https://zhuanlan.zhihu.com/p/65840506复制
上一篇文章我们从整体上介绍了电脑的各个部件以及功能,CPU可以说是整台电脑中最核心的部件。这篇文章里面,给大家介绍一下CPU里面都有什么。
我们家里用的电脑,CPU只有两家厂商在生产:Intel和AMD。每家厂商都提供很多型号的CPU,这篇文章以Intel生产的,主流市场上的旗舰型号:Core i9-9900K为例子来介绍。
还是先看图[1]:

9900K大概可以分为5个部分:
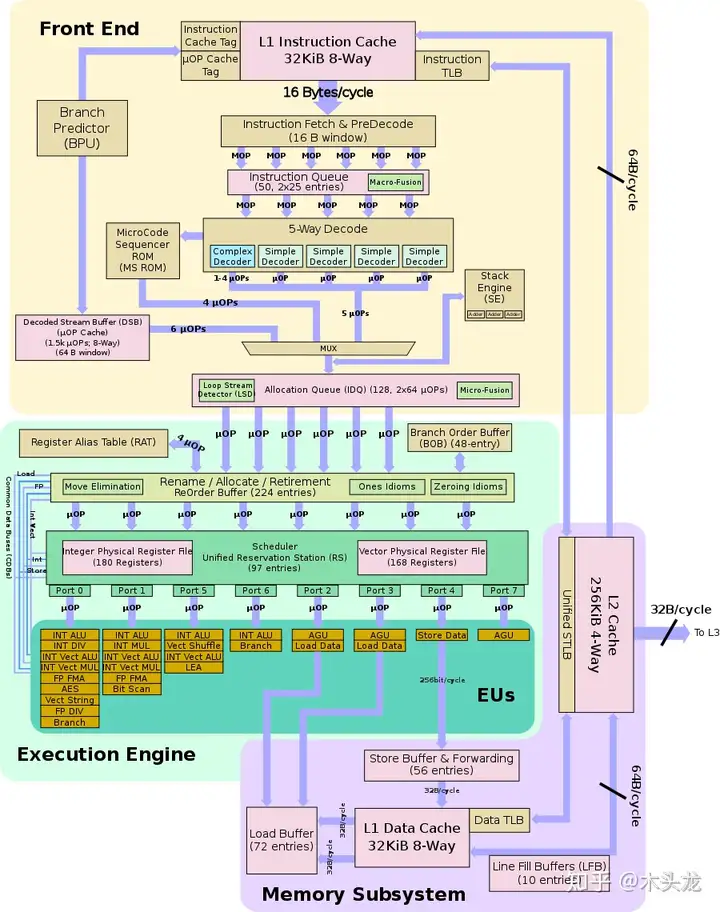
这张图看起来很复杂是不是?不用担心,我们一个一个说。当然,我们这是入门知识,不会介绍的太细。
我们上一篇文章提到,现代CPU都是改进型哈弗架构;并且举了一个会计做财务报告的例子。这里我们继续使用这个例子来介绍。但之前,我们稍微改一下做财务报告的方式,不是一个人全部做完,我们是一个团队。有的同事根据制作指南列计算步骤,有的同事根据计算步骤在小纸条上列公式,有的同事负责从账本上把数据抄到写好公式的小纸条上,有的同事对着小纸条用计算器算数并且算完了写回小纸条上,有的同事把小纸条上的数抄到最终的财务报表上。CPU里面,小纸条有一个专门的名称,叫寄存器(Register)。
一家规模比较大点的企业,完整的账本很厚。我们做整年的财务报告,通常只需要每个科目的汇总数就可以了,为了方便,我们把每个科目汇总的那几页复印出来放在一起。
完整的财务报告制作指南也很厚,但一个企业可能只有其中很少一部业务。例如一家软件公司,就不涉及原材料进货、仓库存储之类的业务;很多公司也没有贷款、投资之类的业务。所以我们也只把跟公司有相关业务的部分复印出来。
同样的,内存中的数据很多,CPU只需要把计算用到的指令、数据放到缓存中——也就是图中的紫色块的缓存子系统。
CPU的前端其实就是我们上篇文章中的控制单元,负责对指令进行预处理。指令预处理大体上分为取指、预解码、融合、解码、分支预测、重排等操作。
取指(Fetch)
我们制作财务报表,第一步就是把制作指南拿出来。CPU也一样,先把指令载入进来。
预解码(PreDecode)
制作指南是一整页的,我们要分解出第一步算哪个数据,第二步又是算哪个数据,在小纸条上把公式列出来,一张小纸条一个公式。CPU也一样,要把程序中一整批的指令数据,拆分出来第一条是什么指令,第二条是什么指令;可能还需要对指令进行分类标志。预解码后的指令放在指令队列(Instruction Queue)里面。
解码(Decode),又称为译码
小纸条上的公式写着:利润=收入-支出,查帐本的同事就需要先把收入和支出数据从账本中找出来,抄到小纸条上。同样的,CPU碰到类似把内存中两个数加起来这样的指令,需要分解成:
这样三个指令。一般来说,我们把原始的指令称为宏操作(Macro-Operations),分解后的指令称为微操作(Micro-Operations, μops)。
指令融合(Micro-Fusion/Macro-Fusion)
假设指南中有一个数据是算平均数的,某个按计算器的同事手上整好有一个可以直接算平均数的统计用计算器。那么,当我们在指南中看到一条类似 (�1+�2+�3+...+��)÷� 这样的公式的时候,我们可以直接列算这几个数的平均数公式,注明给这位同事算。CPU也一样,某些指令是可以融合起来执行的,例如:
可以用一条指令JNE A,B,X来代替,这样的处理称之为指令融合。指令解码前的宏操作融合,称为Macro-Fusion,解码后的微操作融合,称为Micro-Fusion。
分支预测(Branch Prediction)
理论上,制作指南中列出的所有步骤,我们都要完成上面的这些处理。但假设制作指南中说,盈利的话要算某几个数据,亏损的话这几个数不用算,要另外算其它几个数据。当我们计算过第一季度的数据知道企业第一季度是盈利的,我们算第二季度的数据时,想偷懒就直接跳过亏损要算的那几个数据的处理了。CPU处理指令也是一样的,负责预测的模块叫分支预测器(Branch Predictor)
当然,如果算下来我们发现第二季度亏损了,还是要重新处理指南上的这些计算步骤。CPU也一样。
指令重排,或者叫乱序执行(Out-Of-Order,OOO),或者动态执行(Dynamic Execution)
事实上,我们不一定要完全按照指南上的步骤第一步算什么,第二步算什么这样算。只要公式列出来,数据抄出来了,就可以直接交给按计算器的同事去算。所以可能第一步要用的数据不太好找,按计算器的同事就先把第二步算出来了。
当然,这里有一个前提,就是算第二步的时候,不需要用到第一步的计算结果。
执行单元也就是上一篇文章提到的运算单元了。也就是我们这个团队里抄数据、按计算器的各位同事了。其中,按计算器的同事中,有的用的计算器简单点,只能做四则计算,还只能算整数;有的用高级点的计算器,可以算小数;有的用统计专用的计算器;有的用更高级的可以算很多函数的计算器。当然,有这么多不同的计算器,什么样的小纸条给哪位同事用,我们也需要有一个人来做分配小纸条这件事情。
数据存取单元(Load Data/Store Data)
CPU里面也一样,有负责从缓存子系统中载入数据的Load Data单元;有把计算结果写回去缓存子系统的Store Data单元。
计算单元
CPU里面负责具体计算的,根据计算类型、计算的数据不同,有多种计算单元:
调度器(Scheduler)
有这么多不同的计算单元,CPU需要一个把不同的计算指令分配给对应计算单元的调度器。
不过呢,我们这个财务部比较特殊,分了几个小办公室,某几个同事在一个办公室里面,另外几个同事又在另一个办公室里面,而每次我们只能传一张小纸条到一个办公室。
在9900K里面,从图中可以看到,不同的计算单元在不同的端口(Port)下,就是类似的情况。
寄存器文件(Register File)
计算财务数据的时候,很多数据的计算是需要多步计算的,具体到每一步的计算,可能要分给不同的同事来算。如果每一步列一张小纸条,等某位同事算完第一个数,再抄到第二张小纸条给另外一位同事,这显然很慢很麻烦——直接列在一张小纸条上就好了嘛。
另外,我们有这么多同事,分配小纸条的同事每次传小纸条可以一次分配好多张——当然,前提是分给不同的同事。
因为可能一张纸条要算好几次,又有这么多纸条传来传去,因此为了不出错,我们需要标明这张小纸条给谁算,算完了,负责分配小纸条的同事根据下一步要算的,把标注的名字改一下给另外一位同事去算。
CPU中的寄存器也一样,一个数据可能需要不同的计算单元多次处理,又有那么多的计算单元分成了好几组。所以我们需要多个寄存器,这些寄存器的组合称之为寄存器文件。每个计算单元只能处理特定名称的寄存器里面的数据,因此调度器经常需要对寄存器进行分配、重命名、退出等操作。