正文
摘要
最近有多个项目出现过因为序列号导致系统吞吐量上不去
性能下降的情况.
晚上想着学习总结一下, 已备忘, 避免后续继续掉坑里.
学习资料来源:
https://cdn.modb.pro/db/516085
https://www.cnblogs.com/diabloxl/p/3623640.html
复制
序列号-正版-盗版-开源-商业版
首先一般商业的闭源软件才有序列号.
开源软件一般是没有序列号的, 但是一般会有一个开源协议的生命文件.
开源协议一般大体可以分为商业友好和商业不好有.
一般学校学术派相关的开源协议比较商业友好,比如BSD还有MIT协议.
GPL或者是LGPL协议一般对商业不是很友好. 会要求必须继续开源.
开源软件背后的公司一般会有商业版的同档次开源软件出来
一般采用订阅制或者是收取服务费的商业模式(开源作者写书也是一个商业方式)
比如nginx对应F5的nginx-plus redis对应redis labs的商业版软件
或者是类似IBM的redhat rhel操作系统. 因为开源协议的要求才会开放源码制作CentOS
商业版软件一般会有更高级的特性和一定的商业代码,性能稳定性和能够支持的极限更高.
有条件还是需要上商业版的软件, 更有安全和性能保障.
比如国内的OpenEuler还有Anolis两种开源操作系统
华为和阿里都承诺不自己发行商业版, 仅维护开源版本
商业版由生态里面的比如: 统信,中科方德,银河麒麟去发行和赚取利润.
也可以他更好的支持与现场服务, 只有赚取足够的利润才可以有高级人才提供服务.
复制
序列号-正版-盗版-开源-商业版
商业软件为了最大化利润一般采用多级别序列号的方式:
一般采用:
学生(家庭版)-标准版-企业版-旗舰版(无限制)的授权级别
价格从低到高.
一般都是一套标准介质进行安装, 通过不同的序列号增加硬件或者是软件的资源限制.
因为正版软件价格昂贵(微软就是曾经开源届最大公敌)
很多时候盗版软件非常猖獗.
盗版软件其实存在非常多的风险:
1. 出现问题商业厂商不会提供服务,会要求按照名目价格购买服务并且购买到场服务才会入场维护.
2. 盗版软件可能会被认为植入木马,或者是其他恶意软件,可能会造成不必要的安全和财产风险.
3. 很多软件虽然有盗版,但是依旧可能有数据搜集上报机制,容易导致公司处于法务风险的境地.
曾经网络上一个Oracle11.2.0.4的安装介质就被人为插入安装180天后 随机删除系统表的恶意脚本.
很多不法数据库运维人员会借此高价进行维护,赚取大额利润
也有因为使用盗版软件导致自己数据库被勒索的情况发生.
所以在有可能的情况下 尽量使用官方镜像源. 尽量使用正版,不要使用来路不明的软件
安装软件时务必使用 md5 进行check 避免被人投毒.
复制
操作系统序列号- Windows为例
本次以 Windows2012为例进行说明
(家里公司里都上不去外网..之前截图过的)
复制
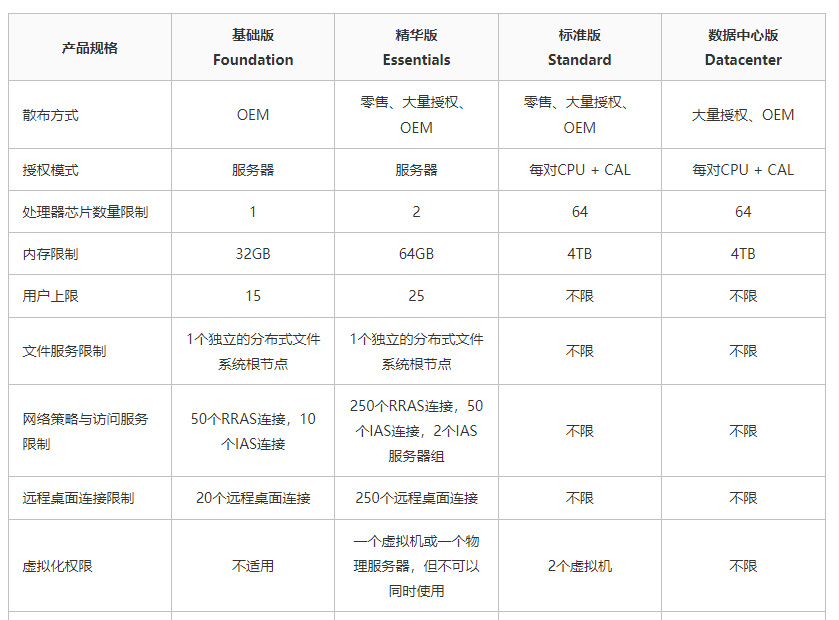
操作系统序列号
1. 不同版本的处理器芯片和内存限制是不同的.
2. 用户以及其他限制也是不一样的.
3. 越高级的版本 使用资源越多的序列号价格越昂贵.
4. 理论上一台高配置服务器,如果购买不打折的商业版系统,可能软件的授权比硬件更加昂贵.
5. 建议合理的进行授权管理, 避免资源无法正常使用. 导致资源浪费和系统瓶颈.
