即时编译(Just In Time,JIT)的运行模式有两种:client模式(C1编译器)和server模式(C2编译器)。这两种模式采用的编译器是不一样的,client模式采用的是代号为C1的轻量级编译器,特点是启动快,但是编译不够彻底;而server模式采用的是代号为C2的编译器,特点是启动比较慢,但是编译比较彻底,所以一旦服务起来后,性能更高。
用户可以使用 -client 和 -server 参数强制指定虚拟机运行在 Client 模式或者 Server 模式。这种配合使用的方式称为“混合模式”(Mixed Mode),用户可以使用参数 -Xint 强制虚拟机运行于 “解释模式”(Interpreted Mode),这时候编译器完全不介入工作。另外,使用 -Xcomp 强制虚拟机运行于 “编译模式”(Compiled Mode),这时候将优先采用编译方式执行,但是解释器仍然要在编译无法进行的情况下接入执行过程。JDK8默认开启了分层编译。不管是开启还是关闭分层编译,原本用来选择即时编译器的参数 -client 和 -server 都是无效的。当关闭分层编译的情况下(指定-XX:-TieredCompilation),Java 虚拟机将直接采用 C2编译器编译。如果只想用 C1,可以在打开分层编译的情况下使用参数 -XX:TieredStopAtLevel=1。在这种情况下,Java 虚拟机会在解释执行之后直接由 1 层的 C1 进行编译。
Oracle JDK6u25之后引入了分层编译(对应参数 -XX:+TieredCompilation)的概念,综合了 C1 的启动性能优势和 C2 的峰值性能优势。JDK8版本默认开启了分层编译。不管是开启还是关闭分层编译,原本用来选择即时编译器的参数 -client 和 -server 都是无效的。当关闭分层编译的情况下(指定-XX:-TieredCompilation),Java 虚拟机将直接采用 C2编译器编译。如果只想用 C1,可以在打开分层编译的情况下使用参数 -XX:TieredStopAtLevel=1。在这种情况下,Java 虚拟机会在解释执行之后直接由 1 层的 C1 进行编译。
下面介绍一下HotSpot VM的编译策略。编译策略通常由CompilationPolicy来表示,CompilationPolicy是选择哪个方法要用什么程度优化的抽象层。此类的继承体系如下:
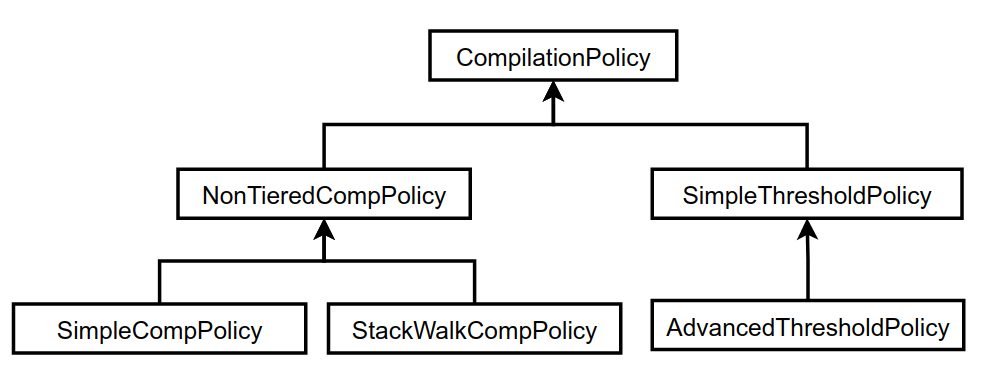
在实现分层编译之前,编译策略主要有两种实现,一种是SimpleCompPolicy,表示哪个方法触发编译就编译哪个方法;另一种是StackWalkCompPolicy,在触发编译的时候会遍历调用栈,看看是不是向上几层找个caller来编译的受益更大,找最大受益的caller来编译。
在实现多层编译之后,CompilationPolicy的任务还加上了为当前要编译的方法选择一个合适的编译路径去编译。
CompilationPolicy类的实现如下:
源代码位置:openjdk/hotspot/src/share/vm/runtime/compilationPolicy.hppclass CompilationPolicy : public CHeapObj<mtCompiler> { // 运行时使用的CompilationPolicy static CompilationPolicy* _policy; // 用于编译耗时统计 static elapsedTimer _accumulated_time; public: // ... // 方法必须被编译执行 static bool must_be_compiled(methodHandle m, int comp_level = CompLevel_all); // 方法被允许编译(在未编译完成时可能会解释执行) static bool can_be_compiled(methodHandle m, int comp_level = CompLevel_all); // 方法被允许OSR编译 static bool can_be_osr_compiled(methodHandle m, int comp_level = CompLevel_all); // ...} |
通过compilationPolicy_init()函数完成CompilationPolicy的初始化,调用栈如下:
Threads::create_vm() thread.cppinit_globals() init.cppcompilationPolicy_init() compilationPolicy.cpp |
在创建虚拟机时会调用compilationPolicy_init()函数,此函数的实现如下:
