https://zhuanlan.zhihu.com/p/510954835复制
很多时候有测试有数据, 却没有分析, 这样的性能数据是有隐患的.
STREAM测试足够简单, 4个测试用例, 每个用例3行核心代码, 毫无疑问是个"简单"的测试, 但要做好缺不容易. 本文以Intel平台为例, 虽然特性可能不同, 但是方法同样适用于其他平台.
测试环境使用双路Intel(R) Xeon(R) Platinum 8160, 开启NUMA, 单路配置如下:
软件环境配置如下:
测试用例:
先使用gcc, 编译命令如下:
CC = gcc
CFLAGS = -O2 -fopenmp
stream: stream.c
$(CC) $(CFLAGS) $< -o $@复制执行得到如下结果:
#./stream
Function Best Rate MB/s Avg time Min time Max time
Copy: 148668.3 0.001121 0.001076 0.001132
Scale: 139143.4 0.001178 0.001150 0.001285
Add: 137631.0 0.001763 0.001744 0.001796
Triad: 149618.5 0.001609 0.001604 0.001621复制现在我们有了真实的数据, Job Done? 真实的数据并不意味着是有效的数据. 如果只能看到一个测试结果, 这很可能是不够的.
有效的性能测试要求数据是可重复的, 我们先重复10次. 命令输出稍有过滤, 不反应在命令行上, 下同.
#for i in {0..9}; do ./stream; done
Function Best Rate MB/s
Triad: 150086.9
Triad: 140199.6
Triad: 158850.1
Triad: 126572.7
Triad: 156869.7
Triad: 153356.6
Triad: 147233.1
Triad: 135064.1
Triad: 147969.0
Triad: 148056.0复制这样看来我们的测试数据并没有可重复性, 可能有以下原因:
不管怎么样, 我们先去理解用例.
STREAM包括4个子用例:
| 子用例 | 具体操作 | 单次操作带宽统计(Byte) |
| Copy | c[j] = a[j] | 16 |
| Scale | b[j] = scalar*c[j] | 16 |
| Add | c[j] = a[j]+b[j] | 24 |
| Triad | a[j] = b[j]+scalar*c[j] | 24 |
单次操作统计的带宽比较直接, 因为a/b/c都是double类型8个字节, 以Triad为例, 每次操作都访问了a, b和c的一个元素, 所以算作24字节. Triad测试核心代码如下:
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
a[j] = b[j]+scalar*c[j];复制稍微阅读代码就知道STREAM并不是开箱即用的类型, 而需要根据不同机器进行配置, 我们第一次测试并没有考虑这点:
* 1) STREAM requires different amounts of memory to run on different
* systems, depending on both the system cache size(s) and the
* granularity of the system timer.
* You should adjust the value of 'STREAM_ARRAY_SIZE' (below)
* to meet *both* of the following criteria:
* (a) Each array must be at least 4 times the size of the
* available cache memory. I don't worry about the difference
* between 10^6 and 2^20, so in practice the minimum array size
* is about 3.8 times the cache size.
* Example 1: One Xeon E3 with 8 MB L3 cache
* STREAM_ARRAY_SIZE should be >= 4 million, giving
* an array size of 30.5 MB and a total memory requirement
* of 91.5 MB.
* Example 2: Two Xeon E5's with 20 MB L3 cache each (using OpenMP)
* STREAM_ARRAY_SIZE should be >= 20 million, giving
* an array size of 153 MB and a total memory requirement
* of 458 MB. 复制另外, STREAM是用来测试系统内存带宽的, 我们有必要了解下系统的理论带宽:
64bit/s * 12channel * 2666Mhz = 255936MB/s复制我们第一次拿到的数据并没有离谱到比理论带宽更高, 但这只是运气. 如果我们的测试就停留在这里, 那么这并不是好运气, 因为我们并没有发现该测试的问题.
按照上面stream.c的注释, 数组大小需要设置为至少4倍cache大小, 并以Xeon E3的L3大小为例. 我们现在倾向于相信Dr. Bandwidth的判断, 但是也要提出自己的问题:
我们使用以下STREAM_ARRAY_SIZE进行测试:
这里我们能看到几个现象:
暂时不纠结这几个问题, 因为这可能只是中间状态.

一个测试正不正确可以通过多方来论证, 我们知道STREAM是标准测试用例, 同样Intel的mlc也是, 现在用mlc来跑一下数据.
