01
现象
社区小伙伴最近在为 Kylin 4 开发 Soft Affinity + Local Cache 的性能测试过程中,遇到了压测场景下查询响应时间不稳定问题, RT 随着时间变化较大,现象如下:
-
同样的 SQL (只是参数不同) 在压测时,刚开始的性能较好,运行一段时间后,性能就下降严重,一段时间后(不固定多长)又有可能恢复之前的水平;
-
Spark 重启后,性能同样也能好转;
如下图所示:
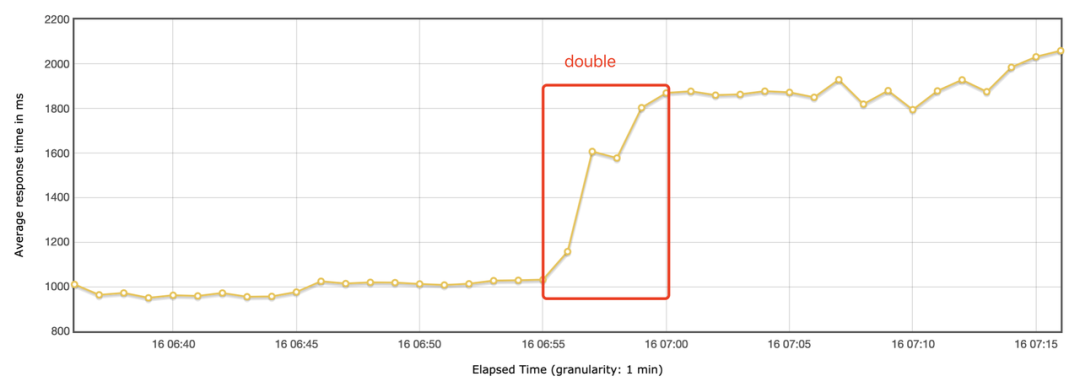
图一:测试第一阶段和第二阶段
第一阶段,测试开始,查询响应时间比较平稳,在 1 秒左右;
第二阶段,16:06 以后查询的响应时间逐渐变大,慢慢增长到第一阶段的两倍,达到接近 2 秒;
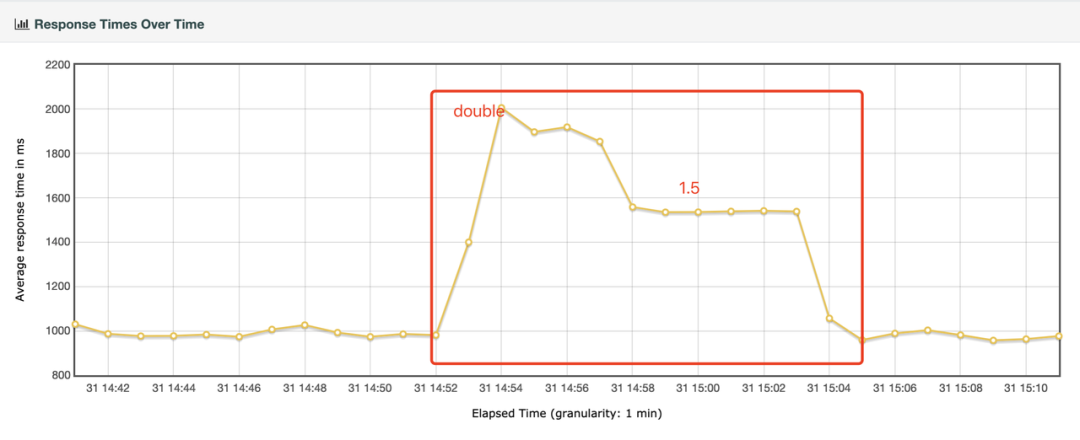
图二:测试第三阶段
第三阶段,查询的响应时间慢慢恢复之前的水平。
02
寻找 Root Cause
相同的环境,一样的配置,每次运行都能复现这种现象,且性能相差巨大,不找出 Root Cause 似乎会失眠。于是开始了一波测试,观察 GC、收集火焰图、做性能下降前后的对比,发现均没有什么太大区别,且都正常。
根因排查
1.Spark Executor GC Log 分析
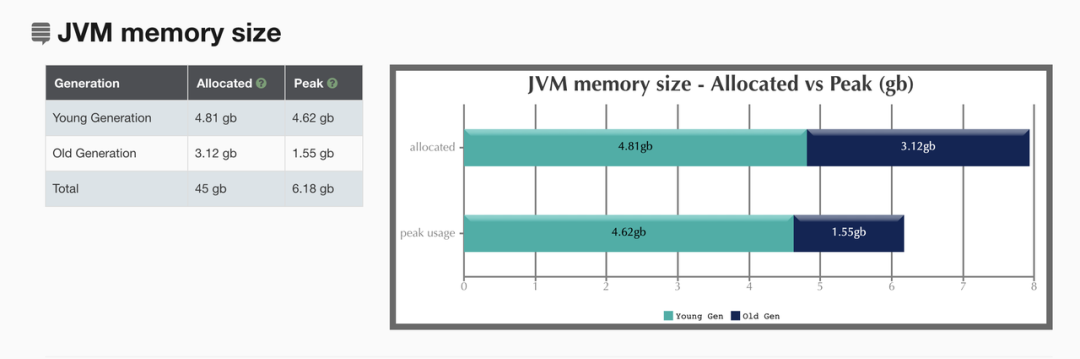
图三:Executor JVM 内存使用
