https://www.cnblogs.com/charlieroro/p/16294734.html复制
本文介绍了一种容量推荐模型,实现方式相对相对比较简单,且已在Uber内部使用,可以依照文中的方式开发一版容量推荐系统。
译自:Capacity Recommendation Engine: Throughput and Utilization Based Predictive Scaling
容量是服务可靠性的关键部分。为了支持不同的业务单元,Uber的服务需要足够的资源来处理每天的峰值流量。这些服务部署在不同的云平台和数据中心上。手动管理容量通常会导致过度分配资源,导致资源利用率低下。Uber构建了一个自动扩缩容服务,用于管理和调节上千个微服务的资源。目前的自动扩缩容服务单纯基于资源利用率指标实现的。最近我们构建了一个新的系统,称为容量推荐引擎(Capacity Recommendation Engine (CRE)),新的算法结合了吞吐量和利用率,并使用机器学习模型来实现扩缩容。该模型提供了黄金指标和服务容量之间的对应关系。通过反应性预测,CRE可以基于线性回归模型和峰值流量估算出区域服务的容量。除了容量,分析报告还可以告诉我们不同区域服务的特性和性能回归。本文将会深入介绍CRE模型以及系统架构,并提供该模型的一些分析结果。
在容量管理方面,利用率(utilization)是最常用的扩缩容指标。在CRE中,除了利用率,还使用吞吐量(throughput)作为另一个容量评估的重要指标。吞吐量代表了业务产品需求。在服务层面,可以转换为每个实例的RPS(每秒请求数)。每当推出新产品以及变更依赖的扇出模式时,都会直接导致服务吞吐量的变化,从而影响容量需求。我们的目标是获取满足利用率需求的服务容量或实例数。我们将实例的CPU core乘以实例数,得到服务所需的总CPU core数。通过将资源分配引入预测模型,就可以将指标与服务容量关联起来。CRE使用吞吐量和资源分配时序数据来构造线性回归模型。
