提高UDP交互性能
这是一篇个人认为非常非常厉害的文章,取自这里。讲述了如何提升UDP流的处理速率,但实际涉及的技术点不仅仅限于UDP。这篇文章中涉及的技术正好可以把前段时间了解的知识串联起来。作者:Toshiaki Makita
讲述内容
- 背景
- 提升网络性能的基本技术
- 如何提升UDP性能
作者介绍
Toshiaki Makita
- NTT开源软件中心的Linux内核工程师
- NTT集团公司的技术支持
- 内核网络子系统的活跃补丁提交者
背景
因特网上UDP事务
- 使用UDP的服务
- DNS
- RADIUS
- NTP
- SNMP等
- 被大量网络服务提供商使用
以太网带宽和交互
- 以太网带宽演进:
- 10M -> 100M -> 1G -> 10G -> 40G -> 100G -> ...
- 10G(或更大)的NIC在商用服务器上越来越普遍
- 10G网络上的交互:
- 最小报文的场景下:最大 14,880,952 个报文/s (最小的以太帧为64字节+ preamble+IFG 20bytes = 84 bytes = 672 bits,10,000,000,000 / 672 = 14,880,952)
- 难以在单个服务器中处理
需要处理多少交互
- UDP 负载大小
- DNS
- A/AAAA请求:40~字节
- A/AAAA响应:100~字节
- RADIUS
- Access-Request:70~字节
- Access-Accept:30~字节
- 通常带有100个字节的属性
- 大部分场景下为100个字节
- DNS
- 10G网络上100字节数据的交互
- 最大7,530,120次交互/s (100 bytes + IP/UDP/Ether headers 46bytes + preamble+IFG 20bytes = 166 bytes = 1328 bits
,即10,000,000,000 / 1328 = 7,530,120) - 即使在少于最短的报文的情况下,但仍具有挑战性
- 最大7,530,120次交互/s (100 bytes + IP/UDP/Ether headers 46bytes + preamble+IFG 20bytes = 166 bytes = 1328 bits
提升网络性能的基本技术
TSO/GSO/GRO
-
报文分割/聚合
-
减少报文在服务中的处理
-
适用于TCP 字节流(使用UDP隧道的TCP也可以)
-
不适用于UDP数据报(除了UFO,其他都依赖物理NICs)
- UDP在数据报之间有明确的界限
- 不能分割/聚合报文
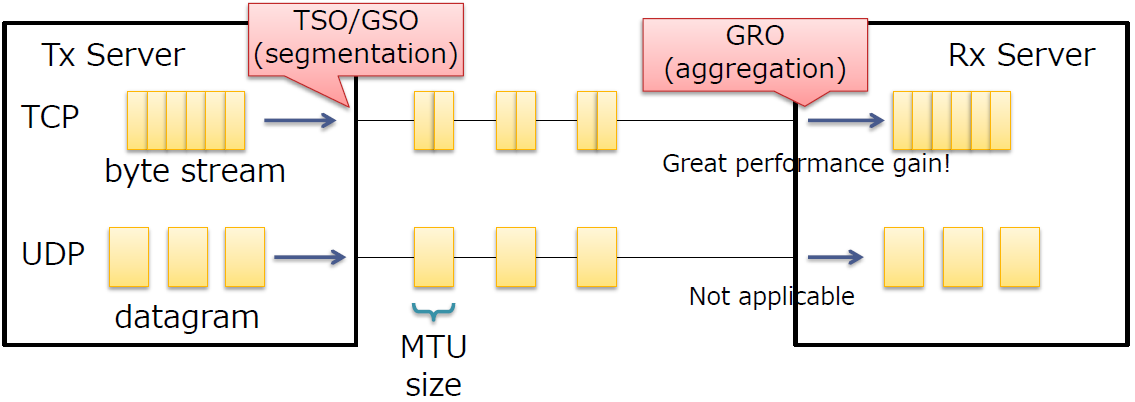
TSO/GSO用于发送报文时,将上层聚合的数据进行分割,分割为不大于MTU的报文;GRO在接受侧,将多个报文聚合为一个数据,上送给协议栈。总之就是将报文的处理下移到了网卡上,减少了网络栈的负担。TSO/GSO等可以增加网络吞吐量,但有可能造成某些连接上的网络延迟。
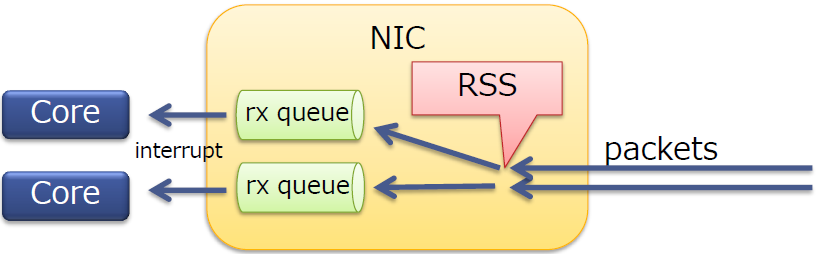
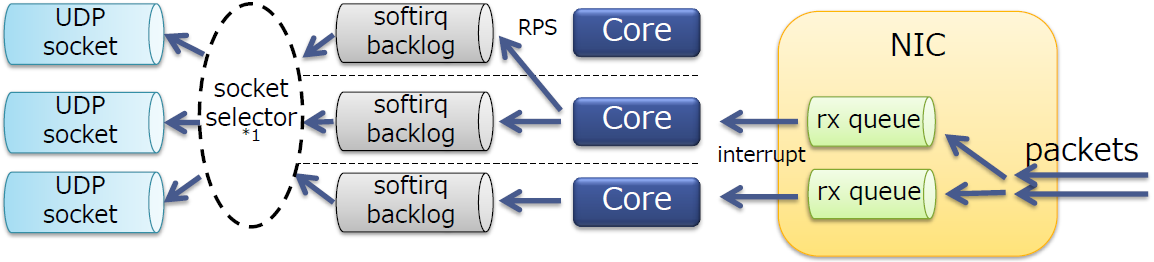
RSS
- 在多核服务器上扩展了网络接收侧的处理
- RSS本身是一个NIC特性
- 将报文分发到一个NIC中的多个队列上
- 每个队列都有一个不同的中断向量(不同队列的报文可以被不同的核处理)
- 可以运用于TCP/UDP
- 通常10G的NICs会支持RSS
RSS是物理网卡支持的特性,可以将NIC的多个队列映射到多个CPU核上进行处理,增加处理的效率,减少CPU中断竞争。
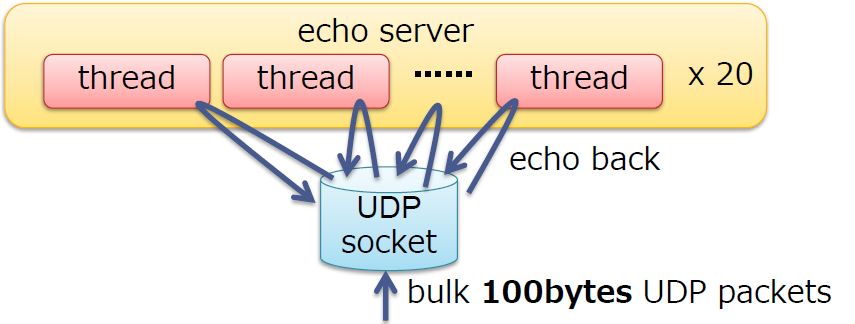
启用RSS的NIC的性能
- 100字节UDP交互性能
- 使用简单的echo多线程(线程数与核数相同,每个线程运行
recvfrom()和sendto()服务器进行测试 - OS:内核4.6.3(RHEL 7.2环境)
- 具有20个核心和10G NIC的中型商用服务器:
- NIC:Intel 82599ES (含RSS, 最大64 个队列)
- CPU:Xeon E5-2650 v3 (2.3 GHz 10 cores) * 2 sockets,禁用超线程
- 结果:270,000 transactions/s (tps) (大概 360Mbps)
- 10G带宽使用了3.6%
- 使用简单的echo多线程(线程数与核数相同,每个线程运行
如何提升
确认瓶颈
-
sar -u ALL -P ALL 1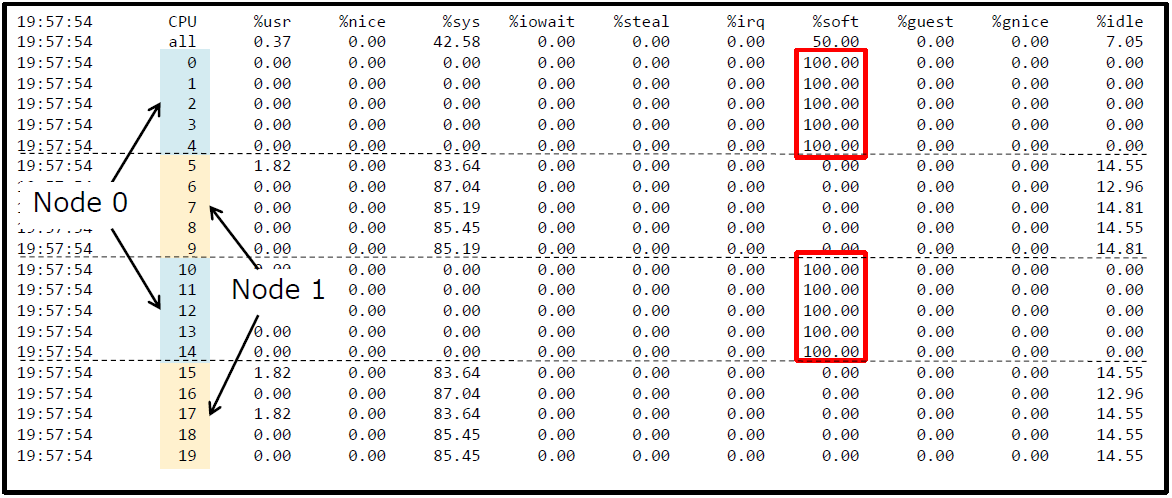
-
softirq仅在NUMA的Node0上运行,为什么?
