1说明
Kubernetes使用nginx-ingress-controller代理到集群内服务的请求,nginx所在的机器上上有大量的time-wait连接。
抓包发现nginx发起的到upstream连接中只有一个请求,http头中connection字段是close,连接是被upstream主动断开的:
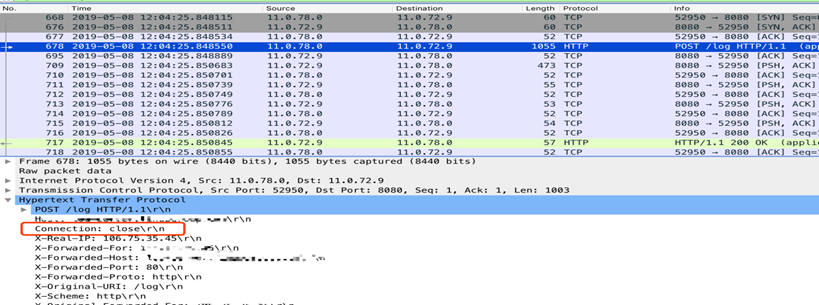
但是明明在配置中为upstream配置了keep-alive,并指定最大数量32。
2.调查
先在测试环境做个试验,摸清nginx的转发行为。
Nginx keep-alive强调需要设置http版本1.1,并且要清除Connection请求头,按要求正确配置确定keep-alive是有效的,这里不展示了。
下面主要试验一下特殊情况。(问题环境中,nginx配置文件因为别的原因没有清除Connection,upstream收到的请求头是Connection: close,所以主要关心特殊情况下的行为)
3.不配置http1.1,不清除Connection:请求端发起“Connection: close”请求
先测试一下在不配置http 1.1和不清除Connection请求头的情况下,请求端在请求头里带上“Connection: close”会怎样。
使用下面的配置文件:

$ cat /etc/nginx/conf.d/echo.com.conf
upstream echo_upstream{
server 172.16.128.126:8080;
keepalive 10;
}
server {
listen 7000 ;
listen [::]:7000 ;
server_name echo.com; # 在本地host配置域名
keepalive_requests 2000;
keepalive_timeout 60s;
location / {
proxy_pass http://echo_upstream;
# proxy_http_version 1.1; # 故意注释这两行配置,观察下行为
# proxy_set_header Connection ""; #
}
}
使用下面的压测命令:
./wrk -d 2m -c 20 -H "host: echo.com" -H "Connection: close" http://10.10.64.58:7000
在upstream端抓包,发现除了少部分报文抓取不连续的连接,其它所有连接中都只包含一次http请求:
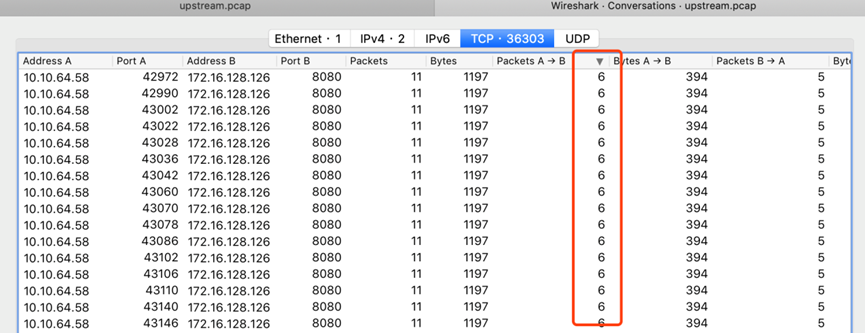
4.不配置http1.1,不清除Connection:请求端发起不带“Connection”请求
请求端发起的请求不设置Connection,nginx将使用默认的close值。使用下面的压测命令:
./wrk -d 2m -c 20 -H "host: echo.com" http://10.10.64.58:7000
压测端发出的请求是这样的:
GET / HTTP/1.1 host: echo.com Host: 10.10.64.58:7000 HTTP/1.1 200 OK Server: nginx/1.12.2 Date: Wed, 08 May 2019 09:01:26 GMT Content-Type: text/plain Content-Length: 379 Connection: keep-alive ...
而upstream端收到请求是带有close的,一个连接中只有一个请求:
GET / HTTP/1.0 Host: echo_upstream Connection: close HTTP/1.1 200 OK Date: Wed, 08 May 2019 09:08:08 GMT Content-Type: text/plain Content-Length: 379 Connection: close Server: echoserver
5.不配置http1.1,不清除Connection:请求端发起“Connection: keep-alive”请求
即使请求端设置了keep-alive,nginx转发给upstream的依然是Connection: close:
GET / HTTP/1.0 Host: echo_upstream Connection: close HTTP/1.1 200 OK Date: Wed, 08 May 2019 11:37:58 GMT Content-Type: text/plain Content-Length: 379 Connection: close Server: echoserver
6.小结
由此得出结论,如果不进行下面设置,无论请求端如何调整,nginx转发给upstream时都不会使用keep-alive:
server {
...
location /http/ {
proxy_pass http://http_backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
...
