https://zhuanlan.zhihu.com/p/408702204
DDL(Data Definition Language)是数据库内部的对象进行创建、删除、修改的操作语言,主要包括:加减列、更改列类型、加减索引等类型。数据库的模式(schema)会随着业务的发展不断变化,如果没有高效的DDL功能,每一次变更都有可能影响业务,甚至产生故障。MySQL在8.0以前就已经支持Online DDL,在执行时能够不阻塞其它DML(Insert/Update/Delete)操作,但许多重要的DDL操作,如加列、减列等,仍旧需要等待很长时间(根据数据量的大小)才会生效。为了提高表结构变更的效率,MySQL在8.0.12版本支持了Instant DDL功能,不需要修改存储层数据就可以快速完成DDL。
执行DDL的ALTER语句增加了新的关键字INSTANT,用户可以显式地指定,MySQL也会自动选择合适的算法,因此Instant DDL对用户是透明的。
ALTER TABLE tbl_name
[alter_specification [, alter_specification] ...]
[partition_options]
alter_specification:
table_options
| ADD [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| ADD [COLUMN] (col_name column_definition,...)
....
| ALGORITHM [=] {DEFAULT|INSTANT|INPLACE|COPY}
备注:
1.DEFAULT:MySQL自己选择锁定资源最少的方式
2.INSTANT:只需要更新数据字典中的元数据, 很快完成
3.INPLACE:此变更由InnoDB引擎独立完成, 不需要使用Redo log等, 可以节省开销
4.COPY:此变更会重建聚簇索引, 执行DDL的时候会创建临时表
随着业务的发展,加字段是最常见表结构变更类型。Instant add column功能不需要修改存储层数据,更不需要重建表,只改变了存储在系统表中的表结构,其执行效率非常高。解决了以下业务上的痛点:
在实现上,MySQL并没有在系统表中记录多个版本的schema,而是非常取巧的扩展了存储格式。在已有的info bits区域和新增的字段数量区域记录了instant column信息,instant add column之前的数据不做任何修改,之后的数据按照新格式存储。同时在系统表的private_data字段存储了instant column的默认值信息。查询时,读出的老记录只需要增加instant column默认值,新记录则按照新的存储格式进行解析,做到了新老格式的兼容。当然,这种实现方式带来的限制就是只能顺序加字段。
官方设计文档详见:https://dev.mysql.com/worklog/task/?spm=a2c4e.10696291.0.0.439f19a4hwOoes&id=11250。本文主要梳理了新的存储格式、DDL、查询以及插入的执行流程。
8.0.12版本之前的MySQL在进行加列操作时,需要更新数据字典并重建表空间,所有的数据行都必须改变长度用于存放增加的数据,DDL操作运行时间很长,占用大量系统资源,更需要额外的磁盘空间(建立临时表),影响系统吞吐,而且一旦执行过程中发生crash,恢复时间也很长。
主要流程:
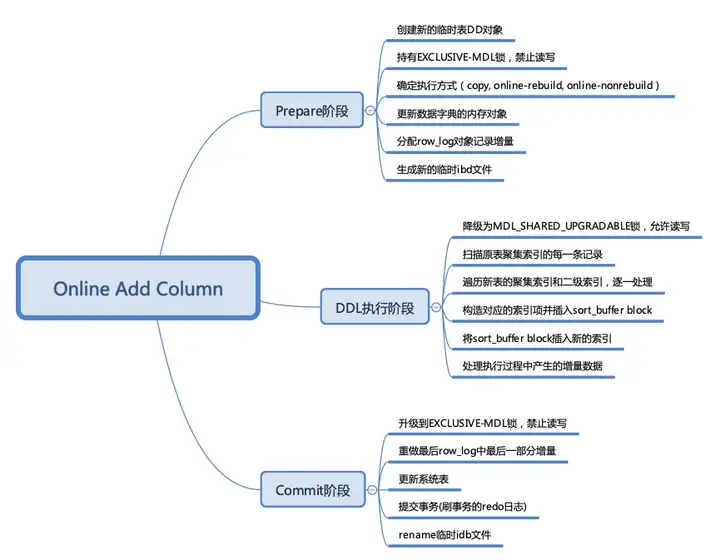
Instant add column在增加列时,实际上只是修改了schema,并没有修改原来存储在文件中的行记录,不需要执行最耗时的rebuild和apply row log过程,因此效率非常高。
主要流程:

在执行instant add column的过程中,MySQL会将第一次intant add column之前的字段个数以及每次加的列的默认值保存在tables系统表的se_private_data字段中。
MySQL从系统表读取表定义时,会将instant column相关的信息载入到InnoDB的表对象dict_table_t和索引对象dict_index_t中。
InnoDB存储引擎支持的行格式包括REDUNDANT,COMPACT以及DYNAMIC,REDUNDANT类型的行记录了完整的元数据信息,可以自解析,但对于COMPACT和DYNAMIC类型,为了减少存储空间,其行内并不包括元数据,尤其是列的个数,因此解析记录时需要额外的元数据辅助。
以COMPACT为例,其行格式为:
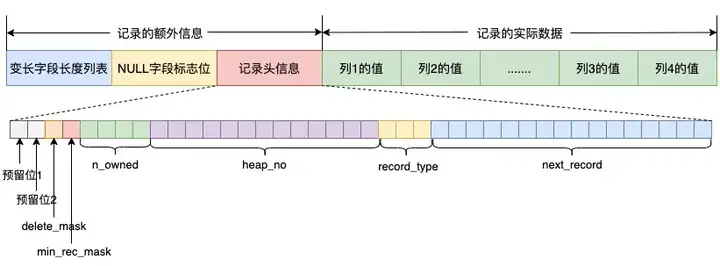
COMPACT行格式的首部是一个变长字段长度列表,这个列表是按照字段的顺序逆序放置的。如果字段的字义长度大于255个字节,或者字段的数据类型为BLOB的,则用2个字节来存储该字段的长度;如果定义长度小于128个字节,或者小于256个字节,但类型不是BLOB类型的,则用一个字节来存储该字段的长度,除此之外都用2个字节来存储。
变长字段长度列表之后是NULL字段标志位,这个标志位用于记录中哪些字段的值是null,只存储nullable属性的字段,不会存储属性为not nulll的字段。每一bit都表示一个nullable的字段的null属性,如果为null则设置为1,这个bit vector也是按照字段的顺序逆序放置的,整个标志位长度取决于记录中nullable字段的个数,而是以8为单位,满8个null字段就多1个字节,不满8个也占用1个字节,高位用0补齐。
