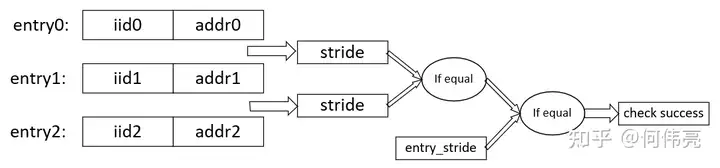
当得到步幅后,会进入检查步幅的状态,在该状态下,与步幅计算类似,不过不需要da阶段的指令发送cache miss才会激活,只需要该load指令是最新的指令即可,将最新的load指令写到entry0中,然后将之后执行的load指令写到entry1和entry2中,然后进行类似步幅计算的操作。
最终三个entry均被提交时,计算三个地址的差值得到两个步幅,通过比较两个步幅是否相等。
当计算得到的步幅相等且有效时,与之前步幅计算时得到的entry_stride进行比较,若相等则代表检查成功,发出check_stride_success信号,同时也会发出entry_addr_cmp_info_vld信号代表完成地址信息比较,然后清空三个entry,等待下一次步幅检查。
通过不断地检查步幅来动态调整置信度,当置信度减为零,代表数据流已经不连续或者是连续的步幅已经不等于之前计算得到的步幅,所以按照之前的步幅进行预取已经没有意义,反而有可能会污染缓存,因此此时需要停止预取。
assign confidence_reset = pfu_gsdb_state_is_check_stride
&& pfu_gsdb_addr_cmp_info_vld
&& pfu_gsdb_check_stride_success;
assign confidence_sub_vld = pfu_gsdb_state_is_monitor_stride
&& pfu_gsdb_addr_cmp_info_vld
&& !pfu_gsdb_check_stride_success
&& !confidence_min;
assign confidence_add_vld = pfu_gsdb_state_is_monitor_stride
&& pfu_gsdb_addr_cmp_info_vld
&& pfu_gsdb_check_stride_success
&& !confidence_max;
复制当处于检查步幅的状态时,将置信度重置为2‘b10。在监视步幅的状态下,每成功检查步幅一次(pfu_gsdb_check_stride_success为1),则将置信度加一;若检查发现步幅与之前的步幅不一致,则置信度减一。当置信度减为0时,停止预取请求,并将所有计算步幅的entry清空,重新回到计算步幅的状态。
当成功检查完步幅后,会将得到的步幅发送到gpfb中,进行地址的计算,准备像总线发出预取请求。首先需要在下列状态机(图4)中计算第一次的预取地址并判断该地址有没有跨4K页。

得到预取的步幅后,当下一次da阶段出现cache miss的指令的时候,就会将该访问的地址加上步幅,得到初始的地址inst_new_va,但是该地址并不代表预取的地址。因为以步幅为1为例,加上步幅后的地址与原来发生cache miss的地址大概率在同一个缓存行中,而预取发生了cache miss的那行缓存行是没有意义的,应该需要预取下一行缓存行,因此需要在此地址的基础上加上strideh即预取步幅的高位(具体含义上文介绍步幅时有提及)。
IDLE:初始状态,等待步幅计算和检查完成,当步幅检查完成后,跳转到 INIT_INST_NEW_VA 中进行预取地址的计算。
INIT_INST_NEW_VA:当到达da阶段的指令出现cache miss的时候,将该指令的访问地址加上步幅得到inst_new_va,同时需要判断该地址有没有跨4k页,如果没有则跳转到 JUDGE 代表地址计算完成。
JUDGE:该状态下代表地址计算完成,产生entry_tsm_is_judge信号,进入下一个状态机准备向总线发出预取请求。
