在前面多篇文章中多次提到方法内联,作为编译器最重要的优化技术,该技术不仅可以消除调用本身带来的性能开销,还能够触发更多的优化。本文将带领大家对该技术一探究竟。
方法内联
方法内联指的是:在编译过程中遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代原方法调用的优化手段。
以 getter/setter 为例,如果没有方法内联,在调用 getter/setter 时,程序需要保存当前方法的执行位置,创建并压入用于 getter/setter 的栈帧、访问字段、弹出栈帧,最后再恢复当前方法的执行。而当内联了对 getter/setter 的方法调用后,上述操作仅剩字段访问。在 C2 中,方法内联是在解析字节码的过程中完成的。每当碰到方法调用字节码时,C2 将决定是否需要内联该方法调用。如果需要内联,则开始解析目标方法的字节码。
我们通过下面这个案例来演示方法内联的过程:
public static boolean flag = true;
public static int value0 = 0;
public static int value1 = 1;
public static int foo(int value) {
int result = bar(flag);
if (result != 0) {
return result;
} else {
return value;
}
}
public static int bar(boolean flag) {
return flag ? value0 : value1;
}
上面这段代码中的 foo 方法将接收一个 int 类型的参数,而 bar 方法将接收一个 boolean 类型的参数。其中,foo 方法会读取静态字段 flag 的值,并作为参数调用 bar 方法。我们看代码明白 bar 方法固定返回 value0 值,但是 Java 解释器却不知道,所以指望解释器来优化这段代码是没戏了。
根据方法内联的定义,我们可知编译器有可能对该段代码进行优化,那么我们尝试调用 foo 方法,并使其达到一定热度,最终触发即时编译。我们增加测试方法如下:
public static void main(String[] args) {
for (int i = 0; i < 20000; i++) {
foo(i);
}
}
执行前增加 -XX:+PrintCompilation 参数,输出编译结果。具体每项内联信息所代表的意思,你可以参考官网。
235 28 3 com.msdn.java.javac.jit.MethodInlineTest::foo (15 bytes)
235 29 3 com.msdn.java.javac.jit.MethodInlineTest::bar (14 bytes)
236 30 4 com.msdn.java.javac.jit.MethodInlineTest::foo (15 bytes)
236 28 3 com.msdn.java.javac.jit.MethodInlineTest::foo (15 bytes) made not entrant
可以看出,foo 方法触发了即时编译,接下来我们通过如下命令来看 bar 方法是否被内联到 foo 方法中。
-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
输出结果为:
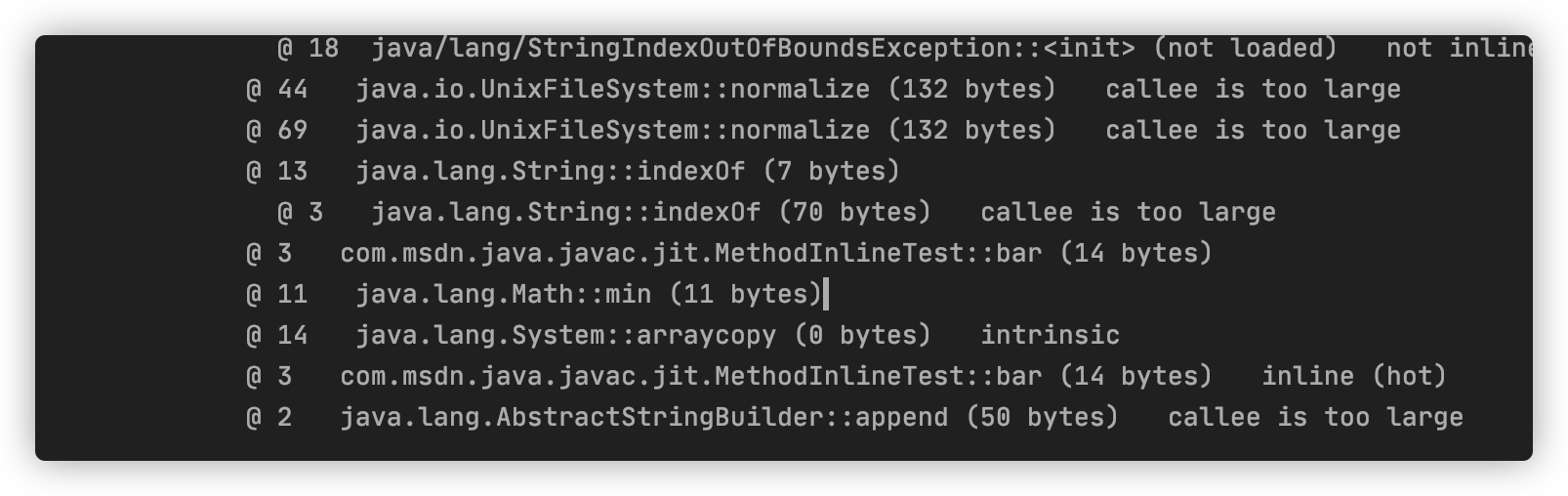
inline 表示 bar 方法内联成功。
网上关于方法内联的推论是利用 IR 图,但是这个东西一方面看起来有些费劲,然后查看 IR 图需要 Ideal Graph Visualizer 工具,该工具对 JDK 版本有限制,只能配置 JDK6,且只支持 Windows 和 Liunx,所以就不讨论 IR 图了。
我们通过修改原代码,一步步来演示优化过程。
第一步,方法内联
public static int foo(int value) {
int result = flag ? value0 : value1;
if (result != 0) {
return result;
} else {
return value;
}