- 尽管可以为20个核提供足够(64个)的队列
可以在/proc/zoneinfo中查看NUMA的node信息。使用mpstat也可以看到类似的现象,
%irq表示硬中断,%soft表示软中断。
RSS下的softirq
-
RSS会将报文分发到接收队列
-
每个队列的中断目的地由
/proc/irq/<irq>/smp_affinity确定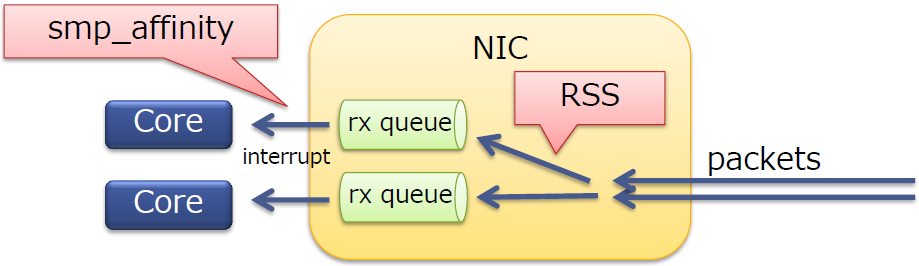
RSS会将报文分发到不同的队列,smp_affinity会设置中断亲和性,将不同队列产生的中断上送给不同的CPU核。
-
通常由
irqbalance设置smp_affinity
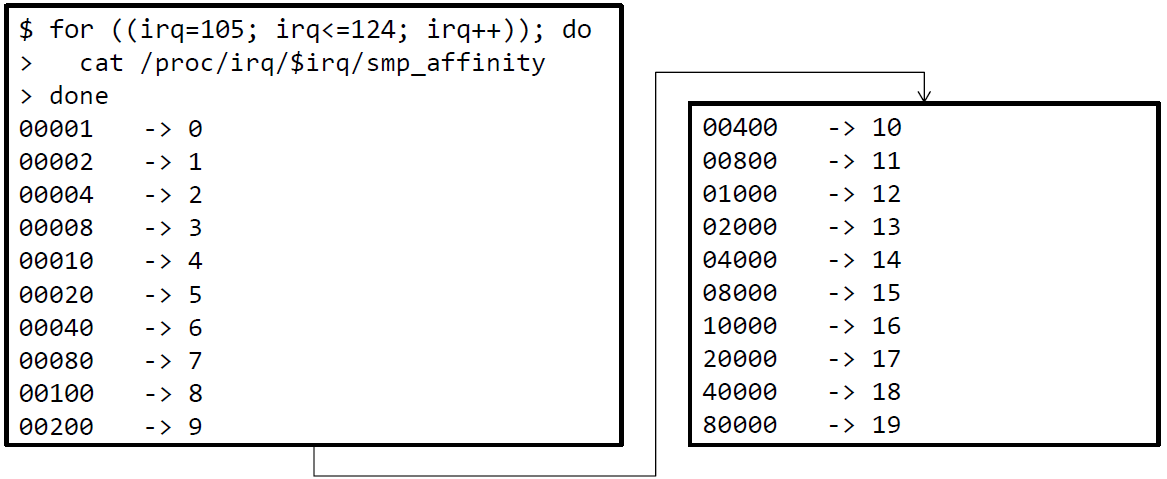
校验smp_affinity
-
smp_affinity

-
irqbalance仅使用了Node 0(核0-4, 10-14),如何修改?
检查affinity_hint
-
一些NIC驱动提供了
affinity_hint,位于/proc/irq/<irq_num>/affinity_hint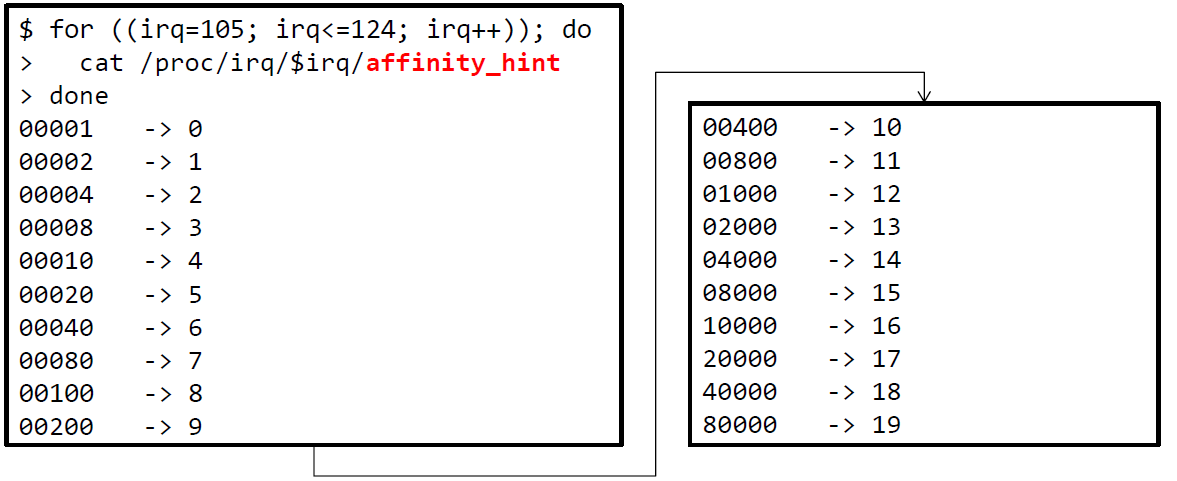
-
affinity_hint是均匀分布的 -
为了显示该hint,可以在
irqbalance(通过/etc/sysconfig/irqbalance)中添加"-h exact"选项,即完全按照/proc/irq/<irq_num>/affinity_hint中的CPU核来进行负载均衡。这种方式其实就是将特定的中断固定到了特定的核上,不会自动调整,RPS影响的是软中断,后面使用BPF将socket与核进行关联之后不会出现irqbalance将流转移到其他核的情况。
修改irqbalance选项
-
添加"-h exact"并重启
irqbalance服务 -
可以看到irqs分布到了所有的核上。
-
sar -u ALL -P ALL 1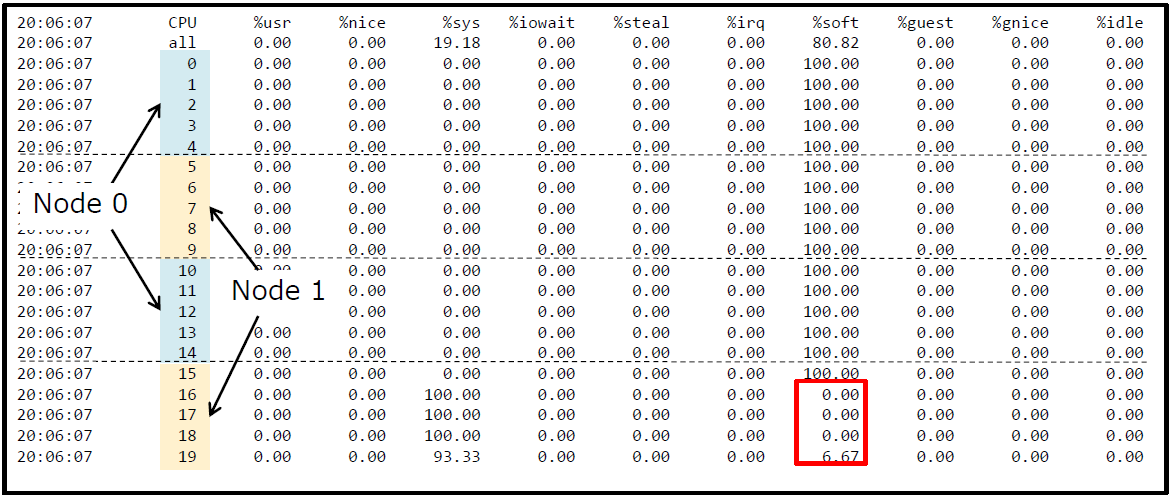
-
虽然irqs看起来分布均匀,但16~19核却没有分配softirq
检查rx-queue状态
-
ethtool -S
$ ethtool -S ens1f0 | grep 'rx_queue_.*_packets' rx_queue_0_packets: 198005155 rx_queue_1_packets: 153339750 rx_queue_2_packets: 162870095 rx_queue_3_packets: 172303801 rx_queue_4_packets: 153728776 rx_queue_5_packets: 158138563 