记录头信息最开始的4个bit组成了info bits, 目前只使用了两个bit,具体含义如下:
| 名称 | 大小(bit) | 描述 |
|---|
为了支持instant add column, 针对COMPACT和DYNAMIC类型,引入了新的记录格式,主要为了记录字段的个数信息。
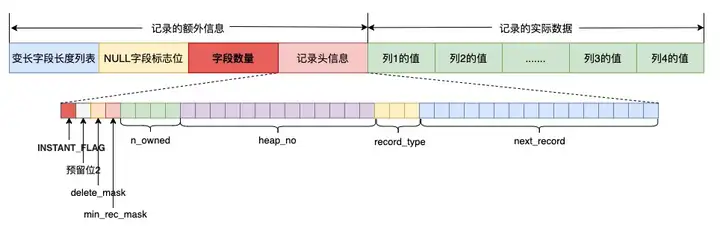
这个特殊的INSTANT_FLAG使用了info bits中的一个bit位,如果记录是第一次instant add column之后插入的,该flag被设置为1,且记录中会使用1或2个字节来存储字段的个数,如果字段个数小于等于127,则使用1个字节存储,否则使用2个字节存储。 相关代码:
// 返回用于存储字段数量的字节数
uint8_t rec_get_n_fields_length(ulint n_fields) {
return (n_fields > REC_N_FIELDS_ONE_BYTE_MAX ? 2 : 1);
}
// 设置字段数量
uint8_t rec_set_n_fields(rec_t *rec, ulint n_fields) {
// 指向记录头信息的前一个字节
byte *ptr = rec - (REC_N_NEW_EXTRA_BYTES + 1);
ut_ad(n_fields < REC_MAX_N_FIELDS);
// 如果字段数量小于或等于127
if (n_fields <= REC_N_FIELDS_ONE_BYTE_MAX) {
// 在当前位置存储字段数量
*ptr = static_cast<byte>(n_fields);
// 存储字段数量的字节数是1
return (1);
}
// 如果字段数量大于127,向前移动一个字节
--ptr;
// 第一个字节记录低8位数据
*ptr++ = static_cast<byte>(n_fields & 0xFF);
// 第二个字节记录高8位数据
*ptr = static_cast<byte>(n_fields >> 8);
ut_ad((*ptr & 0x80) == 0);
*ptr |= REC_N_FIELDS_TWO_BYTES_FLAG;
// 存储字段数量的字节数是2
return (2);
}> create table t1(id int, c1 varchar(10), c2 varchar(10), c3 char(10), c4 varchar(10), primary key(id)) row_format=compact;
Query OK, 0 rows affected (0.24 sec)
> insert into t1 values(1, 'a','ab','ab','ccc');
Query OK, 1 row affected (0.01 sec)
> insert into t1 values(2, 'b', NULL, NULL, 'ddd');
Query OK, 1 row affected (0.01 sec)
> select * from t1;
+----+------+------+------+------+
| id | c1 | c2 | c3 | c4 |
+----+------+------+------+------+
| 1 | a | ab | ab | ccc |
| 2 | b | NULL | NULL | ddd |
+----+------+------+------+------+
2 rows in set (0.00 sec)
$ hexdump -C -v t1.ibd > t1.txt
00010070 73 75 70 72 65 6d 75 6d 03 0a 02 01 00 00 00 10 |supremum........|
00010080 00 29 80 00 00 01 00 00 00 00 07 d8 9e 00 00 00 |.)..............|
00010090 94 01 10 61 61 62 61 62 20 20 20 20 20 20 20 20 |...aabab |
000100a0 63 63 63 03 01 06 00 00 18 00 1f 80 00 00 02 00 |ccc.............|
000100b0 00 00 00 07 d9 9f 00 00 00 94 01 10 62 64 64 64 |............bddd|| 起始地址 | 数据 | 长度(字节) | 解析 |
|---|
| 起始地址 | 数据 | 长度(字节) | 解析 |
|---|
> alter table t1 add column (c5 varchar(10)), ALGORITHM = INSTANT;
Query OK, 0 rows affected (0.28 sec)
> insert into t1 values (3, 'c', NULL, NULL, 'eee', 'eeee');
Query OK, 1 row affected (0.06 sec)
> select * from t1;
+----+------+------+------+------+------+