}
第二步,死代码消除
public static int foo(int value) {
int result = 0;
if (result != 0) {
return result;
} else {
return value;
}
}
上述代码方法内联成功了,那么什么情况下可以方法内联,有什么限制吗?我们继续往下学习。
方法内联的条件
方法内联能够触发更多的优化。通常而言,内联越多,生成代码的执行效率越高。然而,对于即时编译器来说,内联越多,编译时间也就越长,而程序达到峰值性能的时刻也将被推迟。
同时,内联意味着有编译,编译后的机器码要存到 Codecache 中,而 Codecache 内存是有固定大小的由 Java 虚拟机参数 -XX:ReservedCodeCacheSize 控制),如果 Codecache 满了,则会带来性能问题。
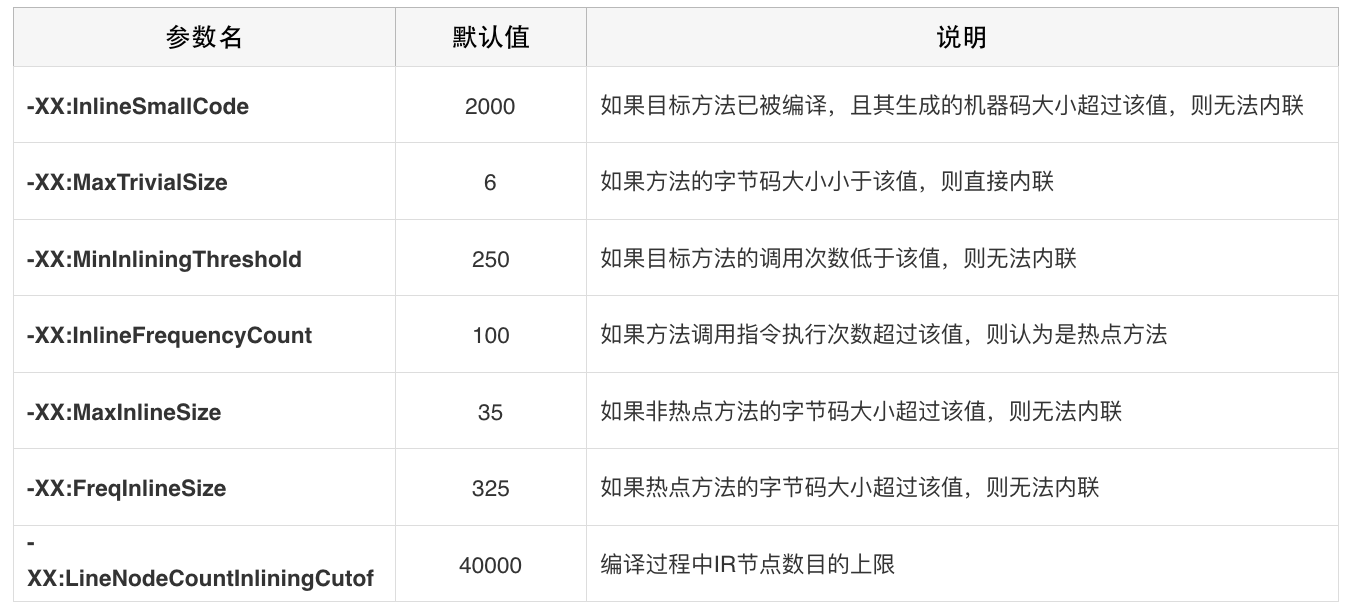
因此,即时编译器不会无限制地进行方法内联。下面我便列举即时编译器的部分内联规则。(其他的特殊规则,可以直接参考JDK 的源代码。)
第一,由 -XX:CompileCommand 中的 inline 指令指定的方法,以及由 @ForceInline 注解的方法(仅限于 JDK 内部方法),会被强制内联。 而由 -XX:CompileCommand 中的 dontinline 指令或 exclude 指令(表示不编译)指定的方法,以及由 @DontInline 注解的方法(仅限于 JDK 内部方法),则始终不会被内联。
这里仅测试手动禁止内联,基于上述代码,我们增加如下 JVM 参数:
-XX:+PrintCompilation -XX:CompileCommand=exclude,com/msdn/java/javac/jit/MethodInlineTest::bar
- 1
编译输出结果为:
### Excluding compile: static com.msdn.java.javac.jit.MethodInlineTest::bar
made not compilable on all levels com.msdn.java.javac.jit.MethodInlineTest::bar (14 bytes) excluded by CompilerOracle
213 28 3 com.msdn.java.javac.jit.MethodInlineTest::foo (15 bytes)
214 29 4 com.msdn.java.javac.jit.MethodInlineTest::foo (15 bytes)
214 30 4 java.lang.String::hashCode (55 bytes)
214 28 3 com.msdn.java.javac.jit.MethodInlineTest::foo (15 bytes) made not entrant
214 31 3 java.util.Arrays::copyOfRange (63 bytes)
即使执行 -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining 参数,也不会输出 inline 标识。
第二,如果调用字节码对应的符号引用未被解析、目标方法所在的类未被初始化,或者目标方法是 native 方法,都将导致方法调用无法内联。
第三,C2 不支持内联超过 9 层的调用(MaxInlineLevel默认为9,可以调整该参数大小),以及 1 层的直接递归调用(可以通过虚拟机参数 -XX:MaxRecursiveInlineLevel 调整)。
关于 1 层的直接递归调用,如下案例所示:
public static int foo(int value) {
if (1 == value) {
return 1;
} else {
return value + foo(value - 1);
}
}
public static void main(String[] args) {
for (int i = 0; i < 10000; i++) {
foo(3);
}
}
