https://www.zhihu.com/people/kent-35-40/posts复制
现代高性能处理器的性能与内存性能的不匹配,如果处理器每次读取数据都直接访问内存,将导致内存的存取速度严重阻碍处理器性能的发挥。因此现代高性能处理器往往采用多层次的缓存技术来减少对内存的访问,节省处理器读取内存的时间。玄铁C910采用两级的高速缓存,第一级缓存分为指令和数据高速缓存,是距离处理器核心最近的缓存,第二级缓存指令和数据共享,相比第一级缓存容量更大,但访问速度也相对更慢。
本文将介绍高性能处理器玄铁C910的第一级指令高速缓存的组成和扩展的Cache操作,并对其中使用的指令预取和缓存路预测等技术进行详细的介绍。
由于指令高速缓存的访问位于指令提取单元(IFU),因此先简单介绍一下玄铁C910指令提取单元(IFU)的流水线组成,取指单元主要进行指令缓存的访问、对指令进行预处理,还有分支预测(本文将不再对分支预测部分进行介绍,相关内容请参考《玄铁C910微架构学习》系列的分支预测篇),取指单元一共分为三个流水级:Instruction Fetch(下文简称为IF)、Instruction Pack(下文简称为IP)、Instruction Buffer(下文简称为IB)。
IF:访问L1指令缓存获取指令,一周期最多可以取出128bit指令。
IP:预处理指令,最多可以预处理8条指令,在发生缓存miss时进行回填(refill)。
IB:将指令缓存到指令Buffer中,然后向后续流水线发送指令。
源码中的pcgen模块主要功能是产生PC,产生PC后即向指令高速缓存发出访问请求。
指令高速缓存部分的源码主要集中在gen_rtl代码中的ifu部分,相关逻辑主要包含在以下文件中:
| 文件名 | 文件内容 |
|---|---|
| ct_ifu_icache_data_array0/1.v | 存储Icache第0/1路数据 |
| ct_ifu_icache_if.v | Icache的顶层模块 |
| ct_ifu_icache_predecd_array0/1.v | 存储第0/1路的预译码信息 |
| ct_ifu_icache_tag_array.v | 存储Icache的Tag |
| ct_ifu_ifctrl.v | IF阶段的控制逻辑 |
| ct_ifu_ipctrl.v | IP阶段的控制逻辑 |
| ct_ifu_ibctrl.v | IB阶段的控制逻辑 |
| ct_ifu_ipb.v | 预取指逻辑 |
| ct_ifu_l1_refill.v | Icache回填逻辑 |
| ct_ifu_pcgen.v | 生成PC的模块 |
| ct_ifu_precode.v | 预译码模块 |
指令高速缓存的工作原理是当CPU需要取指令时,会首先在第一级缓存中寻找,通过比较标签(Tag)如果命中则能第一时间返回指令,否则就需要去下一级缓存中进行寻找,并把整个缓存行读入到缓存中,那么当访问该缓存行的指令时,就可以以最快的速度返回指令。更多关于高速缓存的基础知识可以参考《计算机体系结构量化方法》的第二章和附录B部分。
玄铁C910的指令高速缓存大小为64KB(开源版本中还支持32KB、128KB、256KB的配置),缓存行(Cache line)大小为64Bytes,共有512个set。指令高速缓存主要由三个部分组成:存储指令的data_array、存储标签的tag_array、存储预译码信息的predecd_array。
