https://www.cnblogs.com/charlieroro/p/14182908.html复制
本文翻译自Analysis of the Effect of Core Affinity on High-Throughput Flows
网络吞吐量正在朝更高的数据传输率发展,与此同时,终端系统的处理器也在朝着多核发展。为了在多核终端系统上优化高速数据传输,像网络适配器卸载以及性能调优等技术已经受到了广泛的关注。此外,已经出现了一些多线程网络接收处理的方法。但对于如何调参,以及使用哪个卸载才能达到更高的性能的关注度远远不够,而且对于为什么这么设定的理解也远远不足。本论文会结合前人的研究成果来跟踪高速TCP流下,终端系统出现性能瓶颈的源头。 出于本论文的目的,我们认为协议处理效率是指实现每单位(以Gbps为单位)吞吐量所消耗的系统资源(例如CPU和缓存),并使用低级系统事件计数器测量消耗的各种系统资源的总量。亲和性或核绑定用于决定终端系统上负责处理中断,网络和应用的处理核。我们得出亲和性对协议处理的效率会产生至关重要的影响,三种不同的亲和性方案下网络接收处理的性能瓶颈会发生急剧变化。
由于多种物理限制,处理器内核达到了时钟速度的“极限”,此时CPU时钟频率将无法增加。而另一方面,光纤网络中的数据速率却在不断提高,更好的光学和精密设备改善了散射,吸收和离散的物理事实[1]。尽管物理层取得了这些进步,但我们仍然受到用于协议处理的系统软件层面的限制。因此,为了提高应用层的网络吞吐量,高效的协议处理和适当的系统层面的调优是必要的。
TCP是一种可靠的,面向连接的协议,它会保证发送者到接收者之间的数据的顺序,这样做会将大部分协议处理推到终端系统上。实现TCP协议的功能需要一定程度的复杂性,因为它是一个端到端协议,因此所有功能都需要在端系统中进行检测。这样,提升现有TCP实现效率的途径分为两类:首先,使用卸载尝试将TCP功能放到协议栈之下,以此来达到更好的传输层效率;其次,通过调参,但这些参数会给上层(软件,系统和系统管理)带来复杂性。
调参主要关注亲和性。亲和性(或核绑定)从根本上说是关于在网络多处理器系统中的哪个处理器上使用哪些资源的决定。Linux网络接收处理消息在现代系统上主要有两种实现方式:首先通过中断处理(通常会联合处理),一旦NIC接收到特定数量的报文后,就会向处理器发起中断,然后NIC会通过DMA将报文传输到处理器(应该是先将报文放到DMA,然后再向处理器发起中断),随后NIC驱动核OS内核会继续协议处理,直到给应用准备好数据;其次,通过NIC轮询(在Linux中称为NEW API,NAPI),这种方式下,内核会轮询NIC来检查是否有需要接收的网络数据,如果存在,则内核将根据传输层协议处理数据,以便根据socketAPI将数据将数据传递给应用程序。不论哪种方式,都存在两类亲和性:1)流亲和性,用于确定那个核将会中断处理网络流;2)应用亲和性,用于确定哪个核会执行接收网络数据的应用进程。流亲和性通过/proc/irq//smp affinity中的十六进制核描述符进行设置,而应用亲和性可以通过taskset或类似的工具进行设置。因此一个12核的终端系统,存在144种(12^2)可能的流和应用亲和性。