利用虚拟机参数 -XX:+PrintInlining 来打印编译过程中的内联情况,发现无法内联。尝试修改 MaxRecursiveInlineLevel 参数,再次执行代码。
-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining -XX:MaxRecursiveInlineLevel=5
- 1
发现结果中有内联标识。
第四,即时编译器将根据方法调用指令所在的程序路径的热度,目标方法的调用次数及大小,以及当前 IR 图的大小来决定方法调用能否被内联。
虚方法内联
在讲述虚方法内联前,我们回顾一下之前讲述《方法是如何调用的》一节的虚方法,关于虚方法和非虚方法,是这样定义的:
只有使用 invokespecial 指令调用的私有方法、实例构造器、父类方法和使用 invokestatic 指令调用的静态方法才会在编译期进行解析,再加上被 final 修饰的方法(尽管它使用invokevirtual指令调用) ,这5种方法调用会在类加载的时候就可以把符号引用解析为该方法的直接引用。这些方法统称为“非虚方法”(Non-Virtual Method),与之相反,其他方法就被称为“虚方法”(Virtual Method)。“非虚方法”可以内联,“虚方法”可以采取相关措施来实现内联。
关于虚方法调用有两个优化:内联缓存(inlining cache)和方法内联(method inlining)。
这里简单回忆一下内联缓存的描述,内联缓存是一种加快动态绑定的优化技术。它能够缓存虚方法调用中调用者的动态类型,以及该类型所对应的目标方法。在之后的执行过程中,如果碰到已缓存的类型,内联缓存便会直接调用该类型所对应的目标方法。如果没有碰到已缓存的类型,内联缓存则会退化至使用基于方法表的动态绑定。
上文举的例子都是静态方法调用(非虚方法调用),即时编译器可以轻易地确定唯一的目标方法。
接下来讲述的就是关于虚方法如何实现方法内联,相关措施为:对于需要动态绑定的虚方法调用来说,即时编译器则需要先对虚方法调用进行去虚化(devirtualize),即转换为一个或多个直接调用,然后才能进行方法内联。
为了后文的顺利进行,我们先了解几个字段代表的含义:
-
inline (hot),使用 -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining 参数时输出代码的内联情况,如果某个方法被内联了,结尾会跟有 inline (hot) 标识,当然也有其他一些标识,想要了解它们的含义可以参考官网。
-
made not entrant,使用 -XX:+PrintCompilation 参数时输出代码的编译情况,该标识表示发生了去优化,关于去优化可以参考我的上一篇文章。
-
virtual_call,使用 JITWatch 或者 hsdis 查看汇编代码时会遇到,表示虚方法调用。
-
optimized virtual_call,使用 JITWatch 或者 hsdis 查看汇编代码时会遇到,表示虚方法优化。
-
runtime_call,使用 JITWatch 或者 hsdis 查看汇编代码时会遇到,表示运行时调用。
在学习过程中,遇到了这么一个问题,optimized virtual_call 和 inline (hot)之间的关系,仅从字面意义上来看,针对虚方法的内联不就是优化嘛,那不就意味着 inline (hot)=》optimized virtual_call,这是我初期的认知。网上文章也有相关的描述,比如说:
可以看到JIT对methodCall方法进行了虚调用优化optimized virtual_call。经过优化后的方法可以被内联。
在网上搜了很久,关于 optimized virtual_call 的介绍并不多,没法将其认定作为方法内联的判断条件,而且经过多次测试验证,发现某些虚方法带有 inline (hot) 标识,但是汇编代码中没有出现 optimized virtual_call,而是 runtime_call。所以在后文中我不会使用其作为判断方法内联的条件。(如果有大佬知晓这两者之间的关联,烦请告知一下,谢谢啦)
回归正题,看看 Java 虚拟机是如何解决虚方法的内联问题。
即时编译器的去虚化方式可分为完全去虚化以及条件去虚化(guarded devirtualization)。