复制
数据库序列号
本次以SQLSERVER数据库为例说明.
其他数据库也有类似的问题:
1. SQLSERVER分为express版本,开发板,企业版,数据中心版等.
2. express 版本不收取费用,但是无法用于生产,并且数据文件大小和备份恢复都有严格限制.
3. 开发板也缺少很多核心高级的数据库特性,无法用于生产
4. 企业版和数据中心版是可以用于生产的版本
5. 但是授权模式也分为CAL版本和Core base的版本
● “每处理器”或“每内核”模式
SQL Server 2012开始,授权模式进行了调整。按“每内核”(Per Core)计数,
同时还需要计算物理处理器(插槽)的数量,单个插槽最低需要购买4个内核的授权。
这一授权模式可以很好的简化授权的复杂程度,不用统计有多少用户(或者设备)会访问 SQL Server,
以及是防火墙内部还是来自Internet的外部连接。
这种模式可以使用最多的CPU内核.
● “Server+CAL”模式
CAL 即客户端访问许可(Client Access License),分为设备访问许可(Device CAL)
和用户访问许可(User CAL)两类。SQL Server 及其组件(例如报表服务)提供服务,
即为服务端;客户端则是访问这些服务的设备或用户。
选用“Server+CAL”模式的用户,需要在服务器端采购 SQL Server 服务器许可,
并为客户端购买 CAL。每个客户端只需要一份 CAL 就可以访问本企业中数量不限的 SQL Server 实例。
CAL的模式最多可以使用 20个物理核心,或者是40个虚拟核心. 会导致性能衰退.
复制
国产数据库的序列号
不管是达梦-瀚高-人大金仓-神通
都是商业数据库, 都是需要有序列号的
建议生产环境序列号至少选用企业版, 最好不要有CPU和内存资源限制.
避免导致环境异常, 虽然有一些合同可能会包含数据库的安装采购.
但是建议这一块最好有合作伙伴进行处理.
非专业人士处理数据库非常危险.(我认为我的水平就不够专业)
我们也出现过因为序列号到期 64核心的服务器仅能够使用单核心导致严重的性能衰退和相应不及时.
另外数据库服务器大部分序列号都是基于CPU核心数进行计算, 建议使用物理机,并且建议使用高频率的CPU
避免投资浪费.
复制
关于数据库版本
刚才谈到序列号,也谈到了数据库版本.
在市场经济模式下. 虽然可以货比三家进行对照
但是终归一点, 便宜的不好, 好的不便宜. 羊毛总归处在羊身上.
谈到有客户因为sqlserverCAL序列号导致性能衰退.
也谈到有信创客户因为信创数据库的序列号导致资源利用率上不去.
其实数据库的版本也是一个很大的考量:
比如Oracle的企业版就缺少 分区表的特性.
会导致很多高级功能无法使用.
MySQL的商业版本就会带各种监控调优软件,能够极大的提高生产力.
Redis的企业版也是如此,一方面稳定,一方面也能够提高发现定位问题的能力.
基于此建议生产还是使用高版本,高配置的数据库环境.
复制
序列号引起的虚拟化与物理机的讨论
1. 数据库是非常不建议使用虚拟机的.
虚拟化的一层会导致资源损耗, 虽然有vt-x和vt-d两种特权指令可以实现直通设备
但是依旧会有一些其他损耗在里面,并且无法最大化资源使用率.
建议数据库还是使用物理机更加优秀一些.
2. 因为商业版都是绑定CPU的, 虚拟化的一层会导致CPU被其他软件抢占, 会出现类似于
超售导致的性能衰退,不利于分析分析与判断.
也是建议使用物理机, 直接使用物理机的资源,能够最大化投入产出.
复制
关于JDK,中间件,以及APM
Oracle JDK理论上要比OpenJDK要优秀很多.
虽然Adopt公司一直努力改进, 但是因为Oracle收购sun的技术专利以及商业代码
导致Adopt公司很多地方是受到Oracle的限制的.
可以参见谷歌与Oracle因为十几行Java代码导致的80多亿美元的世纪官司.
中间件也是如此, 虽然tomcat 能够实现很多场景,但是websphere和weblogic 卖这么贵肯定是有
他的金刚钻的. 开源可以做到比较好,但是需要更多的硬件和更聪明的开源大拿进行优化.
这一点可以参加当时给 王垠打3.5的赵海平的履历.
在facebook将php这种解释性语言添加类似于AOT特性, 减少一半的物理服务器的使用.
不管是电费还是设备采购和维护都带来了几十上百亿美元的效益(HipHop For PHP)
复制
总结
性能问题有非常多非常复杂的种类, 序列号与版本仅是很小并且很容易解决的一个.
其实的性能问题其实才是产品更应该尽力去解决和重视的.
而且为客户提供数字服务的公司必须视技术是第一要务的
应该能够或者至少应该有站在技术一线的能力与想法.
重视人才,减少不必要的内耗,尊重规范,尊重技术的发展与规律.
遇到问题应该得有解决问题的想法与动力.不能处处想着得与失.
如果使用开源应该真正做到反哺开源社区,共同发展与辉煌.
应该给予人才尊重与应有的待遇.
不能只看ppt只看考试只看口才的.
复制