玄铁C910的指令高速缓存采用VIPT结构,即使用虚拟地址做index,物理地址做tag。这种结构可以在利用虚拟地址索引访问缓存的同时使用TLB/MMU将虚拟地址翻译成物理地址,然后再将物理地址与访问缓存得到的tag作比较,判断是否命中。而如果使用PIPT结构,当访问缓存的索引超过页内偏移的大小(即地址的低12位)时,则需要先访问TLB/MMU得到物理地址后再索引缓存,这样访问的延迟较大;而如果想要访问缓存的索引不超过页内偏移的大小,则缓存的大小最大只能为4KB×组相联数,这样将大大限制了缓存的容量。因此相比之下,对于容量大于4KB×组相联数的缓存,使用VIPT结构更加有优势,因为VIPT结构可以使访问缓存和虚实地址翻译同时进行,相对速度更快。但是对于采用VIPT结构的缓存,如果访问缓存的索引超过页内偏移的大小(即地址的低12位)就可能会产生alias问题,即多个不同的虚拟地址映射到同一物理地址中,且位于不同的缓存行中。但是由于指令高速缓存是只读的,因此不会引发alias问题,只有当VIPT用在数据高速缓存时才会造成alias问题。从后续的文章中(玄铁C910微架构学习(14)——数据高速缓存),我们也可以看到玄铁C910的数据高速缓存为了避免出现这种alias问题,选择采用PIPT的结构。
使用8个2048x32bit大小的SRAM搭建,使用PC部分位[14:4]进行索引,采用两路组相联结构,每一路共有4个bank,每一个bank的数据宽度为32bit。
项数每个数据宽度数组相联数2048(项数) 32���(每个����数据宽度) 4(����数) ∗ 2(组相联数) = 64��
因此一次最多可以从缓存中取出128bit的指令,最少为4条指令,最多为8条指令(当所有指令都为压缩指令时),由于一共Cache line大小为64Bytes,而data_array一次读写带宽为128bit,因此从下一级缓存取数据时需要取四次。
除了正常的取指需要访问data_array以外,还有许多其它情况需要访问data_array,总结如下:
读访问:
1、正常进行顺序取指,根据路预测的结果决定对哪路Cache进行访问。
2、发生change flow(代表PC不是按顺序的自增,出现跳转或者分支预测失败需要重定向或者发生异常需要重定向)后的PC进行取指,根据路预测的结果决定对哪路进行访问,并且根据PC决定对哪个bank进行访问。
3、由控制状态寄存器(CSR)传来的读Cache请求,玄铁C910在标准RISCV指令集的基础上加入了许多Cache访问的扩展寄存器组,例如mcins、mcindex等。
写访问:
1、发生refill(下文会对此进行详细介绍)时,需要根据替换策略选择某一路的Cache进行替换。
2、invalid Cache(下文会对此进行详细介绍)时,需要往data_array中写0。
由于Icache一共有512个set,且为两路组相联结构,因此tag_array由512x59bit大小的SRAM搭建,其中每一项由两路Tag(物理地址的高28位和一个有效位)和一个fifo_din位组成,fifo_din的作用是决定替换Cache是替换哪一路,因为玄铁C910采用的替换策略是先入先出,因此每一次替换更新完某一路的Cache line后就会将fifo_din位取反,代表下一次替换另一路,从而实现FIFO的替换逻辑。
assign tag_fifo_din = (ifctrl_icache_if_inv_on)
? ifctrl_icache_if_inv_fifo
: !fifo_bit;
//Only When refill last, Valid Bit will Be 1
assign tag_valid_din = l1_refill_icache_if_last;
assign tag_pc_din[27:0] = (ifctrl_icache_if_inv_on || l1_refill_icache_if_first)
? 28'b0