完全去虚化是通过类型继承关系分析(class hierarchy analysis),识别虚方法调用的唯一目标方法,从而将其转换为直接调用的一种优化手段。它的关键在于证明虚方法调用的目标方法是唯一的。
条件去虚化则是将虚方法调用转换为若干个类型测试以及直接调用的一种优化手段。它的关键在于找出需要进行比较的类型。
说到动态绑定,自然而然就会想到继承关系,所以我们就构造这样一段代码:
public abstract class BinaryOp {
public abstract int apply(int a, int b);
}
public class Add extends BinaryOp {
public int apply(int a, int b) {
return a + b;
}
}
基于类型继承关系分析的完全去虚化
为了解决虚方法的内联问题, Java虚拟机首先引入了一种名为类型继承关系分析(Class HierarchyAnalysis, CHA) 的技术, 这是整个应用程序范围内的类型分析技术,用于确定在目前已加载的类中, 某个接口是否有多于一种的实现、 某个类是否存在子类、 某个子类是否覆盖了父类的某个虚方法等信息。
基于类型推导的完全去虚化将通过数据流分析推导出调用者的动态类型,从而确定具体的目标方法。
public static int foo() {
BinaryOp op = new Add();
return op.apply(2, 1);
}
public static int bar(BinaryOp op) {
op = (Add) op;
return op.apply(2, 1);
}
上面这段代码中的 foo 方法和 bar 方法均会调用 apply 方法,且调用者的声明类型皆为 BinaryOp。
还是不习惯使用 IR 图,所以我们从字节码入手吧。
public static int foo();
descriptor: ()I
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=1, args_size=0
0: new #2 // class com/msdn/java/javac/jit/Add
3: dup
4: invokespecial #3 // Method com/msdn/java/javac/jit/Add."<init>":()V
7: astore_0
8: aload_0
9: iconst_2
10: iconst_1
11: invokevirtual #5 // Method com/msdn/java/javac/jit/BinaryOp.apply:(II)I
14: ireturn
LineNumberTable:
line 19: 0
line 20: 8
public static int bar(com.msdn.java.javac.jit.BinaryOp);
descriptor: (Lcom/msdn/java/javac/jit/BinaryOp;)I
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: checkcast #2 // class com/msdn/java/javac/jit/Add
4: astore_0
5: aload_0
6: iconst_2
7: iconst_1
8: invokevirtual #5 // Method com/msdn/java/javac/jit/BinaryOp.apply:(II)I
11: ireturn

在 foo 方法的字节码中,有个关键的 new 指令,而在 bar 方法中有 checkcast 指令,后者可以简单看成强制转换后的精确类型。由于这两个节点的类型均被精确为 Add 类,因此,原 invokevirtual 指令虽然指向 BinaryOp.apply 方法,但是在解析过程中被识别对 Add.apply 方法的调用。
综上,即时编译器因为确定了对象类型,可以直接去虚化,虽然是 invokevirtual 指令,但却可以确定出唯一的方法,最终实现方法内联。
在 bar 方法中,我们还强制将 op 对象转换为 Add 类型,保证了唯一性。那么如果没有这次强转语句,是否可以进行内联呢?