}
}
7.检查问题环境
先看一下问题环境upstream收到的报文,是HTTP/1.1,带有Connection: close,这个组合有点奇怪,是前面试验中没遇到的:
GET /js/manifest.988fecf548c158ad4ab7.js HTTP/1.1 Host: ******** Connection: close X-Real-IP: ******** ....
检查配置文件发现了问题:
...
# Retain the default nginx handling of requests without a "Connection" header
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
...
# Allow websocket connections
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
...
在配置模板文件/etc/nginx/template/nginx.tmpl中找到了这段配置的说明,这是nginx 1.3开始提供的WebSocket proxying代理功能:
{{/* Whenever nginx proxies a request without a "Connection" header, the "Connection" header is set to "close" */}}
{{/* when making the target request. This means that you cannot simply use */}}
{{/* "proxy_set_header Connection $http_connection" for WebSocket support because in this case, the */}}
{{/* "Connection" header would be set to "" whenever the original request did not have a "Connection" header, */}}
{{/* which would mean no "Connection" header would be in the target request. Since this would deviate from */}}
{{/* normal nginx behavior we have to use this approach. */}}
# Retain the default nginx handling of requests without a "Connection" header
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
上面配置的影响是:当http请求头中没有Upgrade字段时,转发给upstream的请求被设置为“Connection: close”(nginx的默认行为)。keepalive因此而无效,之所以是HTTP/1.1,是因为配置文件有这样一样配置:
proxy_http_version 1.1;
8.修改并验证
在测试环境更新nginx配置,将默认行为设置为“Connection: ““”,看一下能否解决问题。更新后的配置如下:
upstream echo_upstream{
server 172.16.128.126:8080;
keepalive 1;
}
map $http_upgrade $connection_upgrade {
default upgrade;
'' "";
}
server {
listen 7000 ;
listen [::]:7000 ;
server_name echo.com; # 在本地host配置域名
keepalive_requests 2000;
keepalive_timeout 60s;
location / {
proxy_pass http://echo_upstream;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
proxy_http_version 1.1;
# proxy_set_header Connection "";
}
}
再次测试,请求端不使用keep-alive:
./wrk -d 2m -c 20 -H "host: echo.com" -H "Connection: close" http://10.10.64.58:7000
在upstream端抓包,即使请求端不使用keep-alive,nginx转发upstream的时候还是会使用keep-alive:
GET / HTTP/1.1 Host: echo_upstream HTTP/1.1 200 OK Date: Wed, 08 May 2019 11:54:00 GMT Content-Type: text/plain Transfer-Encoding: chunked Connection: keep-alive Server: echoserver ... GET / HTTP/1.1 Host: echo_upstream HTTP/1.1 200 OK Date: Wed, 08 May 2019 11:54:00 GMT Content-Type: text/plain Transfer-Encoding: chunked Connection: keep-alive Server: echoserver
把keepalive_timeout 60s;调大,会看到请求端停止请求之后,nginx与upstream还有连接。
9.最终结论
刚开始怀疑是因历史原因修改了nginx.tmpl导致的,但是通过比对nginx-ingress-controller 0.24.0、问题环境中0.9.0以及原始的0.9.0中的nginx.tmpl,发现这是0.9.0版本中的一个bug。
0.24.0的配置模板中设置map的时候,会根据$cfg.UpstreamKeepaliveConnections的值做不同设置:
# See https://www.nginx.com/blog/websocket-nginx
map $http_upgrade $connection_upgrade {
default upgrade;
{{ if (gt $cfg.UpstreamKeepaliveConnections 0) }}
# See http://nginx.org/en/docs/http/ngx_http_upstream_module.html#keepalive
'' '';
{{ else }}
'' close;
{{ end }}
}
0.9.0中则没有考虑keepalive的因素:
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}
翻阅ChangeLog找到了这个问题的修复记录,是在0.20.0版本修复的:make upstream keepalive work for http #3098。
10.参考
- Nginx keep-alive
- NGINX Ingress Controller
- WebSocket proxying
- https://www.lijiaocn.com/%E9%97%AE%E9%A2%98/2019/05/08/nginx-ingress-keep-alive-not-work.html#目录