: l1_refill_icache_if_ptag[27:0];
assign ifu_icache_tag_din[58:0] = {tag_fifo_din,
tag_valid_din, tag_pc_din[27:0],
tag_valid_din, tag_pc_din[27:0]
};
复制predecd_array使用两路2048x32bit大小的SRAM搭建,每一个项与data_array中的128bit指令包对应,在指令从下一次缓存写到L1 Cache时,同时会对每一次写的128bit指令包进行预译码后,输出一个32bit的信息存储到predecd_array中,使能信号和索引信号与data_array完全相同。
因为玄铁C910支持RISC-V压缩指令子集,所以指令包中一条指令的最小单位为16bit,预译码时会将128bit的指令包拆分成8个16bit,每一个16bit拥有4bit的信息:hn_ab_br、hn_br、hn_bry1、hn_bry0(其中n为1到8),hn_bry1和hn_bry0用于将128bit的指令包区分开,用于判断哪个16bit为单独的压缩指令,哪两个16bit组成一条标准的32位指令。hn_ab_br用于表示该条指令是否为绝对跳转指令,hn_br用于表示该条指令是否为分支指令。在从Icache中取出指令时,同时会取出这些译码信息,根据预译码的信息判断是否使用分支预测器预测的结果,在没有分支指令时不使用分支预测器的预测结果,降低了错误预测发生的机率。
当发生了Cache miss时会发送一个请求过来回填(refill)阶段开始进行refill操作,pc会从IP阶段传给refill阶段,包括有虚拟pc(充当Index)、物理pc(充当Tag)、fifo位(决定替换哪一路),会传到Icache。并且当处于数据传输的状态下且没有invalid Cache的信号时,地址会每一周期加8,相当于指向Icache中的下一项(一个Cache line共有四项),每一次refill要进行四次数据传输,每一次传输128bit,传输4次才能填满一个Cache line。refill的读取的数据根据mux判断是从预取Buffer中取还是从总线上取,读取的数据传到Icache中并传到data path中。读取到的数据还会经过precode阶段进行预译码后传到Icache的predecd_arrry,同时也传到data path中,使得此时的IF阶段的data path,不用再重新访问Icache才能拿到数据。
整个refill的过程由以下的状态机(图1)进行控制。
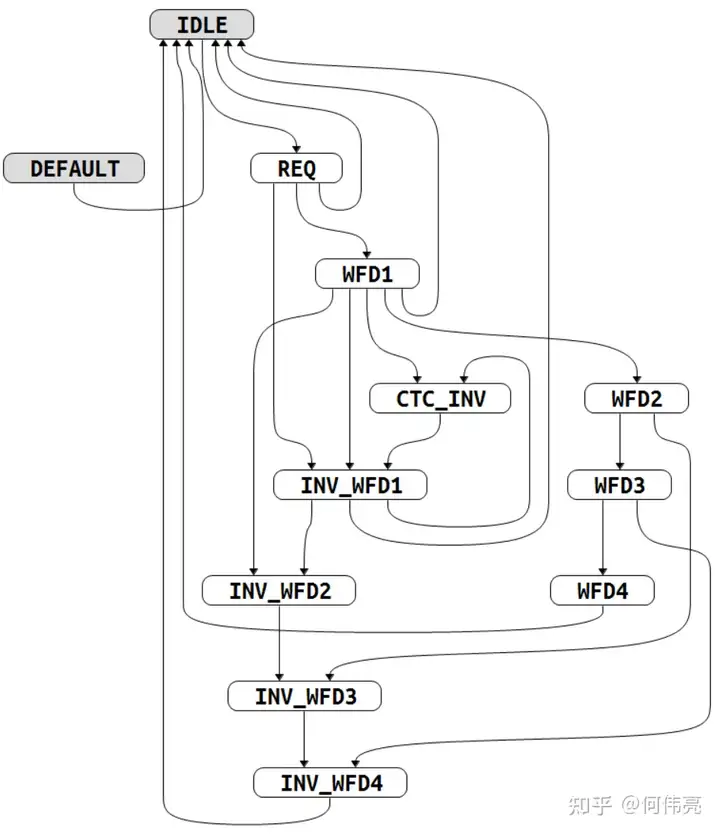
IDLE:等待refill,当开始refill时跳转到REQ。
REQ:但发生change flow(出现分支预测失败需要重定向或者发生异常需要重定向)时,代表当前的PC时无效的,需要被冲刷掉,因此此时的refill是没有意义的。当change_flow但总线没有准许refill时,回到IDLE继续等待;如果不是change_flow,但总线准许refill时,进入WFD1;当总线准许refill和change_flow同时来临时,进入INV_WFD1;当IF阶段传来inst invalid信号时,取消请求回到IDLE。
WFD1:等待第一次有效数据传输。当总线响应的数据有效且tsize(代表此时Cache使能和cacheable)有效时,跳转到WFD2;若总线响应发生了error且tsize有效时,跳转到INV_WFD2;当tsize无效时,代表不经过Cache,所以跳转回IDLE;当发生了change_flow,也代表当前请求的地址是无效的,因此跳转到INV_WFD1;如果IF阶段传来inst invalid信号,代表此时正在无效Cache,所以不进行refill,跳转到CTC_INV。
