1.背景
首先谈一下背景环境,出现文章标题的出错是公司的tke(腾讯云k8s,当然问题和腾讯云k8s集群没有关系),首先分为dev集群环境和生产集群环境,出现问题是在很早期创建的dev环境。
问题报错以下:

注意:同时,后端upstream-host IP并不是svc的IP或者pod的IP。是一个不存在的IP。这是第二个问题。
可以看到请求已经到了ingress,但是就是无法访问后端服务。
检查了k8s的yaml配置,以及在测试pod中访问目标服务pod也可以访问,删除重新创建也是no route to host。
2.问题解决
一筹莫展之际,想到有2套环境,于是再次发布至另一套环境,果然,另一套prod环境是正常的。于是想到两个环境只有ingress的版本不同。于是去查询。 Dev的环境为0.23,而prod环境是0.30。
同时拉上腾讯的支持人员去分析,后面认为是0.23版本的bug,可能是长连接等问题,导致,即使pod不在了,连接依旧保持,并将请求转发至老的POD ip上(即使POD已经不存在),由于ingress镜像没有看tcp连接的命令,于是果断删除了ingress,然后自动拉起,问题果然解决,并且,ingress日志中的upstream-host ip也正常了。


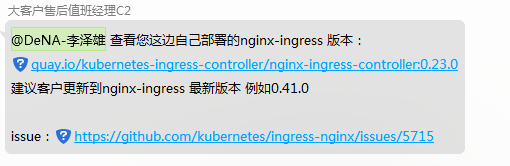
该问题运行2个月后出现,出现概率较小,但是为了避免出现问题,还是推荐使用0.30以上版本的ingerss。
3.参考
https://github.com/kubernetes/ingress-nginx/issues/5715