由于预取支持L1和L2缓存的预取,而两者预取请求发出的控制基本相同,因此本文只介绍L1缓存的预取请求控制,L2缓存的预取请求控制与L1相似,只是请求发往的地方不一样。 将inst_new_va加上步幅的高位得到第一次预取的地址,之后每当总线准许发出预取请求时,就会将上一次发出预取请求的地址加步幅生成新的预取地址,同时还需要判断地址是否超出预取的范围。entry_l1_dist_strideh中的信息代表预取的深度,预取的深度通过MHINT中的D_DIS(对于L1Cache预取的深度)和L2_DIS(L2Cache预取的深度)来配置,对于L1 Cache支持2、4、8、16四种预取深度,L2 Cache支持8、16、32、64四种预取深度。将步幅乘上预取深度得到预取的范围entry_l1_dist_strideh。将预取的地址减去inst_new_va 与预取范围进行比较,当超过预取范围时,即代表达到预取深度,不再发出预取请求。
assign pfu_gpfb_l1_dist_strideh[`PA_WIDTH-1:0] = {`PA_WIDTH{lsu_pfu_l1_dist_sel[3]}} &{pfu_gpfb_strideh[`PA_WIDTH-5:0],4'b0}
| {`PA_WIDTH{lsu_pfu_l1_dist_sel[2]}} & {pfu_gpfb_strideh[`PA_WIDTH-4:0],3'b0}
| {`PA_WIDTH{lsu_pfu_l1_dist_sel[1]}} & {pfu_gpfb_strideh[`PA_WIDTH-3:0],2'b0}
| {`PA_WIDTH{lsu_pfu_l1_dist_sel[0]}} & {pfu_gpfb_strideh[`PA_WIDTH-2:0],1'b0}
assign pfu_gpfb_l2_dist_strideh[`PA_WIDTH-1:0] = {`PA_WIDTH{lsu_pfu_l2_dist_sel[3]}} & {pfu_gpfb_strideh[`PA_WIDTH-7:0],6'b0}
| {`PA_WIDTH{lsu_pfu_l2_dist_sel[2]}} & {pfu_gpfb_strideh[`PA_WIDTH-6:0],5'b0}
| {`PA_WIDTH{lsu_pfu_l2_dist_sel[1]}} & {pfu_gpfb_strideh[`PA_WIDTH-5:0],4'b0}
| {`PA_WIDTH{lsu_pfu_l2_dist_sel[0]}} & {pfu_gpfb_strideh[`PA_WIDTH-4:0],3'b0}
复制计算预取地址和发出请求的控制逻辑由以下状态机(图5)控制。
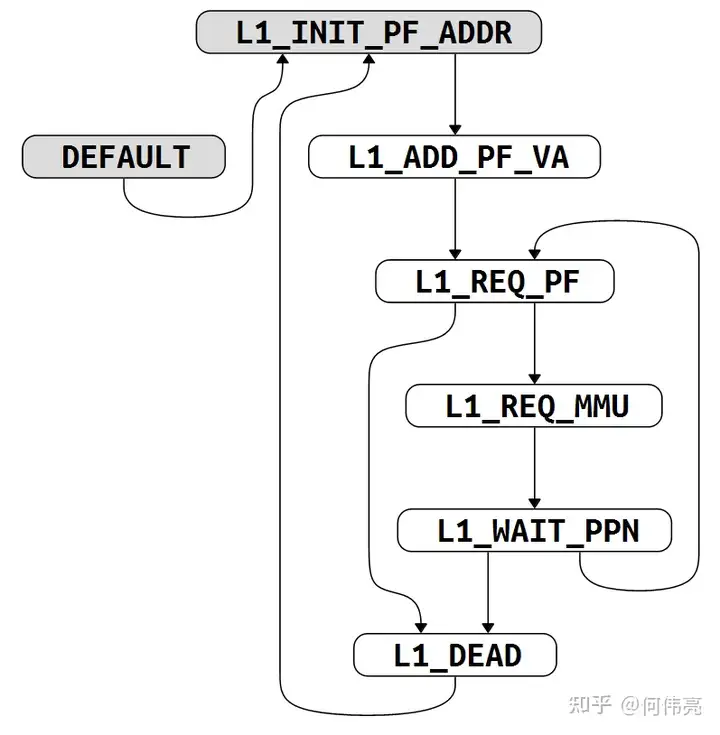
L1_INIT_PF_ADDR:当初始预取的地址计算完成后,即收到entry_tsm_is_judge信号后,跳转到 L1_ADD_PF_VA ,计算预取的地址。
L1_ADD_PF_VA:在该状态下会计算预取地址,用inst_new_va加上步幅的高位得到第一次预取的地址。然后跳转到 L1_REQ_PF 准备发出请求。
L1_REQ_PF:如果加上步幅后的预取地址跨4k页了,且机器模式寄存器MHINT2中mmu的disable为高时,无法使用mmu对跨页部分的地址进行翻译,跳转到L1_DEAD 终止预取请求。如果mmu开启的情况下,加上步幅后的预取地址跨4k页了,则需要进入 L1_REQ_MMU 重新对地址进行翻译。如果没有出现跨页,则在总线准许的情况下,发出预取请求。
L1_REQ_MMU:当mmu准许访问时,跳转到 L1_WAIT_PPN ,等待翻译得到的物理地址。
L1_WAIT_PPN:如果得到的物理地址有效且没有出现error,则进入到 L1_REQ_PF 重新发出请求。如果得到的物理地址出现了error,则进入到 L1_DEAD 中,终止预取操作。
L1_DEAD:等待reinit信号,来重新开始下一次预取。
多流预取模式主要针对同一条load或者store指令(根据pc判断)的多次执行,而且每一次的访问地址按一定步幅变化,在程序的循环中,对数组的操作等就很容易出现这些情况,对于这种情况可以通过预取来减少cache miss。玄铁C910共支持8个具有不同步长的数据流进行预取,最大的预取深度为32。
