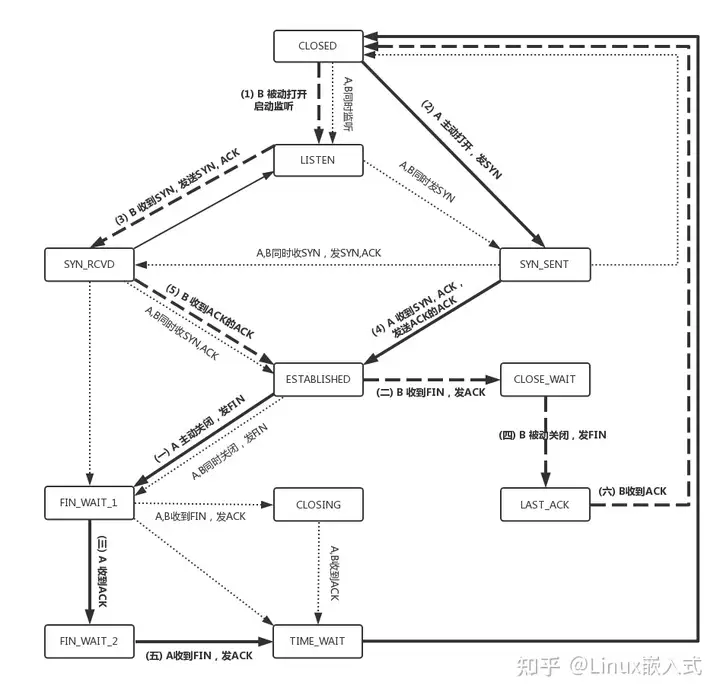
1. 什么是连接?什么情况下算建立了连接?
通过三次握手, 建立连接. 并且源和目的分配了相应资源(缓存等).
2. 什么是心跳?
建立了连接, 很长时间未发送数据包, 连接本身仍是有效的
但存在不可抗力(网线断了), 系统回收资源(超时机制)等因素, 一旦很长时间后试图通信, 连接很可能是不通的
分布式微服务即存在此问题, 为了确保连接一直有效, 隔一段时间就发送确认消息, 用来验证连通状态, 称为心跳
3. 为什么3次握手?不是2或4次?基于3次握手的攻击?
TCP 建立连接时,通过三次握手
- 能防止历史连接的建立
- 能减少双方不必要的资源开销
- 能帮助双方同步初始化序列号
不使用「两次握手」和「四次握手」的原因:
「两次握手」:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
「四次握手」:理论上客户端第三次ACK也可能丢包,也需要第四五六七次握手继续保证,但因为3次后就能发送真正的数据,则数据包就能充当第四次握手
- 例如 A 发给 B 的应答丢了,当 A 后续发送的数据到达的时候,B 可以认为这个连接已经建立,或者 B 压根就挂了,A 发送的数据,会报错,说 B 不可达,A 就知道 B 出事情了。
序列号seq能够保证数据包不重复、不丢弃和按序传输, 只增不减。
使用大量客户端向服务端发送SYN请求,但不回复服务端的ACK,致使服务端一直等待客户端的第3次握手,资源耗尽
4. 有进程号PID为什么还需要端口号?端口号最大值?
通过ip->mac找到对应主机, 但主机可能运行了很多相同的程序, 每个相同的程序都有不同PID, 或主机重启 导致PID变化
所以固定程序的端口号, 仍能以socket区分不同的连接端点,, 直到最大值65535
比如10w人连接服务器上的redis,所有redis共享一个固定端口,服务器端socket固定;但客户端ip不相同,因此socket不同,能区分不同的客户
5. Socket
一端ip+port 与 另一端ip+port四元组
每一个连接的四元组一定不同
6. 为什么要4次分手? || 3次行吗?第2次和第3次合并行吗? || 不要第4次行吗?等2MSL原因?
从4,5考虑, 端口号存在上界, 不释放端口资源会耗尽, 导致连接无法再建立
- 不使用「三次分手」{第2次和第3次合并不行}的原因:
client提出fin请求, server确认收到, 还需要关闭自己的资源, server确认资源已关闭后, 像client一样提出fin
(1) 当客户端发出最后的ACK确认报文时,并不能确定服务器端能够收到该段报文。最差情况下,第四次握手的ACK在即将到达服务端时丢包了(1MSL),B会超时重传第三次握手FIN(1MSL)
- 所以客户端在发送完ACK确认报文之后,会设置一个时长为2MSL的计时器。
MSL指的是Maximum Segment Lifetime:一段TCP报文在传输过程中的最大生命周期。2MSL即是服务器端发出为FIN报文和客户端发出的ACK确认报文所能保持有效的最大时长。服务器端在1MSL内没有收到客户端发出的ACK确认报文,就会再次向客户端发出FIN报文