public static int test(BinaryOp op) {
return op.apply(2, 1);
}
//main测试方法
public static void main(String[] args) {
Add add = new Add();
for (int i = 0; i < 20000; i++) {
test(add);
}
}
输出编译结果如下,test 和 apply 方法都触发了即时编译。
632 48 3 com.msdn.java.javac.jit.VirtualTest::test (7 bytes)
632 49 3 com.msdn.java.javac.jit.Add::apply (4 bytes)
632 50 1 com.msdn.java.javac.jit.Add::apply (4 bytes)
632 51 4 com.msdn.java.javac.jit.VirtualTest::test (7 bytes)
632 49 3 com.msdn.java.javac.jit.Add::apply (4 bytes) made not entrant
633 48 3 com.msdn.java.javac.jit.VirtualTest::test (7 bytes) made not entrant
毫无意外,apply 方法同样被内联了。

如果 BinaryOp 还有另外一个子类,那么情况会做如何改变,首先增加 Sub 类,然后再进行测试。
public class Sub extends BinaryOp{
@Override
public int apply(int a, int b) {
return a - b;
}
}
关于 main 方法不变,继续调用 test 方法进行测试,这里我们打印一下类的加载情况。可以发现 Java 虚拟机仅仅加载了 Add,那么,BinaryOp.apply 方法只有 Add.apply 这么一个具体实现。因此,当即时编译器碰到对 BinaryOp.apply 的调用时,便可直接内联 Add.apply 的内容。
如果同时初始化 Add 类和 Sub 类,那编译器又该如何处理?
条件去虚化
根据类型继承关系分析的定义可知,当 Add 和 Sub 类同时存在,BinaryOp.apply 方法有两种具体实现,则该项技术已经无法处理这种情况。那么就只能依赖接下来的条件去虚化,条件去虚化通过向代码中添加若干个类型比较,将虚方法调用转换为若干个直接调用。
具体的原理非常简单,是将调用者的动态类型,依次与 Java 虚拟机所收集的类型 Profile 中记录的类型相比较。如果匹配,则直接调用该记录类型所对应的目标方法。
public static int test(BinaryOp op) {
