https://www.cnblogs.com/charlieroro/p/14047183.html 感觉自己见识短浅了..复制
来自Linux内核文档。之前看过这篇文章,一直好奇,问什么一条网络流会固定在一个CPU上进行处理,本文档可以解决这个疑问。为了更好地理解本文章中的功能,将这篇文章穿插入内。
本文的描述了Linux网络栈中的一组补充技术,用于增加多处理器系统的并行性和提高性能。
描述的结束为:
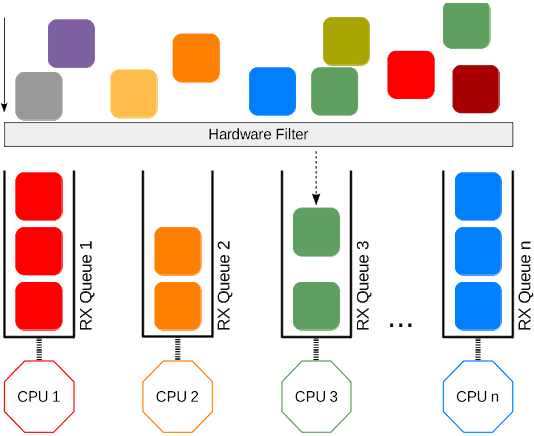
现代NICs支持多个接收和传输描述符队列(多队列)。在接收报文时,NIC可以通过将不同的报文发送到不同的队列的方式来分配多个CPU处理。NIC通过过滤器来分发报文,过滤器会将报文分配给某条逻辑流。每条流中的报文都被导向不同的接收队列,然后由不同CPU处理。这个机制称为“Receive-side Scaling” (RSS)。RSS和其他扩展技术的目的是提升性能。多队列分发技术也可以按照优先级处理流量,但这不是该技术关注的内容。
RSS中的过滤器通常是一个针对网络和/或传输层首部的哈希函数,如对IP地址的4元组和报文的TCP端口进行哈希。最常见的RSS的硬件实现是使用一个128个表项的间接表,每个表项存储一个队列元素。根据由报文计算出的哈希值的低7位来决定报文的接收队列(通常是Toeplitz哈希),使用该值作为间接表的索引,然后读取相应的值。
一些先进的NICs允许根据编程的过滤器将报文导入队列。例如,使用TCP 80端口的web服务器的报文可以直接导入其归属的接收队列。可以使用ethtool配置这种n元组过滤器(–config-ntuple)。
对于支持多队列的NIC,驱动通常会提供一个内核模块参数来配置硬件队列的数目。例如在bnx2x驱动中,该参数称为num_queues。一个典型的RSS配置应该给每个CPU分配一个接收队列(如果驱动支持足够多队列的话),或至少给每个内存域分配一个接收队列(内存域指共享一个特定内存级别(L1, L2, NUMA 节点等)的一组CPUs)。
RSS设备的间接表(通过掩码哈希解析队列)通常是在驱动初始化时进行编程。默认会将队列平均分布到表中,但也可以在运行时通过ethtool命令进行检索和修改(–show-rxfh-indir 和 –set-rxfh-indir)。通过修改间接表,可以给不同的队列分配不同的相对权重。
每个接收队列都会关联一个IRQ(中断请求)。当给定的队列接收到新的报文后,NIC会触发中断,通知CPU。PCIe设备的信令路径使用消息信令中断(MSI-X),可以将每个中断路由到一个特定的CPU上。可以在/proc/interrupts中查看到IRQs的队列映射。默认情况下,任何CPU都可以处理IRQ。由于报文接收中断处理中包含一部分不可忽略的处理过程,因此在CPU之间分散处理中断是有利的(防止新的中断无法被即时处理)。如果要手动调节IRQ的亲和性,参见SMP IRQ affinity。一些系统会运行irqbalance,这是一个守护进程,自动分配IRQ,可能会覆盖手动设置的结果。
当关注延迟或当接收中断处理成为瓶颈后应该启用RSS。将负载分担给多个CPU可以有效减小队列长度。对于低延迟网络来说,最佳设置是分配与系统中CPU数量一样多的队列。最高效的高速率配置可能是接收队列数量最少的配置,这样不会由于CPU饱和而导致接收队列溢出,由于在默认模式下启用了中断合并,中断的总数会随着每个其他队列的增长而增加。
可以使用mpstat工具查看单CPU的负载,但对于启用了超线程(HT)的处理器,每个超线程都表示一个单独的CPU。但对于中断处理,HT在初始测试中没有显示任何好处,因此应该将队列的数目限制为系统上的CPU core的数目。
RSS 是一个网卡特性,其使用的是硬件队列。
为了确定一个接口支持RSS,可以在