在本论文中,我们将通过详细的实验扩展先前的工作[3],[4],使用单个高速TCP流对每个亲和性组合进行压力测试。我们会使用终端系统的性能内省来理解选择的亲和性对接收系统效率的影响。我们可以得出有三种不同的亲和性场景,且每种场景下的性能瓶颈差异很大。
目前已有多项研究评估了多核系统中的网络I/O性能[5]–[8]。当前内核中一个主要的提升是默认启用NAPI [9]。NAPI用于解决接收活锁问题[8],即CPU消耗大量周期来处理中断。当一个机器进入活锁状态时,由于大部分的CPU周期用于处理硬中断和软中断上下文,它会丢弃报文。启用了NAPI的内核会在高速率下切换到轮询模式来节省CPU周期,而不依赖纯中断驱动模式。10 Gbps WAN上的报文丢失和性能说明可以参见[10],[11]。[12]更多关注延迟的架构来源,而不是基础数据中心的链接。改善终端系统瓶颈不利影响的另一个方面涉及重新考虑终端系统的硬件架构。传输友好的NIC,以及新的服务器架构可以参见[12],[14]。不幸的是,这些戏剧性的变化很少能用于已部署的、用于测试目的的商品终端系统类型。
现代NIC支持多接收和传输描述符队列。NIC使用过滤器将报文发送到不同的队列,以此来在多个核上分担负载。启用Receive-Side Scaling (RSS) [15]后,不同流的报文会发送到不同的接收队列,并由不同的CPU处理。RSS需要NIC的支持。Receive Packet Steering (RPS) [16]是RSS的内核软件版本。它会为接收的报文集选择CPU核来执行协议处理。Receive Flow Steering (RFS) [17]与RPS类似,但它会使用TCP四元组来保证一条流上所有的报文会进行相同的队列和核。所有这些扩展技术目的都是为了提升多核系统的整体性能。
当执行网络处理[6]时,通常明智的做法是选择共享相同的最低缓存结构的核[18]。例如,当一个给定的核(如核A)被选择来执行协议/中断处理时,与核A共享L2缓存的核应该执行相应的用户应用程序。这样做会减少上下文切换,提升缓存性能,最终增加总体吞吐量。
Irqbalance守护进程会执行轮询调度来在多核上进行中断的负载均衡。但它也会造成负面影响,见[19], [20]。我们需要更明智的方法,而且需要控制选择处理中断的核。在我们的实验中禁用了irqbalance守护进程。
暂停帧[21]可以允许以太网通过流控制阻止TCP,因此,当仅需要在路由器或交换机上进行临时缓冲时,可以避免TCP窗口的倍数减小(避免)。为了实现该功能,支持暂停帧的以太网设备会在每个链路中使用闭环过程,在这种链路中,发送设备知道需要缓冲帧的传输,直到接收器能够处理它们为止。