该模式下主要使用3种buffer(pmb、sdb、pfb)进行管理,下面将对这三种buffer进行介绍。pmb主要用于暂存发生了cache miss的指令pc,通过与lsu流水线中执行的指令pc进行比较,判断有没有多次执行该指令,有没有预取的必要。如果该指令执行了三次就会送到sdb中,计算步幅,当得到有效的步幅时,则会进入到pfb中,准备发出预取请求。
该buffer共有8个项,主要用于存储发生了cache miss的load指令或发生了cache miss的store指令,判断该指令是否多次执行,如果发现指令执行了三次,就会将该指令送到sdb中进一步计算步幅,判断是否需要进行预取。当load流水线或者store流水线的da阶段发现出现cache miss,而且此时全局预取模式没有在进行工作(即没有得到有效的步幅)时,会先判断当前3种buffer中所有表项中的pc有没有与该pc一致的表项,如果没有则会创建一项pmb_entry,优先寻找空的表项写入,如果没有空表项则寻找可替换的表项写入,当没有可替换的表项时,则不写入。
assign pipe_create_vld = ld_da_pfu_act_vld || st_da_pfu_act_vld && !ld_da_pfu_act_dp_vld;
assign pipe_create_dp_vld = ld_da_pfu_act_dp_vld || st_da_pfu_act_dp_vld;
//------------------------hit pc----------------------------
assign pfu_pmb_hit_pc = |pfu_pmb_entry_hit_pc[PMB_ENTRY-1:0];
assign pfu_sdb_hit_pc = |pfu_sdb_entry_hit_pc[SDB_ENTRY-1:0];
assign pfu_pfb_hit_pc = |pfu_pfb_entry_hit_pc[PFB_ENTRY-1:0];
assign pfu_hit_pc = pfu_pmb_hit_pc
|| pfu_sdb_hit_pc
|| pfu_pfb_hit_pc;
//-------------------create signal--------------------------
assign pfu_pmb_create_vld = pipe_create_vld
&& !pfu_hit_pc
&& !pfu_gpfb_vld;
assign pfu_pmb_create_dp_vld = pipe_create_dp_vld
&& !pfu_hit_pc
&& !pfu_gpfb_vld;
复制然后将发生了cache miss的指令的pc存储起来,并把指令的类型存储起来(load或store类型)。然后根据指令类型选择load流水线或者store流水线中的有效指令的pc,与该entry中的pc进行比较,从而判断之前发生cache miss的指令是否出现多次执行的情况,当出现两次命中pc时,则可以将该指令的pc送到sdb中进一步计算步幅,如果sdb表项满了且没有能替换的,则会在pmb中继续等待,直到sdb中出现可替换表项。
由于一共只有8个项,因此为了防止一些只执行了一次的指令,占用表项,每一个entry内部使用一个timeout_cnt计数器,当entry有效时,每周期加一,当计满(计数器的最大值可以通过机器模式隐式操作寄存器(MHINT3)进行配置)时,则认为该项可以被替换,有新的项进来时,可以将其替换。
该buffer共有2项,可同时支持两条可能需要预取的指令进行步幅的计算和检查,具体的计算步幅过程与全局预取模式中的步幅计算过程类似(请参考上文)。只不过在全局预取模式中,只要是da阶段有效的load指令都会进入三个项计算步幅中,但是在多流预取模式下,由于针对的是某一条指令访问地址的变化进行步幅计算,因此需要判断da阶段中指令的pc与entry中的pc是否一致,一致时才能进行步幅的计算。
assign pfu_sdb_entry_hit_pc = pfu_sdb_entry_vld