rx_queue_6_packets: 164411653 rx_queue_7_packets: 165924489 rx_queue_8_packets: 176545406 rx_queue_9_packets: 165340188 rx_queue_10_packets: 150279834 rx_queue_11_packets: 150983782 rx_queue_12_packets: 157623687 rx_queue_13_packets: 150743910 rx_queue_14_packets: 158634344 rx_queue_15_packets: 158497890 rx_queue_16_packets: 4 rx_queue_17_packets: 3 rx_queue_18_packets: 0 rx_queue_19_packets: 8复制 -
可以看到RSS并没有将报文分发给队列16~19
RSS 间接表
-
RSS有一个间接表,用于确定分发的报文所属的队列
-
可以使用
ethtool -x命令查看(虚拟环境可能不支持)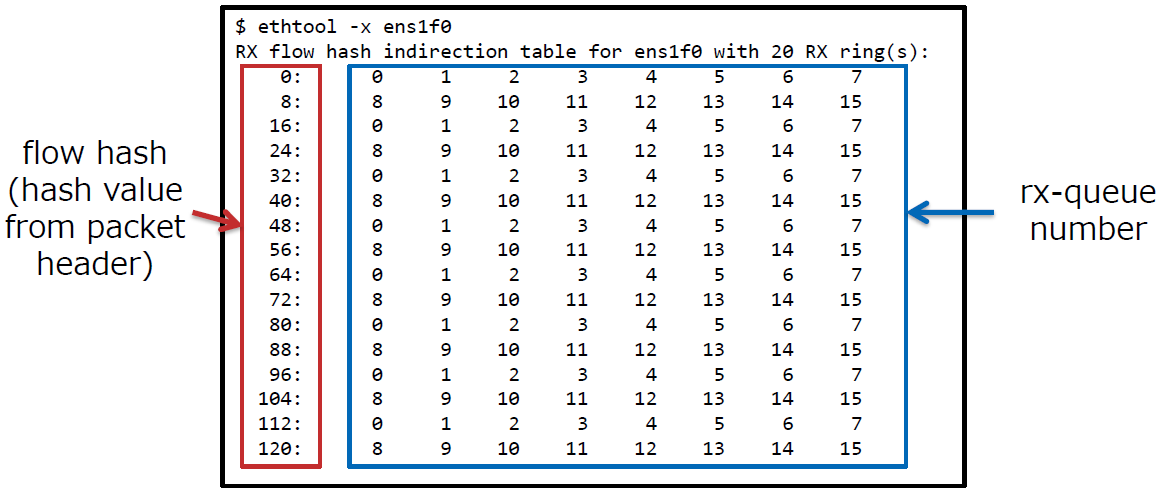
-
可以看到仅使用了015的接收队列,并没有使用1619的队列
-
使用所有的0~19的队列
# ethtool -X ens1f0 equal 20 Cannot set RX flow hash configuration: Invalid argument复制 -
间接表中该NIC的最大接收队列数为16,因此不能使用20个队列
- 虽然有64个接收队列
-
使用RPS替代
- RSS的软件仿真
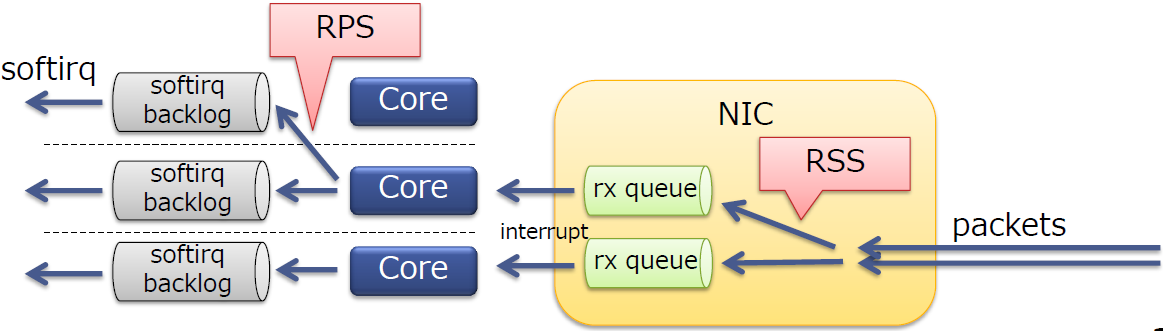
使用RPS
-
现在给接收队列69上的流分配CPU69 和16~19,这两组CPU都位于Node1
• rx-queue 6 -> core 6, 16
• rx-queue 7 -> core 7, 17
• rx-queue 8 -> core 8, 18
• rx-queue 9 -> core 9, 19
# echo 10040 > /sys/class/net/ens1f0/queues/rx-6/rps_cpus
# echo 20080 > /sys/class/net/ens1f0/queues/rx-7/rps_cpus
# echo 40100 > /sys/class/net/ens1f0/queues/rx-8/rps_cpus
# echo 80200 > /sys/class/net/ens1f0/queues/rx-9/rps_cpus
复制-