WFD2:等待第二次有效数据传输。当总线响应有效,跳转到WFD3;当总线响应发生了error,跳转到INV_WFD3。
WFD3:等待第三次有效数据传输。当总线响应有效,跳转到WFD4;当总线响应发生了error,跳转到INV_WFD4。
WFD4:等待第四次有效数据传输。当总线响应有效,跳转到IDLE;当总线响应发生了error,跳转到IDLE。在该状态下代表refill结束,会向Cache发送Last信号。
INV_WFD1:当出现总线响应发生error时,会进入该状态,该状态下不进行任何操作,但是传输已经开始,不能中途停止,所以还要继续经过传输的状态。当响应数据有效或响应error且tsize有效时,跳转到INV_WFD2;如果IF阶段传来inst invalid信号,代表此时正在无效Cache,跳转到CTC_INV。
INV_WFD2:当响应数据有效或响应erro时,跳转到INV_WFD3。
INV_WFD3:当响应数据有效或响应error时,跳转到INV_WFD4。
INV_WFD4:当响应数据有效或响应error时,跳转到IDLE。
CTC_INV:当正在进行无效Cache时会在该状态下等待,当无效Cache完成时,会跳转到INV_WFD1。
为了方便进行Cache维护操作,提高Cache效率,玄铁C910扩展了许多对Cache进行操作的指令,对于Icache的操作的指令有Icache.IALL(无效所有表项,仅操作当前核)、Icache.IALLS(无效所有表项,操作所有核)、Icache.IPA(按物理地址无效对应的表项,操作所有核)、Icache.IVA(按虚拟地址无效对应表项,操作当前核)。除了扩展的Cache指令外,还扩展了一些机器模式Cache访问的寄存器,其中机器模式硬件操作寄存器MCOR可以决定是否对高速缓存和分支预测进行操作,Cache指令寄存器(MCINS)决定是否向高速缓存发起读请求,Cache访问索引寄存器(MCINDEX)配置读请求访问的Cache位置信息,Cache数据寄存器(MCDATA0/1)记录读取高速缓存的数据,更多内容请参考玄铁C910用户手册。
这些扩展的Cache操作在指令高速缓存中主要由下列状态机(图2)控制完成:
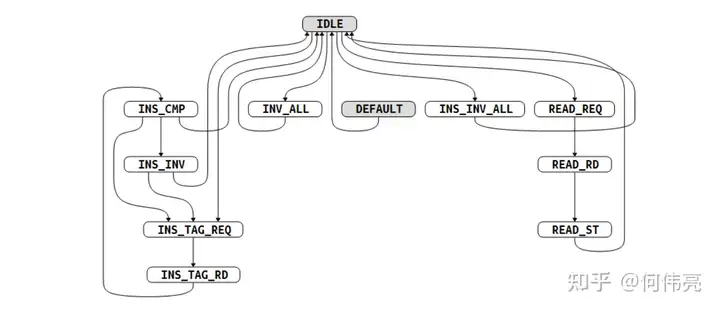
IDLE:等待无效请求,若有Cache指令请求无效整个Icache则跳转到INS_INV_ALL;如果是Cache指令请求无效Cache中的某个地址则跳转到INS_TAG_REQ;如果是cp0(控制状态寄存器模块)传来请求无效整个Cache则跳转到INV_ALL;如果是cp0传来的读Icache请求则跳转到READ_REQ。
READ_REQ:由cp0传来读请求时会到达这个状态。机器模式Cache指令寄存器MCINS的最后一位代表是否向Cache发起读请求(高电平有效),机器模式Cache访问索引寄存器MCINDEX用来配置读请求访问Cache的位置信息如Index、Way、Tag/DATA、哪个Cache。机器模式Cache数据寄存器MCDATA0/1用于存放读取的缓存数据。在这状态下会将访问的位置信息传到Icache中,然后跳转到READ_RD。
READ_RD:该状态下读取Icache的数据和Tag,将从Icache传来的数据和Tag读到IF阶段。然后会跳转到READ_ST。
READ_ST:该状态下根据位置信息(如哪一路、Tag或数据),将读到的数据传到cp0。