#./mlc --max_bandwidth
Intel(R) Memory Latency Checker - v3.9a
All Reads 223685.88
3:1 Reads-Writes : 204527.66
2:1 Reads-Writes : 203232.96
1:1 Reads-Writes : 187929.30
Stream-traid like: 199753.85复制可以看到mlc和STREAM的数据并不一致, 所以至少有一个数据是和预期不符的.
TACC Technical Report TR-17-01 Benchmarking the Intel®Xeon®Platinum 8160 Processor 使用了和我们测试平台接近的配置, 也是双路8160, 它的测试结果和mlc相近, 但是这个文档有个问题, 里面并没有描述测试的具体步骤.

Daniel Molka等人在 Memory Performance and Cache Coherency Effects on an Intel Nehalem Multiprocessor System 提到:
== ref begin ==
Our C benchmarks are comparable to STREAM(2) as they use the same access patterns. However, there are several differences compared to the original version:
== ref end ==
John McCalpin在自己博客里面提到:
== ref begin ==
== ref end ==
现在我们有了多个方向可以继续深入.
从现在开始, 默认我们会设置cpu亲和性, 这对测试的性能和稳定性都有帮助, 和STREAM本身的测试目标也是一致的. 另外, 从各种渠道能了解到, 超线程使用对最大内存带宽并没有帮助, 一般都是建议关闭超线程进行测试, 我们这里没有关闭超线程, 而是单个core上只是用一个thread, 注意这和直接关闭超线程还是有区别的, 细节这里不再深入.
CC = gcc
CFLAGS = -O2 -fopenmp
CFLAGS += -DSTREAM_ARRAY_SIZE=80000000
stream: stream.c
$(CC) $(CFLAGS) $< -o $@复制OpenMP绑核操作通过如下环境变量:
OMP_PLACES=cores OMP_PROC_BIND=close OMP_NUM_THREADS=48复制重复跑10次, 可以发现性能比较稳定, 另外性能比之前的测试有提升, 但是还未达到上面别人测试的190+GB/s.
#for i in {0..9}; do \
> OMP_PLACES=cores OMP_PROC_BIND=close OMP_NUM_THREADS=48 ./stream; done
Function Best Rate MB/s
Triad: 152465.3
Triad: 154007.7
Triad: 153062.2
Triad: 153388.8
Triad: 152586.6
Triad: 151996.2
Triad: 153001.2
Triad: 153576.0
Triad: 153330.4
Triad: 152719.7复制4个测试用例的表现情况
#OMP_PLACES=cores OMP_PROC_BIND=close OMP_NUM_THREADS=48 ./stream
Function Best Rate MB/s
Copy: 136942.9
Scale: 135235.4
Add: 151359.2
Triad: 153219.5复制其实上面已经提到, 一般情况下cpu在写cacheline之前需要先读入cacheline, 导致的结果就是:
为了验证这个, 编译时调大NTIMES, 通过pcm来查看内存带宽, 确实可以看到整体带宽接近200000MB/s, 而这个值比STREAM本身输出的带宽更接近测试目的.
|---------------------------------------||---------------------------------------|
|-- System Read Throughput(MB/s): 144211.22 --|
|-- System Write Throughput(MB/s): 58162.46 --|
|-- System Memory Throughput(MB/s): 202373.69 --|
|---------------------------------------||---------------------------------------|复制如果想更细致的观察每种子测试的情况, 可以稍微修改代码, 比如循环里面只保留Copy操作:
|---------------------------------------||---------------------------------------|
|-- System Read Throughput(MB/s): 133023.05 --|
|-- System Write Throughput(MB/s): 66650.63 --|
|-- System Memory Throughput(MB/s): 199673.69 --|
|---------------------------------------||---------------------------------------|复制这里读写比呈现出明显的2:1.
到现在我们解释了, 为什么很多测试报告中Triad比Copy高的一种可能, 这个可能性不只一种.
为了解决write allocate导致的统计偏差, 我们考虑使用non-temporal store (NT)来避免write allocate, 从而使STREAM自己的统计值更加反应真实的内存带宽. 因为gcc 6.5.1不能生成相应的NT代码, 这里使用Intel提供的icc来编译:
ICCFLAGS = -O3 -xCORE-AVX2 -ffreestanding -qopenmp
ICCFLAGS += -DSTREAM_ARRAY_SIZE=80000000
stream.icc: stream.c
icc $(ICCFLAGS) $< -o $@复制执行结果如下, 可以看到STREAM的输出已经大幅提升, 接近上面pcm获取的物理带宽, 也接近其他测试比如TACC的值.