巨帧(Jumbo Frames)仅仅是个以太帧,但它的长度远大于IEEE标准的1500字节的MTU。在大多数场景下,当使用Gigabit以太网时,帧的大小可以达到9000字节,这样做可以通过增加增加有效负载与帧头大小的比率来获得更好的协议效率。虽然以太速度从40Gbps提升到了100Gbps,但9000字节的帧大小的标准并没有发送变化 [22]。原因是由于存在各种分段卸载(segmentation offloads)。Large/Generic Segment Offload (LSO/GSO) 和Large/Generic Receive Offload (LRO/GRO)与当代路由器和交换机中的以太网实现相结合,来在当条TCP流上发送和接收非常大的帧,这种方式下唯一的限制因素是协商的传输速率和错误率。
本研究不会直接关注如何在长距离上移动大量数据,一些终端系统应用程序已经实现了多种方式,这些方式有助于有效地利用TCP [23]–[26]。这些成熟应用背后的总体思路是使用多条TCP流来处理应用层的传输,并将这些流的处理和重组分配给多个处理器[27]–[29]。大部分这些应用同样能够利用基于UDP的传输层协议,如RBUDP [30] 和UDT [31]。
目前已经有很多协议专门用于在封闭的网络(在数据中心内或数据中心之间)中快速可靠地转移大量数据。最近,这些协议专注于如何将数据从一个系统的一块内存直接转移到另一块内存中,两个例子是RDMA [32] 和 InfiniBand [33]。这些协议的共同点是它们依赖于终端系统之间相对复杂,健壮和可靠的中间网络设备。
以前,我们研究了亲和性对终端系统性能瓶颈的影响 [3],并得出亲和性对端到端系统的高速流的影响巨大。此研究并没有深究不同亲和性场景下终端性能瓶颈发生的位置,目标是确定这些亲和性场景下的性能瓶颈发生在哪里,并评估新的Linux内核(前面使用的是Linux 2.6版本的内核)是否解决了这些问题。
各种NIC卸载提供了很多有用的参数。NIC厂商通常会提供一些建议来指导用户如何调节系统,以充分利用其高性能硬件。[34]提供了宝贵的Linux调参资源,这些资源是通过在ESnet的100 Gbps测试平台上进行仔细的实验获得的。ESnet提供了很多演示文稿,详细介绍了实验中获得的调优建议,但很少有经验证明这些调优建议和卸载的原理。
本论文中,我们将提供多线程协议处理,或将协议处理推送到协议栈的不同组件中。我们将努力证明参考空间局部性在终端系统中跨多条流的数据流处理中的重要性。因此,这些实验中引入了iperf3 [35] 来通过单条高速TCP流来进行压力测试,该测试会使流量达到终端系统的网络I/O上限。注意,这并不是一个实际案例,实践中,如GridFTP [23] 这样的应用会通过多条流来达到更快的传输速率,性能也更加可预测,但在实践中应谨慎使用这种工具(尤其使在长距离移动大量数据时)。但理解终端系统中数据传输的限制非常重要(最好只用一个流即可完成)。
为此,我们引入了两台服务器,连接延迟< 1ms RTT,与我们之前使用ESnet Testbed的95ms RTT光纤环路进行的实验[3]相反。循环测试可以有效地观测长距离下TCP带宽的行为,我们的目标是进行压力测试,然后分析接收端的性能效率。
本实验中的系统都运行在Fedora Core 20上,内核为3.13。使用最新内核的原因是,假设该内核已经引入了最新的网络设计。