INV_ALL:无效整个Icache。机器模式硬件操作寄存器MCOR可以对高速缓存和分支预测进行操作,当选中指令高速缓存且进行无效化时,就会传来无效Icache的请求。使用一个计数器Icache_inv_cnt作为Index,初始化为最大值用自减的方式,不断传到Icache中进行无效Cache的操作,当无效完成后,跳转回IDLE。
INS_TAG_REQ:发送读Tag请求到Icache中。由LSU发来无效cacheline的请求。然后会跳转到INS_TAG_RD。对于Cache指令Icache.IPA(按物理地址无效表项)和Icache.IVA(按虚拟地址无效表项),需要读出Tag判断需要无效的地址是否存在于Icache中。
INS_TAG_RD:读取Icache的Tag。之后跳转到INS_CMP。
INS_CMP:比较发送请求的Tag和从Icache中读取的Tag。发送到读取Tag的Index低6位由LSU传来的Index决定,由于Cache的Index使用虚拟地址进行索引,只有低12位的页内偏移与物理地址相同,而高3位对应的物理地址要由地址转换得到,因此当需要对物理地址进行无效操作时,会将所有可能的映射地址都取出来判断是否命中,高位为计数器addr_inv_count_reg决定,当有无效cacheline请求时后被置为5‘b00111,每周期减一,相当于需要将低位为LSU传来的Index的所有项都比较Tag,若命中则跳转到INS_INV进行无效Cache line的操作。若没有命中则跳转回INS_TAG_REQ,将下一个Index的Tag拿出来比较。
INS_INV:将Cache Line无效,清除Tag的有效位。如果addr_inv_count_reg不为0则需要跳转回到INS_TAG_REQ,继续比较下一个Index的Tag,否则则代表无效cacheline操作完成跳转回IDLE。
INS_INV_ALL:无效整个Icache。对于Cache指令Icache.IALL和 Icache.IALLS需要无效Icache的所有表项,具体操作与INV_ALL状态类似。
玄铁C910的L1指令高速缓存支持指令预取功能,通过配置隐式操作寄存器MHINT.IPLD使能,当指令高速缓存发生缺失时需要向下一级缓存中取数据回填,这个过程可能会消耗较长的时间,而加入预取功能则可以减少取指的延迟。预取指令主要是预取下一行Cache line的内容到Prefetch Buffer中,只有当发生了refill时,在refill请求后,才会进行预取,会在refill请求后的四个周期后向总线发出预取请求,因此会在refill的数据写完Cache line后,接着进行预取数据,将Cache line的数据分四个周期写到Prefetch Buffer中,预取完成后预取写回状态机会先判断当前有没有refill请求,如果有则比较是否命中,命中则使用Prefetch Buffer中的数据;反之,则等待下一次refill请求,当下一次refill请求到来时也会比较是否命中,若命中则使用Prefetch Buffer中的数据回填指令高速缓存,降低取指延迟。指令预取要求预取的缓存行和当前缓存行位于同一页面,保证取指地址的安全,整个预取的过程由下列状态机(图3)进行控制:
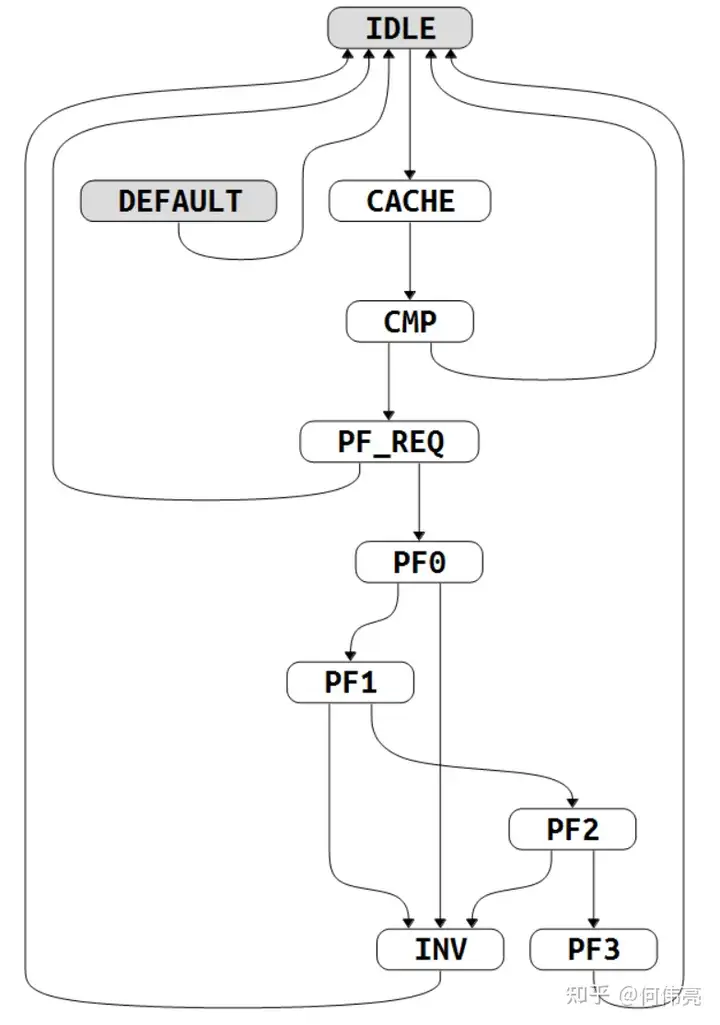
IDLE:等待Prefetch开始,开始后转到Cache。
Cache:等待一周期,等从Icache中读出Tag。
CMP:通过比较Tag检查Icache中是否已经包含将要预取的Cache line,若包含则跳转到回IDLE,不进行预取指。否则进入PF_REQ,向总线发出预取请求。
PF_REQ:当总线空闲,可以进行读取,且此时没有refill的请求时,进入PF0开始预取第一组数据;当有refill请求且refill的Cache line没有命中Prefetch line时,跳转回IDLE。