/proc/interrupts中查看一个接口是否对应了多个中断请求队列。如下NIC为p1p1接口创建了6个接收队列(p1p1-0到p1p1-5)。# egrep 'CPU|p1p1' /proc/interrupts CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 89: 40187 0 0 0 0 0 IR-PCI-MSI-edge p1p1-0 90: 0 790 0 0 0 0 IR-PCI-MSI-edge p1p1-1 91: 0 0 959 0 0 0 IR-PCI-MSI-edge p1p1-2 92: 0 0 0 3310 0 0 IR-PCI-MSI-edge p1p1-3 93: 0 0 0 0 622 0 IR-PCI-MSI-edge p1p1-4 94: 0 0 0 0 0 2475 IR-PCI-MSI-edge p1p1-5复制可以在
/sys/class/net/<dev>/queues目录中看到一个接口上现有的队列,如下面的eth0有两组队列:# ll /sys/class/net/eth0/queues total 0 drwxr-xr-x 3 root root 0 Aug 19 16:23 rx-0 drwxr-xr-x 3 root root 0 Aug 19 16:23 rx-1 drwxr-xr-x 3 root root 0 Aug 19 16:23 tx-0 drwxr-xr-x 3 root root 0 Aug 19 16:23 tx-1复制也可以使用ethtool -l 查看。如下面的eth0最多支持2组队列,当前启用了2组(就是上述的两组),可以使用ethtool -L eth0 combined 10修改当前启用的队列数,需要注意的的是,目前很多环境都是云化的虚拟环境,大部分ethtool操作功能和权限都受到了限制。
# ethtool -l eth0 Channel parameters for eth0: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 2 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2复制如上所述,下图的硬件过滤器就是个根据4元组或5元组等进行哈希的哈希函数。可以使用
ethtool -x <dev>命令查看RSS使用的哈希函数(但大部分虚拟环境不支持该命令,可以在/proc/sys/net/core/netdev_rss_key中查看RSS使用的哈希key)。
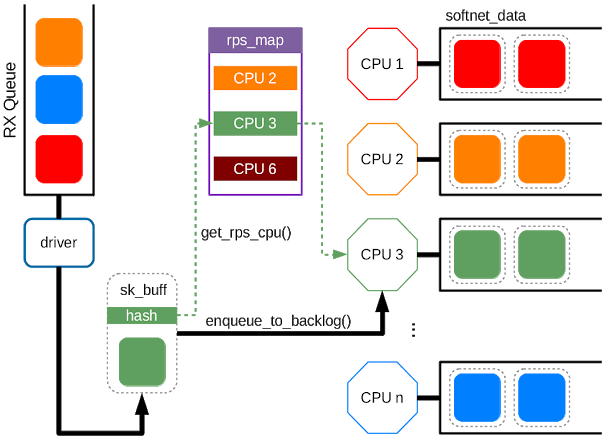
Receive Packet Steering (RPS)是RSS的一个软件逻辑实现。作为一个软件实现,需要在数据路径的后端调用它。鉴于RSS会给流量选择CPU队列,因此会触发CPU运行硬件中断处理程序,RPS会在中断处理程序之上选择CPU来执行协议处理。整个过程是通过将报文放到期望的CPU backlog队列中,然后唤醒该CPU进行处理来实现的。RPS相比RSS有一些优势:
在接收中断处理程序的下半部分会调用RPS(当一个驱动使用netif_rx()或netif_receive_skb()发送一个报文到网络栈时)。这些函数会调用get_rps_cpu() 函数,get_rps_cpu() 会选择一个处理报文的队列。
RPS的第一步是通过对一条流中的报文的地址或端口(2元组或4元组,具体取决于协议)进行哈希来确定目标CPU。哈希操作会涉及相关流中的所有报文。可以通过硬件或栈来支持对报文的哈希。支持报文哈希的硬件会在接收的报文描述符中传入哈希值,通常与RSS使用的哈希相同(如Toeplitz 哈希)。哈希值会保存在skb->hash中,并且可以在栈的其他位置用作报文流的哈希值。
每个接收硬件队列都有相关的CPU列表,RPS会将报文入队列并进行处理。对于每个接收到的报文,会根据流哈希以列表大小为模来计算列表的索引。索引到的CPU就是处理报文的CPU,且报文会放到CPU backlog队列的末尾。在下半部分的例程处理结束之后,会给有报文进入backlog队列的CPU发送IPIs。IPI会唤醒远端CPU对backlog的处理,后续队列中的报文会在网络栈中进行处理。