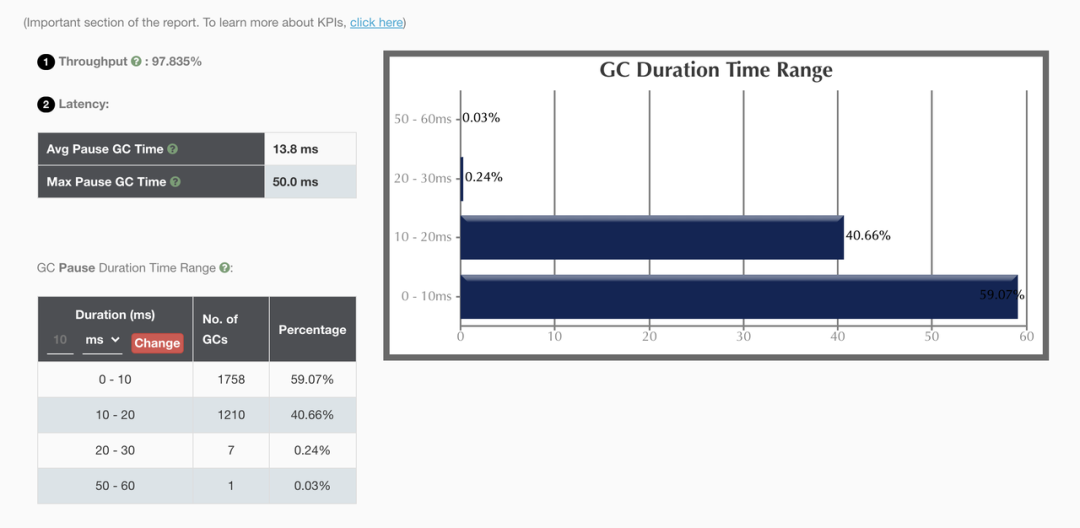
图四:Executor JVM GC 耗时分布
根据 GC log 分析,大部分 GC 在 20ms 内,比较正常,Peak Memory Size 也毫无压力。
2.Spark Executor 火焰图

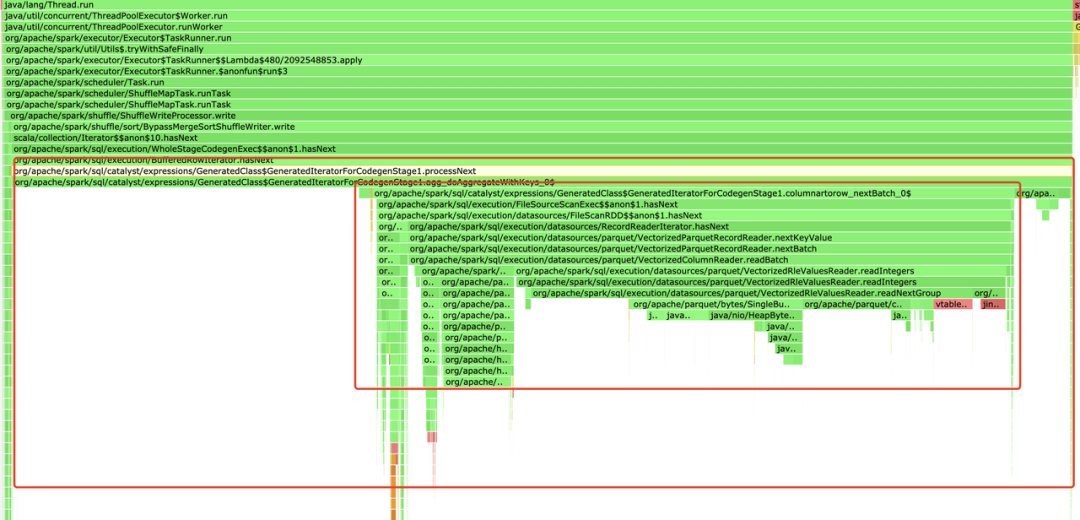
图五:Executor 火焰图
从火焰图上看,唯一区别在于小红框部分的比例前后不同,但这部分是 Spark Code Generate 的代码,相同的 SQL ,代码逻辑是一样,大红框整体的占比也是差不多的(后来回想,这是一个异常点,只是当时无法想到是跟 JIT 有关)。
3.Parquet 读取
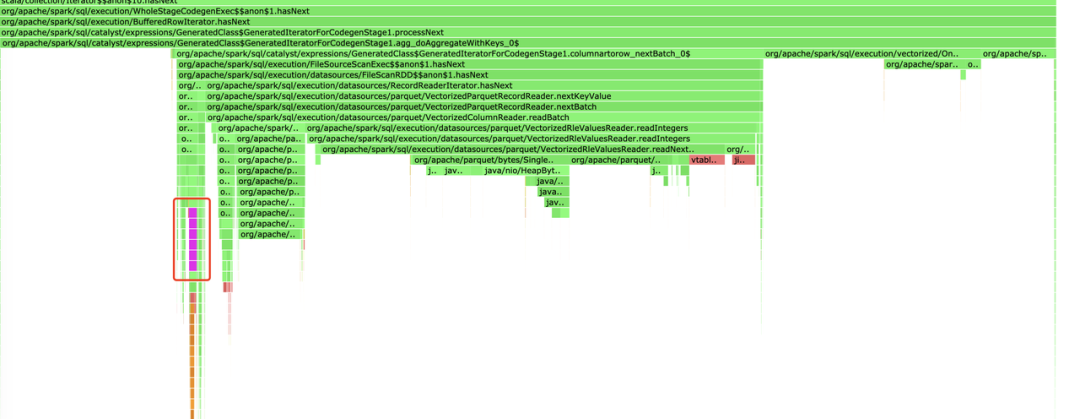
图六:Executor 读取文件相关部分火焰图
从火焰图上可以看到,紫色部分是读取 Parquet 数据部分,占比和正常水平时的一样。
关键线索
一切看起来都是那么的正常,但为什么却有两倍的 RT 呢?毫无头绪下,只能再回归各种指标数据,日志文件了。
在看 Executor stderr log 时,无意间看到了这个 Warning,且各个 Executor 上都有:

图七:JVM Warning Message on Executor stderr