// 根据命令行参数选择编译策略,默认情况下选择AdvancedThresholdPolicyvoid compilationPolicy_init() { switch(CompilationPolicyChoice) { case 0: CompilationPolicy::set_policy(new SimpleCompPolicy()); break; case 1: // 需要在C2编译器可用情况下才能选择此选项 CompilationPolicy::set_policy(new StackWalkCompPolicy()); break; case 2: // 需要在支持分层编译情况下才能选择此选项 CompilationPolicy::set_policy(new SimpleThresholdPolicy()); break; case 3: // 需要在支持分层编译情况下才能选择此选项 CompilationPolicy::set_policy(new AdvancedThresholdPolicy()); break; default: fatal("CompilationPolicyChoice must be in the range: [0-3]"); } CompilationPolicy::policy()->initialize();} |
CompilationPolicyChoice是虚拟机配置命令,表示具体的编译策略,server模式下默认是3,也就是采用AdvancedThresholdPolicy策略。
AdvancedThresholdPolicy继承自SimpleThresholdPolicy,SimpleThresholdPolicy在CompilationPolicy的基础上添加了两个属性_c1_count和_c2_count,表示C1和C2编译线程的数量。AdvancedThresholdPolicy添加了_start_time和_increase_threshold_at_ratio两个属性,前者表示启动时间,后者表示当CodeCache已使用了指定比例时提升C1编译的阈值。
在compilationPolicy_init()函数中会调用AdvancedThresholdPolicy::initialize()函数初始化编译策略。AdvancedThresholdPolicy::initialize()函数的实现如下:
void AdvancedThresholdPolicy::initialize() { // CICompilerCountPerCPU默认值为false,表示是否每个CPU对应1个后台编译线程, // CICompilerCount表示后台编译线程的数量,默认值3 // 当这两个选项配置都是默认值时,将CICompilerCountPerCPU设置为true if (FLAG_IS_DEFAULT(CICompilerCountPerCPU) && FLAG_IS_DEFAULT(CICompilerCount)) { FLAG_SET_DEFAULT(CICompilerCountPerCPU, true); }<br> int count = CICompilerCount; if (CICompilerCountPerCPU) { //考虑机器的CPU数量,计算总的后台编译线程数 int log_cpu = log2_int(os::active_processor_count()); int loglog_cpu = log2_int(MAX2(log_cpu, 1)); count = MAX2(log_cpu * loglog_cpu, 1) * 3 / 2; } // 计算C1,C2编译线程的数量,按照1:2的比例进行分配 set_c1_count(MAX2(count / 3, 1)); set_c2_count(MAX2(count - c1_count(), 1)); // 重置CICompilerCount FLAG_SET_ERGO(intx, CICompilerCount, c1_count() + c2_count()); // InlineSmallCode表示只有当方法代码的大小小于该值时才会使用内联编译的方式,x86下默认是1000 // 这里是将其调整为2000 if (FLAG_IS_DEFAULT(InlineSmallCode)) { FLAG_SET_DEFAULT(InlineSmallCode, 2000); } // 当CodeCache已使用了指定比例时提升C1编译的阈值 set_increase_threshold_at_ratio(); } // IncreaseFirstTierCompileThresholdAt默认是50%,当CodeCache的// 已使用量大于50%时就会开始提高触发C1编译的阈值void set_increase_threshold_at_ratio() { _increase_threshold_at_ratio = 100 / (100 - (double)IncreaseFirstTierCompileThresholdAt); } |
在64位JVM中,有2种情况来计算总的编译线程数,如下:
- -XX:+CICompilerCountPerCPU=true, 默认情况下,编译线程的总数根据处理器数量来调整;
- -XX:+CICompilerCountPerCPU=false且-XX:+CICompilerCount=N,强制设定总编译线程数。