#OMP_PLACES=cores OMP_PROC_BIND=close OMP_NUM_THREADS=48 ./stream.icc
Function Best Rate MB/s
Copy: 183038.7
Scale: 183276.2
Add: 197941.8
Triad: 196963.8复制我们可以验证不同编译器的编译结果:
#objdump -d stream | grep -c movnt
0
#objdump -d stream.icc | grep -c movnt
7复制现在看下NT store的情况下, STREAM的输出结果和pcm是否有差异. 以Copy子用例(注释掉其他测试用例代码), 可以看到STREAM的输出和pcm的输出已经基本一致. 另外, 还可以关注下pcm里面的System Read/Write Throughput, 如果我们调整了STREAM_ARRAY_SIZE会有什么现象, 这里不再展开.
|---------------------------------------||---------------------------------------|
|-- System Read Throughput(MB/s): 90601.87 --|
|-- System Write Throughput(MB/s): 93221.18 --|
|-- System Memory Throughput(MB/s): 183823.05 --|
|---------------------------------------||---------------------------------------|复制如果我们还想确定icc是不是有其他优化, 或者就想看下icc在打开关闭NT store的区别, 我们可以关闭NT store试试:
ICCFLAGS = -O3 -xCORE-AVX2 -ffreestanding -qopenmp
ICCFLAGS += -DSTREAM_ARRAY_SIZE=80000000
ICCFLAGS += -qopt-streaming-stores never
stream.icc: stream.c
icc $(ICCFLAGS) $< -o $@复制测试结果和gcc的接近
#OMP_PLACES=cores OMP_PROC_BIND=close OMP_NUM_THREADS=48 ./stream.icc
Function Best Rate MB/s
Copy: 136866.1
Scale: 136431.3
Add: 151861.5
Triad: 154430.0复制需要指出的是, non-temporal store的实现在Intel的cpu上都不尽相同, 比如这篇 Measuring Memory Bandwidth On the Intel® Xeon® Processor 7500 series platform 提到:
As noted above, to get an accurate memory bandwidth measurement for a given platform, a non-cacheable write transaction is typically used for the write transaction portion of the STREAM benchmark. However, due to the way the cache coherency protocol was designed for the Intel® Xeon® processor 7500/6500 series processors, even issuing a non-cacheable write instruction will not prevent a third read to occur when running the STREAM triad. The coherency protocol for the Intel Xeon processor 7500/6500 processors must check coherency with the IOH device before each write. IOH coherency can be checked either with a read for ownership transaction (occurs before a cacheable write) or a separate read must be made to main memory where a small coherency buffer is stored (occurs before a non-cacheable write). So both Measuring Memory Bandwidth White Paper 3 cacheable and non-cacheable writes will cause an “extra” read transaction to occur which is not counted by the STREAM benchmark. The net result of the coherency protocol for the Intel Xeon processor 7500/6500 series processor, is the STREAM benchmark will always return a bandwidth result which is 25% lower than what the platform is actually capable of.
这里面有2组测试:
我们需要回答以下问题:
这里我们要重新看下mlc的结果:
#./mlc --max_bandwidth
Intel(R) Memory Latency Checker - v3.9a
All Reads 223685.88
3:1 Reads-Writes : 204527.66
2:1 Reads-Writes : 203232.96
1:1 Reads-Writes : 187929.30
Stream-traid like: 199753.85复制如果相信mlc的结果, 内存读写性能并不是完全对称的, 和读写比例有一定的关系, 这样就解释了上面的2个问题. 同时也告诉我们, 相同的Triad测试, write allocate和non-temporal store的真实读写比例也是不一样的, 对于内存子系统并不是完全一致的压力, 这也会影响我们对数据的解读.
我们通过改变线程数量来测试内存带宽的可扩展性, 仍然使用icc编译出来的STREAM版本, 因为要涉及多线程, 我们测试2种不同的OpenMP绑核方式.