用于生成TCP流的应用为iperf3。为了确保将压力施加在终端系统上,传输使用了零拷贝模式(使用TCP sendfile系统调用来避免不必要的拷贝以及防止耗尽发送端系统的内存)。
被测试的系统是根据ESnet数据传输节点(DTN)的原型建模的。这类系统的目的是作为一个中间人,将大量数据从高性能计算机(HPCs)传输到消耗数据的中的终端系统上。实践中,这类系统必须能够通过InfiniBand主机总线适配器尽可能快地接收大量数据,然后将数据传输到本地磁盘或大规格的本地内存中,然后在高速(100 Gbps)WAN上向接收系统提供数据。它们使用了连接到Intel Sandy Bridge处理器的PCI-Express Generation 3。每个终端系统有两个六核处理器。由于Sandy Bridge的设计,特定的PCI-Express槽会在物理上直接连接到一个单独的socket(即CPU插槽,可以使用lscpu命令查看)。可以通过Quick Path Interconnect(QPI)提供的低级socket间的通信来克服此限制。图1站展示了该架构:
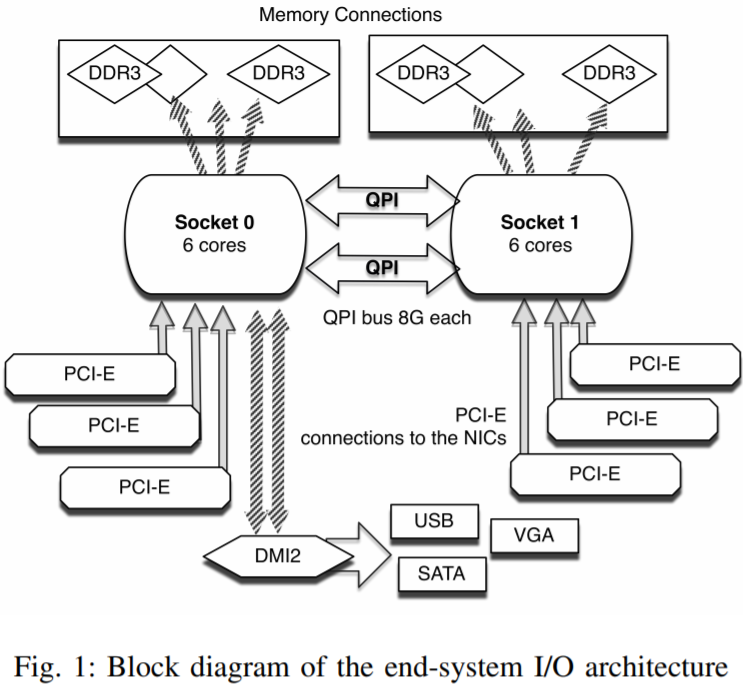
测试平台选用的是ESnet 100 Gbps 测试平台[37],它连接了(专门用于跨洲的)100 Gbps网络上的各种基于商用硬件的终端系统。该测试平台开放给了所有研究员,并提供了除了产生重复结果外的其他好处,因为整个测试床都是可保留的。这样就保证了不会存在竞争的流量。出于实验目的,需要在终端系统上测试性能瓶颈,而不是网络上。
Linux下图分析器使用的是Oprofile。Oprofile为Linux提供了轻量且高度内省的对系统硬件计数器[38]的监控功能。Oprofile的新工具ocount 和operf用于监控接收系统上的各种事件的计数器。在这些实验中,由于需要监视的接收者可能会超额,因此Oprofile的低开销和详细的Linux内核自检的能力是至关重要的。通过自省可以有效地测量operf的开销,并且发现该开销始终比受监视过程的计数结果至少小一个数量级。由于可用的计数器数量和自省功能,在这些实验中,Oprofile被选为英特尔的性能计数器监视器(PCM)。PCM还可以报告功耗,在未来的测试中可能会有用。
下面是实验中使用的自变量:
下面是实验中使用的因变量:
表1展示了实验环境的概况。发送和接收端系统的配置相同。
在执行144次实验前,都会运行一个脚本来检查系统的网络设定和调参,保证后续的实验的一致性。系统使用了ESnet的调参建议,保证TCP的高性能。然后进行初步测试,以确保没有异常会导致可变的带宽结果。发送系统设置为最佳亲和配置,且不会更改其亲和设置。在发送端会启动一个iperf3服务器,并放在那里运行。然后在接收端,使用嵌套的for循环shell脚本修改了设置所有rx队列的中断(/proc/irq/<irq#)设置到对应的/smp_affinity配置文件中,这样所有接收队列中的报文都会发往相同的核。内部for循环会在执行iperf3反向TCP零拷贝测试时运行operf,将接收者绑定到一个给定的核,并报告结果。通过这种方式来测试流和应用亲和性的所有组合。多次运行实验来保证结果的一致性。