sar -u ALL -P ALL 1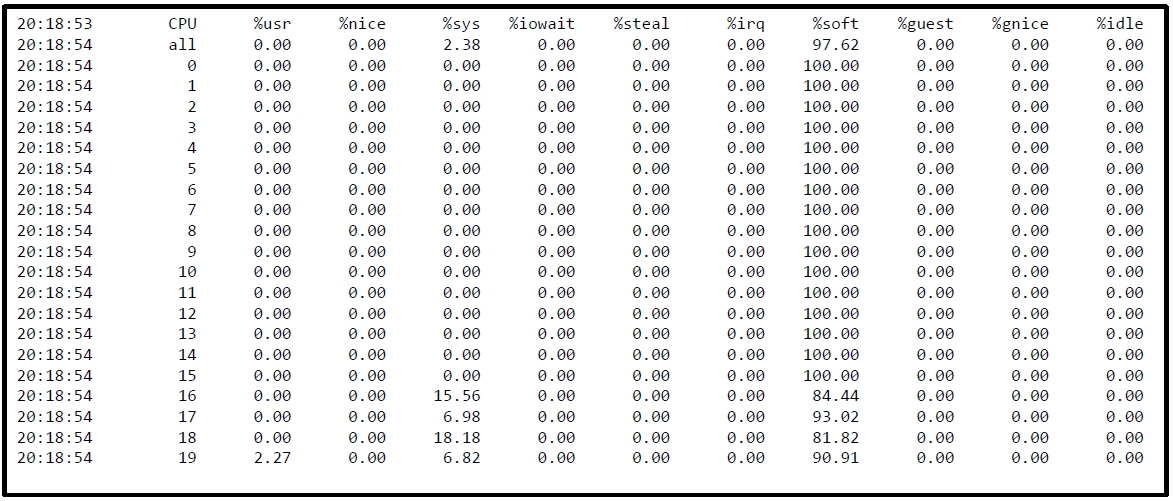
-
此时软中断的分布几乎是均匀的
RSS & affinity_hint & RPS
-
多亏了affinity_hint 和RPS,现在可以将流均匀地分发到不同的CPU核上。
-
性能变化:
- Before: 270,000 tps (大概 360Mbps)
- After: 17,000 tps (大概 23Mbps)
变的更差了。。
-
可能的原因是软中断太多导致的
- 软中断几乎占了100%的CPU
- 需要更好地分析手段
分析软中断
-
perf
- 内核树分析工具
- 通过CPU采样定位热点
-
举例:
perf record -a -g -- sleep 5- 每5秒将结果输出到
perf.data文件
- 每5秒将结果输出到
-
火焰图
- 以svg格式可视化展现
perf.data - https://github.com/brendangregg/FlameGraph
- 以svg格式可视化展现
-
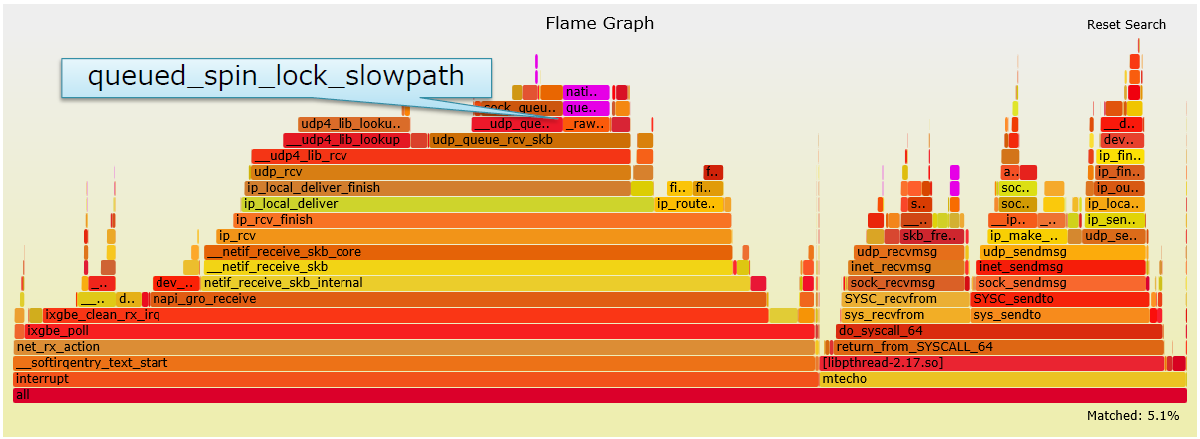
CPU0的火焰图(结果经过了过滤)
- X轴:CPU消耗
- Y轴:调用深度
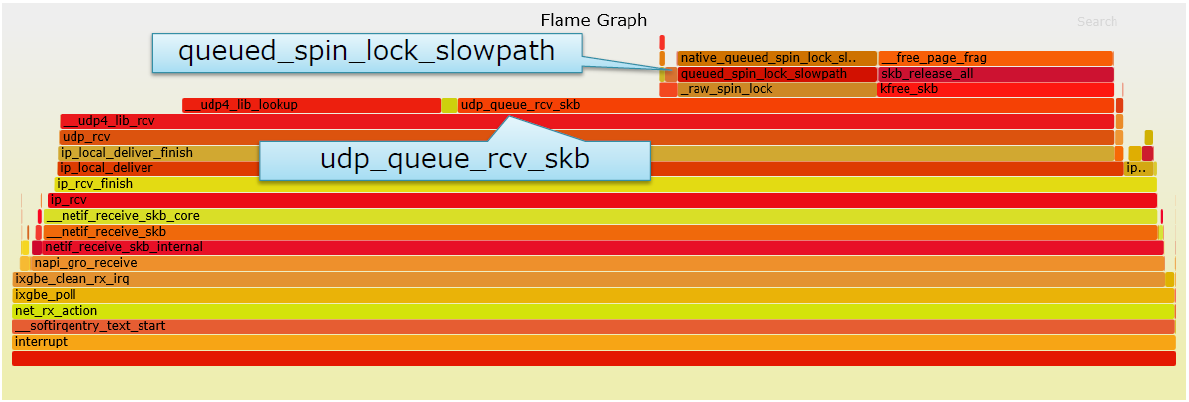
-
queued_spin_lock_slowpath:锁竞争 -
udp_queue_rcv_skb:要求socket锁
socket锁竞争
-
echo服务器在一个特定端口上仅绑定了一个socket
-
每个内核的softirq同时将报文推入socket队列

-
最终导致socket锁竞争
避免锁竞争
- 使用
SO_REUSEPORT选项分割sockets- 该选项在内核3.9引入,默认使用流(报文首部)哈希来选择socket
-
SO_REUSEPORT允许多个UDP socket绑定到相同的端口上-
在每个报文排队时选择一个套接字
int on = 1; int sock = socket(AF_INET, SOCK_DGRAM, 0); setsockopt(sock, SOL_SOCKET, SO_REUSEPORT, &on, sizeof(on)); bind(sock, ...);复制SO_REUSEPORT的介绍可以参考这篇文章。
-
使用SO_REUSEPORT
-
sar -u ALL -P ALL 1
-
此时软中断消耗的CPU就比较合理了,从下面火焰图可以看到中断处理消耗的CPU缩短了
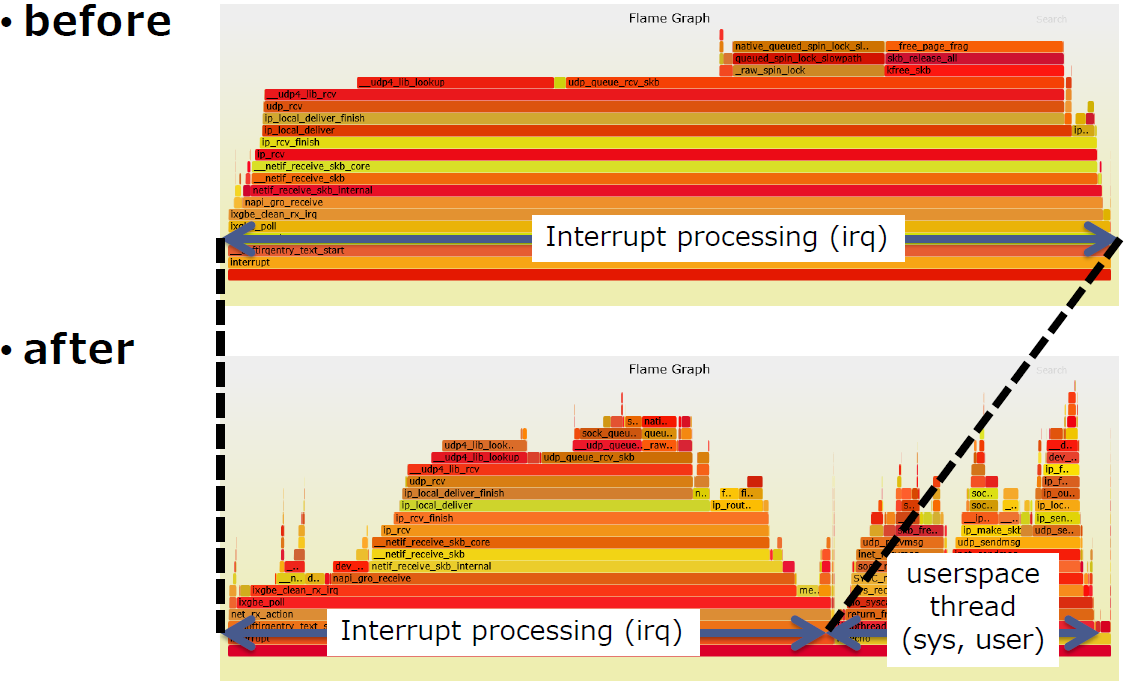
-
性能变化
- RSS: 270,000 tps (大概 360Mbps)
- +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
- +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
-
进一步分析:
-
可以看到,仍然有socket锁竞争。
SO_REUSEPORT默认使用流哈希来选择队列,不同的CPU核可能会选择相同的sockets,导致竞争。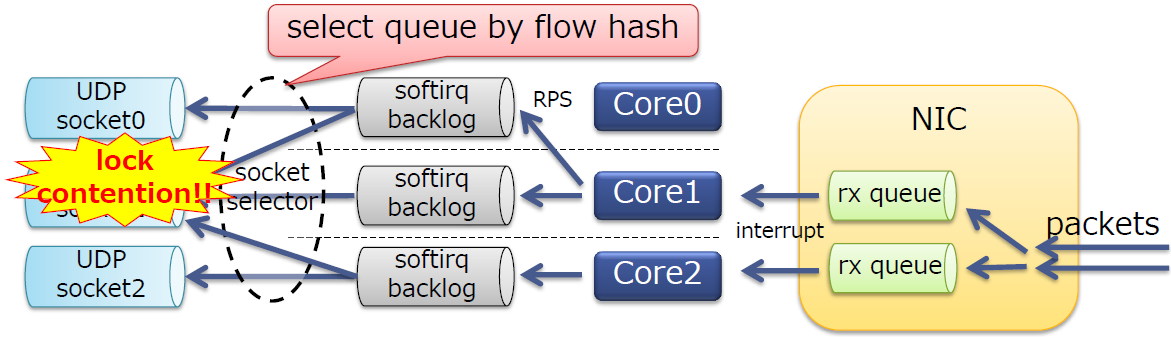
避免socket锁竞争
- 根据CPU核号选择socket
- 通过
SO_ATTACH_REUSEPORT_CBPF/EBPF实现 - 在内核4.5引入上述功能
- 通过
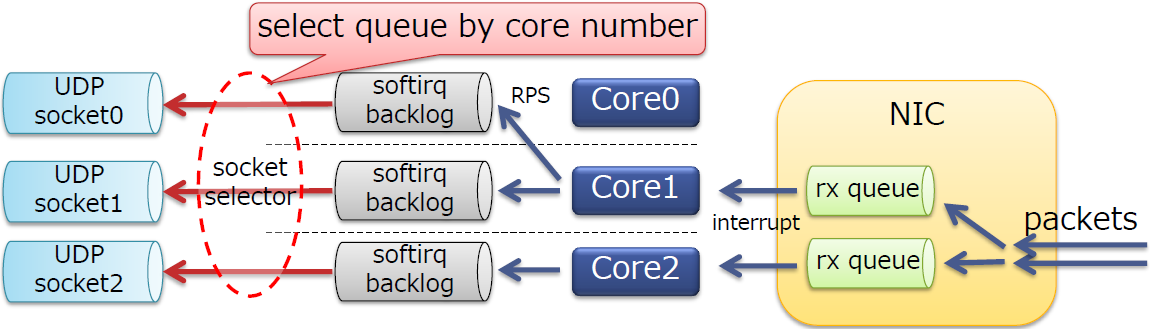
-
此时软中断之间不再产生竞争
-
用法可以参见内核源码树中的例子:tools /testing/selftests /net /reuseport_bpf_cpu.c
-
启用
SO_ATTACH_REUSEPORT_EPBF前后的火焰图如下,可以看到中断消耗的CPU更少了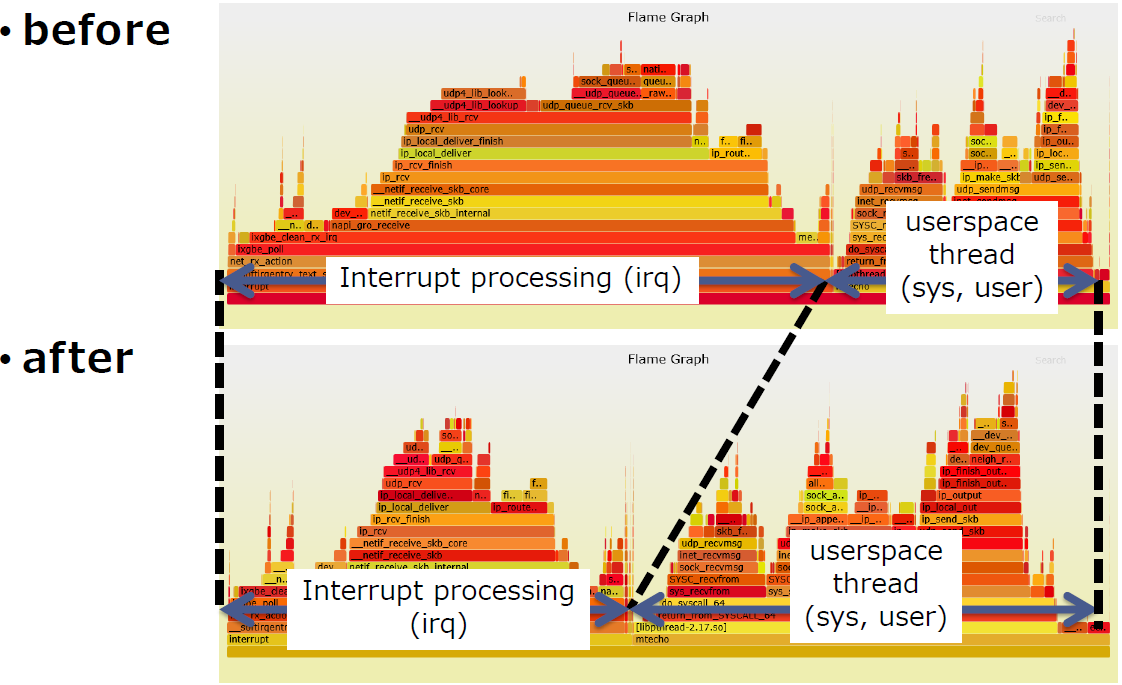
-
性能变化:
- RSS: 270,000 tps (approx. 360Mbps)
- +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
- +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
- +SO_ATTACH_...: 4,250,000 tps (大概 5640Mbps)
固定用户线程
-
用户线程数:sockets数 == 1:1,但不一定与软中断处于同一CPU核

-
将用户现场固定到相同的核,获得更好的缓存亲和性。可以使用cgroup, taskset, pthread_setaffinity_np()等方式
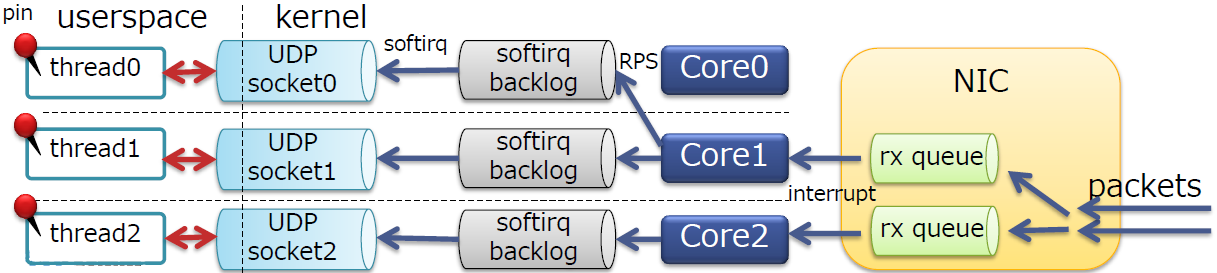
-
性能变化
- RSS: 270,000 tps (approx. 360Mbps)
- +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
- +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
- +SO_ATTACH_...: 4,250,000 tps (大概 5640Mbps)
- +Pin threads: 5,050,000 tps (大概 6710Mbps)
输出方向的锁
- 到目前为止解决的问题都处在接收方向上
- 发送方向是否有锁竞争?
Tx队列
- 内核具有Qdisc(默认的Qdisc为
pfifo_fast) - 每个Qdisc都连接到NIC的tx队列
- 每个Qdisc都有自己的锁
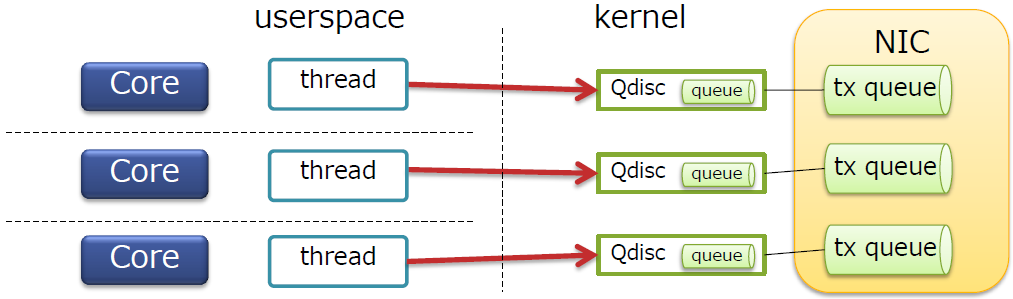
Tx队列的锁竞争
- Qdisc默认通过流哈希进行选择
- 因此可能会发送锁竞争
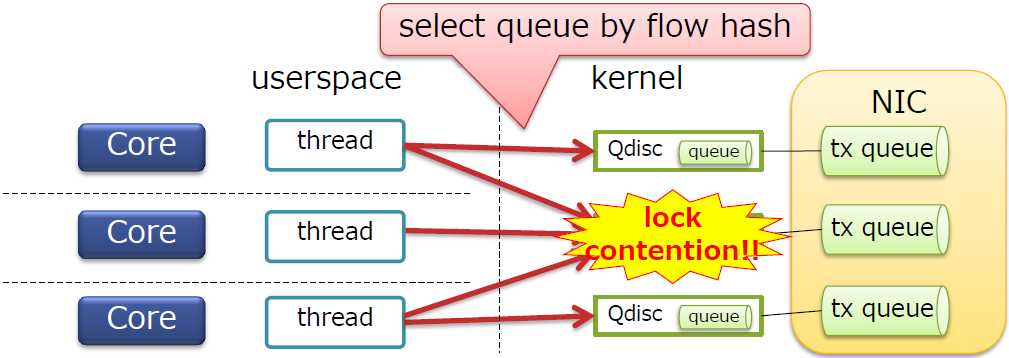
- 但并没有在输出方向上看到锁竞争,为什么?
避免Tx队列的锁竞争
- 这是因为
ixgbe(Intel 10GbE NIC驱动)可以自动设置XPS
-
XPS允许内核选择根据CPU核号选择Tx队列(Qdisc)
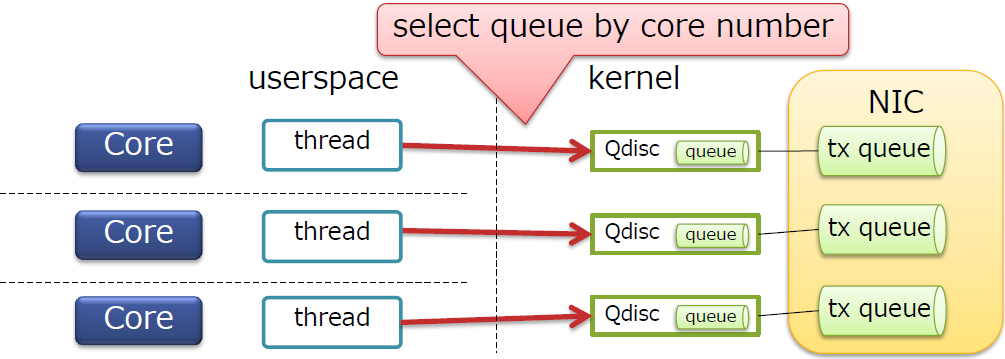
-
因此发送方向没有锁竞争
XPS的影响如何
-
禁用XPS
# for ((txq=0; txq<20; txq++)); do > echo 0 > /sys/class/net/ens1f0/queues/tx-$txq/xps_cpus > done复制- Before: 5,050,000 tps (大概 6710Mbps)
- After: 1,086,000 tps (大概 1440Mbps)
可见有近5倍的性能差距,且从火焰图看,产生了大量锁竞争

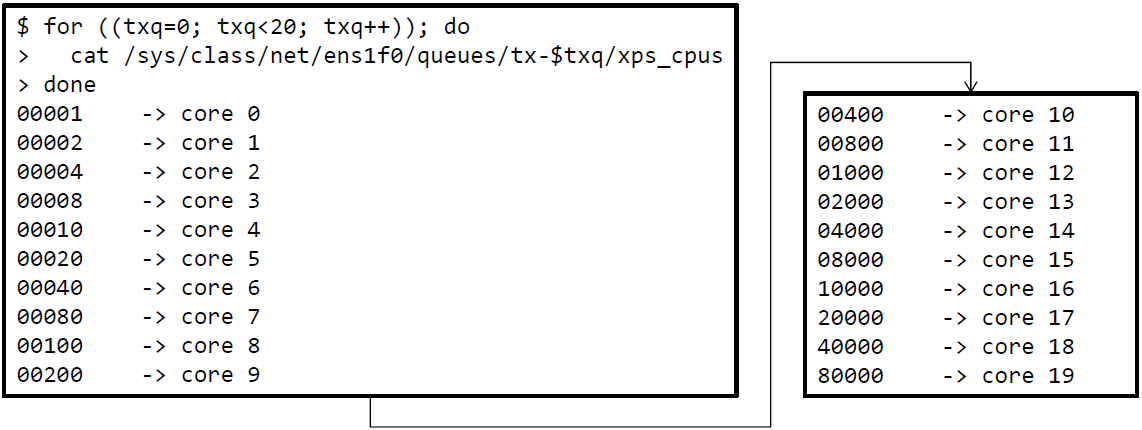
重新启用XPS
-
启动XPS。XPS的工作方式其实与RPS类似
# echo 00001 > /sys/class/net/<NIC>/queues/tx-0/xps_cpus # echo 00002 > /sys/class/net/<NIC>/queues/tx-1/xps_cpus # echo 00004 > /sys/class/net/<NIC>/queues/tx-2/xps_cpus # echo 00008 > /sys/class/net/<NIC>/queues/tx-3/xps_cpus ...复制 -
尽管
ixgbe可以自动设置XPS,但并不是所有的驱动都可以 -
确保配置了xps_cpus
优化单个核 1
- 为了完全利用多核,并避免竞争,性能达到了5,050,000 tps (大概 6710Mbps)
- 为了进一步提高性能,需要降低单个核的开销
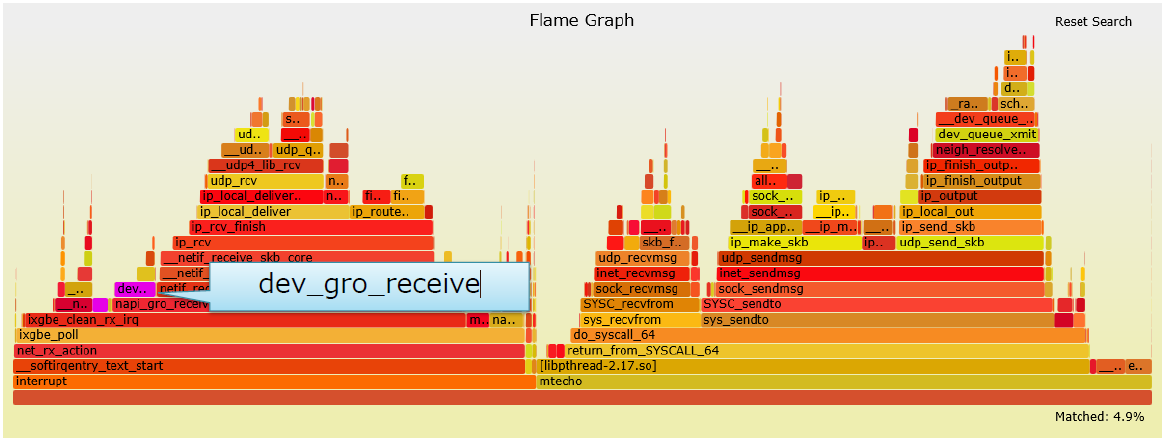
-
可以看到默认启用了GRO,并消耗了4.9%的CPU时间。
-
GRO并不适用于UDP(UDP隧道除外,如VXLAN)
-
为UDP服务禁用GRO
# ethtool -K <NIC> gro off复制 -
警告:
- 如果关注TCP性能,则不能禁用GRO功能
- 禁用GRO会导致TCP接收吞吐量降低
- 在KVM 虚拟化管理系统上也不要禁用GRO
- GRO提高了隧道协议流量以及虚拟机管理程序上的guest TCP流量的吞吐量
- 如果关注TCP性能,则不能禁用GRO功能
禁用GRO
- 性能变化
• RSS (+XPS): 270,000 tps (大概 360Mbps)
• +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
• +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
• +SO_ATTACH_...: 4,250,000 tps (大概 5640Mbps)
• +Pin threads: 5,050,000 tps (大概 6710Mbps)
• +Disable GRO: 5,180,000 tps (大概 6880Mbps)
优化单个核 2
-
可以看到执行了iptables相关的操作
- 此时并不需要任何iptables
-
iptables消耗了3%的CPU
-
由于iptables是内核加载的模块,即使用户不需要任何规则,它内部也会消耗一部分CPU
-
即使不添加任何规则,某些发行版也会加载iptables模块
-
如果不需要iptables,则卸载该模块
# modprobe -r iptable_filter # modprobe -r ip_tables复制 -
性能变化
• RSS (+XPS): 270,000 tps (大概 360Mbps)
• +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
• +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
• +SO_ATTACH_...: 4,250,000 tps (大概 5640Mbps)
• +Pin threads: 5,050,000 tps (大概 6710Mbps)
• +Disable GRO: 5,180,000 tps (大概 6880Mbps)
• +Unload iptables: 5,380,000 tps (大概 7140Mbps)
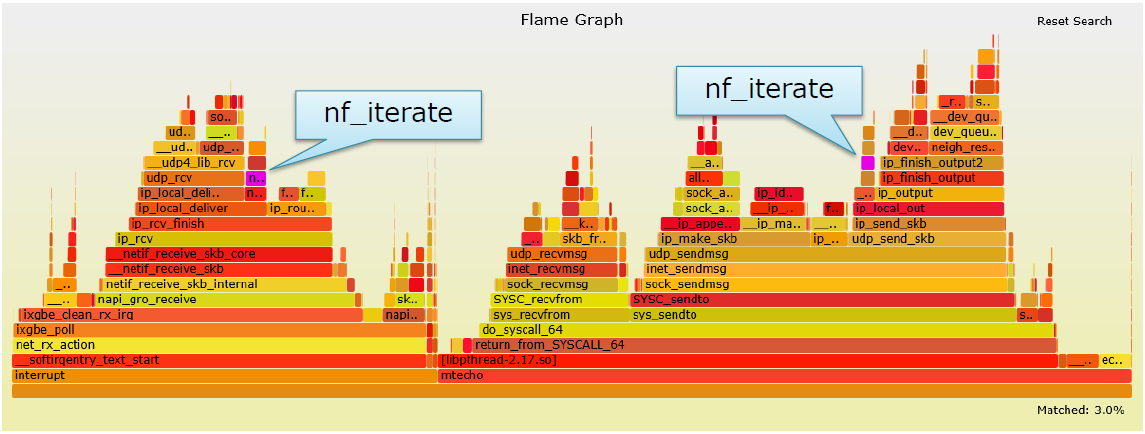
优化单个核3
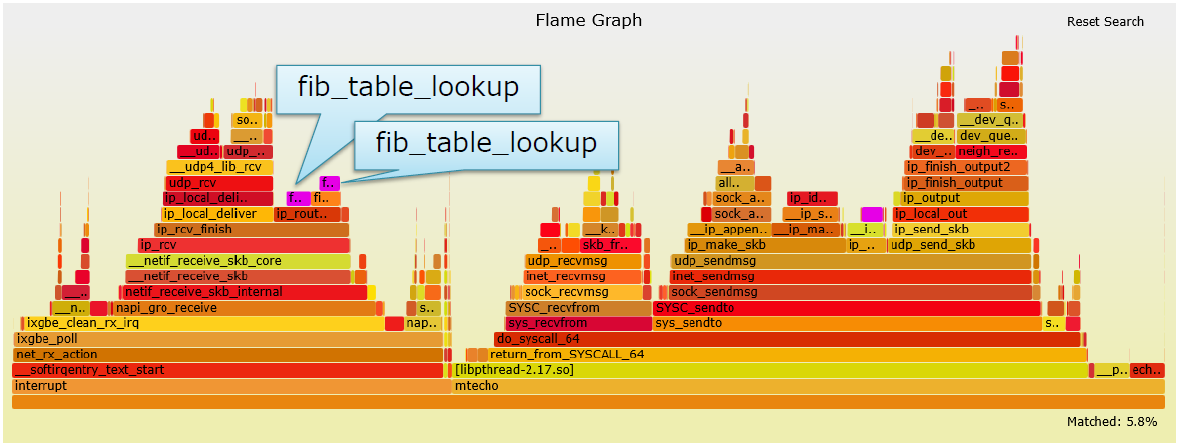
-
在接收路径上,FIB查询了两次。每次消耗1.82%~的CPU时间。其中以此用于校验源IP地址:
- 反向路径过滤器
- 本地地址校验
-
如果不需要源校验,则可以忽略
# sysctl -w net.ipv4.conf.all.rp_filter=0 # sysctl -w net.ipv4.conf.<NIC>.rp_filter=0 # sysctl -w net.ipv4.conf.all.accept_local=1复制 -
性能变化
• RSS (+XPS): 270,000 tps (大概 360Mbps)
• +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
• +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
• +SO_ATTACH_...: 4,250,000 tps (大概 5640Mbps)
• +Pin threads: 5,050,000 tps (大概 6710Mbps)
• +Disable GRO: 5,180,000 tps (大概 6880Mbps)
• +Unload iptables: 5,380,000 tps (大概 7140Mbps)
• +Disable validation: 5,490,000 tps (大概 7290Mbps)
优化单个核4
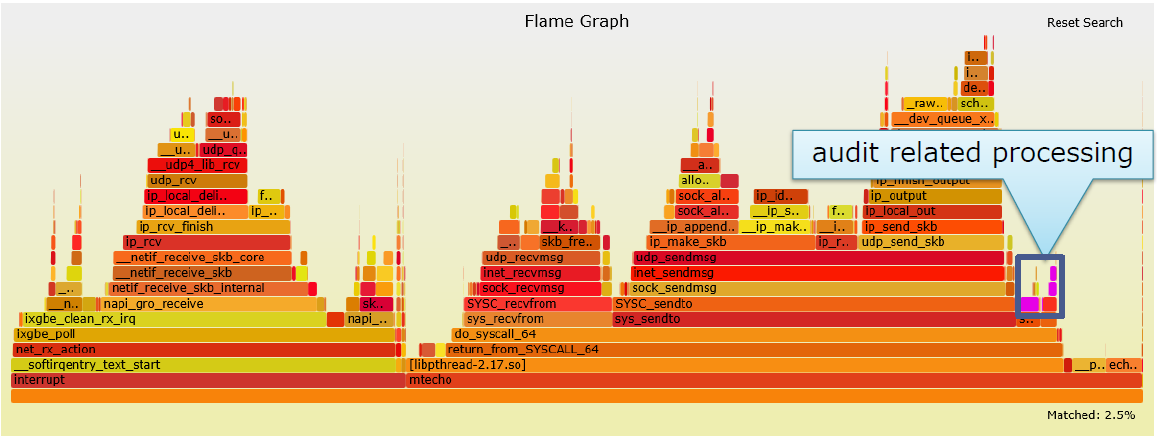
-
当大量处理报文时,Audit消耗的CPU会变大。大概消耗2.5%的CPU时间
-
如果不需要audit,则禁用
# systemctl disable auditd # reboot复制 -
性能变化
• RSS (+XPS): 270,000 tps (大概 360Mbps)
• +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
• +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
• +SO_ATTACH_...: 4,250,000 tps (大概 5640Mbps)
• +Pin threads: 5,050,000 tps (大概 6710Mbps)
• +Disable GRO: 5,180,000 tps (大概 6880Mbps)
• +Unload iptables: 5,380,000 tps (大概 7140Mbps)
• +Disable validation: 5,490,000 tps (大概 7290Mbps)
• +Disable audit: 5,860,000 tps (大概 7780Mbps)
优化单个核5
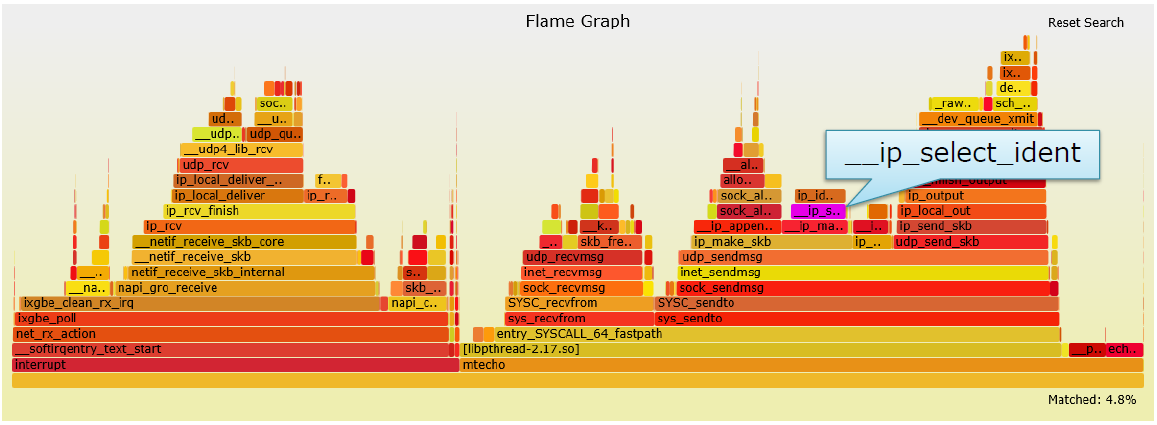
-
IP ID字段计算(__ip_select_ident)消耗的CPU比较多,消耗大概4.82%的CPU
-
该字段用于解决特定环境下的问题
- 如果很多客户端使用了相同的IP地址
- 原子操作会造成缓存竞争
- 如果不使用隧道协议,很可能看不到如此大量的CPU消耗
- 如果很多客户端使用了相同的IP地址
-
如果真的碰到这种问题
-
只有在不发送大于MTU的报文时才可以跳过它
-
虽然非常严格
int pmtu = IP_PMTUDISC_DO; setsockopt(sock, IPPROTO_IP, IP_MTU_DISCOVER, &pmtu, sizeof(pmtu));复制
-
-
-
性能变化
• RSS (+XPS): 270,000 tps (大概 360Mbps)
• +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
• +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
• +SO_ATTACH_...: 4,250,000 tps (大概 5640Mbps)
• +Pin threads: 5,050,000 tps (大概 6710Mbps)
• +Disable GRO: 5,180,000 tps (大概 6880Mbps)
• +Unload iptables: 5,380,000 tps (大概 7140Mbps)
• +Disable validation: 5,490,000 tps (大概 7290Mbps)
• +Disable audit: 5,860,000 tps (大概 7780Mbps)
• +Skip ID calculation: 6,010,000 tps (大概 7980Mbps)
超线程
-
目前还没有启用超线程
-
启用之后的逻辑核为40个
- 物理核为20个
-
需要给40个核配置RPS
- 提示:最大可用的接收队列为16
-
启用超线程,并在所有的接收队列上设置RPS
• queue 0 -> core 0, 20
• queue 1 -> core 1, 21
• ...
• queue 10 -> core 10, 16, 30
• queue 11 -> core 11, 17, 31
• ... -
性能变化
• RSS (+XPS): 270,000 tps (大概 360Mbps)
• +affinity_hint+RPS: 17,000 tps (大概 23Mbps)
• +SO_REUSEPORT: 2,540,000 tps (大概 3370Mbps)
• +SO_ATTACH_...: 4,250,000 tps (大概 5640Mbps)
• +Pin threads: 5,050,000 tps (大概 6710Mbps)
• +Disable GRO: 5,180,000 tps (大概 6880Mbps)
• +Unload iptables: 5,380,000 tps (大概 7140Mbps)
• +Disable validation: 5,490,000 tps (大概 7290Mbps)
• +Disable audit: 5,860,000 tps (大概 7780Mbps)
• +Skip ID calculation: 6,010,000 tps (大概 7980Mbps)
• +Hyper threading: 7,010,000 tps (大概 9310Mbps) -
猜测,如果更多的rx队列可能会获得更好的性能
更多热点1
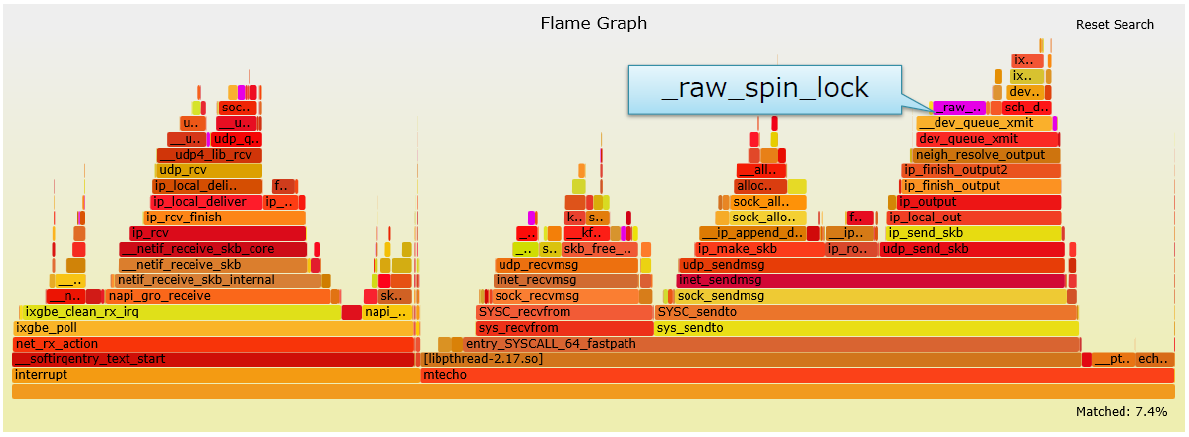
- Tx Qdisc锁(_raw_spin_lock)的消耗比较严重
- 没有竞争,但出现了很多原子操作
- 在Linux netdev社区中进行优化
更多热点2

- slab内存申请和释放
- 在Linux netdev社区中进行优化
其他挑战
- UDP服务器的环境为guest
- Hypervisor可能使CPU饱和或丢弃报文
总结
-
对于100字节的数据,可以达到几乎10G的速率
- 从:270,000 tps (approx. 360Mbps)
- 到:7,010,000 tps (approx. 9310Mbps)
-
提高UDP性能
-
应用(最关键)
- 实现
SO_REUSEPORT - 实现
SO_ATTACH_REUSEPORT_EBPF/CBPF - 对TCP监听socket同样有效
- 实现
-
OS设置
-
检查smp_affinity
-
如果rx队列不足,则使用RPS
-
确保配置了XPS
-
考虑如下降低单核开销的方法
• Disable GRO
• Unload iptables
• Disable source IP validation
• Disable auditd
-
-
-
硬件
- 如果可能,使用具有足够RSS接收队列的NICs(如核数相同的队列)