PF0:当总线传输发生error时,跳转到INV代表数据传输无效;当预取的数据有效,即跳转到PF1,取下一组数据。
PF1:当总线传输发生error时,跳转到INV代表数据传输无效;当预取的数据有效,即跳转到PF2,取下一组数据。
PF2:当总线传输发生error时,跳转到INV代表数据传输无效;当预取的数据有效,即跳转到PF3,取下一组数据。
PF3:当总线传输发生error时,跳转到INV代表数据传输无效;当预取的数据有效,即跳转到IDLE,结束预取。
INV:当出现传输error时就会跳转到这个状态,当总线传来Last信号,代表这次传输结束,跳转回IDLE。
从预取缓存区中读取指令到Cache中的控制状态机(图4):
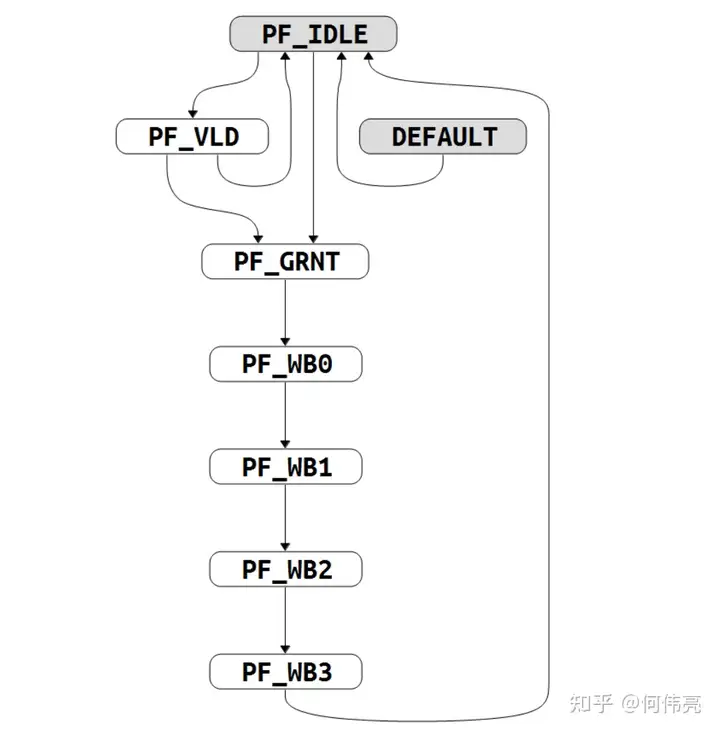
PF_IDLE:当发生Icache invalid时,维持在PF_IDLE状态;当预取完成后(即预取到最后一组数据时),此时如果Prefetch line命中refill的Cache line时,跳转到PF_GRNT;如果Prefetch line没有命中refill的cacahe line则跳转到PF_IDLE;如果Prefetch完成时没有refill请求则跳转到PF_VLD。
PF_VLD:跳转条件与跳转的目的状态与PF_IDLE相同,该状态用于当完成预取后,但又没有出现refill请求时,等待request请求出现。
PF_GRNT:当Prefetch line命中refill的Cache line时,会跳转到该状态,该状态会跳转到PF_WB0开始将第一组数据从预取Buffer中取到Icache中。
PF_WB0:从Prefetch Buffer中读取第一组数据到Icache中,然后跳转到PF_WB1。
PF_WB1:从Prefetch Buffer中读取第二组数据到Icache中,然后跳转到PF_WB2。
PF_WB2:从Prefetch Buffer中读取第三组数据到Icache中,然后跳转到PF_WB3。
PF_WB3:从Prefetch Buffer中读取第四组数据到Icache中,完成数据的读取后跳转回IDLE。
玄铁C910的指令高速缓存采用两路组相联结构,为了减少并行访问两路缓存的功耗,采用路预测技术,仅在低功耗模式下开启,即MHINT.IWPE位为1时,主要使用两比特标志预测哪一路,每一个比特对应一路,会作为Icache data_array的使能信号,若预测为该路时才会访问该路的data_array,进而降低功耗。当两位都为高时,则代表不进行预测,两路都访问。路预测主要分为顺序路预测和跳转路预测,当访问Icache的同时也会访问precode的信息,得出该指令是否为跳转指令,若为跳转指令则下一个pc执行跳转路预测,反之,则执行顺序路预测。
顺序路预测的流程如图5所示:

always @( inner_way_pred_default[1:0]
or ipctrl_pcgen_inner_way_pred[1:0]
or inc_pc[4:3])
begin
if(inc_pc[4:3] == 2'b10 || inc_pc[4:3] == 2'b11)
inner_way_pred[1:0] = ipctrl_pcgen_inner_way_pred[1:0];
else
inner_way_pred[1:0] = inner_way_pred_default[1:0];
end
assign inner_way_pred_default[1:0] = (ipctrl_pcgen_inner_way1 || ipctrl_pcgen_inner_way0)