我们现在核之前的工作[3]得出存在三种不同的性能类型,对应如下亲和性场景:1)相同的socket,相同的核(即流和应用都绑定到相同的核),这种情况下,吞吐量可以达到20Gbps;2)不同的socket(不同的核)可以达到的吞吐量为28Gbps;3)相同的socket,不同的核,吞吐量可以达到39Gbps。虽然变更了OS(从运行2.6内核的CentOS换到了运行3.13内核的Fedora),并更新了NIC驱动后的整体性能得到了提升,但三种亲和性设定下的相对性能并没有变化。
可以看到相同的socket,不同的核的吞吐量最大,原因是相同的socket使得缓存查询效率比较高,不同的核减少了中断上下文切换造成的性能损耗。因此将处理报文和应用放到相同的核上并不总是正确的,虽然提高缓存命中率,但有可能增加了中断上下文造成的损耗。
我们以前的工作表明,在系统级上超额的接收者的低吞吐量与缓存未命中之间存在关联。本次实验也会采纳这种观点,使用ocount来监控系统级别的硬件计数器,并使用operf来进行内核自省,以仔细检查接收者的性能瓶颈的根源。
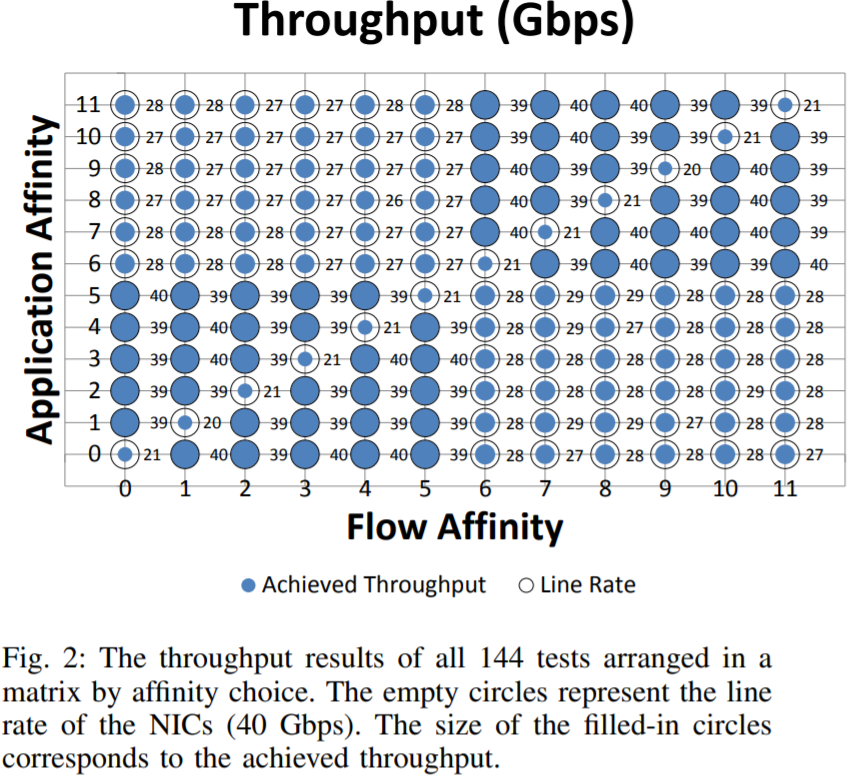
上图展示了144次实验结果,空心圆表示NIC给出的速率(见表1),填充的蓝色表示实际测量到的吞吐量,填充越多,表示实际吞吐量越大。
这个结论与上面给出的相同,左下角和右上角象限中的吞吐量最大,此时应用和流的亲和到相同的socket,但不同的核。
为了高效地传达144个测试的结果,我们使用了图2中的矩阵。Y轴表示应用亲和的核,数字0到11表示物理核。因此核0到5位于socket0,核6到11位于socket1(见图1)。上数矩阵有两个重要属性:
在后面的图中我们引入了Oprofile硬件计数器结果。当解释结果时,需要注意硬件计数器本身携带了一些信息。例如,可以简单地查看iperf3传输过程中退出的指令总数,但这并不包含实际传输的数据量。这样做的目的是为了查看效率,因此使用退出的指令数除以传输吞吐量(Gbps)作为结果。 由于每个测试的长度是相同,因此可以对结果进行归一化。
图3展示了每秒每GB的数据传输下退出的指令数。本图中的对角线展示了(当流和应用都亲和到相同的核时)处理效率低下。这种场景下,不仅仅吞吐量很低(见图2),而且处理效率也远远低于其他场景。在流亲和到socket0,应用亲和到socket1的情况下,需要在socket0和socket1之间通过更多的指令来移动数据。
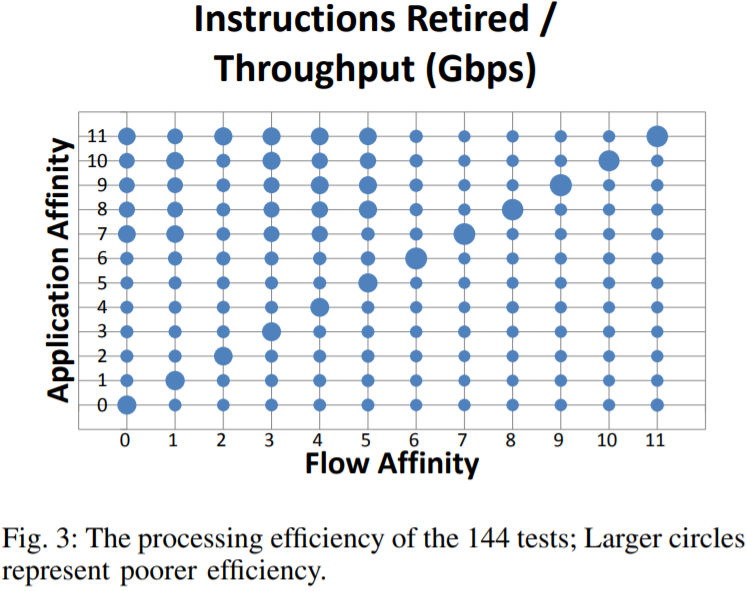
144次测试的处理效率,圆越大表示处理效率越低。
从图3可以看出缓存位置对缓存指令数的影响。距离越远,命中率约低,搜索量越大,导致需要的指令越多。