server提出fin以后, 这个fin可能丢失, 如果丢失, client无法确认server是否已经关闭资源, 那么server需要重新发送fin
(2) 另一个问题是,假如客户端不等2MSL,发完第四次直接关闭连接,那么端口就空出来了。但服务端并不知道,有可能之前发给客户端该端口的包阻塞恢复了。如果恰好另一个连接占用了这个端口,那么会出现混乱。等2MSL可以额外保证阻塞包都TTL了
- 第四次ACK发生了丢失,客户端等2MSL,服务端重传FIN。假如这个重传的FIN也丢了怎么办?
客户端已关闭或建立新连接,会直接返回RST
7. 解释从一个局域网某节点A访问另一局域网某节点B的过程
节点A通过DNS解析到节点B的ip地址, 形成包[[ipA:ipB] + 路由器网卡A的mac地址], 传输过程中, [ipA:ipB]作为源和目的节点的标识, 保持不变.
mac地址一直被替换为下一跳的节点, 如果链路表中没有对应ip:mac地址映射, 则广播找下一跳并进行添加,否则直接定点
8. 单臂路由
同一交换机下接不同网段的节点,节点间属于不同局域网,无法直接通信,需要路由器充当网关
可以使用一个路由器接在交换机上,充当任意一个节点到另一个节点的网关,需要在路由器内创建虚拟网卡
9. 为什么OSI TCP/IP协议要分层?
高内聚,低耦合。每层只内聚干自己的专业,留下规范的接口给别层调用,接口的实现可用任意具体协议。
10. 有了ip为什么还要mac?
- 私有ip地址可变,mac全球唯一
- 公有ip地址唯一,但根据网络协议栈,必须要装mac头,ip包才能发出去,即只要是在网络上跑的包,都是完整的。可以有下层没上层,绝对不可能有上层没下层。
- 职责分离:ip负责大区定位,mac负责小区寻址
11. 有了mac为什么还要ip?
- 职责分离:ip负责大区寻址,mac负责小区寻址
- 假如不要ip,丧失大区定位能力,每个网关的mac表需记录所有其他节点的mac,会过于庞大
12. linux查看ip地址?
ifconfig, ip addr
13. http请求在传输时会拆包装包吗?
不会,类似数据库逻辑删除思想,实际上使用游标定位,游标扫过的部分表示已经拆过的XX头
14. ip头结构里的优先级字段有什么用?
- 当很多ip包共用一个网口时,需要排队,其中有些排队规则qdisc需要用到优先级,比如pfifo_fast将不同优先级分成三段,段内再使用fifo
- 业务场景:会员/超级用户
15. 假如本地ip位于192.168.1.x范围,本地某台机器将ip设置为16.158.23.6,那么当该机器ping本地其他机器时会发生什么?
- 通信定位需要ip + mac
- 当目标ip和源ip位于同一网段,则认为是内网通信,通过ARP协议/广播返回目标mac;如果不同,则认为要访问外网,直接将包加上网关的mac送到网关,再从网关广播回本地目标地址[多一跳,南辕北辙]
16. DHCP哪一层?原理(4次握手)?
- 应用层,基于UDP封装的BOOTP协议
- 网络协议栈是自洽的!!所有协议的实现方式也是遵守网络协议发包