| id | c1 | c2 | c3 | c4 | c5 |
+----+------+------+------+------+------+
| 1 | a | ab | ab | ccc | NULL |
| 2 | b | NULL | NULL | ddd | NULL |
| 3 | c | NULL | NULL | eee | eeee |
+----+------+------+------+------+------+
3 rows in set (0.00 sec)
$ hexdump -C -v t1.ibd > t1.txt
00010070 73 75 70 72 65 6d 75 6d 03 0a 02 01 00 00 00 10 |supremum........|
00010080 00 29 80 00 00 01 00 00 00 00 07 d8 9e 00 00 00 |.)..............|
00010090 94 01 10 61 61 62 61 62 20 20 20 20 20 20 20 20 |...aabab |
000100a0 63 63 63 03 01 06 00 00 18 00 1f 80 00 00 02 00 |ccc.............|
000100b0 00 00 00 07 d9 9f 00 00 00 94 01 10 62 64 64 64 |............bddd|
000100c0 04 03 01 06 08 80 00 20 ff a6 80 00 00 03 00 00 |....... ........|
000100d0 00 00 07 e7 a0 00 00 00 95 01 10 63 65 65 65 65 |...........ceeee|
000100e0 65 65 65 00 00 00 00 00 00 00 00 00 00 00 00 00 |eee.............|| 起始地址 | 数据 | 长度(字节) | 解析 |
|---|
查询的流程没有变化,关键点在于如何准确地解析记录,对于没有存储在记录中的instant column, 直接填默认值即可,关键函数是rec_init_null_and_len_comp。 主要流程:
|-mysql_execute_command
|-Sql_cmd_dml::execute
|-Sql_cmd_dml::execute_inner
|-JOIN::exec
|-do_select
|-sub_select
|-TableScanIterator::Read
|-handler::ha_rnd_next
|-ha_innobase::rnd_next
|-ha_innobase::index_first
|-ha_innobase::index_read
|-row_search_mvcc
|-rec_get_offsets_func
|-rec_init_offsets
|-rec_init_offsets_comp_ordinary
|-rec_init_null_and_len_comp
|-*nulls = rec - (REC_N_NEW_EXTRA_BYTES + 1); // REC_N_NEW_EXTRA_BYTES = 5,
|-if (!index->has_instant_cols())
|-*n_null = index->n_nullable;
|-else if (rec_get_instant_flag_new(rec) /* Row inserted after first instant ADD COLUMN */
|-non_default_fields = rec_get_n_fields_instant
|-*nulls -= length;
|-*n_null = index->get_n_nullable_before(non_default_fields);
|-else /* Row inserted before first instant ADD COLUMN */
|-*n_null = index->n_instant_nullable;
|-non_default_fields = index->get_instant_fields();
|-row_sel_store_mysql_rec
|-for (i = 0; i < prebuilt->n_template; i++)
|-row_sel_store_mysql_field // row_sel_store_mysql_field_func
|-rec_get_nth_field_instant // 如果是记录中的,则从记录中读取,否则返回其默认值
|-row_sel_field_store_in_mysql_format_func执行instant add column后,老数据的格式没有变化,新插入的数据按照新格式存储,关键函数是rec_convert_dtuple_to_rec_comp,该函数将MySQL逻辑记录转换为COMPACT格式的物理记录。此外,函数rec_set_instant_flag_new在记录的Info bits字段设置REC_INFO_INSTANT_FLAG,表示这个记录是instant add column之后创建的。