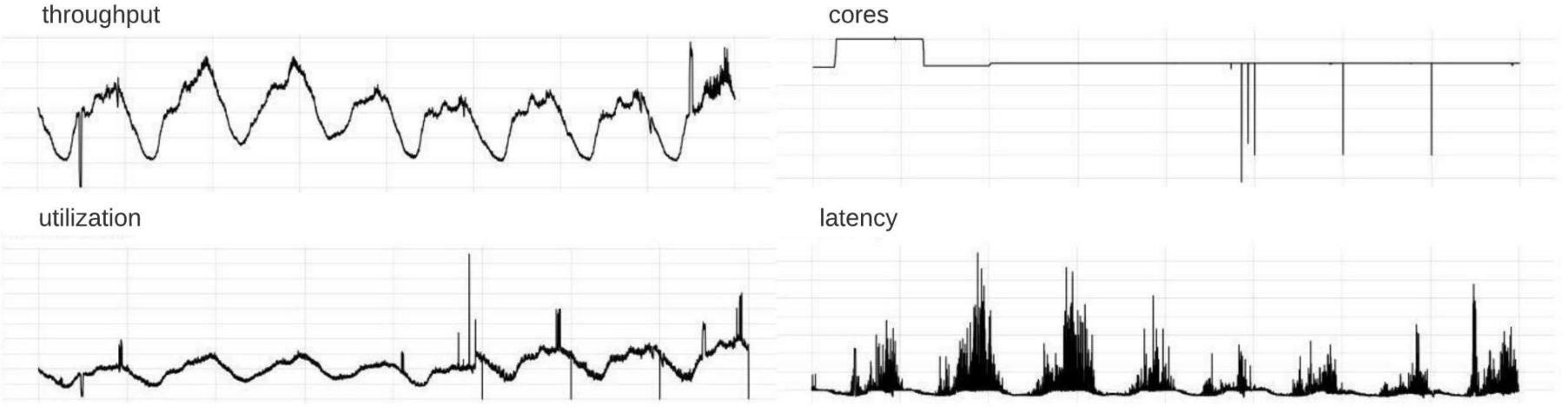
图1:CRE使用的黄金指标
Uber使用了多家云厂商,每家厂商都有不同的网络栈、硬件类型和流量模型。我们将每个区域作为独立的扩缩容目标,通过单独进行线性回归分析来考虑不同环境下的差异。从结果中可以看出各自的性能差异,并进一步影响缩放组中的容量。
CRE的推荐流程包括如下步骤:
CRE使用峰值吞吐量和目标利用率,以及步骤3生成的指标关系来计算容量实例数。每个步骤都对最终的推荐容量和服务可靠性至关重要。下面将深入了解一下各个步骤。
由于扩缩容的频率不同(小时、天、周),其需要评估的吞吐量也不同。
例如按周来评估吞吐量:将目标吞吐量 RPSTarget作为下一周评估的峰值流量。CRE使用的默认吞吐量评估方式为时序分解模型。使用基于STL的时序分解方式将全局吞吐量时序数据分为趋势(trend)、季节性(seasonality)和其他(residue)三部分。这三部分之和表示了原始全局吞吐量指标。seasonality表示一个频率模式,trend表示跨天的模式。下例以天作为seasonality,展示了美国/拉丁美洲的上下班的峰值。residue 为不匹配trend或seasonality的剩余原始指标,通常表示噪音。使用时序分解结果,CRE可以为大多数服务提供可靠的预测。
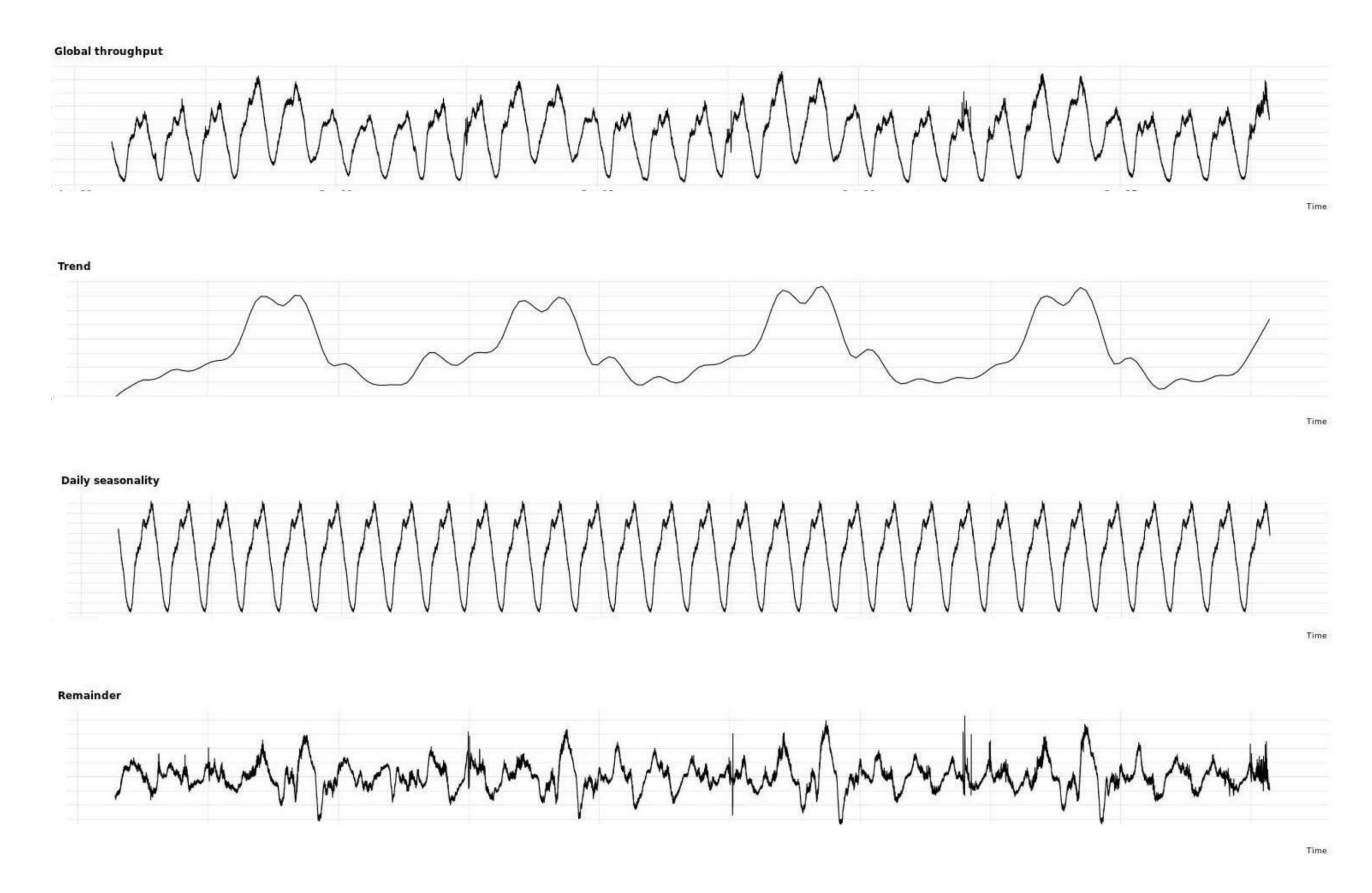
图2吞吐量分解结果