- 类似线程壳复用的线程池,DHCP Server维护一个ip地址池,当有新机器(只有MAC无IP)访问到Server时,就为其分配一个ip
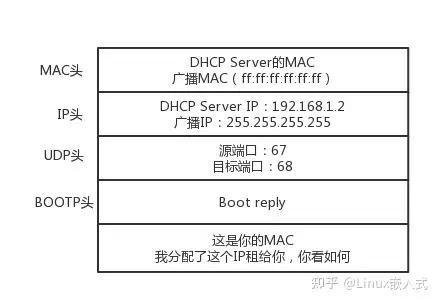
- 由于新机器在租赁ip期间IP地址还未确定,因此其与Server通过广播通信,对于其他已经有ip的机器,会忽略这些信息
- 假如同时有多台Server为其分配,则接受最先到达的

- 最终,Server广播授权信息给新机器,使其生效,并通知网关更新ARP路由表,将新机器的ip+mac加入

17. PXE协议
基于UDP
当面对数百台新机器需要配ip和装OS时,DHCP可以附加配置中心的地址,让新机器访问配置中心拉取OS安装文件,自动安装OS

18. MAC包格式
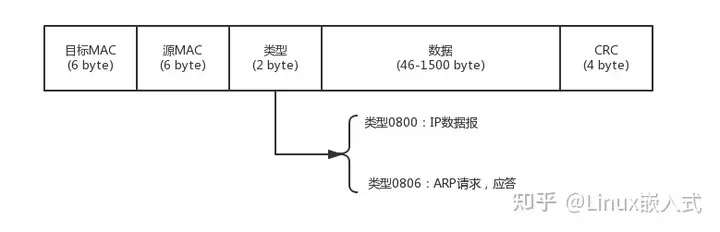
- 如果类型是0800,则数据是TCP/UDP包装的HTTP/DHCP等协议内容
- 如果类型是0806,表明目标机器的mac未知,正在使用ARP协议通过广播的方式获取目标机器mac


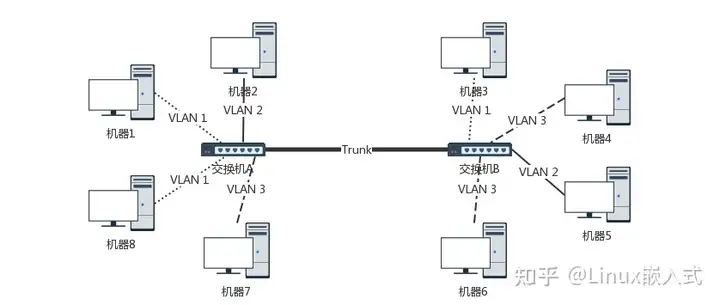
19. 集线器 vs 交换机
- 集线器是一层设备,所以没有链路功能,只能通过广播的方式将所有请求轮询找目标
- 交换机是二层设备,具有链路功能,会在本地保留转发表,转发表刚开始空白,一旦通过ARP协议广播建立连接就将源和目的MAC缓存,以后就直接走缓存
- 交换机的环路问题:在ARP广播时,两台交换机之间可能无限广播,最终占满带宽
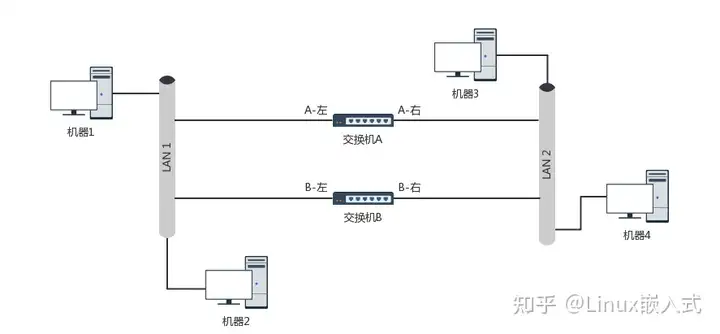
- STP 协议:用最小生成树组织交换机,一定不会有环
- 当接入最小生成树的机器过多,新加入机器的初始ARP广播也会成为瓶颈,这需要隔离子网
- VLAN逻辑隔离:在MAC头添加tag字段,表示所属的虚拟子网赛道,只有同赛道内部允许广播