在上面提到的对角线场景中,用户的副本数决定了终端系统消耗的资源。从系统角度看,大量用于访问内存层次结构的指令恰恰证明了这一点(见图4,5,6)。主要注意的是这些图的标题进行了简化(具体意义参见解析)。此外,由于原始的计数器输出在此处的意义不大,因此使用了计数器的数据除以指令退出/吞吐量作为结果(图3)。
在应用和流亲和到不同核但相同socket的场景下,内存层级结构的事务似乎主导了主要的退出指令数。但这种情况下的传输接近线性,因此内存层次结构并不像是真正的瓶颈。经过初步分析,发现对于流和应用位于不同socket的场景,瓶颈可能是由于LOCK前缀引起的,因为使用方正在等待缓存一致性。
然而,对于应用和流亲和到不同socket的场景,只有非常少的一部分指令会用于内存层次结构的事务,尽管事实上用户副本会继续主导CPU消耗。这种情况下使用了很多计数器来监控并分析可能的瓶颈,包括硬件中断和由于LOCK前缀造成的CPU周期浪费,但都没有展现出与该亲和场景的关联性。

用于L2高速缓存事务中的已退出指令/吞吐量的比例,可以看出相同socket,但不同core的缓存命中率相对较高。

用最后一级高速缓存事务中的已退出指令/吞吐量的比例
有趣的是,在本对角线场景下,与内存层次结构相关的事务仅占了整体退出指令数的很小一部分。这种情况下,内省显示NIC驱动(mlx4 en)是主要的系统资源消耗者。将来会使用驱动程序自省调查这种情况下瓶颈的确切来源。

用于内存事务处理中的已退出指令/吞吐量的比例
本论文最重要的结论之一是系统内和系统间通信间的时钟速度壁垒的界线正在迅速模糊。当一个处理器核和另外一个核进行通信时,数据需要在系统(芯片)网络间进行传输。为了实现大规模数据复制和一致性,必须在WAN上进行数据的传输。那么这些网络有什么不同?WAN上对数据传输性能的影响正在持续变小,且网络也正在变得越来越可靠,越来越可重配置。同时,系统间的网络也变得越来越复杂(由于横向扩展系统和虚拟化),且有可能降低了可靠性(如由于节能有时需要降低芯片的某些部分或完全关闭它们的部分)。当讨论到亲和性,除了这些变化外,仍然需要关注其距离,本地性(无论网络的大小)。未来,最有效的解决方案可能不仅仅是将NIC集成到处理器芯片上[14],甚至有可能集成现有的I/O结构的功能,如北向桥。然而,这些可行性可能需要很多年才能够实现。
本研究给出了更确切的结论,即需要谨慎往一个芯片上添加更多的组件,这样有可能导致跨socket的性能变低。这些结论为以终端系统为主的吞吐量和延迟测试提供了重要的背景:在高吞吐量,高性能硬件上,端到端的TCP流的体系结构延迟源可能会发生巨大变化。
同时,也可以使用相同的方式来测试其他NIC和其他NIC驱动,看是否能够得出类似的结论。最近,中断合并和在NAPI之间自动切换的NIC驱动程序也正在研究中。此外,也在调研多流TCP和UDT GridFTP传输。未来的目标是实现一个轻量级中间件工具,该工具可以在更大程度上优化亲和性,并扩展已在缓存感知的亲和性守护程序[18]上的工作。
[1] G. Keiser, Optical Fiber Communications. John Wiley & Sons, Inc., 2003.
