RabbitMQ消息应答
执行一个任务可能需要花费几秒钟,你可能会担心如果一个消费者在执行任务过程中挂掉了。一旦RabbitMQ将消息分发给了消费者,就会从内存中删除。在这种情况下,如果正在执行任务的消费者宕机,会丢失正在处理的消息和分发给这个消费者但尚未处理的消息。
但是,我们不想丢失任何任务,如果有一个消费者挂掉了,那么我们应该将分发给它的任务交付给另一个消费者去处理。
为了确保消息不会丢失,RabbitMQ支持消息应答。消费者发送一个消息应答,告诉RabbitMQ这个消息已经接收并且处理完毕了。RabbitMQ就可以删除它了。
如果一个消费者挂掉却没有发送应答,RabbitMQ会理解为这个消息没有处理完全,然后交给另一个消费者去重新处理。这样,你就可以确认即使消费者偶尔挂掉也不会丢失任何消息了。
RabbitMQ集群方案
设计集群的目的:
- 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行
- 通过增加更多的节点来扩展消息通信的吞吐量
RabbitMQ可以通过三种方法来部署分布式集群系统,分别是:cluster(集群),federation(联盟),shovel
集群通过连接多个机器组成单个逻辑中间服务器。机器之间通信要借助于Erlang的消息传输,要求集群中所有节点必须有相同的Erlang cookie;节点之间的网络必须是可靠的,且运行相同版本的RabbitMQ和Erlang。
虚拟主机、交换机、用户信息和权限会自动镜像到集群中各个节点。队列可能位于单个节点或镜像到多个节点。连接到任意节点的客户端能够看到集群中所有队列,即使该队列不位于连接节点上。通常可以使用集群来提高可靠性和吞吐量,前提是在分布同一个区域内的机器,不支持网络分段。联盟允许单台服务器上的交换机或队列接收发布到另一台服务器上交换机或队列的消息,可以是单独机器或集群。服务器之间通过AMQP协议通信,因此两个联盟交换机或联盟队列要求设置相应的用户权限。
联盟交换机之间由单向点对点链接关联,默认消息只会由联盟链接转发一次,但允许有更复杂的路由拓扑来提高转发次数。消息也可以不进行转发;如果消息到达联盟交换机之后不会路由到队列,那么它再也不会被转发。
联盟队列类似于单向点对点连接,消息会在联盟队列之间转发任意次,直到被消费者接受。
通常使用联盟来连接internet上的中间服务器,用作订阅分发消息或工作队列。shovel连接方式与联盟的连接方式类似,但它工作在更低层次。shovel接受队列上的消息,转发到另一台服务器上的交换机。
shovel和联盟类似,但它比联盟提供更多控制。
联盟/shovel vs 集群:
1)前者中间服务器逻辑分离,后者组成一个逻辑中间服务器;
2)前者可以运行不同版本RabbitMQ和Erlang,后者要求RabbitMQ和Erlang的版本保持一致;
3)前者可以分布在WAN上,采用AMQP协议通信,要求设置权限,后者必须分布在LAN上,结合Erlang内部节点通信,要求有相同的Erlang cookie;
4)前者的拓扑结构可自行设计,链接可以单向或双向,后者要求节点之间必须保持双向链接;
5)前者遵循CAP理论的可用性和分区容错性,后者遵循CAP理论的一致性和可用性(可选择一致性和分布容错性);
6)前者服务器中的交换机可以选择联盟或本地,后者孤注一掷;
7)前者客户端只能看到所连接服务器上的队列,后者客户端可以看到所有节点的队列。
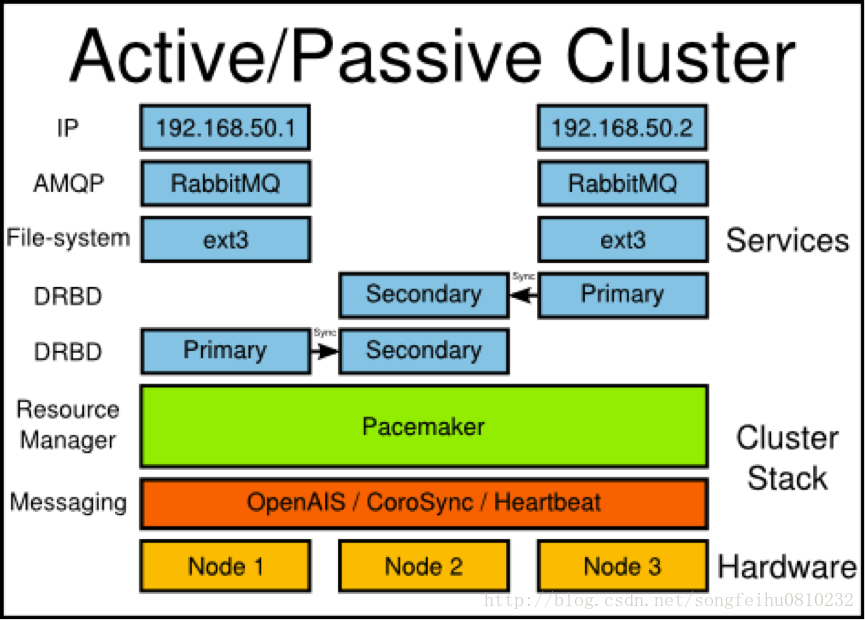
在容灾与可用性方面,RabbitMQ提供了可持久化的队列。能够在队列服务崩溃的时候,将未处理的消息持久化到磁盘上。为了避免因为发送消息到写入消息之间的延迟导致信息丢失,RabbitMQ引入了Publisher Confirm机制以确保消息被真正地写入到磁盘中。它对Cluster的支持提供了Active/Passive与Active/Active两种模式。例如,在Active/Passive模式下,一旦一个节点失败,Passive节点就会马上被激活,并迅速替代失败的Active节点,承担起消息传递的职责。
MQ选择文档

参考
http://blog.csdn.net/oMaverick1/article/details/51331004
http://blog.csdn.net/hilyoo/article/details/7704280
http://blog.csdn.net/a491857321/article/details/50670238
http://blog.csdn.net/woogeyu/article/details/51119101
http://blog.csdn.net/cool_sti/article/details/38613917