RPS需要在内核编译时启用CONFIG_RPS 选项(SMP上默认启用,可以使用 cat /boot/config-$(uname -r)|grep CONFIG_RPS命令查看)。但即使在编译时指定了该功能,后续也需要通过明确配置才能启用该功能。可以通过sys文件系统中的文件来配置RPS可以为接收队列转发流量的CPU列表。
/sys/class/net/<dev>/queues/rx-<n>/rps_cpus复制
该文件实现了CPU位图。当上述值为0时(默认为0),不会启用RPS,这种情况下,报文将在中断的CPU上进行处理。SMP IRQ affinity解释了如何将CPU分配给位图。
对于一个单队列设备,典型的RPS配置会将rps_cpus 设置为与中断CPU相同的内存域中的CPUs。如果NUMA的本地性不是问题,则也可以设置为系统上的所有CPUs。在高中断率的情况下,最好从位图中排除该CPU(因为该CPU已经足够繁忙)。
对于一个多队列系统,如果配置了RSS,则硬件接收队列会映射到每个CPU上,此时RPS可能会冗余。但如果硬件队列的数目少于CPU,那么,如果rps_cpus为每个队列指定的CPU与中断该队列的CPU共享相同的内存域时,则RPS可能是有用的。
RPS使用
/sys/class/net/<dev>/queues/rx-<n>/rps_cpus来设置某个接收队列使用的CPU。如果要使用CPU 1~3,则位图为0 0 0 0 0 1 1 1,即0x7,将7 写入rps_cpus即可,后续rx-0将会使用CPU 1~3来接收报文。# echo 7 > /sys/class/net/eth0/queues/rx-0/rps_cpus复制在驱动将报文封装到sk_buff之后,将会经过
netif_rx_internal()或netif_receive_skb_internal(),然后调用get_rps_cpu()将哈希值映射到rps_map中的某个表项,即CPU id。在获取到CPU id之后,enqueue_to_backlog()会将sk_buff 放到指定的CPU队列中(后续处理)。为每个CPU分配的队列是一个per-cpu变量,softnet_data。
如果已经启用了RSS,则可以不启用RPS。但如果系统上CPU的数目大于队列的数目时,可以启用RPS,给队列关联更多的CPU,这样一个队列的报文就可以在多个CPU上处理。
RPS扩展了内核跨CPU接收处理的能力,而不会引入重排。如果报文的速率不同,则将同一流上的所有报文发送到同一CPU会导致CPU负载失衡。在极端情况下,单条流会主导流量。特别是在存在很多并行连接的通用服务器上,这类行为可能表现为配置错误或欺骗源拒绝服务攻击。
流限制是RPS的一个可选特性,在CPU竞争期间,通过提前一点丢弃大流量的报文来为小流量腾出处理的机会。只有当RPS或RFS目标CPU达到饱和时,才会激活此功能。一旦一个CPU的输入报文队列超过最大队列长度(即,net.core.netdev_max_backlog)的一半,内核会从最近的256个报文开始按流计数,如果接收到一个新的报文,且此时这条流的报文数超过了设置的比率(默认为一半,即超过了256/2个),则会丢弃新报文。其他流的报文只有在输入报文队列达到netdev_max_backlog时才会丢弃报文。如果报文队列长度低于阈值,则不会丢弃报文,因此流量限制不会完全切断连接:即使是大流量也可以保持连接。
如果因为 CPU backlog 不够或者 flow limit 不够,被丢弃的报文会将丢包信息计入
/proc/net/softnet_stat
流控制功能默认会编译到内核中(CONFIG_NET_FLOW_LIMIT),但不会启用。它是为每个CPU独立实现的(以避免锁和缓存竞争),并通过在sysctl net.core.flow_limit_cpu_bitmap中设置相关位来切换CPU,它的CPU位图接口与rps_cpus 相同。
/proc/sys/net/core/flow_limit_cpu_bitmap复制