20. ICMP
ICMP协议工作在网络层,作为轻量级包,探测网络的拥堵情况

- 查询报文,主动发出请求,查看丢包率和延时RTT,如ping

- 差错报文,被动接收网络故障。当到达TTL最大hop数,这个包就会在自毁前发送ICMP
- 用二分法ping出故障节点,tcpdump -i eth0 icmp
- traceroute嗅探:设置TTL做网络拓扑结构BFS,设置不分片检测链路最小MTU。原理都是发送特殊的ICMP报文
21. MAC报文和IPv4报文

- 原则:越靠近协议栈底层,传输时拆装可能性越大,对应头部应越简洁
- MAC头只需
- 6字节源MAC
- 6字节目的MAC
- 2字节协议类型(描述MAC包封装的上层数据功能,如普通IP请求/ARP请求)
- MTU长度的上层数据
- IPv4头需要
- 4位版本(4/6)
- 4位首部长度
- 8位服务类型(3波段,普通用户/超级用户/黄金用户,排队时分优先级)
- 总长度
- 标识
- 标志
- 片位移
- TTL生存时间
- 协议类型(描述IP报文封装的上层数据功能,如TCP/UDP)
- 校验和
- 源IP
- 目的IP
- pad
- 上层数据
22. 静态路由 vs 动态路由
- 静态路由提前在每个网关人工配置好路由表,收到报文后先对网关mac与报文的目的mac是否相符,然后根据目的ip查路由表的网段,决定下一跳ip和出口网卡,最后通过ARP协议获得下一跳的mac,并更新为报文的目的mac
- 转发网关要求路径上所有节点都有公网ip,整个过程报头的ip不变,源目的mac改变
- 通过ip route add命令配置路由表
- NAT网关允许路径上具有私网ip,这样就有可能出现报头中源目的IP相同,因此引入NAT端口映射,使用 公网ip + 映射端口 作为私网内部身份,整个过程报头的ip,mac,port都改变
- 动态路由根据路由协议算法动态生成路由表,总是找节点间的最短距离
- BGP协议 基于TCP基于bellman-ford, 从所有邻居反馈里挑最小值 + 本节点到邻居的延时作为距离
- OSPF协议 基于UDP基于dijkstra, 每个节点只将到邻居的延时广播, 每个节点收到广播后组图用dijkstra
- 如果发现存在多条最短路径, 可将其用作负载均衡
23. TCP vs UDP
- TCP是有状态服务,通过数据结构维护一定网络状态信息,做到可靠传输,超时重传,拥塞控制,有序传输等治理能力
- TCP/IP也是基于IP的,对于 TCP 来讲,IP 传输层丢不丢包,我管不着,但是在我的网络层上,会努力保证可靠性
- 因为建立连接很费力,所以一旦确定建好,就可以使用字节流的方式加快传输

- TCP的治理能力体现在包头的哪些字段?
- 可靠传输,握手挥手,超时重传:状态位 + 确认序号
- 有序传输:32位序号,每4µs加一,重复需要4小时,超过包的TTL,因此保证有序
- 流量控制:窗口大小。假如服务端一直不确认接收。那么服务端反馈给客户端的TCP包里,窗口大小会减少,则客户端就不能扩大未发送可发送区间。当未发可发区间缩减到0,客户端停止发送。

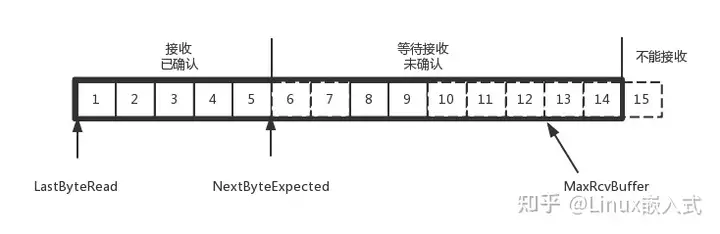
- 拥塞控制:窗口大小。
- 慢启动:每当收到一个确认,cwnd可发送窗口大小就++,这使得cwnd成指数增长
- 当cwnd达到阈值ssthresh ,每收到一个确认,cwnd+=(1/cwnd),这使得cwnd成线性增长
- 慢恢复:当线性增长到出现丢包,表示出现拥塞,将ssthresh置为cwnd/2, 将cwnd重置为1,接着使用指数增长
- 快恢复:将cwnd/2, 然后sshthresh置为cwnd, 接着使用线性增长