[2] C. Benvenuti, Understanding Linux Network Internals. O’Reilly Media, 2005.
[3] N. Hanford, V. Ahuja, M. Balman, M. K. Farrens, D. Ghosal, E. Pouyoul, and B. Tierney, “Characterizing the impact of end-system affinities on the end-to-end performance of high-speed flows,” in Proceedings of the Third International Workshop on Network-Aware Data Management, NDM ’13, (New York, NY, USA), pp. 1:1–1:10, ACM, 2013.
[4] N. Hanford, V. Ahuja, M. Balman, M. K. Farrens, D. Ghosal, E. Pouyoul, and B. Tierney, “Impact of the end-system and affinities on the throughput of high-speed flows.” poster - Proceedings of The Tenth ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS) ANCS14, 2014.
[5] A. Pande and J. Zambreno, “Efficient translation of algorithmic kernels on large-scale multi-cores,” in Computational Science and Engineering, 2009. CSE’09. International Conference on, vol. 2, pp. 915–920, IEEE, 2009.
[6] A. Foong, J. Fung, and D. Newell, “An in-depth analysis of the impact of processor affinity on network performance,” in Networks, 2004. (ICON 2004). Proceedings. 12th IEEE International Conference on, vol. 1, pp. 244–250 vol.1, Nov 2004.
[7] M. Faulkner, A. Brampton, and S. Pink, “Evaluating the performance of network protocol processing on multi-core systems,” in Advanced Information Networking and Applications, 2009. AINA ’09. International Conference on, pp. 16–23, May 2009.
[8] J. Mogul and K. Ramakrishnan, “Eliminating receive livelock in an interrupt-driven kernel,” ACM Transactions on Computer Systems (TOCS), vol. 15, no. 3, pp. 217–252, 1997.
[9] J. Salim, “When napi comes to town,” in Linux 2005 Conf, 2005.
[10] T. Marian, D. Freedman, K. Birman, and H. Weatherspoon, “Empirical characterization of uncongested optical lambda networks and 10gbe commodity endpoints,” in Dependable Systems and Networks (DSN), 2010 IEEE/IFIP International Conference on, pp. 575–584, IEEE, 2010.
[11] T. Marian, Operating systems abstractions for software packet processing in datacenters. PhD thesis, Cornell University, 2011.
[12] S. Larsen, P. Sarangam, R. Huggahalli, and S. Kulkarni, “Architectural breakdown of end-to-end latency in a tcp/ip network,” International Journal of Parallel Programming, vol. 37, no. 6, pp. 556–571, 2009.
[13] W. Wu, P. DeMar, and M. Crawford, “A transport-friendly nic for multicore/multiprocessor systems,” Parallel and Distributed Systems, IEEE Transactions on, vol. 23, no. 4, pp. 607–615, 2012.
[14] G. Liao, X. Zhu, and L. Bhuyan, “A new server i/o architecture for high speed networks,” in High Performance Computer Architecture (HPCA), 2011 IEEE 17th International Symposium on, pp. 255–265, IEEE, 2011.
[15] S. Networking, “Eliminating the receive processing bottleneckintroducing rss,” Microsoft WinHEC (April 2004), 2004.
[16] T. Herbert, “rps: receive packet steering, september 2010.” http://lwn. net/Articles/361440/. [17] T. Herbert, “rfs: receive flow steering, september 2010.” http://lwn.net/ Articles/381955/. [18] V. Ahuja, M. Farrens, and D. Ghosal, “Cache-aware affinitization on commodity multicores for high-speed network flows,” in Proceedings of the eighth ACM/IEEE symposium on Architectures for networking and communications systems, pp. 39–48, ACM, 2012.
[19] A. Foong, J. Fung, D. Newell, S. Abraham, P. Irelan, and A. LopezEstrada, “Architectural characterization of processor affinity in network processing,” in Performance Analysis of Systems and Software, 2005. ISPASS 2005. IEEE International Symposium on, pp. 207–218, IEEE, 2005.