通过将每个报文散列到一个哈希表bucket中,并增加每个bucket计数器来计算每条流的速率。哈希函数与RPS选择CPU时使用的相同,但由于bucket的数目要远大于CPU的数目,因此流控制可更精细地识别大流量,并减少误报。默认的表大小为4096个bucket,可以通过sysctl工具修改:
net.core.flow_limit_table_len
复制只有在分配新表时才会查询该值。修改该值不会更新现有的表。
流控制在系统上有很多并行流时有用,如果单个连接占用了CPU的50%,则表明存在问题。这种环境下,可以为所有的CPU启用流控制特性,来处理网络rx中断(/proc/irq/N/smp_affinity可以设置中断亲和性)。
该特性依赖于输入报文队列长度超过流限制阈值(50%)+流历史长度(256)。在实验中将net.core.netdev_max_backlog设置为1000或10000效果很好。
RPS/RFS主要是针对单队列网卡多CPU环境。而
/proc/irq/{IRQ}/smp_affinity和/proc/irq/{IRQ}/smp_affinity_list指定了哪些CPU能够关联到一个给定的IRQ源。RPS只是单纯把数据包均衡到不同的cpu,这个时候如果应用程序所在的cpu和软中断处理的cpu不是同一个,此时对cpu cache的影响会很大。目前大多数SMP系统会使用smp_affinity功能,默认不启用RPS。
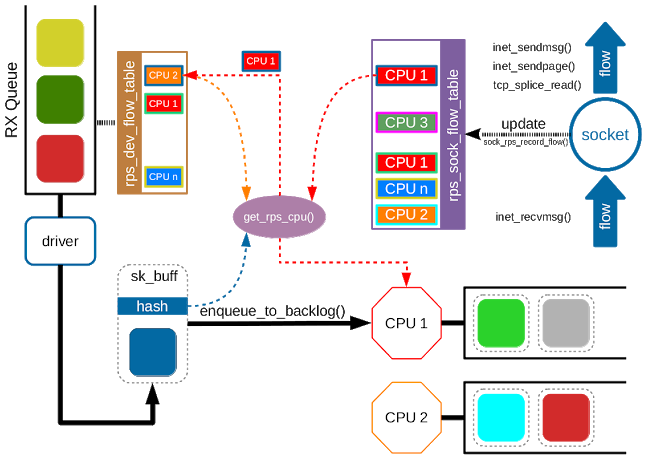
虽然基于哈希的RPS可以很好地分配处理报文时的负载,但没有考虑到应用所在的位置。Receive Flow Steering (RFS)扩展了这一点。RFS的目的是通过将报文的处理引导到正在消耗报文的应用程序线程所在的CPU上来提高数据缓存命中率。RFS依赖与RPS相同的机制来将入队列的报文导向另外一个CPU的backlog队列,并唤醒该CPU。
在RFS中,报文不会根据哈希结果进行转发,哈希结果会作为流查询表的索引。该表会将流映射到正在处理这些流的CPU上。流哈希(见RPS)用于计算该表的索引。记录在表项中的CPU就是上次处理该条流的CPUs。如果一个表项中不包含有效的CPU,则映射到该表项的报文将会完全使用RPS。多个表项可能映射到相同的CPU上(存在很多条流,但仅有很少的CPU,且一个应用可能会使用很多流哈希来处理流)。
rps_sock_flow_table 是一个全局的流表,包含流期望的CPUs:处理当前在用户空间中使用的流的CPU。每个表的值都对应一个CPU索引,并在执行recvmsg 和 sendmsg (准确地讲是 inet_recvmsg(), inet_sendmsg(), inet_sendpage() 和 tcp_splice_read())时更新。
当调度器将一个线程转移到一个新的CPU,但它在旧CPU上有未处理的接收报文时,收到的报文可能会乱序。为了防止发生这种情况,RFS使用一个秒流表来跟踪每个流中未处理的报文:rps_dev_flow_table 是针对每个设备的每个硬件接收队列的表。每个表中的值都保存了一个CPU索引和一个计数器。CPU索引表示入队列(cpu的backlog队列)流报文的当前CPU,后续由内核处理。理想情况下,内核和用户空间的处理会发生在相同的CPU上,此时两个表(rps_sock_flow_table和rps_dev_flow_table)中的CPU索引是相同的。但如果调度器最近转移了用户线程,而报文的入队列和处理仍旧发生在老的CPU上,此时就会发生CPU不一致的情况。
当CPU处理的流有新报文入队列时,rps_dev_flow_table 中的计数器会记录当前CPU的backlog的长度。每个backlog队列都有一个头计数器,在报文出队列时增加。尾计数器的计算方式为:头计数器+队列长度。即rps_dev_flow[i]中的计数器记录了流i中的最后一个元素,该元素入队列到为流i分配的CPU中(当然,表项i实际上是通过哈希选择的,多条流可能会哈希到同一表项i)。