bool rec_convert_dtuple_to_rec_comp(rec_t *rec, const dict_index_t *index,
const dfield_t *fields, ulint n_fields,
const dtuple_t *v_entry, ulint status,
bool temp) {
const dfield_t *field;
const dtype_t *type;
byte *end;
byte *nulls;
byte *lens = NULL;
ulint len;
ulint i;
ulint n_node_ptr_field;
ulint fixed_len;
ulint null_mask = 1;
ulint n_null = 0;
ulint num_v = v_entry ? dtuple_get_n_v_fields(v_entry) : 0;
bool instant = false;
ut_ad(temp || dict_table_is_comp(index->table));
if (n_fields != 0) {
// 获得nullable字段个数
n_null = index->has_instant_cols()
? index->get_n_nullable_before(static_cast<uint32_t>(n_fields))
: index->n_nullable;
}
if (temp) {
ut_ad(status == REC_STATUS_ORDINARY);
ut_ad(n_fields <= dict_index_get_n_fields(index));
n_node_ptr_field = ULINT_UNDEFINED;
nulls = rec - 1;
if (dict_table_is_comp(index->table)) {
/* No need to do adjust fixed_len=0. We only
need to adjust it for ROW_FORMAT=REDUNDANT. */
temp = false;
}
} else {
ut_ad(v_entry == NULL);
ut_ad(num_v == 0);
// 指向指向记录头信息的前一个字节
nulls = rec - (REC_N_NEW_EXTRA_BYTES + 1);
switch (UNIV_EXPECT(status, REC_STATUS_ORDINARY)) {
case REC_STATUS_ORDINARY:
ut_ad(n_fields <= dict_index_get_n_fields(index));
n_node_ptr_field = ULINT_UNDEFINED;
// 如果存在instant column,那么还存在字段个数信息,调用rec_set_n_fields设置
// 字段数量,并返回存储字节数, 如果字段数量不大于127,存储长度为1字节,否则为2字节
if (index->has_instant_cols()) {
uint32_t n_fields_len;
n_fields_len = rec_set_n_fields(rec, n_fields);
// nulls指向存储字段数量信息的前一个字节,也就是null标志位最后一个字节开始的位置
nulls -= n_fields_len;
instant = true;
}
break;
case REC_STATUS_NODE_PTR:
ut_ad(n_fields ==
static_cast<ulint>(
dict_index_get_n_unique_in_tree_nonleaf(index) + 1));
n_node_ptr_field = n_fields - 1;
n_null = index->n_instant_nullable;
break;
case REC_STATUS_INFIMUM:
case REC_STATUS_SUPREMUM:
ut_ad(n_fields == 1);
n_node_ptr_field = ULINT_UNDEFINED;
break;
default:
ut_error;
return (instant);
}
}
end = rec;
if (n_fields != 0) {
// 指向变长字段长度列表最后一个字节开始的位置
lens = nulls - UT_BITS_IN_BYTES(n_null);
/* clear the SQL-null flags */
memset(lens + 1, 0, nulls - lens);
}
/* Store the data and the offsets */
// 遍历所有字段
for (i = 0; i < n_fields; i++) {
const dict_field_t *ifield;
dict_col_t *col = NULL;
field = &fields[i];
type = dfield_get_type(field);
len = dfield_get_len(field);
if (UNIV_UNLIKELY(i == n_node_ptr_field)) {
ut_ad(dtype_get_prtype(type) & DATA_NOT_NULL);
ut_ad(len == REC_NODE_PTR_SIZE);