return op.apply(2, 1);
}
我们继续使用前面的例子。假设编译时类型 Profile 记录了调用者的两个类型 Sub 和 Add,那么即时编译器可以据此进行条件去虚化,依次比较调用者的动态类型是否为 Sub 或者 Add,并内联相应的方法。其伪代码如下所示:
public static int test(BinaryOp op) {
if (op.getClass() == Sub.class) {
return 2 - 1; // inlined Sub.apply
} else if (op.getClass() == Add.class) {
return 2 + 1; // inlined Add.apply
} else {
... // 当匹配不到类型Profile中的类型怎么办?
}
}
如果类型 Profile 中的记录可以匹配到对应的对象类型,即时编译器则可以进行方法内联。我们实操一下看看结果:
public static void main(String[] args) {
Add add = new Add();
Sub sub = new Sub();
for (int i = 0; i < 20000; i++) {
test(add);
test(sub);
}
}
编译结果为:
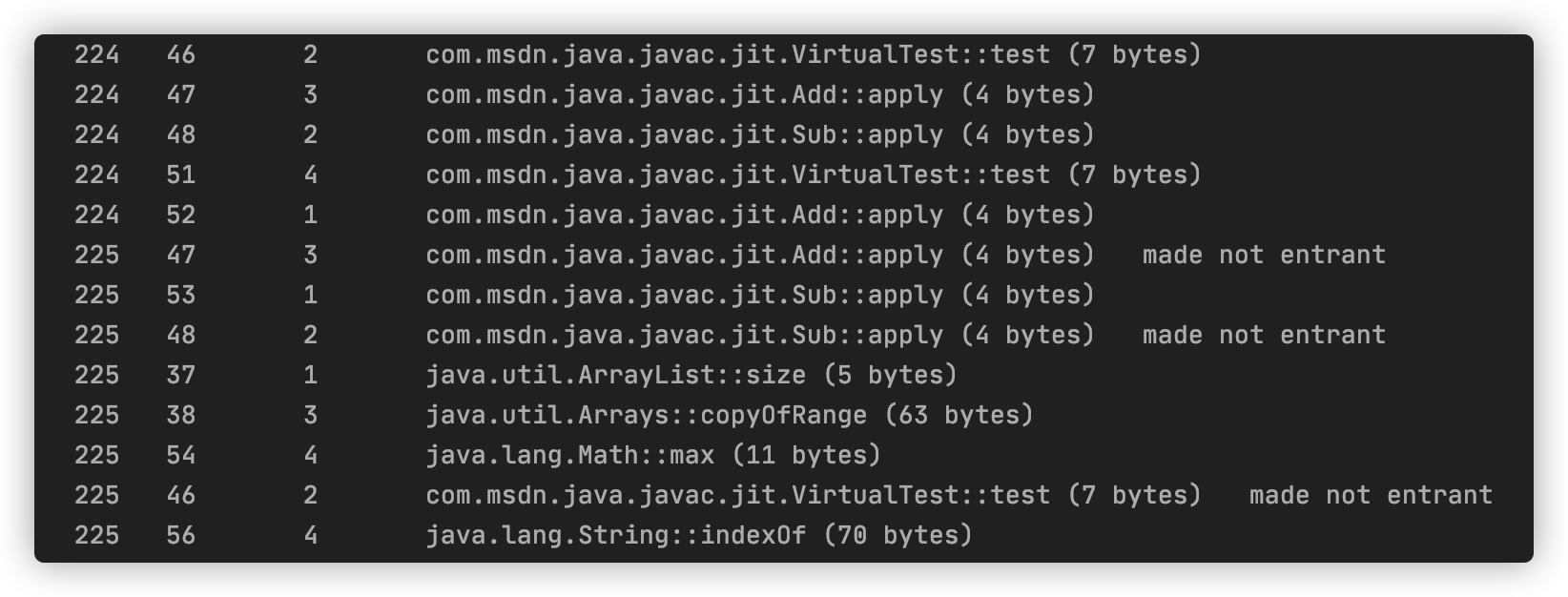
直接看内联结果如下:
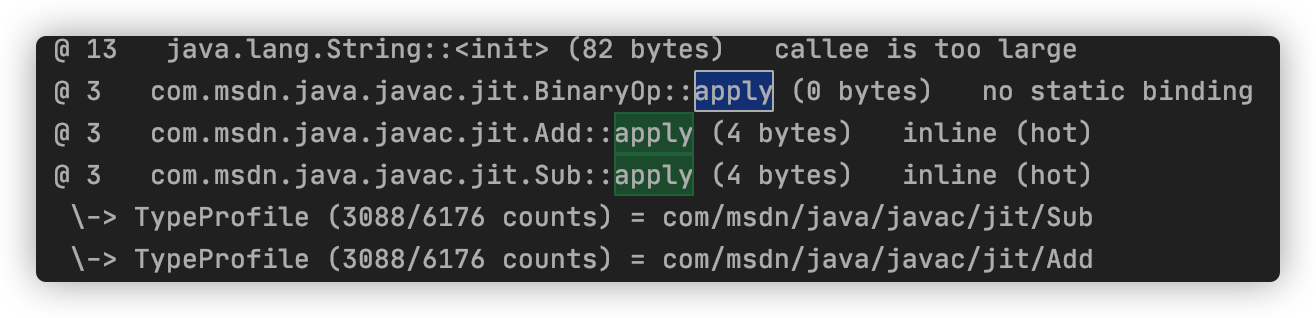
如果遍历完类型 Profile 中的所有记录,仍旧匹配不到调用者的动态类型,那么即时编译器有两种选择。
第一,如果类型 Profile 是完整的,也就是说,所有出现过的动态类型都被记录至类型 Profile 之中,那么即时编译器可以让程序进行去优化,重新收集类型 Profile。
第二,如果类型 Profile 是不完整的,也就是说,某些出现过的动态类型并没有记录至类型 Profile 之中,那么重新收集并没有多大作用。此时,即时编译器可以让程序进行原本的虚调用,通过内联缓存进行调用,或者通过方法表进行动态绑定。
关于上述两点,自己只找到了一种替代方案来进行测试,主要就是禁止编译 Sub 类中的 apply 方法,这样就没法类型 Profile 就不包含 Sub 信息,同样因为是手动禁止编译,所以编译器也不会重新收集 Profile 信息。
还是基于上述测试代码,不过增加如下参数:
-XX:CompileCommand=exclude,com/msdn/java/javac/jit/Sub::apply -XX:+PrintCompilation
- 1
编译结果输出如下:
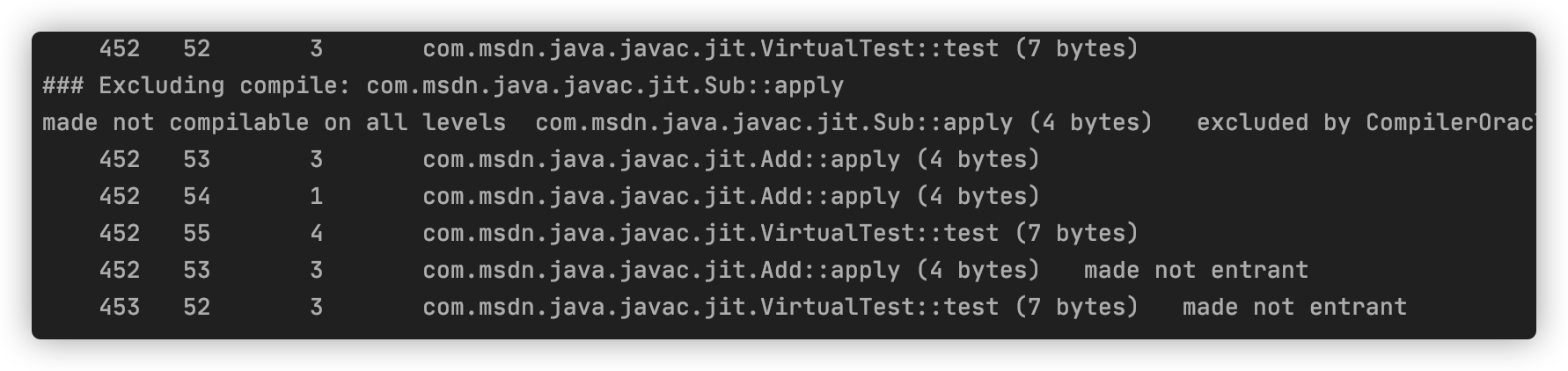
同样我们利用 PrintInlining 参数输出内联信息。