? {ipctrl_pcgen_inner_way1, ipctrl_pcgen_inner_way0}
: 2'b11;
复制图中的取指令指的是获取PC的指令地址,通过PC判断是否位于缓存行边界,若位于同一个Cache line中则可以使用之前的命中信息,因为如果顺序访问的话,取完一个Cache line的数据需要四次,因此,如果当前的pc位于Cache line的后半行时,会根据前面一半的Cache line的命中信息来预测当前该取哪一路,因为顺序取指肯定会位于同一个Cache line中,所以这种情况下,预测的准确度会比较高。但当当前pc属于Cache line的前半行时,会根据之前多次路命中的情况来决定预测哪一路或不进行预测,使用一个3比特的计数器来进行预测,当Cache的way0命中时该计数器会减一,way1命中时计数器加一,当计数器等于3’b000时路预测为way0,当计数器等于3‘b111时路预测为way1,其它情况下,不进行预测。
always @(posedge forever_cpuclk or negedge cpurst_b)
begin
if(!cpurst_b)
hit_cnt[2:0] <= 3'b011;
else if(icache_way0_hit)
hit_cnt[2:0] <= hit_cnt_sub[2:0];
else if(icache_way1_hit)
hit_cnt[2:0] <= hit_cnt_add[2:0];
else
hit_cnt[2:0] <= hit_cnt[2:0];
end
assign hit_cnt_sub[2:0] = (hit_cnt[2:0] == 3'b000)
? 3'b000
: hit_cnt[2:0] - 3'b1;
assign hit_cnt_add[2:0] = (hit_cnt[2:0] == 3'b111)
? 3'b111
: hit_cnt[2:0] + 3'b1;
assign ipctrl_pcgen_inner_way0 = (hit_cnt[2:0] == 3'b000);
assign ipctrl_pcgen_inner_way1 = (hit_cnt[2:0] == 3'b111);
复制访问Cache时,虽然不会对无效数据路进行访问,但还是会对两路的Tag进行比较,判断路预测是否正确,当预测失败时,需要重新发送该PC,使用正确的命中信息重新访问Icache读取指令包,因此在路预测失败时会影响取指的性能,需要花更多的代价进行取指,得到命中信息后还需要更新上述提到的计数器。
跳转路预测的流程如图6所示:
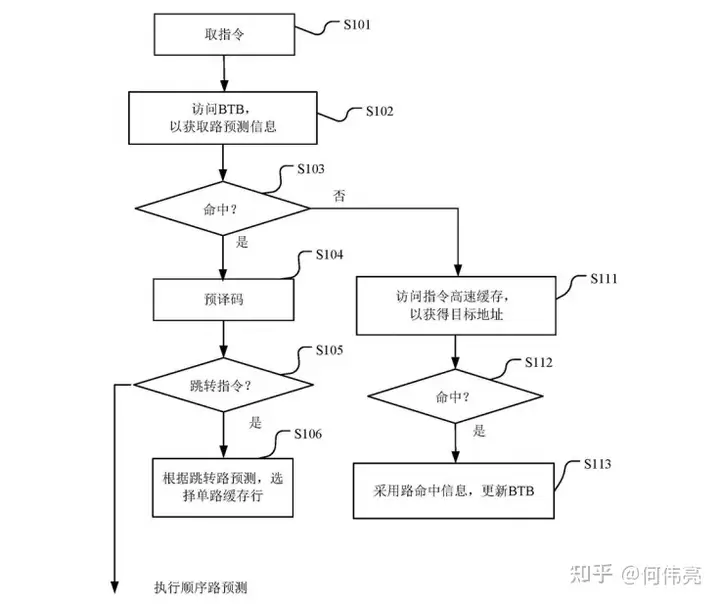
当从Icache的precode array中读出指令的预译码结果,若发现为跳转指令,会进行跳转路预测,或者当发生异常或者分支预测失败需要change flow时,或其他需要reissue的情况时,也会进行跳转路预测,通过PC访问BTB获取路预测信息。然后根据Tag的比较结果判断是否命中,如果发生预测失败,则需要重新发送该PC重新访问Icache读取指令包,同时将正确的路命中信息更新到BTB中。
begin
if(pcgen_chgflw_higher_than_ib)
chgflw_way_pred[1:0] = 2'b11;
else if(ibctrl_pcgen_pcload)
chgflw_way_pred[1:0] = ibctrl_pcgen_way_pred[1:0];
else if(ipctrl_pcgen_chgflw_pcload)
chgflw_way_pred[1:0] = ipctrl_pcgen_chgflw_way_pred[1:0];