memcpy(end, dfield_get_data(field), len);
end += REC_NODE_PTR_SIZE;
break;
}
// 如果不是not null类型的字段
if (!(dtype_get_prtype(type) & DATA_NOT_NULL)) {
/* nullable field */
ut_ad(n_null--);
// 如果写满8个,则offset向左移1位,并将null_mask置为1
if (UNIV_UNLIKELY(!(byte)null_mask)) {
nulls--;
null_mask = 1;
}
ut_ad(*nulls < null_mask);
// 如果字段是null
if (dfield_is_null(field)) {
// 将null标志位设为1
*nulls |= null_mask;
// 向前移1位
null_mask <<= 1;
continue;
}
null_mask <<= 1;
}
/* only nullable fields can be null */
ut_ad(!dfield_is_null(field));
ifield = index->get_field(i);
fixed_len = ifield->fixed_len;
col = ifield->col;
if (temp && fixed_len && !col->get_fixed_size(temp)) {
fixed_len = 0;
}
/* If the maximum length of a variable-length field
is up to 255 bytes, the actual length is always stored
in one byte. If the maximum length is more than 255
bytes, the actual length is stored in one byte for
0..127. The length will be encoded in two bytes when
it is 128 or more, or when the field is stored externally. */
if (fixed_len) {
#ifdef UNIV_DEBUG
ulint mbminlen = DATA_MBMINLEN(col->mbminmaxlen);
ulint mbmaxlen = DATA_MBMAXLEN(col->mbminmaxlen);
ut_ad(len <= fixed_len);
ut_ad(!mbmaxlen || len >= mbminlen * (fixed_len / mbmaxlen));
ut_ad(!dfield_is_ext(field));
#endif /* UNIV_DEBUG */
} else if (dfield_is_ext(field)) {
ut_ad(DATA_BIG_COL(col));
ut_ad(len <= REC_ANTELOPE_MAX_INDEX_COL_LEN + BTR_EXTERN_FIELD_REF_SIZE);
*lens-- = (byte)(len >> 8) | 0xc0;
*lens-- = (byte)len;
} else {
/* DATA_POINT would have a fixed_len */
ut_ad(dtype_get_mtype(type) != DATA_POINT);
#ifndef UNIV_HOTBACKUP
ut_ad(len <= dtype_get_len(type) ||
DATA_LARGE_MTYPE(dtype_get_mtype(type)) ||
!strcmp(index->name, FTS_INDEX_TABLE_IND_NAME));
#endif /* !UNIV_HOTBACKUP */
if (len < 128 ||
!DATA_BIG_LEN_MTYPE(dtype_get_len(type), dtype_get_mtype(type))) {
*lens-- = (byte)len;
} else {
ut_ad(len < 16384);
// 设置变长字段长度信息
*lens-- = (byte)(len >> 8) | 0x80;
*lens-- = (byte)len;
}
}
if (len > 0) memcpy(end, dfield_get_data(field), len);
end += len;
}
if (!num_v) {
return (instant);
}
/* reserve 2 bytes for writing length */
byte *ptr = end;
ptr += 2;
......
mach_write_to_2(end, ptr - end);
return (instant);
}MySQL的instant add column功能极大地提高了增加字段的效率,执行过程中不需要修改存储中的数据,只改变了存储在系统表中的表结构。期待MySQL能支持更多更实用的instant DDL类型,例如任意顺序加字段、删字段、修改字段类型等,这可能需要引入更复杂的多版本schema技术,设置将更多的schema信息下沉到存储层,实现难度无疑会大大增加。