无论以上哪种情况,HotSpot VM都会将这些编译线程按照1:2的比例分配给C1和C2(至少1个),举个例子,对于一个四核机器来说,总的编译线程数目为 3,其中包含一个 C1 编译线程和两个 C2 编译线程。
设置完成编译器线程数量后,会在创建虚拟机实例时调用compilation_init()函数初始化编译相关组件,包括编译器实现,编译线程,计数器等。调用栈如下:
Threads::create_vm() thread.cpp CompileBroker::compilation_init() compileBroker.cpp |
compilation_init()函数的实现如下:
void CompileBroker::compilation_init() { if (!UseCompiler) { // 不使用编译器就不需要初始化 return; } // 返回前面计算出的编译器线程数量 int c1_count = CompilationPolicy::policy()->compiler_count(CompLevel_simple); int c2_count = CompilationPolicy::policy()->compiler_count(CompLevel_full_optimization); if (c1_count > 0) { _compilers[0] = new Compiler(); // C1编译器为Compiler } if (c2_count > 0) { _compilers[1] = new C2Compiler(); // C2编译器为C2Compiler } // 启动编译线程 init_compiler_threads(c1_count, c2_count); // ...} |
调用init_compiler_threads()函数的实现如下:
void CompileBroker::init_compiler_threads(int c1_compiler_count, int c2_compiler_count) { // 初始化编译线程任务队列 if (c2_compiler_count > 0) { _c2_method_queue = new CompileQueue("C2MethodQueue", MethodCompileQueue_lock); _compilers[1]->set_num_compiler_threads(c2_compiler_count); } if (c1_compiler_count > 0) { _c1_method_queue = new CompileQueue("C1MethodQueue", MethodCompileQueue_lock); _compilers[0]->set_num_compiler_threads(c1_compiler_count); } int compiler_count = c1_compiler_count + c2_compiler_count; _compiler_threads = new (ResourceObj::C_HEAP, mtCompiler) GrowableArray<CompilerThread*>(compiler_count, true); char name_buffer[256]; // 创建C2编译器线程 for (int i = 0; i < c2_compiler_count; i++) { CompilerCounters* counters = new CompilerCounters("compilerThread", i, CHECK); CompilerThread* new_thread = make_compiler_thread(name_buffer, _c2_method_queue, counters, _compilers[1], CHECK); _compiler_threads->append(new_thread); } // 创建C1编译器线程 for (int i = c2_compiler_count; i < compiler_count; i++) { CompilerCounters* counters = new CompilerCounters("compilerThread", i, CHECK); CompilerThread* new_thread = make_compiler_thread(name_buffer, _c1_method_queue, counters, _compilers[0], CHECK); _compiler_threads->append(new_thread); }} |
分别创建C1和C2编译的CompileQueu队列,所有的编译任务都需要入到队列中,然后由创建出来的编译线程从队列中获取到编译任务进行编译,这在后面的文章中会详细介绍,这里不再介绍。
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流