现在,避免出现乱序数据包的技巧是:当选择处理报文的CPU时(通过get_rps_cpu()),会比较接收到数据包的队列的rps_sock_flow表和rps_dev_flow表。如果流的rps_sock_flow 表中期望的CPU与rps_dev_flow 表中记录的当前CPU匹配的话,报文会进入该CPU的backlog队列。如果不同,当下面任一条成立时,会更新CPU,使其与期望的CPU匹配:
rps_dev_flow[i]中记录的尾计数器在上述检查之后,报文会发送(可能会更新CPU)到当前CPU。上述规则用于保证只有当老CPU上不存在未处理的报文时才会将一个流转移到一个新的CPU上(因为未处理的报文可能晚于将要在新CPU上处理的报文)。
只有启用了内核参数CONFIG_RPS (SMP默认会启用)之后才能使用RFS。该功能只有在明确配置之后才能使用。可以通过如下参数设置全局流表rps_sock_flow_table的表项数:
/proc/sys/net/core/rps_sock_flow_entries复制
每个队列的rps_dev_flow_table 流表中的表项数可以通过如下参数设置:
/sys/class/net/<dev>/queues/rx-<n>/rps_flow_cnt复制
上述配置都需要在为接收队列启用RFS前完成配置。两者的值会四舍五入到最接近的2的幂。建议的流数应该取决于任意时间活动的连接数,这可能大大少于打开的连接数。我们发现rps_sock_flow_entries的值32768在中等负载的服务器上可以很好地工作。
对于一个单队列设备,单队列的rps_flow_cnt 的值通常设置为与rps_sock_flow_entries相同的值。对于多队列设备,每个队列的rps_flow_cnt 的值可以配置为与rps_sock_flow_entries/N,N表示队列的数目。例如,如果rps_sock_flow_entries 为32768,且配置了16个接收队列,每个队列的rps_flow_cnt 为2048。
rps_sock_flow_table的结构如下:struct rps_sock_flow_table { u32 mask; u32 ents[0]; };复制
mask用于将哈希值映射到表的索引。由于表大小会四舍五入为2的幂,因此mask设为table_size - 1,并且很容易通过hash & scok_table->mask索引到一个sk_buff。表项通过rps_cpu_mask分为流id和CPU id。低位为CPU id,高位为流id。当应用在socket上进行操作 (inet_recvmsg(), inet_sendmsg(), inet_sendpage(), tcp_splice_read())时,会调用sock_rps_record_flow() 更新
rps_sock_flow_table表。当接收到一个报文时,会调用
get_rps_cpu()来决定报文发到哪个CPU队列,下面是其计算方式:ident = sock_flow_table->ents[hash & sock_flow_table->mask]; if ((ident ^ hash) & ~rps_cpu_mask) goto try_rps; next_cpu = ident & rps_cpu_mask;复制
get_rps_cpu()使用流表的mask字段来获取表项的索引,然后检查匹配到的表项是否存在高比特位,如果存在,则使用表项中的CPU,并将其分配给该报文。否则使用RPS映射。RFS使用pre-queue的
rps_dev_flow_table来跟踪未处理的报文,解决在CPU切换之后,应用可能接收到乱序报文的问题。rps_dev_flow_table的结构如下:struct rps_dev_flow { u16 cpu; u16 filter; /* For aRFS */ unsigned int last_qtail; }; struct rps_dev_flow_table { unsigned int mask; struct rcu_head rcu; struct rps_dev_flow flows[0]; };复制与sock流表一样,