- UDP是无状态服务,相当于工作在四层的IP协议,轻量不维护网络状态,因此也不具备治理能力
- TCP相当于严格遵守独家的治理协议,而UDP把治理能力的实现留给了应用层(比如基于QUIC协议的HTTP3)
- 比如网络环境不良时可以选择性丢帧,尽量让用户无感知
- 比如不保证加载顺序,同一个页面多次刷新,先加载文字还是先加载图片无所谓
- 很多时候,实时性强的场景都会基于UDP实现自己的治理能力,比如组队游戏,直播等
- 高速移动场景,比如移动互联网,如果用TCP可能还没建立好连接就在地理上移动到别的区域了,因此也基于UDP
24. HTTP1.0/1.1
- 先DNS解析ip,然后tcp握手建立连接,然后通信
- HTTP 协议是基于 TCP 协议的,所以它使用面向连接的方式发送请求,通过 stream 二进制流的方式传给对方。当然,到了 TCP 层,它会把二进制流变成一个的报文段发送给服务器。
- 在发送给每个报文段的时候,都需要对方有一个回应 ACK,来保证报文可靠地到达了对方。如果没有回应,那么 TCP 这一层会进行重新传输,直到可以到达。同一个包有可能被传了好多次,但是 HTTP 这一层不需要知道这一点,因为是 TCP 这一层在埋头苦干。
- TCP 层发送每一个报文的时候,都需要加上自己的地址(即源地址)和它想要去的地方(即目标地址),将这两个信息放到 IP 头里面,交给 IP 层进行传输。
- IP 层需要查看目标地址和自己是否是在同一个局域网。如果是,就发送 ARP 协议来请求这个目标地址对应的 MAC 地址,然后将源 MAC 和目标 MAC 放入 MAC 头,发送出去即可;如果不在同一个局域网,就需要发送到网关,还要需要发送 ARP 协议,来获取网关的 MAC 地址,然后将源 MAC 和网关 MAC 放入 MAC 头,发送出去。
- 网关收到包发现 MAC 符合,取出目标 IP 地址,根据路由协议找到下一跳的路由器,获取下一跳路由器的 MAC 地址,将包发给下一跳路由器。
- 这样路由器一跳一跳终于到达目标的局域网。这个时候,最后一跳的路由器能够发现,目标地址就在自己的某一个出口的局域网上。于是,在这个局域网上发送 ARP,获得这个目标地址的 MAC 地址,将包发出去。