扩展
因类加载导致去优化
上文演示 Add 和 Sub 同时初始化的情况,如果修改一下 Sub 初始化的位置,则会发生意想不到的情况。
public static void main(String[] args) throws InterruptedException {
Add add = new Add();
for (int i = 0; i < 20000; i++) {
test(add);
}
Thread.sleep(2000);
System.out.println("Loading Sub");
Sub sub = new Sub();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出编译结果发现:

Sub 类的加载时机是晚于 test 方法的调用,从编译结果可以看出,因类加载导致 test 方法的去优化。至于为何会发生去优化,原因如下:test 方法中对于 apply 方法调用已经被去虚化为对 Add.apply 方法的调用。如果在之后的运行过程中,Java 虚拟机又加载了 Sub 类,那么该假设失效,Java 虚拟机需要触发 test 方法编译结果的去优化。
一点疑惑
上文我们已经创建了 Add 和 Sub 类,那么我们再创建一个 Mul 类,同样继承 BinaryOp。
public class Mul extends BinaryOp {
@Override
public int apply(int a, int b) {
return a * b;
}
}
//测试代码
public static void main(String[] args) {
Add add = new Add();
Sub sub = new Sub();
Mul mul = new Mul();
for (int i = 0; i < 20000; i++) {
test(add);
test(sub);
test(mul);
}
}
同样输出编译结果,如下图所示:
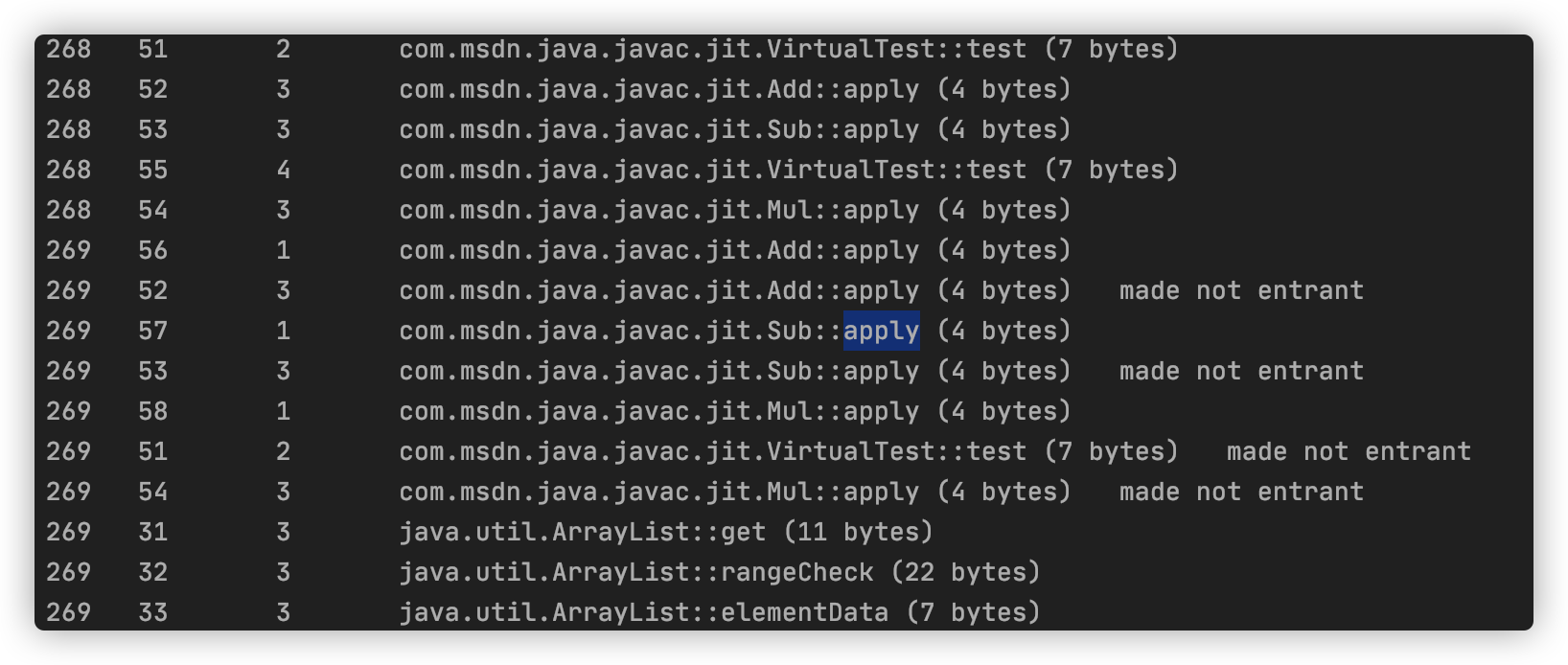
继续看内联信息

从结果来看,没有任何的内联信息,那么关于 apply 方法的调用要么通过内联缓存进行调用,或者通过方法表进行动态绑定。
后续又经测试,将循环次数增加至 400000 时,apply 方法又进行了内联,而且输出编译结果时,main 方法竟然也触发了即时编译,关于这其中的细节以及为何变成这样,个人暂时搞不懂。如果有大佬知晓这块知识,望不吝赐教。
总结
方法内联是指,在编译过程中,当遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代原方法调用的优化手段。