rps_dev_flow_table也使用table_size-1作为掩码,而表大小也必须四舍五入为2的幂。当一个报文入队列后,last_qtail更新为CPU队列的末尾。如果应用迁移到一个新的CPU,则sock流表会反应这种变化,且get_rps_cpu()会为流选择新的CPU。在设置新CPU之前,get_rps_cpu()会检查当前队列的首部是否经过了last_qtail,如果是,则表示队列中没有未处理的报文,可以安全地切换CPU,否则get_rps_cpu()会使用rps_dev_flow->cpu中记录的老CPU。
上图展示了RFS是如何工作的。内核获取一个蓝色的报文,属于蓝色的流。 per-queue流表 (
rps_dev_flow_table)检测到蓝色的报文属于CPU2(老的CPU),而此时socket将sock流表更新为使用CPU1,即新的CPU。get_rps_cpu()会对两个表进行检查,发现CPU发生了迁移,因此会更新 per-queue流表(假设此时在CPU2上没有未处理的报文) ,并将CPU1分配给蓝色的报文。
加速RFS 对RFS来说,就像RSS对RPS:它是一个硬件加速负载均衡机制,基于消耗流报文的应用所运行的位置来使用软状态进行导流。加速RFS的性能要比RFS好,因为报文会直接发送到消耗该报文的线程所在的CPU上。目标CPU可能是应用运行的CPU,或在缓存结构中接近应用线程所在的CPU的CPU。
为了启用加速RFS,网络栈会带调用ndo_rx_flow_steer 驱动函数来与期望(匹配特定流)的硬件队列进行交互。网络栈会在rps_dev_flow_table 中的流表项更新之后调用该函数。驱动会使用一个设备特定的方法来编程NIC,使其引导报文。
流的硬件队列是从rps_dev_flow_table中记录的CPU派生的。网络栈会查询CPU到硬件队列的映射,该映射由NIC驱动程序维护,它是自动生成(/proc/interrupts中展示)的IRQ亲和表的反向映射。驱动可以使用内核库cpu_rmap (“CPU affinity reverse map”)来生成映射。对于每个CPU,映射中相应的队列设置为最接近缓存位置的CPU的队列。
只有在内核编译时启用了CONFIG_RFS_ACCEL且NIC设备和驱动同时支持的情况下才能使用加速RFS功能。同时它还要求通过ethtool启用ntuple过滤功能。驱动程序会为每个接收队列配置的IRQ亲和性自动推导CPU到队列的映射,不需要额外的配置。
如果希望使用RFS且NIC支持硬件加速,就可以启用该技术。
为了启用aRFS,需要一张带有可编程ntupter过滤器的网卡,和驱动程序的支持。可以使用如下方式启用ntuple过滤器:
# ethtool -K eth0 ntuple on复制对于支持aRFS的驱动,需要实现ndo_rx_flow_steer 来帮助set_rps_cpu()配置硬件过滤器。当
get_rps_cpu()决定为一条流分配CPU时,它会调用set_rps_cpu()。set_rps_cpu()首先会检查网卡是否支持ntuple过滤器,如果支持,它会请求rx_cpu_rmap来为流找一个合适的RX队列。rx_cpu_rmap是一个由驱动维护的特殊的映射,该映射用来为CPU查找一个合适的RX队列,找到的队列可是与给定CPU直接关联的队列,也可能是临近的缓存位置上的队列。在获取到RX队列索后,set_rps_cpu()会调用ndo_rx_flow_steer()来通知驱动为给定的流创建一个新的过滤器。ndo_rx_flow_steer()会返回过滤器id,过滤器id会被保存到per-queue流表中。除了实现
ndo_rx_flow_steer(),驱动还需要周期性地调用rps_may_expire_flow()检查过滤器是否有效,并移除过期的过滤器。
Transmit Packet Steering是一种在多队列设备上传输报文时,为报文智能选择传输队列的机制。可以通过记录两种映射来实现,即将CPU映射到硬件队列或将接收队列映射到传输队列。