[20] G. Narayanaswamy, P. Balaji, and W. Feng, “Impact of network sharing in multi-core architectures,” in Computer Communications and Networks, 2008. ICCCN’08. Proceedings of 17th International Conference on, pp. 1–6, IEEE, 2008.
[21] B. Weller and S. Simon, “Closed loop method and apparatus for throttling the transmit rate of an ethernet media access controller,” Aug. 26 2008. US Patent 7,417,949.
[22] M. Mathis, “Raising the internet mtu,” http://www.psc.edu/mathis/MTU, 2009.
[23] W. Allcock, J. Bresnahan, R. Kettimuthu, M. Link, C. Dumitrescu, I. Raicu, and I. Foster, “The globus striped gridftp framework and server,” in Proceedings of the 2005 ACM/IEEE conference on Supercomputing, p. 54, IEEE Computer Society, 2005.
[24] S. Han, S. Marshall, B.-G. Chun, and S. Ratnasamy, “Megapipe: A new programming interface for scalable network i/o.,” in OSDI, pp. 135–148, 2012.
[25] M. Balman and T. Kosar, “Data scheduling for large scale distributed applications,” in Proceedings of the 9th International Conference on Enterprise Information Systems Doctoral Symposium (DCEIS 2007), DCEIS 2007, 2007.
[26] M. Balman, Data Placement in Distributed Systems: Failure Awareness and Dynamic Adaptation in Data Scheduling. VDM Verlag, 2009.
[27] M. Balman and T. Kosar, “Dynamic adaptation of parallelism level in data transfer scheduling,” in Complex, Intelligent and Software Intensive Systems, 2009. CISIS ’09. International Conference on, pp. 872–877, March 2009.
[28] M. Balman, E. Pouyoul, Y. Yao, E. W. Bethel, B. Loring, M. Prabhat, J. Shalf, A. Sim, and B. L. Tierney, “Experiences with 100gbps network applications,” in Proceedings of the Fifth International Workshop on Data-Intensive Distributed Computing, DIDC ’12, (New York, NY, USA), pp. 33–42, ACM, 2012.
[29] M. Balman, “Memznet: Memory-mapped zero-copy network channel for moving large datasets over 100gbps network,” in Proceedings of the 2012 SC Companion: High Performance Computing, Networking Storage and Analysis, SCC ’12, IEEE Computer Society, 2012.
[30] E. He, J. Leigh, O. Yu, and T. Defanti, “Reliable blast udp : predictable high performance bulk data transfer,” in Cluster Computing, 2002. Proceedings. 2002 IEEE International Conference on, pp. 317 – 324, 2002.
[31] Y. Gu and R. L. Grossman, “Udt: Udp-based data transfer for high-speed wide area networks,” Computer Networks, vol. 51, no. 7, pp. 1777 – 1799, 2007. Protocols for Fast, Long-Distance Networks.
[32] R. Recio, P. Culley, D. Garcia, J. Hilland, and B. Metzler, “An rdma protocol specification,” tech. rep., IETF Internet-draft draft-ietf-rddprdmap-03. txt (work in progress), 2005.
[33] I. T. Association et al., InfiniBand Architecture Specification: Release 1.0. InfiniBand Trade Association, 2000.
[34] ESnet, “Linux tuning, http://fasterdata.es.net/host-tuning/linux.”
[35] ESnet, “iperf3, http://fasterdata.es.net/performance-testing/ network-troubleshooting-tools/iperf-and-iperf3/.”
[36] E. Dart, L. Rotman, B. Tierney, M. Hester, and J. Zurawski, “The science dmz: A network design pattern for data-intensive science,” in Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, SC ’13, (New York, NY, USA), pp. 85:1–85:10, ACM, 2013.
[37] “Esnet 100gbps testbed.” http://www.es.net/RandD/100g-testbed.
[38] J. Levon and P. Elie, “Oprofile: A system profiler for linux.” http:// oprofile.sf.net, 2004.
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/14182908.html