目标利用率(UtilizationTarget)是CRE中用来推导容量数值的一个信号。该信号描述了未来服务资源的最大利用率。为了有效利用资源,应该尽量提高利用率,以便为未预测到的情况预留一部分缓冲余地。正常情况下,每天的流量不会超过目标利用率。目标利用率应该包括某些特殊场景,如区域下线,此时该区域的流量会转移到其他区域,此时由于流量的上升,利用率也会随之上升。
对于资源密集型的服务,利用率、吞吐量、容量、服务以及硬件性能都是常见的关联因子,且相互影响。一旦其中一个因子发生了变化,通常也会影响到其他因子。由于我们的目标是评估服务容量,因此需要确定这些信号之间的关系。CRE使用利用率和归一化吞吐量来构建一个线性回归模型。通过将吞吐量除以实例核数,可以得出归一化吞吐量--称之为每核吞吐量(TPC)。通过归一化吞吐量指标,我们可以将相关因子范围缩小到利用率和TPC。通过线性回归结果展示的斜率和截距可以观察到性能变化曲线。下面是利用率和TPC的关系公式:
通过去除异常值和归一化,对数据进行预处理。如果由于控制面问题,指标源提供了明显异常的数据点,则需要在处理过程中移除这些数据。可以使用交叉验证来提高模型质量。当可以通过线性回归模型复现数据时,将会体现为调整后的判定系数(与结果质量相对应的测量值,数值越大,拟合度越高)。
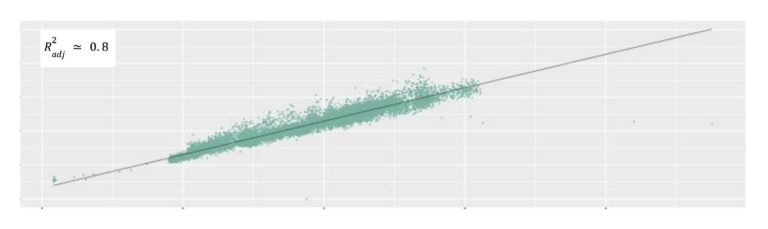
图3:利用率 vs 每核吞吐量
在图4中可以看到评估的线性关系并不能代表指标关系,相反可以将数据点近似分为两个不同的线性关系组。出现这种现象很可能是因为服务多样化以及/或硬件性能的变化引起的。
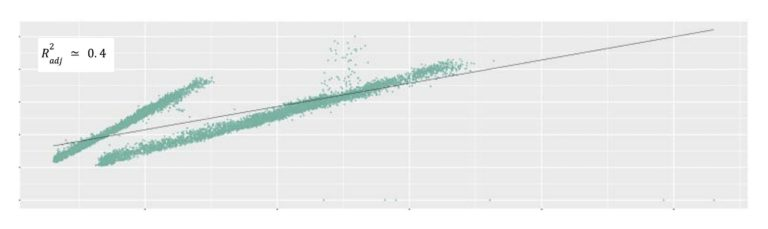
图4:利用率 vs 每核吞吐量