XPS使用CPU映射
该映射的目的是队列专门分配给 CPU 的一个子集,在此队列上的CPU会完成这些队列的报文传输。这种方式提供了两种好处:首先,由于竞争同一个队列的cpu更少,因此大大降低了设备队列的锁竞争(当每个CPU完成自己的传输队列时会释放锁);其次,降低了传输竞争导致的缓存miss率,特别是对那些保存了sk_buff结构的数据缓存行。
XPS使用接收队列映射
该映射用于基于管理员设置的接收队列映射选择传输队列。一组接收队列可以映射到一组传输队列(多对多,但通常会使用1:1映射)。这将允许在相同的队列上下文(如CPU和缓存等)中对报文进行传输和接收。这种方式可以用于繁忙的轮询多线程工作负载,在这些工作负载中,很难将特定的CPU与特定的应用程序线程关联起来。应用线程不会固定运行在某些CPU上,且每个线程会基于一个单独的队列接收报文。socket会缓存接收队列的数目。在这种模型下,将传输队列与相关的接收队列关联起来,可以有效降低CPU开销。此时传输工作会锁定到给定应用执行轮询的上下文中,避免触发其他CPU造成的开销。当应用程序在繁忙的轮询期间清理报文时,可能会在与应用相同的线程上下文中完成传输,从而减少延迟。
可以通过设置一个CPUs/接收队列位图来为每个传输队列配置XPS。每个网络设备会计算并维护从CPUs到传输队列或从接收队列到传输队列的反向映射。当在一条流中传输首个报文时,会调用get_xps_queue()选择一个队列。该函数会为每个socket连接使用的接收队列的ID来匹配"接收队列到传输队列"的查询表。另外,该函数也可以使用运行的CPU ID作为key来匹配"CPU到队列"的查询表。如果这个ID匹配到一个队列,则使用该队列传输报文。如果匹配到多个队列,则通过流哈希计算出的索引来选择一个队列。当基于接收队列映射选择传输队列时,传输设备不会针对接收设备进行验证,因为这需要在数据路径中进行代价高昂的查找操作。
为特定传输流选择的队列会保存在对应的流(如TCP)socket结构体中。该传输队列会用于这条流上的后续报文的传输,方式发送乱序(ooo)报文。这种方式还分摊了流中所有报文调用get_xps_queues()的开销。为了防止乱序报文,只有设置了流报文的skb->ooo_okay字段,才能变更这条流使用的队列。这个标志位标识这条流中没有未处理的报文,这样就可以切换传输队列,而不用担心生成乱序报文的风险。传输层会负责正确处理乱序报文。如TCP,当确认一个连接上的所有数据后就会设置该标志。
只有在内核启用了CONFIG_XPS 符号时才能使用XPS功能。如果内核编译了该功能,由驱动决定是否以及如何在设备初始化时配置XPS。使用sfsfs来检查和配置CPUs/接收队列到传输队列的映射。
对于基于CPUs的映射:
xps_cpus的意义与rx-/rps_cpus类似,确定队列使用的CPU。
/sys/class/net/<dev>/queues/tx-<n>/xps_cpus复制
对于基于接收队列的映射:
/sys/class/net/<dev>/queues/tx-<n>/xps_rxqs复制
对于一个只有一条传输队列的网络设备,由于这种情况下无法选择传输对,此时XPS是不起作用的。在多队列系统中,建议配置XPS,这样每个CPU会映射到一个传输队列。如果系统中传输队列的数目等于CPUs的数目,则每个队列仍然会映射到一个CPU,此时不会产生多队列竞争CPU的情况。如果队列的数目少于CPUs的数目,那么,共享给特定队列的最佳CPU可能是与处理该队列的传输完成(传输中断)的CPU共享高速缓存的CPU。
对于基于接收队列选择的传输队列,XPS需要明确配置接收队列到传输队列的映射关系。如果用户配置的接受队列映射没有生效,则会使用基于CPU映射来选择传输队列。
这是由硬件实现的速率限制机制,当前支持设置最大速率熟悉,使用如下值设置一个Mbps值:
/sys/class/net/<dev>/queues/tx-<n>/tx_maxrate复制
0值表示不启用,默认为0.