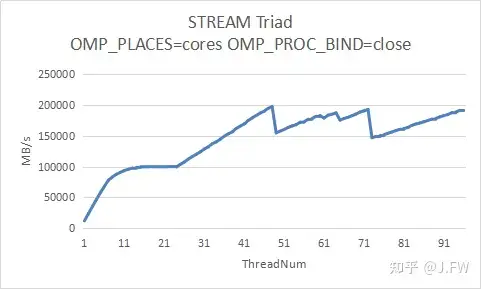
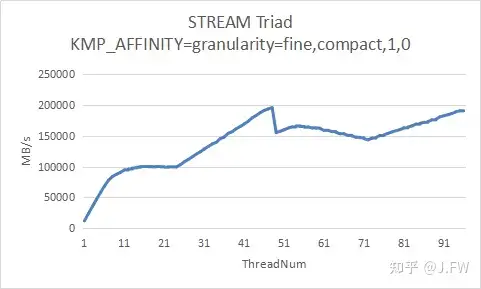
可以看出ThreadNum在1~48的时候, 2组测试结果基本相同, 但是当部分物理核的2个逻辑核都用起来后, 因为绑核的原因出现了一定偏差, 而且这两盒TACC的测试结果也不相同, 包括ThreadNum<=48的曲线.
现在的问题是, 我们有没有必要分析ThreadNum在49~96的情况, 注意STREAM是要测试内存带宽及其扩展性, STREAM并不是要测试任意情况下的带宽, 但不管怎么样, 我们需要有进一步分析的能力.
接着上面的可扩展性, 我们这里只看一个差别, 49线程的性能下降为什么那么大. 首先我们知道OpenMP会把for循环拆成一段一段分配给各个线程, OpenMP有多种schedule模式, 一般情况下会认为通过static的方式, 把任务一次性拆分成大小相近的子任务(chunk), 每个线程处理一个子任务, 查找相应文档没有找到OpenMP运行时打印chunk size的配置, 所以我们手动来确认.
因为这是个cpu bound的程序, 容易获得执行循环的汇编:
0x0000000000401c2e <+346> vmulpd 0x6055c0(%rcx, %rdx, 8),%ymm0,%ymm1
=> 0x0000000000401c37 <+355> vmovntpd %ymm1,0x2685f7c0(%rcx,%rdx,8)
0x0000000000401c40 <+364> add $0x4,%rdx
0x0000000000401c44 <+368> cmp %rdi,%rdx
0x0000000000401c47 <+371> jb 0x401c2e <L_main_333__par_region11_2_5+346>复制将其中的%rdi打印出来即可:
(gdb) info register rdi
rdi 0x18e98c 1632652复制这个测试使用STREAM_ARRAY_SIZE=80000000, 以及48并发, 每个chunk大小约为1632653. 我们可以将所有线程的rdi都打印出来进行验证, 所有chunk大小接近.
现在回答这个就比较简单了, OpenMP把任务平均分成了49份, 分别让cpu 0,1, ..., 48来执行, 而cpu 0和48是一个物理核上的2个超线程, 明显低于2个物理核产生的带宽, 但并不是简单的1/2关系. 如果我们还想往细了看, 在48并发的测试:
#OMP_PLACES=cores OMP_PROC_BIND=close OMP_NUM_THREADS=48 ./stream.icc
== cpu 24 ==
+ 99.43% 99.43% stream.icc stream.icc [.] main
388,960,166 instructions # 0.18 insns per cycle
== cpu 8 ==
+ 98.90% 98.90% stream.icc stream.icc [.] main
387,721,925 instructions # 0.18 insns per cycle
== cpu 48 ==
+ 98.21% 98.11% stream.icc stream.icc [.] main
384,367,805 instructions # 0.18 insns per cycle复制49并发的测试:
#OMP_PLACES=cores OMP_PROC_BIND=close OMP_NUM_THREADS=48 ./stream.icc
== cpu 24 ==
+ 73.45% 73.45% stream.icc stream.icc [.] main
+ 25.65% 25.65% stream.icc libiomp5.so [.] _INTERNALc8ed1ec4::__kmp_wait_template...
508,436,164 instructions # 0.24 insns per cycle
== cpu 8 ==
+ 75.07% 75.07% stream.icc stream.icc [.] main
+ 24.08% 24.% stream.icc libiomp5.so [.] _INTERNALc8ed1ec4::__kmp_wait_template...
505,000,306 instructions # 0.24 insns per cycle
== cpu 0 ==
+ 99.75% 99.55% stream.icc stream.icc [.] main
280,565,561 instructions # 0.13 insns per cycle
== cpu 48 ==
+ 99.80% 99.80% stream.icc stream.icc [.] main
281,612,801 instructions # 0.13 insns per cycle复制现在我们清楚, 49并发的时候测出来的性能慢是因为47个快线程需要等待2个慢线程, 所以49并发可以认为不是STREAM测试的有效case.
虽然分析了这么多, 但是还有很多地方可以继续: