Docker
-
什么是docker?
docker是基于Golang语言进行开发的一个开源应用容器引擎,换言之就是运行在宿主机上的一个sandboxed process,但是它与宿主机的其它进程是相互隔离的,是操作系统层面的一种虚拟化技术
-
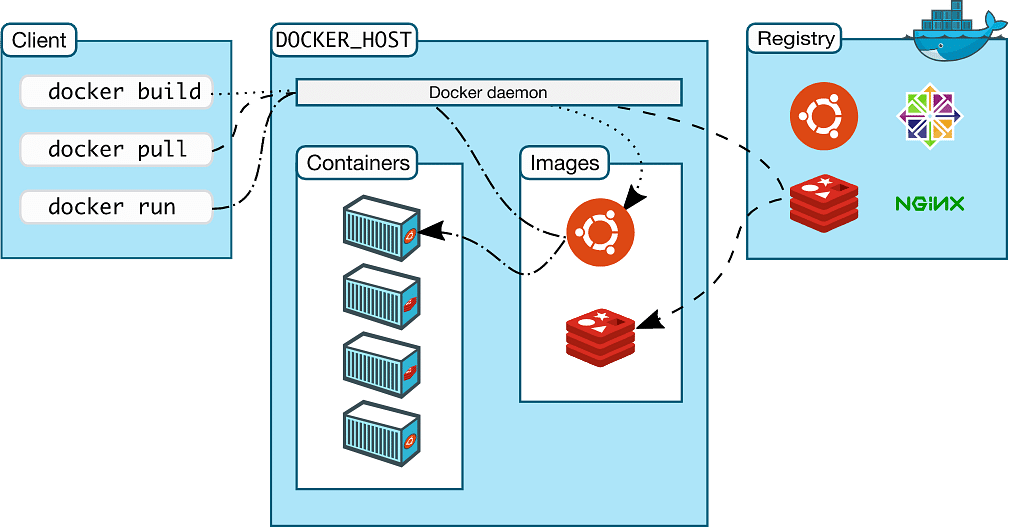
docker组件模块有哪些?
- docker client
- docker server (docker daemon、 docker engine、docker container )
- docker registry
-
docker是如何实现资源隔离及资源限制?
docker是基于linux内核中cgroup&namespace技术来实现资源限制与资源隔离
-
docker初始化过程?
docker是通过执行二进制文件dockerd同时读取docker配置文件deamon.json文件完成初始化过程,docker启动配置文件常用配置一般有如下
-
容器的cgroup的驱动类型是什么,比如systemd还是cgroupfs
-
容器的日志驱动类型,以及日志策略
-
容器的存储驱动类型
-
docker的根目录位置等
-
docker启动一个容器的过程?
-
docker client发起启动容器请求至docker server通常由docker deamon所接受该请求
-
docker deamon接收到请求,进行对参数的分析,需要映射什么卷,多少CPU,多少内存,什么网络模式,使用什么镜像等容器名字等等
-
如果当前宿主机没有启动需要的镜像,那需要从镜像仓库拉取镜像
-
以上过程完成结束容器整个启动过程
-
docker有哪些优势?
-
资源空间占用少,与传统虚拟机相比,它不需要虚拟硬件设备而带来的额外空间使用,所有的运行基础环境都是共享操作系统本身的
-
启动速度快,与传统的虚拟机相比,在启动时docker不需要准备虚拟设备初始化过程,它凌驾于操作系统内核上执行启动应用程序
-
可移植性便携性,docker是一个跨平台产品,而且它使用镜像保留应用系统运行环境的一致性,可随时随地进行跨平台移植
-
便于维护管理,与传统环境区别就是,只需要维护好每个应用对应的镜像就可以了
-
持续集成及部署,由于docker使用镜像管理应用的运行环境,在发布时只需要针对应用系统制定相应Dockerfile集合一些脚本简化传统发布过程
-
容器与镜像的关系?
如果把镜像看成一个类,那么容器就是一个对象;镜像提供了容器运行环境,而容器就是镜像运行时状态,可以看作成是一个被隔离的进程
-
镜像如何分层?
-
镜像是由多个镜像层堆叠形成的,在制作镜像时编写的Dockerfile中的每条指令都是一个镜像层
-
未运行镜像只有镜像层
-
运行进container分镜像层与容器层(通常镜像层称之为容器的底层,容器层称之为可写层writable layer)
-
什么是CoW?
CoW是容器运行时进行读取&修改文件使用的功能,在容器运行时分为镜像层&容器层,如果发生文件修改时,如果容器层没有要修改文件,则使用CoW功能从镜像层拷贝一个文件副本容器层中
-
Dockerfile都有哪些指令?
FROM LABEL ADD COPY RUN EXPOSE WORKDIR ENTRYPOINT CMD USER
-
linux namespace功能?
-
UTS(UNIX Time-shareing System)提供了主机名与域名的隔离,这样每个容器都有自己独立的主机名与域名,在网络层面上可以看成一个独立的节点
-
IPC(Inter-Process Communication)Linux中与IPC相关的资源有系统信号、消息队列、共享内存等,同一个IPC中进程是相互可见的,不同的IPC进程相互不可见
-
PID 其功能就是为进程分配identifier id,二个不同的namespace下可以使用相同的PID,容器中的PID 1号进程通常是在制定镜像时的CMD ENTRYPOINT决定的
-
Mount 其功能就是用来隔离文件系统的挂载点,比如二个不同的容器可以使用相同挂载点
-
NETWORK 主要功能提供网络相关资源隔离,如网络设备、IP协议、路由表、防火墙、socket等,还有网络目录资源/sys/class/net,/proc/net
-
USER 主要功能用来隔离用户相关资源,比如用户ID、组ID、用户HOME目录、用户属性、用户下KEY等
-
CNM CNI区别?
它们二个都是提供容器的网络模型
-
CNM是由Docker公司提出的,全名叫Container netwrok model,主要由三个组件组成network sandbox 、endpoint、network,其中endpoint是成对出现一端在network sandbox中,另一端在network
-
CNI是CoreOS公司提出,全名Container network interface,实现简单只规定容器runtime与网络插件简单契约
二者主要区别在于,CNM是由Docker公司提出,只支持Docker需要一个分布式存储引擎;而CNI是一个开放网络接口,设计简单只提供添加/删除网络接口接口,便于接入网络插件
-
-
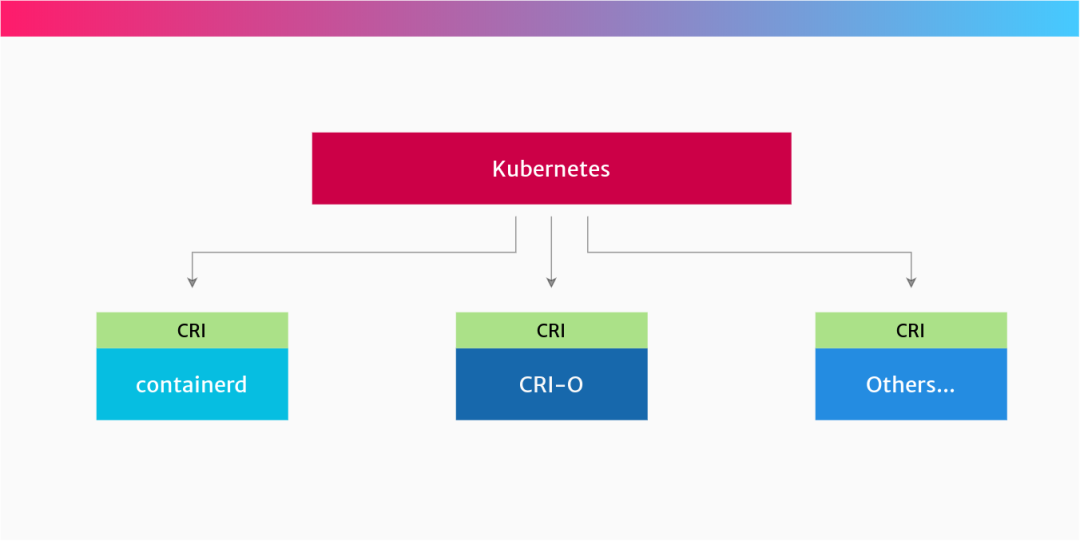
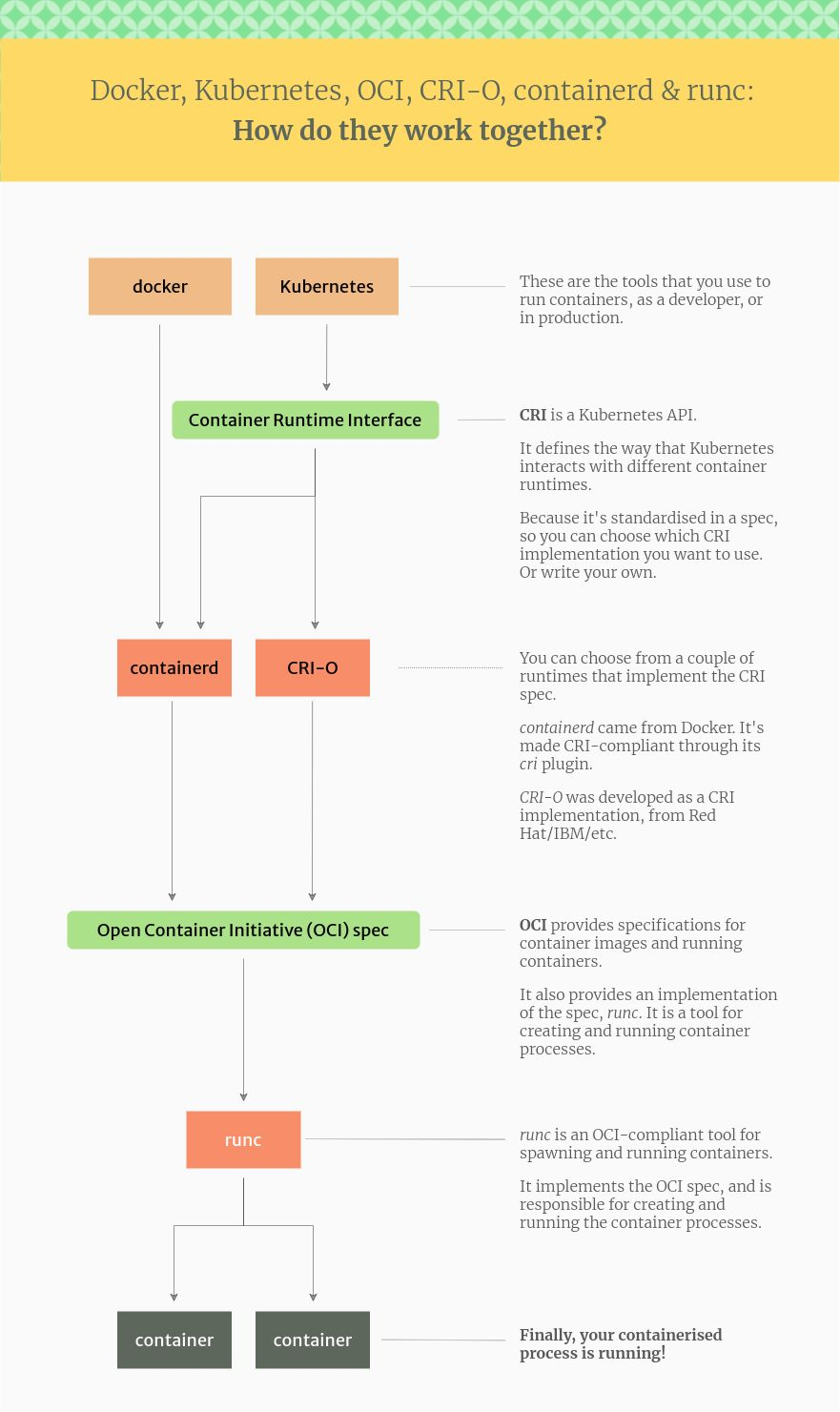
什么是CRI OCI runC?
-
什么是Container runtimes,其实就是容器运行环境,是一个可执行的二进制文件,如containerd、CRI-O、Docker
-
什么是CRI,CRI命名Container runtime interface,是kubernetes提供给Container runtimes一个标准API接口,是Kubernetes与Container runtimes之间的桥梁
-
什么是OCI,全名Open Container Initaitive,它约束容器镜像与Container runtimes开放式行业标准同时也提供调用runC创建容器与运行容器
-
什么是runC,runC更偏向于低层同时也遵守OCI开放规范,直接与Linux内核交互创建容器、运行容器
网络知识
-
什么overlay网络?
是建立在Underlay网络之上的一个逻辑网络,最常见的overlay网络有Vxlan 、NVGRE等
vxlan是一种网络虚拟化技术,采用"MAC IN UDP"的封装形式将二层以太网帧封装在UDP协议中使用IP网络传输数据包
vxlan的优点;它可以突破传统二层VLAN的4096的限制、可以网络分段支持在规模部署、由于是封装技术可以在不同的二层网络传输数据
Kubernetes
-
什么是kubernetes?
Kubernetes是一个可移植、可扩展的应用容器管理平台工具,是google公司基于golang语言开发的,结合容器技术解决了传统应用部署无法定义资源边界,资源分配过渡浪费,资源隔离、应用分布式部署等
-
Kubernetes功能?
-
服务发现和负载均衡
-
编排
-
滚动发布与回滚
-
Pod资源分配限额
-
自动修复
-
弹性扩容(可以使用label功能选择匹配Pod,监控容器资源使用情况动态扩展Pod的数量)
-
密钥与配置管理(kubernetes可以在不重构Pod情况下,更新密钥及应用配置信息)
-
Kubernetes架构组成
Kubernetes是由多组节点组成的,如果按节点的功能划分为控制节点(control plane)与工作计算节点(work node);控制节点负责集群访问控制、资源分配、资源调度、资源部署、集群高可用、故障转移、集群控制节点一般都是分布式跨节点运行提供容错机制,工作节点主要负责为Pod提供运行环境及网络规则使Pod能与集群内部与外部实现网络通信
- 控制平面组件
-
etcd
是一个强一制性分布式K/V数据库,在kubernetes环境中主要负责存储集群状态及配置信息;同时还提供kube-controller-manager & kube-scheduler高可用、容错机制等
-
kube-apiserver
kube-apiserver是整个kubernetes集群环境唯一访问入口,是集群中控制枢纽中心组件,kube-apiserverr提供了集群API接口,是kubernetes集群的前端,比如集群访问、资源查看等都要通过kube-apiserver来完成,但是kube-apiserver本身不具备负载均衡功能,通常在kube-apiserver组件配置一个负载均衡来实现流量平衡分流
-
kube-controller-manager
kubernetes集群中控制器管理器,主要负责管理集群各种控制器通过kube-apiserver提供的list-watch接口实时监控集群中资源状态变化,如果发生资源状态与预期不一致情况下(比如RC副本控制器中Pod数量与期望值有差异,那么这时RC控制器创建缺少Pod)对应的控制器纠正修复资源状态确保与期望值一样,常见控制如下
-
Replication Controller
-
Endpoint Controller
-
Node Controller
-
Namespace Controller
-
ResourceQuota Controller
-
Job Controller
-
-
cloud-controller-manager
云控制器器可以将集群与云提供商的API连接,一般定制开发,比如让自建的集群与阿里云的SLB互联 -
scheduler-manager
集群资源调度器,主要负责将新创建和未调度的Pod,根据输入的调度算法&调度策略绑定到最合适的Node上,并将绑定信息写入到到etcd数据库中,整个过程涉及到三个资源对象,待调度的Pod、可用Node列表、调度算法与调度策略
影响调度策略因素,几种常见的如下-
资源负载
-
污点策略
-
亲和性策略
-
- 工作节点组件
-
kubelet
运行在集群环境每个节点的agent,主要接收并处理来自kube-apiserver的调度任务,并且定期向kube-apiserver发送节点资源状态信息,主要功能负责Pod管理(创建、停止、删除)、健康检查、容器资源监控等
-
kube-proxy
运行在集群环境每个node的网络代理agent,主要功能是实现kubenetes service概念实质组件(kubernetes service属于抽象性资源对象),kube-proxy维护每个节点网络规则(多数由iptables实现)提供Pod在集群内部与集群外部网络通信
-
Container-runtime
提供Pod容器实例的运行环境
-
Kubernetes kubeadm初始化过程
在使用kubeadm初始化集群时,kubernetes支持二种方式(一种是使用kubeadm init 使用命令入参初始化集群;一种是通过config.yaml配置自定义选择初始化集群kubeadm init --config=kubeadm.yaml,配置文件可以使用kubeadm config print init-default生成一个默认配置文件,可以根据自己的要求进行个性修改,如Pod/Service网络、apiserver地址、镜像仓库地址、DNS Domain
以下使用kubeadm init 初始化过程步骤拆解
-
第一步 kubeadm init preflight
初始化前置环境条件检查,检查项包括,kubernetes组件镜像、Container runtime、kubernetes端口检查等
-
第二步 kubeadm init certs
生成一个自签名CA证书与密钥为集群每个组件建立身份标识,在初始化过程中证书默认保存在每个节点的/etc/kubernetes/pki目录下(在初始化过程时可以使用参数--cert-dir指定目录)
-
第三步 kubeadm init kubeconfig
生成kubeconfig访问集群配置文件(默认位置保存control-plane节点/etc/kubernetes/目录下)用来提供给kubelet、controller-manager、schedulerl连接kube-apiserver,同时生成admin.conf提供kubeadm初始化过程使用(该文件可以用来管理集群)
-
第四步 kubeadm init control-plane
生成control-plane组件Pod配置清单文件,默认保存位置/etc/kubernetes/manifests目录下
-
第五步 kubeadm init mark-control-plane
标识集群控制节点,配置标签及污点,防止应用Pod被调度到控制节点上
-
第六步 kubeadm init bootstrap-token
生成集群引导注册token,主要用来工作节点使用该token注册到集群中
-
第七步 kubeadm init upload-config & kubeadm init upload-certs
上传kubelet、kubeadm配置至configMap中,主要用来新创建的工作节点加入集群时使用;上传引导集群token及集群CA证书
-
第八步 kubeadm init addon coredns
初始化集群DNS插件,主要提供集群内部域名解析
-
Kubernetes kubelet启动过程
kubelet监听端口 HTTPS 10250 & HTTP 10255
-
启动kubeletServer,加载kubelet本身的属性及检查kubeletServer进程结构信息(接口、进程结构等)
-
检索加载kubeconfig配置文件,引导kubelet与集群kube-apiserver进行通信进行节点状态检查,并注册自己
-
检查加载kubelet config配置文件,初始化kubelet进程实例,主要工作初始化配置Cgroup驱动、DNS、Domain、网络插件、网络地址、健康检查探针、Container runtime、垃圾回收策略、资源保留策略等
-
Kubernetes 创建Pod过程
-
客户端发起创建Pod资源请求
-
kube-apiserver接收到REST API请求后,验证请求的合法性(用户认证、授权、资源配额等)
-
验证通过,kube-apiserver将创建Pod资源对象写入etcd数据库中并生成创建Pod事件消息
-
kube-scheduler通过kube-apiserver API接口,周期性从etcd获取集群中可用的node节点与待调度的Pod事件消息,根据调度策略计算出最合适node节点,将Pod与node绑定在一起
-
kube-scheduler调用kube-apiservr API接口将绑定事件消息写入到etcd数据库中
-
kubelet会定期性监听kube-apiserver API接口,来获取Pod资源事件消息,如果是创建Pod对象,则调用Container runtime创建容器实例
-
创建成功后,kubelet会将Pod的状态上报给kube-apiserver,并将Pod的状态写入到etcd数据库中
-
Kubernetes 创建Deployment过程
创建的过程大致与创建Pod的过程相类似
-
客户端发送创建Deployment资源请求
-
kube-apiserver接收到请求后,验证请求的合法性
-
验证通过后,kube-apiserver将创建资源对象同步写入etcd数据库中,并生创建deployment资源事件消息
-
kube-controller-manager监听kube-apiserver的API接口,定期从etcd获取创建deployment资源事件消息并创建replicationSet资源,kube-apiserver同时将RS资源状态写入到etcd数据库
-
kube-controller-manager监听kube-apiserver的API接口,从etcd获取创建RS对象资源状态时,RS控制器获取到期望Pod状态,并将创建Pod请求通过kube-apiserver写入到etcd数据库
-
kube-scheduler通过监控kube-apiserver API接口, 从etcd获取集群中可用的node节点列表与待调度的Pod事件消息,根据调度策略计算出最合适的node节点,将Pod与node绑定在一起
-
kube-scheduler调用kube-apiserver API接口将绑定事件更新到etcd数据库中
-
kubelet定期性监听kube-apiserver API接口,获取到需要创建Pod资源时, 调用Container runtime创建容器实例
-
创建成功后,kubelet将Pod状态信息上报给kube-apiserver后,kube-apiserver将Pod资源状态更新到etcd数据库
-
Kubernetes Pod原理
- 什么是Pod?
在kubernetes环境中Pod是最小调度单元,而非容器实例;Pod是由一个容器或者一组容器实例组成的最小调度单位,
- Pod功能特征?
-
Pod中的所有容器实例在同一时间同时调度到同一个节点上
-
Pod中的容器实例相互共享一个网络空间,使用同样的IP地址、端口范围、网络名称
-
Pod中的窗口实例相互共享一个MOUNT空间,容器之间可以共享文件系统、共享数据
-
- Pod应用场景
-
一个内容管理系统,包括文件、数据加载器、本地缓存管理系统的组合
-
一个常规应用与日志与检查点备份、压缩、轮换、快照系统的组合
-
一个常规应用与它的数据变化器、日志实时收集、事件发布器的组合
-
一个常规应用和它的网络代理、桥接、适配器等网络辅助组件的组合
-
-
Kubernetes Pause 容器功能
在理解 Pause Pod存在的意义,再回顾一下,为什么Kubernetes需要Pod?
为什么要使用Pod作为Kubernetes集群中最小调度单位,直接使用Docker不行吗?Docker确实非常适合单个应用进程部署,但是如果遇到需要多个应用程序彼此需要相互共享数据时,怎么办?当然你可以把所有应用程序封装在一个容器中,这样封装在一个容器时会暴露出很多缺陷,如下几点-
容器变得臃肿而又复杂不易管理
-
启动脚本变得复杂,并不像之前单体应用进程部署
-
init 1进程需要业务进程来承担收割容器中的僵尸进程,占用资源长期不会释放
-
多个应用程序封装在一起,无法对非init1进程提供自我治愈功能
什么是 Pause 容器?
kubernetes在设计时并不提倡“富容器”这种使用方式,认为将多个应用程序封装在一个部分资源隔离且部分资源共享的集合中更为合理一些,这个容器的集合就叫Pod,在Kubernetes集群中,Pod是个抽象对象资源,那么具体实现Pod的实质工具就是Pause Pod
Pause 容器是Pod所有容器的”根容器 或 父容器“,为每个业务容器提供以下功能
-
Pod中所有容器实例共享一个网络命名空间,使用同样端口范围、网络名称、IP地址
-
Pod中所有容器实例共享一个存储命名空间,可以共享文件系统、共享数据
-
在启用PID namespace时,Pause容器为每个业务容器提供init1进程,通过调用wait()来收割业务容器的僵尸进程
在kubernetes1.8之后,关闭默认开启shareProcessNamespace功能,原因如下
-
当执行kill -HUB 1时,1号进程无法对应业务容器的进程
-
当启用PID namespace时,所有容器共享一个进程命名空间,意味着/proc目录所有容器都是可见的(例如在进程上传递参数,环境变量传递敏感信息时会带一定的风险)
-
-
Kubernetes kube-proxy原理
- 什么是kube-proxy?
kube-proxy是运行在每个node节点的网络代理agent,是提供kubenetes service服务发现、反向代理、负载均衡等功能,其主要职责就是将某个service的访问请求正确的转发到后端的Pod实例上
-
问题一:为什么要转发给service,而不是其它的对象资源,比如直接转发给Pod上
Service是一组具有相同功能Pod的访问入口,本身具有固定的IP地址与端口,并负责把请求转发给后端相应Pod上,因为在kubernetes环境中Pod的IP地址不是固定的,而Service可以解决这一问题,Service是根据label selector标签选择匹配相应的Pod,并将绑定在一起
-
问题二:服务发现是如何实现的?
kube-proxy是通过调用kube-apiserver API接口来监控集群中service与endpoint对象资源的变化,并维护service到endpoints的映射关系,当资源状态发生变化能够及时更新
-
问题三:负载均衡是如何实现的?
kube-proxy是通过iptables中的一个probability模块实现负载均衡与IPVS实现负载均衡
-
-
kube-proxy实现原理
kube-proxy在运行过程中会动态创建与service相关的iptables规则,使用NAT技术实现service与Pod的流量转发,在调用过程中客户端无须关心后端有多少Pod,网络通信是透明的 -
kube-proxy有哪几种模式?
-
userspace
当某个Pod以ClusterIP方式访问service时,流量会被Pod所有节点的iptables转发给本机的kube-prxoy进程,然后由kube-proxy建立与后端Pod的TCP/UDP连接,随后将流量转发给某个后端的Pod(与HAPrxoy类似)整个过程发生在用户态空间
-
iptables
与userspace模式不同的是iptables是使用系统内核态完成整个过程,其实现原理是通过kube-apiserver的watch接口实时监控service与endpoints的对象资源状态,如果状态发生变化,并更新相应的iptables规则
-
ipvs
ipvs是解决了iptables在大规模部署情况下service与Pod急速膨胀,导致处理性能下降而引入的第三代迭代产品,支持了更多负载均衡算法及新增iptables的扩展功能ipset
-
-
Kubernetes 副本控制器
kubernetes中的副本控器主要职责是通过标签选择器匹配一组或多组Pod,实时维护期望的Pod与实际Pod保持一致,并保证Pod可用性
-
replication Controller
RC是kubernetes第一代管理Pod副本控制器,原始的功能就是用来复制Pod与处理异常Pod重新调度
-
replicaSet
RS是kubernetes继RC基础上升级新一代副本控制器,与RC不同的是Pod的选择器表达更丰富些,RC不能同时支持多个匹配对,而RS使用matchLabels同时可以支持多个匹配对,而且它还支持运算表达oprator(In NotIn Exists DoesNotExist)
-
Deployment
Deployment是在后面升级部署控制器, 同时它也兼顾RS所有的功能,但是Deployment更像是为RS提供声明式部署并提供滚动更新
与RS滚动更新不同之处是,Depolyment的滚动更新是后端服务接管的,而RS的是交互式是由kubectl发起的
-
Kubernetes Deployment Yaml文件组成结构
-
apiVersion版本
-
kind 对象资源
-
metadata 元数据(指定该deployment的名字、标签)
-
spec 详细规格(replica副本数量、标签选择、滚动更新策略、网络模式、污点容忍、节点亲和性、容器配置)
-
Kubernetes 高级功能 (RBAC)
-
RBAC&ABAC
-
污点容忍
节点亲和性是Pod的一种属性,主要功能就是能够吸引Pod到一类节点之上
污点则正好与亲和性相反,它使节点能够排斥一类特定的Pod,而容忍度则是应用于Pod上,功能就是允许Pod调度到与之匹配污点的节点上
污点与容忍度需要配合使用,可以避免Pod被分配到不适合的节点上,每个节点可以设置一个或者多个污点

# 为以下二台节点设置污点,定义key=value:effect # effect的值有PreferNoSchedule NoSchedule NoExcute <root@PROD-K8S-CP1 ~># kubectl taint node prod-sys-k8s-wn1 resource=addons:NoExecute node/prod-sys-k8s-wn1 tainted <root@PROD-K8S-CP1 ~># kubectl taint node prod-sys-k8s-wn2 resource=addons:NoExecute node/prod-sys-k8s-wn2 tainted # 为Pod设置容忍度,如下 # 容忍语法分为key value operator effect # 调整core-dns的污点容忍 tolerations: - key: CriticalAddonsOnly operator: Exists - key: node-role.kubernetes.io/master effect: NoSchedule - key: resource value: addons effect: NoExecute复制 -
节点亲和性
节点的亲和性类似于nodeSelector,可以根据节点的标签决定Pod被调度到具体的节点上,节点亲和性分二种,如下
-
requiredDuringSchedulingIgnoredDuringExecution 强制匹配节点的标签属性
- preferredDuringSchedulingIgnoredDuringExecution 优先选择,如果没有匹配到节点的标签,也可以被调度匹配require规则
在节点亲和性配置中,表达式中的operator字段,支持的运算符有:In、NotIn、Exists、DoesNotExist、Gt 和 Lt,其中NotIn DoesNotExist可以实现节点的反亲和性
同时指定了 nodeSelector 和 nodeAffinity,两者 必须都要满足, 才能将 Pod 调度到候选节点上
如果指定了多个nodeSelectorTerms, 只要其中一个 nodeSelectorTerms 满足的话,Pod 就可以被调度到节点上
如果在同一个nodeSelectorTerms 关联了多个matchExpressions, 则只有当所有 matchExpressions 都满足时 Pod 才可以被调度到节点上
配置文件
apiVersion: v1 kind: Pod metadata: name: with-node-affinity spec: affinity:
## 下面二段的配置解释为,优先选择匹配preferredf规则中的集群节点含有标签another-node-label-key,值为another-node-label-value的节点
##复制nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 //可以设置权重 preference: matchExpressions: - key: another-node-label-key operator: In values: - another-node-label-value containers: - name: with-node-affinity image: k8s.gcr.io/pause:2.0复制 -
-
Pod亲和性
Pod之间的亲和性与反亲和性是基于运行在节点上的Pod的标签而非Node的标签
具体规则定义是,如果X节点运行一个或多个满足Y规则的Pod,那么Y就会被调度到该节点上
在发生调度时,处理Pod之间的亲和性与反亲和性会消耗大量的CPU,因此kubernetes不建议在大规模集群环境中上百台node设置这样的规则
Pod亲和性与反亲和性,与Node亲和性类似,也存在二种类型
requiredDuringSchedulingIgnoredDuringExecution & preferredDuringSchedulingIgnoredDuringExecution
配置文件参考
apiVersion: v1 kind: Pod metadata: name: with-pod-affinity spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - S1 topologyKey: topology.kubernetes.io/zone podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: security operator: In values: - S2 topologyKey: topology.kubernetes.io/zone containers: - name: with-pod-affinity image: k8s.gcr.io/pause:2.0复制 -
滚动更新
在kubernetes环境中使用滚动更新RollingUpdates实现对业务系统零停机更新,通过创建新实例逐步更新Pod实例
Rollover
多个更新同时进行情况,Deployment Controller发现有新的Deploymnt时,同时会创建对应的ReplicaSet并创建期望的Pod实例
如果已经发现有一个正在更新的Deployment,比如它的期望是5个副本,已经完成了3个,但在此时新的Deployment发起更新,这种情况下会立即KILL前面创建的3个整本,并执行最新的更新
RollingUpdates更新策略是基于二个参数(MaxSurge & MaxUnavailabel)来控制整个更新过程
-
MaxSurge
最大可用数 .spec.strategy.rollingUpdate.maxSurge,代表在滚动更新时最大可用的Pod数,其值可以设置成百分比(当是百分比时通常向上取整转换为绝对数),可以设置绝对数,默认是25%
比如,当MaxSurge设置为30%,那么在整个更新过程最大Pod数是130%
-
MaxUavailable
最大不可用数,.spec.strategy.rollingUpdate.maxUnavailable,代表在滚动更新时最大不可用Pod数,其值可以是百分比或者是绝对数,默认值是25%
在更新过程,kubernetes在计算availableReplicas数值,不计算被终止的Pod,其公式如下
replicas - MaxUnavailable ≤ availableReplicas ≤ replicas + MaxSurge
举例,如果replicas是5,MaxSurge是50%,MaxUnavailable是50%,那么可用的Pod值在 3和8之间,更新过程如下
-
新副本scale 3,同时进行老副本scale 3 = 5 - 2,此时总的Pod数为6(3个新的,3 个老的)
-
新副本scale 2,同时进行老副本scale 0 = 3 - 3,此时总的Pod数为5(5个新的,0个老的)
-
- 弹性扩容
具体算法
期望副本数== ceil[当前副本数 * (当前指标 / 期望指标)]
重要参数
-
--horizontal-pod-autoscaler-initial-readiness-delay
当触发HPA策略时,新扩容的Pod初始化缓冲时间,默认值是30秒
-
-horizontal-pod-autoscaler-cpu-initialization-period
新扩容的Pod初始化完成,该Pod启动过程需要时间,那么这个就是Pod启动缓冲时间,默认时间是5分钟
配置范例
apiVersion: autoscaling/v2beta2 kind: HorizontalPodAutoscaler metadata: name: prod-common-service namespace: prod spec: minReplicas: 3 maxReplicas: 5 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: prod-common-service metrics: - type: Resource resource: name: cpu target: averageUtilization: 50 type: Utilization - type: Resource resource: name: memory target: averageUtilization: 70 type: Utilization复制按照域名请求并发
type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 2k复制 -
- Secret
- JOB
-
版本回滚
当在更新的时候发现版本不稳定的情况下,需要执行回滚操作,kubernetes支持三种回滚的方式,如下
-
使用之前镜像版本进行回滚
kubectl set image deployment/nginx-deployment nginx=nginx:1.161 --record=true
复制 -
使用新的Deployment文件,只要文件发生过变化,那么就会被更新
kubectl apply -f new-deployment.yaml
复制 -
使用kubernetes的版本历史记录进行回滚
## 第一步查看历史版本 kubectl rollout history deployment/nginx-deployment ## 回滚到指定的版本 kubectl rollout history deployment/nginx-deployment --revision=2
复制
-
-
健康检查
探针参数解释
• initialDelaySeconds: 300
初始化启动后宽限时间,在此期间不做探针检查,默认值是0
• timeoutSeconds: 5
探针探测失败后的超时时间,默认值是1
• periodSeconds: 10
宽限期结束后,每隔10秒进行探测一次,默认值是10s
• successThreshold: 1
在执行探测时, 如果连续成功一次就视为成功,默认值是1
• failureThreshold: 3
探测失败后的,重试次数,默认值是3
整个Pod在初始化到结束探测检查的最大生命周期时间,如下公式
initialDelaySeconds+ fialureThreshold* periodSeconds+timeoutSeconds
kubernetes环境中支持三种常见healthcheck,如下
- TCP探测
apiVersion: v1 kind: Pod metadata: name: goproxy labels: app: goproxy spec: containers: - name: goproxy image: k8s.gcr.io/goproxy:0.1 ports: - containerPort: 8080 readinessProbe: tcpSocket: port: 8080 initialDelaySeconds: 5 periodSeconds: 10 livenessProbe: tcpSocket: port: 8080 initialDelaySeconds: 15 periodSeconds: 20复制 -
HTTP接口探测
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-http spec: containers: - name: liveness image: k8s.gcr.io/liveness args: - /server livenessProbe: httpGet: path: /healthz port: 8080 httpHeaders: - name: Custom-Header value: Awesome initialDelaySeconds: 3 periodSeconds: 3复制 -
使用命令探测,如题命令返回为0代表正常
apiVersion: v1 kind: Pod metadata: labels: test: liveness name: liveness-exec spec: containers: - name: liveness image: k8s.gcr.io/busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600 livenessProbe: exec: command: - cat - /tmp/healthy initialDelaySeconds: 5 periodSeconds: 5复制
- TCP探测
- 资源预留
- 优先级
- 网络策略
- 驱逐策略
-
Kubernetes 常用命令
中间件
Redis
Redis的定义,Redis其实是一个内存型数据数据库,主要用来提高吞吐量、降低延迟面设计的
-
集群模式
-
主从模式(master & slave)
这种模式情况下,master可以读写,slave只可以读,俗称读写分离主写从读,但是只要master节点出现故障地,那么集群将不可用
-
哨兵模式(Sentinel)
在主从模式的基础上,使用哨兵接管提供故障检测、主从切换,但是sentinel模式在高并发情况下发生故障切换时,会出现短暂不可用;集群扩容节点比较复杂;由于主从模式节点的数据是一样的,浪费内存资源
-
集群模式(cluster)
Redis Cluster是一种服务器sharding技术,3.0版本支持,主要规避sentinel浪费内存资源
-
数据分片
Redis Cluster数据分片使用hash slot,每个节点都有16384哈希槽,每个KEY通过CRC16算法得出的结果然后对16384取余,最终决定KEY读写到那个slot中
Redis Cluster每个节点都保存整个集群槽的信息,如果发生读写操作时,根据槽的信息获取节点的信息,完成读写
-
集群复制
同样cluster模式也是采用了主从模式,当节点发生故障时,进行主从切换
-
读写分离
-
常见问题
- 过期策略
根据业务系统具体要求,对KEY设置过期时间
-
KEY的过期时间设置
set key1 value1 EX 60 expire key1 60
复制 -
查看KEY的过期时间
ttl key1
复制 -
具体策略
-
在使用KEY的主动检索KEY的过期时间,如果过期将被淘汰(主要使用maxmemory-policy策略进行淘汰)
-
在Redis资源空闲时CPU使用定时任务ServerCron来检索过期KEY
-
- 淘汰过程,使用Redis中的hz,这个参数主要定义在Redis CPU空闲时每秒执行清理的次数默认是10次,在清理的过程中会依次遍历所有DB,确保所有DB的过期KEY被淘汰
-
- 持久化
-
RDB Redis默认持久化方式,将redis所有数据集以快照的形式在固定时间周期dump到一个文件中(默认dump.rdb)
-
优点:数据恢复速度快(将dump.rdb文件拷贝到redis的安装目录的bin目录下,重启redis),适合场景大规模部署;
-
缺点:数据备份消耗内存资源、数据一致性低
[root@localhost ~]# vim /etc/redis/6379.conf # save <指定时间间隔> <执行指定次数更新操作>,满足条件就将内存中的数据同步到硬盘中
# 官方出厂配置默认是 900秒内有1个更改,300秒内有10个更改以及60秒内有10000个更改,则将内存中的数据快照写入磁盘
# 若不想用RDB方案,可以把 save "" 的注释打开,下面三个注释 # save "" save 900 1 "这三项默认设置" save 300 10 save 60 10000 dbfilename dump.rdb //RDB文件名称 dir /var/lib/redis/6379 //RDB文件路径 rdbcompression yes //是否进行压缩 #当RDB持久化出现错误后,是否依然进行继续进行工作,yes:不能进行工作,no:可以继续进行工作,可以通过info中的rdb_last_bgsave_status了解RDB持久化是否有错误 stop-writes-on-bgsave-error yes #配置存储至本地数据库时是否压缩数据,默认为yes。Redis采用LZF压缩方式,但占用了一点CPU的时间。若关闭该选项,但会导致数据库文件变的巨大。建议开启。 rdbcompression yes #是否校验rdb文件;从rdb格式的第五个版本开始,在rdb文件的末尾会带上CRC64的校验和。这跟有利于文件的容错性,但是在保存rdb文件的时候,会有大概10%的性能损耗,所以如果你追求高性能,可以关闭该配置 rdbchecksum yes #指定本地数据库文件名,一般采用默认的dump.rdb dbfilename dump.rdb #数据目录,数据库会写入这个目录。rdb、aof文件也会写在这个目录 dir /var/lib/redis/6379复制 -
-
AOF 用日志方式记录数据变化,保证数据安全性、完整性
-
优点:数据备份完整,一致性高
-
缺点:恢复效率低,使用日志回滚
[root@localhost ~]# vim /etc/redis/6379.conf '//Redis 默认不开启。它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。 appendonly no appendfilename "appendonly.aof" //指定本地数据库文件名,默认值为 appendonly.aof # 持久化策略 # no 表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快 # always 表示每次写入都执行fsync,以保证数据同步到磁盘 # everysec 表示每秒执行一次fsync,可能会导致丢失这1s数据,默认配置 appendfsync everysec '//everysec:一般情况使用 '
复制 -
-
-
注意事项
-
不要放一些垃圾数据,及时清理无用数据
-
KEY尽量设置过期时间来减少Redis内存空间浪费
-
单个KEY不要设置太大,如果KEY太大的话,会带来网络延迟,降低业务系统处理性能
-
不同的业务使用不同的DB进行划分,这样有助于问题排查及数据清理
-
- 流量使用率高问题
-
对大KEY进行拆分,缓解网络流量
-
开启代理缓存功能(阿里云企业版性能增强性)
-
如果不满足业务需求,需要进行扩容
-
- CPU使用率高
频繁的建立连接会导致Redis实例,消耗大量资源具体表现CPU使用非常高
-
优化短连接,改为长连接,比如使用JedisPool连接池(最大连接数maxTatol、最大空闲数maxIdel、当资源池耗尽时最大等待时间maxWaitMills)
-
优化热点KEY,开启代理查询缓存功能,当在有效的时间内收到同样的请求时,将缓存数据直接返回给客户端,无需和后端的数据分片交互
-
进行扩容
-
- 性能优化参数
-
操作系统net.core.somaxconn 调整内核参数最大linux establish connection
-
操作系统net.ipv4.tcp_max_syn_backlog 调整内核参数SYN RECEIVED的队列
-
修改用户文件句柄数 ulimit -n
-
修改redis最大连接maxclient
-
Nginx
-
模块分类
-
全局模块
-
events
-
http
-
配置参数
连接优化参考文献
## //全局配置 ## //受限于OS文件句柄数ulimit -n worker_rlimit_nofile 102400; ## //nginx的连接处理机制在于不同的操作系统采用不同的IO模型,在linux使用epoll的IO多路复用模型,在freebsd使用kqueue的IO多路复用模型,在solaris使用/dev/Poll方式的IO多路复用模型,在windows使用的是icop等等 events { use epoll; woker_connections 65535; ## //每个worker进程可以同时处理多个客户端请求 multi_accept on; }复制上传文件优化## //sendfile参数用于开启文件高效传输模式。同时将tcp_nopush和tcp_nodelay两个指令设为on用于防止网络阻塞 ## //使用内核的FD文件传输功能,可以减少user mode和kernel mode的切换,从而提升服务器性能 sendfile on; ## //当tcp_nopush设置为on时,会调用tcp_cork方法进行数据传输。使用该方法会产生这样的效果:当应用程序产生数据时,内核不会立马封装包,而是当数据量积累到一定量时才会封装,然后传输。 tcp_nopush on; Syntax: sendfile on | off; Default: sendfile off; Context: http, server, location, if in location ## // 设置客户端连接保持会话的超时时间。超过这个时间,服务器会关闭该连接 keepalive_timeout 65; ## // 打开tcp_nodelay,在包含了keepalive参数才有效 ## //不缓存data-sends(关闭 Nagle 算法),这个能够提高高频发送小数据报文的实时性。on可以提高小数据报文的实时性,off可以降低网络里小包的数量,提升网络性能 tcp_nodelay on; ## // 设置客户端请求头读取超时时间.如超过这个时间,客户端还没有发送任何数据,Nginx将返回“Request timeout(408)"错误,默认值是60。 client_header_timeout 15; ## // 设置客户端请求主体读取超时时间。如超过这个时间,客户端还没有发送任何数据,Nginx将返回“Request timeout(408)错误,默认值是60。 client_body_timeout 15; ## //指定响应客户端的超时时间。这个超时仅限于两个连接活动之间的时间,如果超过这个时间,客户端没有任何活动,Nginx将会关闭连接。 send_timeout 15; Syntax: client_header_timeout time; Default: client_header_timeout 60s; Context: http, server复制
client_max_body_size 25m; client_body_buffer_size 256k; client_header_timeout 3m; client_body_timeout 3m;
types_hash_max_size 2048;复制 -
nginx主进程
-
读取nginx配置文件并验证有效性与正确性
-
建立、绑定和关闭socket
-
管理工作进程
-
实现平滑重启,应用新配置
-
nginx工作进程
-
接收客户端请求
-
与后端服务器通信,接收后端服务器处理结果
-
发送请求结果,响应客户端请求
RabbitMQ
- RabbitMQ集群模式
- RabbitMQ集群原理
- RabbitMQ数据同步
- RabbitMQ如何故障转移?
Kafka
-
消息中间件的定义
消息中间件是基于队列与消息的传递技术,在网络中为应用系统提供同步或者异步、可靠的传递消息的系统
-
kafka功能与使用场景
Kafka可以提供消息异步处理、解耦、削峰、提速等
Kafka应用场景有,流数据处理、日志聚合、事件采集等
Tomcat
-
什么是tomcat
Tomcat是一个开源Servlet容器,轻量级应用服务,同时还提供web服务器的功能,对动态JSP文件解析非常好
-
Tomcat优化参数
Tomcat优化从二个方面开展
-
jvm启动参数
-javaagent:/home/nflow/servers/jvmAgent/jmx_prometheus_javaagent-0.15.0.jar=8888:/home/nflow/servers/jvmAgent/config.yml -server -XX:+UseContainerSupport -XX:MaxRAMPercentage=70.0 -XX:InitialRAMPercentage=70.0 -XX:MinRAMPercentage=70.0 -Duser.timezone=GMT+08 -XX:MaxMetaspaceSize=512M -Xss1M -XX:NewRatio=2 -XX:SurvivorRatio=7 -XX:MaxTenuringThreshold=8 -XX:MaxHeapFreeRatio=75 -XX:MinHeapFreeRatio=40 -XX:TargetSurvivorRatio=80 -XX:MaxGCPauseMillis=500 -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=90 -XX:+UseCMSInitiatingOccupancyOnly -XX:+CMSScavengeBeforeRemark -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGC -XX:+PrintClassHistogram -XX:+PrintAdaptiveSizePolicy -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+PrintGCDetails -XX:+PrintGCTaskTimeStamps -Xloggc:/home/nflow/logs/gc.log -XX:HeapDumpPath=/home/nflow/logs/heapdump.hprof -XX:OnOutOfMemoryError=/home/nflow/scripts/dump-handle
复制 -
Tomcat自身参数
maxConnections // Tomcat处理城的最大连接数,如果超出这值接受请求,但不处理请求,默认值取决于Tomcat使用的Connector type, For NIO and NIO2 the default is 10000. For APR/native, the default is 8192,一般2000足够了 acceptCount // Tomcat在超出处理最大连接数,新的请求被放在这个队列中,默认值是100;如果该队列满了之后,请求被拒绝 maxThreads // 客户请求最大线程数,默认值是200 minSpareThreads // Tomcat在运行状态下的最小线程数,包括空闲与活动线程,默认值是10 enableLookups // 是否反查域名,取值为: true 或 false 。为了提高处理能力,应设置为 false redirectPort // 在需要基于安全通道的场合,把客户请求转发到基于SSL 的 redirectPort 端口 connectionTimeout // 连接超时时间,默认值是6000ms,但是一般情况下设置2000ms keepAliveTimeout // 连接的会话保持时间,默认和connectionTimeout一致
复制
-
Service Discovery
zookeeper
zookeeper是基于JAVA开发的,运行环境需要JDK的支持
-
zookeeper角色
-
leader
集群中只有且仅有一个leader,通过选举过程产生,负责集群所有事务写操作(会话状态、节点变更),保证集群事务处理的顺序性,默认情况下leader也处理集群中的读请求
-
follower
参与leader选举投票,及负责处理客户端非事务性处理(读请求)请求,如果接受到客户端的事务请求,则会转发给leader,让leader进行处理
-
observe
集群中的观察者,不负责集群中选举投票;同时观察集群状态并同步状态,如果接受非事务性请求则独立处理,如果接受到事务请求则转交给leader进行处理,主要功能是提升集群中非事务处理性能
-
端口定义
| 端口 | 功能 |
| 2181 | 负责处理客户端连接 |
| 2888 | 集群之间数据同步 |
| 3888 | 集群选举通信 |
-
启动时选举
zookeeper在选择主要是依据sid
-
Server-1启动后,默认投票给自己
-
Server-2启动后,进行各自投票,然后比较sid(默认zoo.conf文件中指定的myid),发现Server-2的sid编号更大(编号大代表权重高),于是Server-1的投票给Server-2
-
Server-3启动后,进行各自投票,然后比较集群中sid,比较结束后Server-3的sid权重最高,于是一致投票给Server-3,选举结束,Server-3为leader
-
Server-4启动后,此时发现集群的节点Server-1,Server-2,Server-3状态是非LOOKING状态,而且已经有leader的情况下,虽然Server-4的sid权重更高,也不会影响现有的leader
-
运行期选举
如果是在运行时,leader发生故障,进行重新选择主要依据zxid,如下
-
首先Leader发生故障后,集群中的非observer节点状态切换为LOOKING后开始进行选举
-
集群LOOKING节点进行各自投票,分别投给自己与其它节点
-
对比zxid,只要大于自己的进行重新投票,在选举过程中只要票数大于集群节点的一半,即可当选
-
数据同步
-
DIFF
如果leader的记录与follower的记录差别不是太大,记录差别主要依据是minZxid & maxZxid介于二者值之间,就使用DIFF策略进行数据同步,使用增量的方式将事务请求同步给follower
- SNAP
二种场景TRUNC
- peerLastZxid 小于 maxZxid
-
leader没有提议缓存队列,peerLastZxid ≠ maxZxid
介于这二种情况使用SNAP的方式,将leader的内存快照同步给follower并覆盖,主要过程就是leader发起SNAP指令后,进行内存数据序列化同步,follower接收完数据后然后进行反序列化然后存入内存数据库中
-
truncation,场景是当follower的zxid权重或者领先leader的zxid(这种情况有可能是之前降级的leader),在这种情况下使用TRUNC方式将大于leader的记录截取掉并保持与leader的事务记录一致
- etcd
- eureka
- consul
LVS
-
LVS模式
- NAT
首先client 发送请求[package] 给VIP;VIP 收到package后,会根据LVS设置的LB算法选择一个合适的realserver,然后把package 的DST IP 修改为realserver;realserver 收到这个package后判断dst ip 是自己,就处理这个package ,处理完后把这个包发送给LVS VIP;LVS 收到这个package 后把sorce ip改成VIP的IP,dst ip改成 client ip然后发送给client,由于流量进出都需要经过LVS,因此性能会受到影响
- DR
director分配请求到不同的real server, real server处理请求后直接回应给用户,这样director负载均衡器仅处理客户机与服务器一半的连接,避免了新的瓶颈,同样增加了系统的可伸缩性。Direct Routing 由于采用物理层(修改MAC地址)技术,因此所有服务都必须在一个物理网段
- IPIP
IP Tunneling 技术极大的提高了director的调度处理能力,同时也极大的提高了系统能容纳的最大节点数,可以超过100个节点。real server 可以在任何LAN或WAN上运行,这意味着允许地理上的分布,这在灾难恢复中有重大的意思,服务器必须拥有正式的IP地址用于与客户机直接通信,并且所有服务器必须支持IP隧道协议
-
调度策略
-
Round Robin
-
权重
-
less
-
加权轮询
-
加权最小
-
IP_HASH
-
配置文件
vi /etc/keepalived/keepalived.conf //配置keepalived和DR global_defs { router_id LVS_TEST #服务器名字 } vrrp_instance LVS实例名称 { state MASTER #配置主备,备用机此配置项为BACKUP interface ens33 #指定接口 virtual_router_id 51 #指定路由ID,主备必须一样 priority 101 #设置优先级,主略高于备份 advert_int 1 #设置检查时间 authentication { auth_type PASS #设置验证加密方式 auth_type 1234 #设置验证密码 } virtual_ipaddress { 192.168.1.100 } } virtual_server 192.168.1.100 80 { delay_loop 15 #健康检查时间 lb_algo rr #LVS调度算法 lb_kind DR #LVS工作模式 !persistence 60 #是否保持连接,!不保持 protocol TCP #服务采用TCP协议 real_server 192.168.1.10 80 { weight 1 #权重 TCP_CHECK { #TCP检查 connect_port 80 #检查端口80 connect_timeout 3 #超时时间3秒 nb_get_retry 3 #重试次数3次 delay_before_retry 4 #重试间隔4秒 } } real_server 192.168.1.20 80 { weight 1 TCP_CHECK { connect_port 80 connect_timeout 3 nb_get_retry 3 delay_before_retry 4 } } }复制