else if(ipctrl_pcgen_reissue_pcload)
chgflw_way_pred[1:0] = ipctrl_pcgen_reissue_way_pred[1:0];
else
chgflw_way_pred[1:0] = ifctrl_pcgen_way_pred[1:0];
end
复制路预测信息的来源(优先级从高到低):
1、当退休单元(rtu)、执行单元(iu)、addrgen模块给IFU传来chgflw信号,代表分支预测失败需要重定向或者发生异常需要重定向时(rtu传来的是异常信号,iu传来的是分支预测失败信号,addrgen模块传来的是预译码后与预测地址比较发现不一致的预测失败信号),不进行路预测,即两路都使能。
2、来自IB阶段的pcload信号,当IB阶段发现指令缓冲区(Ibuffer)满了,就需要将即将要进入Ibuffer中的那条指令的PC重新发射,而该指令的正确路命中信息已经在IP阶段得到,因此需要将这些路预测信息传递,使得该PC使用正确的路命中信息作为路预测的结果,或者在IB阶段返回地址预测器(RAS)和间接分支预测器(Ind_BTB)做出了预测时,由于RAS和Ind_BTB中没有存储路预测信息,所以对于RAS和Ind_BTB路预测均为不进行预测。
3、来自IP阶段的pcload信号,当BHT预测跳转时,使用BTB传来的路预测信息。根据BHT的结果决定是在taken或者ntaken的表中取出预测的信息,在根据Cache的哪一路命中取出BTB中存储的路预测信息,用该预测信息,作为预测结果。
4、来自IP阶段的reissue_pcload信号,代表当路预测发生错误时,即预测的路取出的Tag没有命中时,就需要reissue该pc,同时将实际的命中信息,作为重新发送该pc时的路预测信息。
5、来自IF阶段的pcload信号,当L0_BTB预测跳转时,使用L0_BTB的路预测信息。
本文为《玄铁C910微架构学习》系列的第一篇文章,对高性能处理器玄铁C910的L1指令缓存的组成结构进行了详细的介绍,针对玄铁C910扩展的Cache操作的具体过程也进行了介绍,同时还介绍了指令高速缓存中使用的提高性能的指令预取技术和降低功耗的路预测技术。
本系列后续的文章将对玄铁C910处理器其它部分的具体工作过程和相关的优化技术进行详细的分析,希望能给想要想学习高性能处理器的人提高一些帮助。
[1] Patterson, David A & Hennessy, John L. (2017). Computer Architecture: A Quantitative Approach (The Morgan Kaufmann Series in Computer Architecture and Design).(6th ed.).
[2] 玄铁C910用户手册
[3] 刘东启,江滔,陈晨. 用于指令高速缓存的路预测方法、访问控制单元以及指令处理装置[P]. 开曼群岛:CN112559049A,2021-03-26.
[4] https://github.com/T-head-Semi/openc910
[5] Chen C, Xiang X, Liu C, et al. Xuantie-910: A commercial multi-core 12-stage pipeline out-of-order 64-bit high performance risc-v processor with vector extension: Industrial product[C]//2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020: 52-64.