- 目标的机器发现 MAC 地址符合,就将包收起来;发现 IP 地址符合,根据 IP 头中协议项,知道自己上一层是 TCP 协议,于是解析 TCP 的头,里面有序列号,需要看一看这个序列包是不是我要的,如果是就放入缓存中然后返回一个 ACK,如果不是就丢弃。
- TCP 头里面还有端口号,HTTP 的服务器正在监听这个端口号。于是,目标机器自然知道是 HTTP 服务器这个进程想要这个包,于是将包发给 HTTP 服务器。HTTP 服务器的进程看到,原来这个请求是要访问一个网页,于是就把这个网页发给客户端。
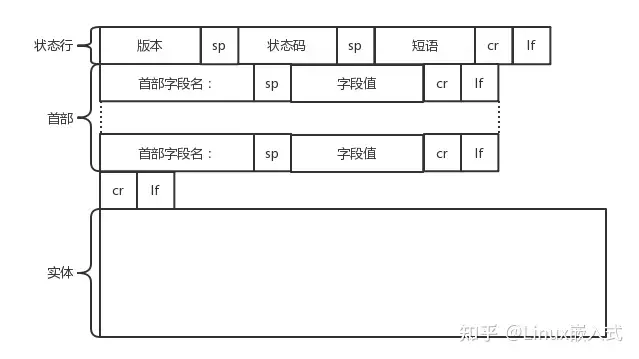
- request报文
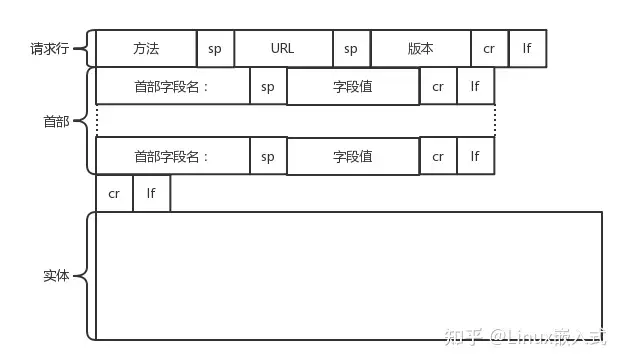
- 请求行 = 方法(GET/POST/PUT/DELETE) + URL + VERSION(1.0/1.1/2/3)
- 首部 = kv[], 规定accept-charset(utf-8), content-type(json), content-length, cache-control
- response报文
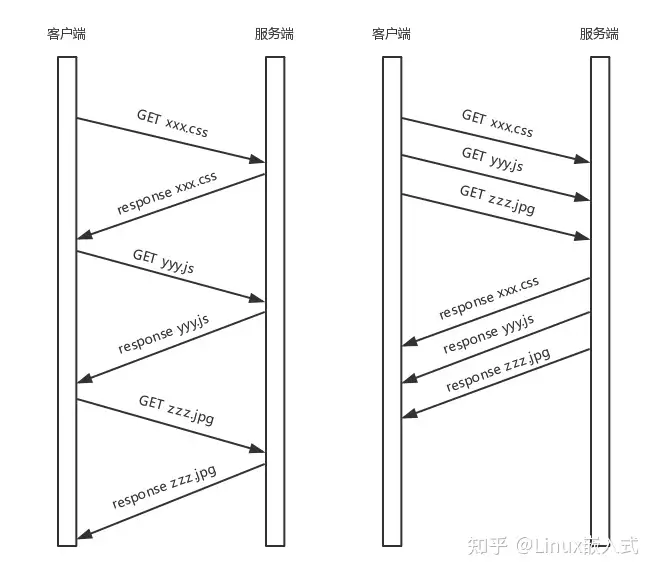
25. HTTP2.0 vs HTTP1.x vs HTTP3.0
- 队首阻塞:HTTP1.x串行化传输,如果首个请求解析很慢(比如大图片),则之后所有的都阻塞
- 多路复用:HTTP2.0将多个请求打标签(流),然后mesh成帧,将这些帧视为一次串行化请求,只需要建立一次连接,并且解析帧的速度非常快
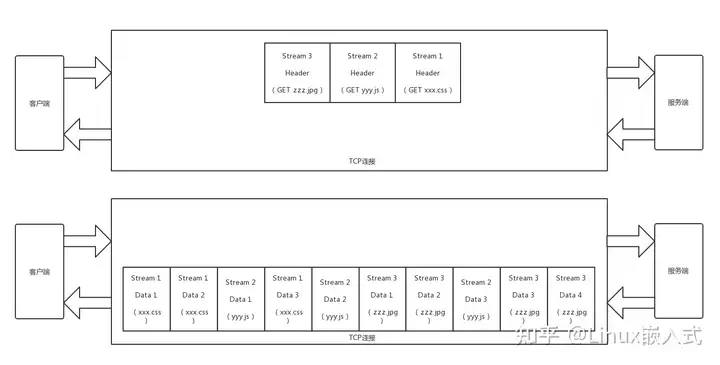
- HTTP2.0仍然基于TCP,TCP要强制保证有序可靠,因此如果某帧丢包等待TCP重传,仍然可能阻塞后续帧
- HTTP3.0放弃TCP的严格机制,自定义基于UDP的QUIC保证治理能力,流之间彻底解耦并发不会阻塞,流内部仍然可能阻塞