&& (pipe_cmp_pc[PC_LEN-1:0]
== pfu_sdb_entry_pc[PC_LEN-1:0]);
assign pfu_sdb_entry_pf_inst_vld = pfu_sdb_entry_hit_pc
&& pipe_cmp_inst_vld;
复制计算完步幅后,与全局预取模式一样,同样需要检查步幅(具体过程请参考上文),检查步幅成功后,则会将该项的步幅和地址等信息给到pfb,准备发送预取请求,如果pfb表项满了且没有能替换的,则会在sdb中继续等待,直到pfb中出现可替换表项。
与pmb一样,为了防止一些执行次数少的指令占用表项,每一项内部均使用一个timeout_cnt计数器,当entry有效时,每周期加一,当计满时则将该表项标志为可被替换状态,每当entry中存储的pc与da阶段指令的pc一致时都会重置该计数器。
该buffer共有8项,主要用于评估置信度以动态控制预取的开始和停止,向总线发出请求,具体的实现过程与全局预取模式类似(参考上文),也是使用上文中的状态机进行控制,每一项存储一个load或store指令的pc(即触发预取的指令)和预取步幅,所以可以同时支持8个不同步幅的数据流。
不同点在于,该模式下,L1cache只支持1、2、4、8四种预取深度,L2cache只支持4、8、16、32四种预取深度,判断何时达到预取深度的逻辑也与全局预取模式类似,而且L1cache只支持对于load指令的预取,对于store指令不进行预取,L2cache则两者都支持。置信度的评估也有所不同,置信度的初始值为3’b110,仅当同一load或store指令再次执行时,才会进行步幅的检查,两次步幅相等时置信度加一,反之则减一,当置信度减为0时会停止预取,将该项清空。
与前两个buffer一样,内部同样拥有timeout_cnt计数器,来决定该表项何时可以被替换,除此之外,还有一个no_req_cnt计数器(用于记录当前entry对于pc命中的次数),当该entry很多次命中pc却没有发请求时,需要被替换,避免长时间占用表项,每一次da阶段的指令命中该entry的pc则计数器加一,计满(同样通过MHINT3进行配置计数器的最大值)时会将该项设置为可被替换的状态。
如果多流预取模式或全局预取模式同时发出请求,则优先处理多流预取模式的请求;如果多流模式下,多个pfb中的entry同时请求,则按entry的排序进行作为优先级排序,没有得到响应的请求则继续等待。
上文提到玄铁C910的预取支持L1cache和L2cache的预取,且两者分开管理控制,预取单元仅负责向总线发出预取的地址和相关属性,写回的数据并不会经过预取单元。
对于L1Dcache是通过line fill buffer(本系列后续会进行介绍)写回到cache中,而对于L2Cache则通过总线写回。但是由于预取单元每次只能发出一个预取请求,因此会优先发送L1Dcache的预取请求,仅当line fill buffer满了的时候(此时无法将预取的数据写回L1Dcache),会选择发送L2Cache的预取请求。
全局预取模式:主要用于对于连续的等步幅的地址访问,对于密集矩阵和数组访问的情况下十分有效,当六次访问(三次用于步幅计算、三次用于步幅检查)的访问地址的步幅相等时,就会进行预取,预取的深度可通过MHINT配置,L1缓存最大支持16个缓存行的预取深度,L2缓存最大支持64个缓存行的预取深度。由于预取不准确会导致污染缓存,因此通过监视步幅,改变置信度,通过评估置信度动态调整预取的开始和停止,减少对缓存的污染。
多流预取模式:跨步幅访问的长序列称为流,多流预取表示同时支持多个步幅的预取,对于交错跨步幅的序列十分有效,比如矩阵向量乘法,多个矩阵交替访问,而每个矩阵访问的步幅可能不同,这时全局预取模式可能就无法发挥作用,而多流预取就可以应对这种情况。因此,多流预取模式是针对同一个指令(同一pc)多次执行,而每一次的访问地址按等步幅变化的情况下进行预取,当一条访存指令发生了cache miss且执行了三次,就会进行步幅的计算和检查(共需要再遇到该指令执行六次),步幅检查通过后就会进行预取操作,玄铁C910可同时支持8个不同的步幅数据流,L1缓存支持的最大预取深度为8个缓存行,L2缓存最多支持32个缓存行的预取。