方法内联有许多规则。除了一些强制内联以及强制不内联的规则外,即时编译器会根据方法调用的层数、方法调用指令所在的程序路径的热度、目标方法的调用次数及大小来决定方法调用能否被内联。
完全去虚化通过类型继承关系分析,将虚方法调用转换为直接调用。它的关键在于证明虚方法调用的目标方法是唯一的。
条件去虚化通过向代码中增添类型比较,将虚方法调用转换为一个个的类型测试以及对应该类型的直接调用。它将借助 Java 虚拟机所收集的类型 Profile。
在学习过程中遇到了几点疑惑,一是 optimized virtual_call 和 inline (hot)之间的关系,两者是否存在关联,optimized virtual_call 的触发场景是什么?二是虚方法内联扩展的第二点,自己对写的测试用例带来的结果存在疑惑。
其他技能
JITWatch
JITWatch 是一个查看JIT行为的可视化工具。
下载
1、从 github 上 clone 项目,之后运行该项目。
// maven运行方法
mvn clean compile test exec:java
//gradle
gradlew clean build run
- 4
个人测试过,发现运行后打开的 JITWatch 窗口显示乱码,就只好换个方式。(也许只是我个人遇到了这个问题,该种方式最简单,推荐尝试)

2、从http://pan.baidu.com/s/1i3HxFDF 下载,原作者放了一个 jitwatch.sh 在里面,下载下来之后改一下文件中的路径就可以直接运行了。
下载好的压缩包解压后得到如下内容:

修改 jitwatch.sh 文件:
JITWATCH_HOME="/Users/xxx/Downloads/JITWatch/jitwatch-master/lib";
JITWATCH_JAR="/Users/xxx/Downloads/JITWatch/jitwatch-1.0.0-SNAPSHOT.jar"
java -cp $JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/jfxrt.jar:$JITWATCH_JAR:$JITWATCH_HOME/hamcrest-core-1.3.jar:$JITWATCH_HOME/logback-classic-1.1.2.jar:$JITWATCH_HOME/logback-core-1.1.2.jar:$JITWATCH_HOME/slf4j-api-1.7.7.jar org.adoptopenjdk.jitwatch.launch.LaunchUI
然后打开命令行窗口,执行如下命令:
JITWatch % ./jitwatch.sh
至于使用记录,可以参考如下几篇文章:
参考文献
极客时间 郑雨迪 《深入拆解Java虚拟机》 方法内联
《深入理解Java虚拟机第三版》