RPS 和RFS是内核2.6.35引入的,XPS是2.6.38引入的。
加速RFS是2.6.35引入的。
/proc/irq/${irq_num}/smp_affinity的用于设置硬中断的亲和性,可以在/proc/interrupts中查看对应的硬中断的设置效果;由于RPS是运行在中断的下半部分,即属于软中断,因此/sys/class/net/${net_dev}/queues/rx-0/rps_cpus用于设置处理接收到的报文的CPU,可以在/proc/softirqs 中查看对应的软中断的效果,可以使用watch -n 1 'cat /proc/softirqs |grep NET_RX'查看。可以在这篇文章中查看设置脚本。
当系统上网卡的队列数小于系统的CPU核数时,可以使用RPS将多余的CPU分配给队列,这样可以提高CPU的利用率
irqbalance默认可以自动在所有CPU核上对中断进行负载分担。它有三种模式:exact|subset|ignore,默认是ignore
当某个CPU的大部分CPU时间都用于处理某些中断时(如接收大量报文),最好将上层应用与该CPU分开,降低对各自处理性能的影响。
网卡上的接收队列和发送队列中保存的是主存的DMA中的文件描述符,当NIC接收到报文后,直接将报文写入RX Ring中的报文指针指向的DMA中的地址,然后向CPU发送硬中断。(NAPI可以减少硬中断次数)
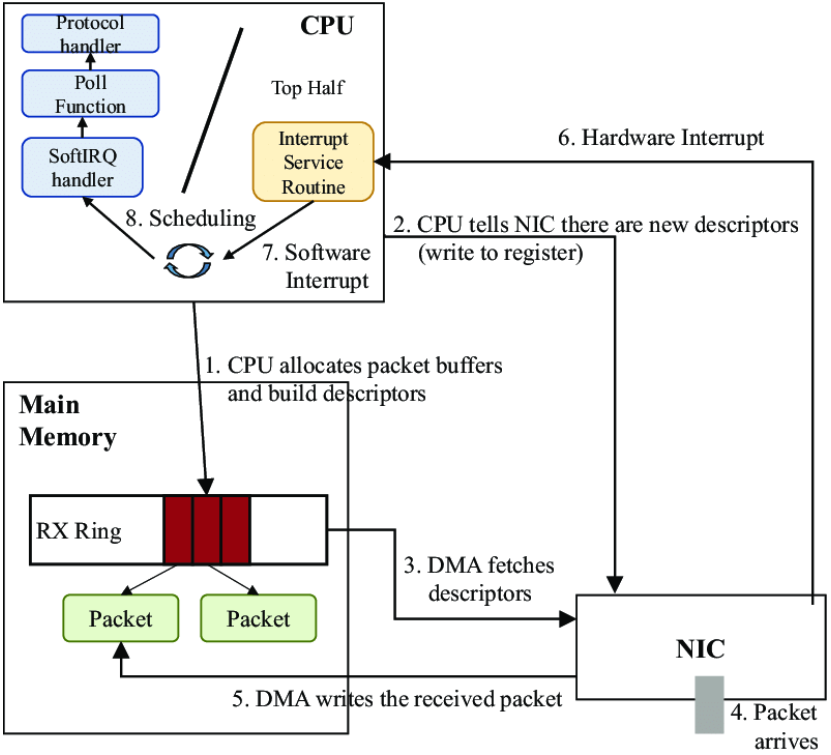
需要区分网卡的接收队列RX Ring和RPS对应的队列之间的关系。网卡会使用哈希来选择放入报文的接收队列,且接收队列是通过DMA方式直接写入报文的(没有CPU参与),位于DMA区域;而RPS则用于指定处理队列的CPU(需要CPU处理),从RPS的配置路径中可以看到(如/sys/class/net/eth0/queues/rx-0),它与队列相关。总的来说,就是先把报文放到队列中,然后为队列选择出该该队列中报文的CPU。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/14047183.html