上文对玄铁C910的预取机制进行了详细的介绍,下文将量化分析这些预取技术对于性能的影响。
本文使用YOLO算法卷积层的卷积函数,关于卷积层的相关介绍请参考本专栏的文章《在D1哪吒开发板上部署YOLOv3 tiny以及从体系结构视角分析卷积层优化策略》,本文中使用基于gemm库优化的卷积层的卷积函数作为测试程序,将测试程序放在SMART平台上进行仿真和性能监测,具体过程可以参考本专栏文章《YOLOv3卷积层在C910 处理器平台上的实现和仿真》。上文提到可以通过配置MHINT寄存器来控制是否开启预取,因此通过配置MHINT寄存器,对比分析开启所有预取、仅开启L1DCache预取、仅开启L2Cache预取、关闭所有预取四种情况下,处理器的性能变化。
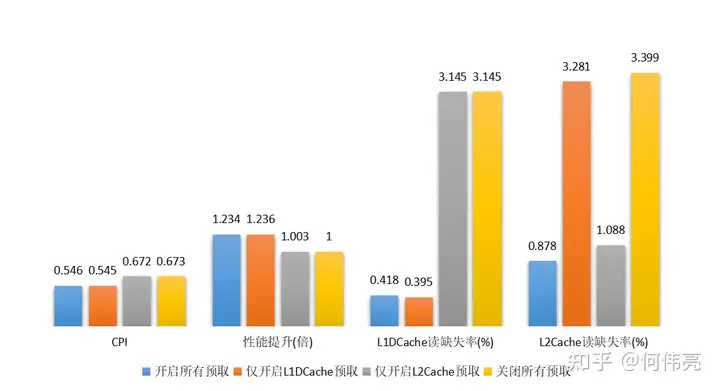
仿真得到的结果如图6所示,其中CPI(cycle per instruction)代表平均每条指令执行的周期数,L1DCache读缺失率=L1DCache的读访问缺失数/L1DCache的读访问次数,L2Cache读缺失率=L2Cache的读访问缺失数/L2Cache的读访问次数。由于从仿真结果得出,在四种情况下L1DCache的写缺失率和L2Cache的写缺失率基本相同,因此上图中没有进行展示。
从仿真结果可以看出,开启所有预取相比于关闭所有预取,性能提升约1.2倍。在开启L1 DCache预取的情况下,L1DCache的读缺失率仅为0.4%,而关闭L1 DCache预取后,读缺失率则提高到3.1%。在开启L2Cache预取的情况下,L2Cache的读缺失率仅为1.0%左右,而关闭预取后,读缺失率则提高到3.3%。
因此,可以看出预取能大大减小缓存的缺失率,减少存储访问延时。值得一提的是,从上述结果可以看出,L1DCache的命中率对于性能有较大的影响。使用了L1DCache预取的情况下,能减少对L2缓存的访问,降低因缓存缺失带来的延时,因此对性能提高有较大的帮助;而仅开启L2Cache预取的时候,虽然能降低L2Cache的缺失率,但是由于没有开启L1DCache预取,L1DCache缺失率没有改善,每当发生缺失时都需要从L2缓存中读取数据回填到L1DCache中,大大增加了访问时间,从而限制了处理器性能的提升。
综上所述,基于gemm库优化的卷积层已经是性能较为优的版本,但是可以看到预取技术还是能显著地提升处理器的性能。因此,对于这种涉及大量矩阵向量运算的卷积函数,玄铁C910的预取技术能有效地提高处理器的性能。
本篇文章介绍了玄铁C910中数据预取的工作原理和具体实现,详细介绍了全局预取和多流预取两种模式,并针对预取技术对于处理器性能的影响进行了分析。本系列后续的文章将对玄铁C910处理器其它部分的具体工作过程和相关的优化技术进行详细的分析,希望能给想要学习高性能处理器的人提供一些帮助。
[1] 玄铁C910用户手册
[2] https://github.com/T-head-Semi/openc910
[3] Falsafi B, Wenisch T F. A primer on hardware prefetching[J]. Synthesis Lectures on Computer Architecture, 2014, 9(1): 1-67.
[4] Chen C, Xiang X, Liu C, et al. Xuantie-910: A commercial multi-core 12-stage pipeline out-of-order 64-bit high performance risc-v processor with vector extension: Industrial product[C]//2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020: 52-64.