有了利用率和TPC线性关系方程,一旦提供了目标利用率,就可以计算出目标TPC。例如,假设将目标利用率设置为0.7,在图5中,目标TPC 趋势相对比较稳定合理,我们还可以从TPC中推断出各区域基础设施之间的差异。特别地,相比其他区域,zoneF地目标TPC比较小,原因可能是底层基础设施和硬件的性能比较好。此外从图中可以看出,各区域的曲线有下降趋势。服务的性能下降也可以成为未来考察的一种可能因子。
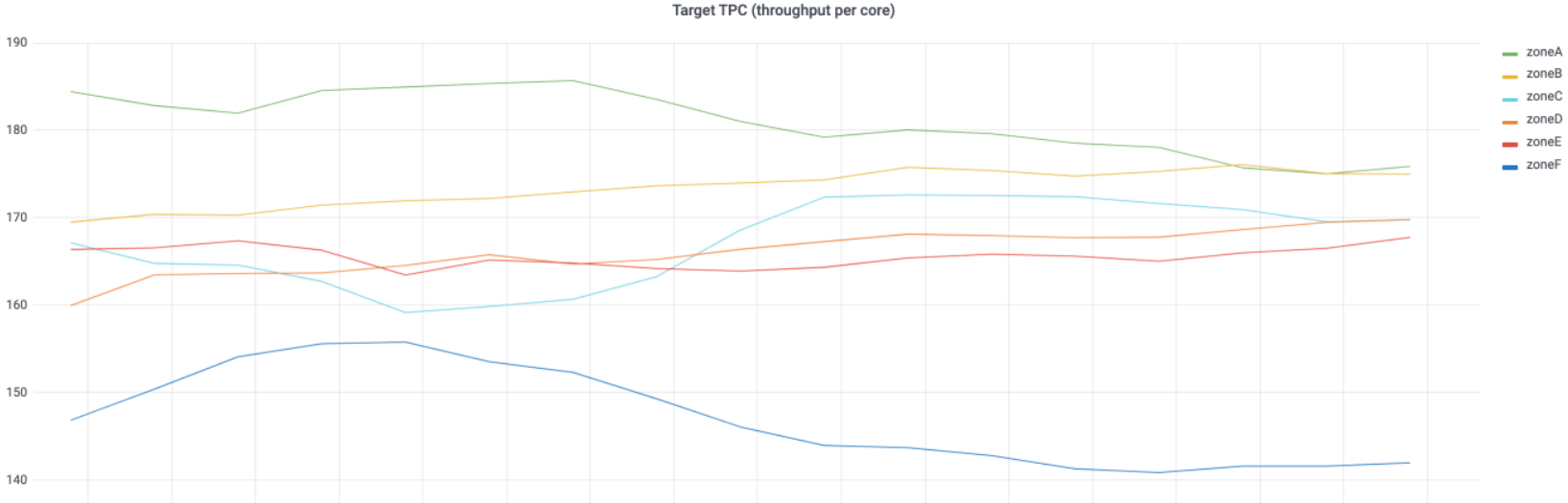
图5:服务的目标TPC趋势
使用线性回归的结果𝛼(利用率)和𝛽(斜率),以及预定义的目标利用率和评估到的峰值流量,我们可以计算出服务所需的核数,即容量。
变量定义:
TPCTarget: 目标每核吞吐量(TPC)
RPSTarget: 峰值流量评估阶段提供的目标RPS
UtilizationTarget: 定义的目标利用率
CoresTotal: 服务所需的总核数
CoresInstance: 每个实例所需的核数
公式:
基于线性回归模型,将Utilization 和 TPC更新到目标值
变量定义:
通过公式(1)和(2),可以得出:
在获取到所需的总核数后,就可以得出每个实例所需的核数。最后获取到推荐的容量实例数。
在生成推荐的容量数据后,为了安全地滚动变更,我们引入了护栏来在自动扩缩容前对结果进行检测。该步骤可以保证自动扩缩容的质量和服务的可靠性。例如,使用护栏来对比当前容量和推荐结果,通过预定义的百分比阈值,如果推荐值超过了当前的容量百分比,则护栏会处理该数据并调整对应的推荐结果。还有其他类似的护栏,如保障模型性能质量的护栏,在扩缩容结束之后,它会在报告中为工程师提供一个告警消息,便于检查后续的数据。
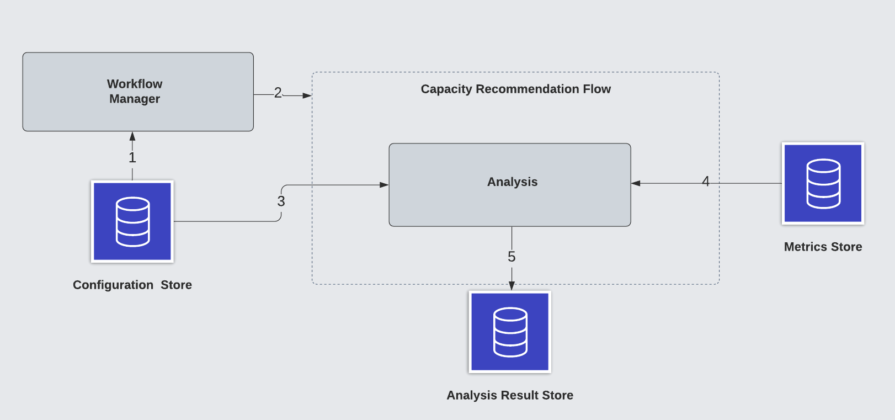
图6:调度流
典型的调度容量推荐流包括以下步骤:
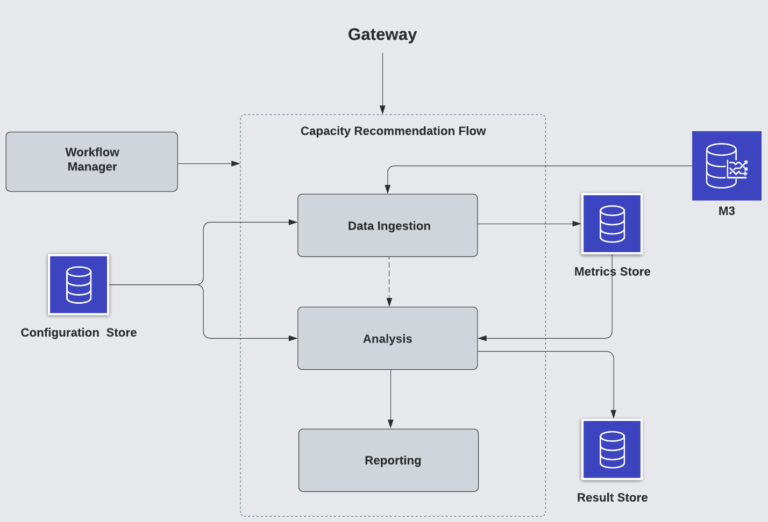
图7:按需流
如果服务所有者希望临时生成容量建议,可以使用按需容量推荐流。
按需容量推荐分析流与调度流类似,区别是:
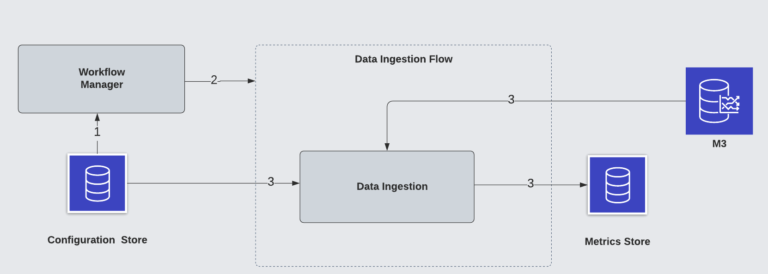
图8:数据采集流
专用数据采集流会基于配置来采集和存储关键服务的原始指标时序数据。该流会用到特定的指标服务。
典型的数据采集流包括如下步骤:
我们已经上线了多个关键业务服务。下图是一个服务随时间扩缩容的曲线。根据分析结果对实例数周期性地进行扩缩容。图9展示了两个区域的容量实例随时间的变化曲线。不同的服务的性能、流量模式和底层硬件性能都会影响到利用率和线性回归模型。随着时间的推移,会导致不同的扩缩容趋势。

图9:区域容量
图10是服务利用率的扩缩容曲线,整体呈上升趋势,每天和每周的流量模式都会导致不同的利用率。CRE会尝试根据评估的峰值流量来提高利用率,以满足其需求。
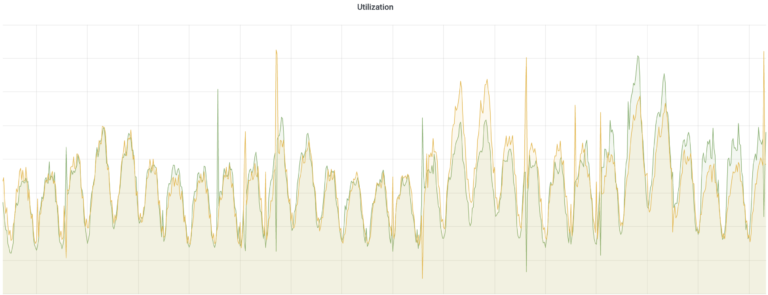
图10:区域利用率
本文引入了一种容量推荐引擎,通过机器学习模型来分析历史数据,能够对区域服务的性能趋势和利用率模式进行分析。有了这些数据,就可以通过自动扩缩容来可靠地管理数千个微服务的容量。现在,通过吞吐量评估以及一个基于吞吐量和利用率的线性回归模型,可以以天为节奏为我们推荐后续7天的峰值流量容量。我们的下一个目标是按小时进行反应式扩展,以扩大每日高峰流量的容量,并在非高峰时段释放容量。这将使我们能够利用各种任务所使用的资源利用率模式,以进一步提高整体资源使用效率。
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/16294734.html