JVM调优汇总
1、根据实际情况选择合适垃圾收集器
堆内存4G一下可以用parallel,4-8G可以用ParNew + CMS,8G以上可以用G1,几百级以上用ZGC。
2、jvm参数的初始值和最大值设置一样,避免扩容时消耗性能。
‐Xms3072M ‐Xmx3072M ‐XX:MetaspaceSize=256M‐XX:MaxMetaspaceSize=256M
3、JVM调优目的:减少GC,主要是减少FullGC的频率。
优化思路:
- 尽可能让对象都在新生代里分配和回收,尽可能别让太多对象频繁进入老年代,避免频繁对老年代进行垃圾回收,同时给系统充足的内存大小,避免新生代频繁进行垃圾回收。
- 尽量让每次Young GC后的存活对象小于Survivor区域的50%,都留在年轻代中,避免对象动态年龄判定的触发。尽量别让对象进入老年代,减少FullGC频率,避免频繁fullGC对性能影响。(FullGC时间长,会STW)。
- 元空间的大小参数必须要设置,默认是21m,但是它会自动扩容,元空间满了也会触发fullGC,所以一开始就设置好,避免扩容和触发FullGC。
- 参数设置:默认老年代:年轻代是2:1,可以调整为1:1或者1:2,eden区和s0、s1默认是8:1:1,可以调整为6:1:1,就是为了扩大年轻代的空间,避免触发对象动态年龄判定机制,尽量避免对象进入老年代,触发FullGC,也可以减少minorGC的频率。
怎么选择垃圾收集器
1. 优先调整堆的大小让服务器自己来选择
2. 如果内存小于100M,使用串行收集器
3. 如果是单核,并且没有停顿时间的要求,串行或JVM自己选择
4. 如果允许停顿时间超过1秒,选择并行或者JVM自己选
5. 如果响应时间最重要,并且不能超过1秒,使用并发收集器
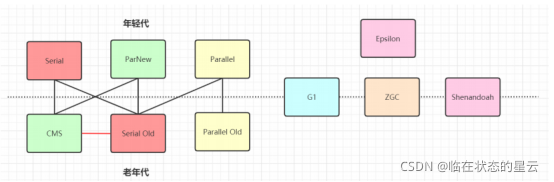
6. 4G以下可以用parallel,4-8G可以用ParNew+CMS,8G以上可以用G1,几百G以上用ZGC
下图有连线的可以搭配使用
JDK 1.8默认使用 Parallel(年轻代和老年代都是)
JDK 1.9默认使用 G1
为什么大内存要用G1
- 如果堆内存达到了几十个G以上,那么用cms、parNew这些收集器,垃圾回收的时间会很长,想STW时间也会很长,用户体验很差。
- G1是可以调整停顿时间的,去优先收集部分垃圾对象,并不是一次回收所有的垃圾,那这样用户体验就会很好。
- 但是G1不太适用于小内存,因为内存小,回收速度会很快,G1它只回收部分的垃圾,性价比就不如cms这些了,只有在大内存时才能体现它的价值。
G1垃圾收集器优化建议
假设参数 -XX:MaxGCPauseMills 设置的值很大,导致系统运行很久,年轻代可能都占用了堆内存的60%了,此时才 触发年轻代gc。 那么存活下来的对象可能就会很多,此时就会导致Survivor区域放不下那么多的对象,就会进入老年代中。
或者是你年轻代gc过后,存活下来的对象过多,导致进入Survivor区域后触发了动态年龄判定规则,达到了Survivor 区域的50%,也会快速导致一些对象进入老年代中。
所以这里核心还是在于调节 -XX:MaxGCPauseMills 这个参数的值,在保证他的年轻代gc别太频繁的同时,还得考虑 每次gc过后的存活对象有多少,避免存活对象太多快速进入老年代,频繁触发mixed gc.
什么场景适合使用G1
1. 50%以上的堆被存活对象占用
2. 对象分配和晋升的速度变化非常大
3. 垃圾回收时间特别长,超过1秒
4. 8GB以上的堆内存(建议值)
5. 停顿时间是500ms以内
每秒几十万并发的系统如何优化JVM
Kafka类似的支撑高并发消息系统大家肯定不陌生,对于kafka来说,每秒处理几万甚至几十万消息时很正常的,一般 来说部署kafka需要用大内存机器(比如64G),也就是说可以给年轻代分配个三四十G的内存用来支撑高并发处理,这里就 涉及到一个问题了,我们以前常说的对于eden区的young gc是很快的,这种情况下它的执行还会很快吗?很显然,不可能,因为内存太大,处理还是要花不少时间的,假设三四十G内存回收可能最快也要几秒钟,按kafka这个并发量放满三 四十G的eden区可能也就一两分钟吧,那么意味着整个系统每运行一两分钟就会因为young gc卡顿几秒钟没法处理新消 息,显然是不行的。那么对于这种情况如何优化了,我们可以使用G1收集器,设置 -XX:MaxGCPauseMills 为50ms,假 设50ms能够回收三到四个G内存,然后50ms的卡顿其实完全能够接受,用户几乎无感知,那么整个系统就可以在卡顿几 乎无感知的情况下一边处理业务一边收集垃圾。
G1天生就适合这种大内存机器的JVM运行,可以比较完美的解决大内存垃圾回收时间过长的问题。