因此开启 Code Cache Size 性能指标采集 (该性能指标似乎自己平时比较少关注),再压测一轮,发现了端倪:Code Cache 影响了查询性能。
查看 JMeter Report 中随时间变化的 RT 曲线,并且结合 Spark Metrics 的 Code Cache Size 曲线,发现 RT 翻倍的时间点与各个 Executor Code Cache Size 满的时间点吻合:
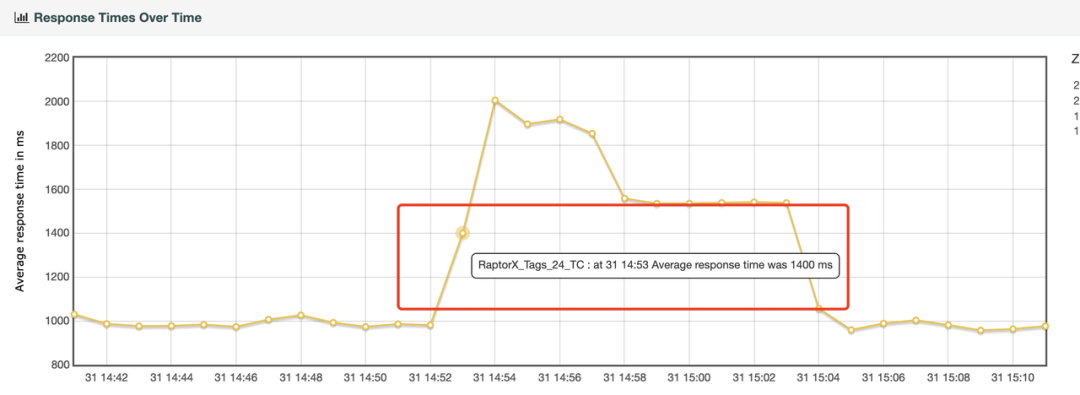
图八:Kylin 4 Response Time 曲线图
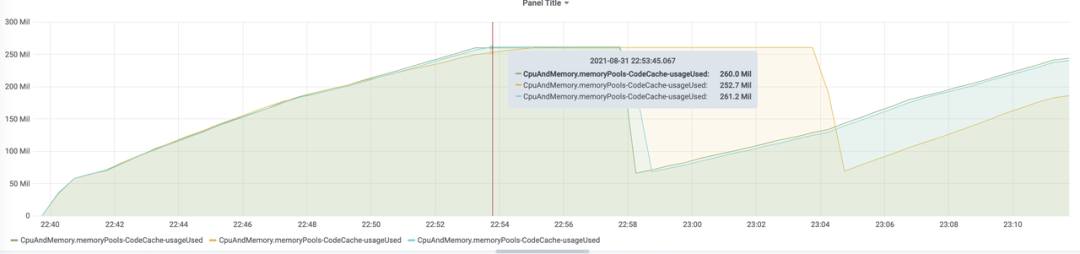
图九:Spark Executor Code Cache Size 曲线图
在 RT 高峰时,所有 Executor 的 Code Cache Size 均达到最大值,后续有些 Executor 的 Code Cache Size 因为回收机制下降下来,此时的 RT 也开始略有好转,当所有 Executor 的 Code Cache 都未达到最大值时,RT 恢复正常。
Root Cause
经过上面的分析,接着验证下是否分析正确,因此把 JVM 参数 -XX:ReservedCodeCacheSize=256M 调整为 2G ( 目前该参数最大可配置 2G ),再次压测一轮,整体 RT 就稳定了许多:
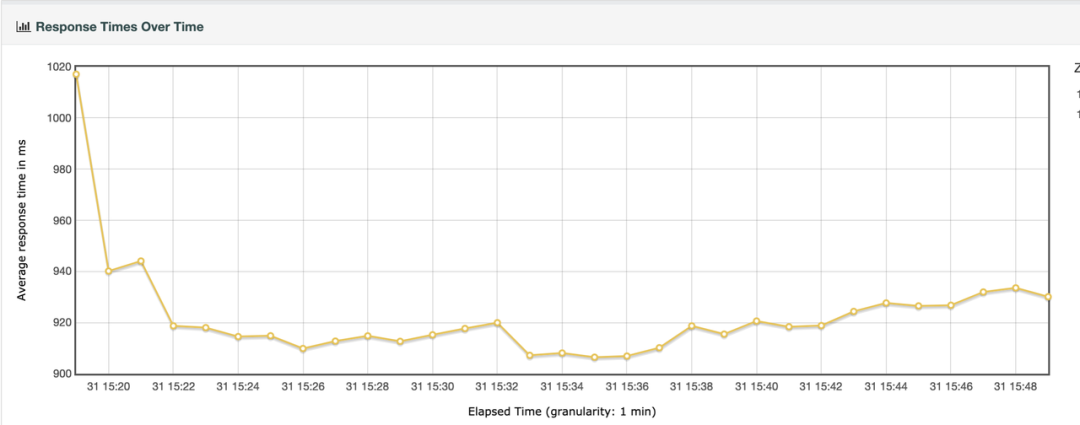
图十:调整后 Kylin 4 Response Time 曲线图
且观察 Code Cache Size 性能指标,发现最大值可达到 400M:

图十一:调整后 Spark Executor Code Cache Size 曲线图
至此,Root Cause 找到了,因为 Code Cache Size 满了,导致了 JIT 停止,而 JIT 是 JVM 提升性能的一把利器,停止了工作,随之带来的性能下降显而易见,影响巨大。
03
小结
1. Code Cache Size 的性能指标,对 JIT 功能至关重要,必须监控起来,然后根据实际使用情况,进行适当调整;
2. JVM 中 Code Cache Size 及 JIT 等相关参数:
-
-XX:+TieredCompilation:开启分层编译( C1 and C2 ),JDK 8 之后默认开启;
-
-XX:+UseCodeCacheFlushing:在JIT被关闭之前,也就是 CodeCache Size 满之前,会做一次清理,删除一些 Code Cache 的代码,如果清理后还是没有空间,那么 JIT 依然会关闭,JDK 8 默认开启;
-
-XX:ReservedCodeCacheSize=2G:Code Cache Size,最大可配置 2G;
-
-XX:NmethodSweepActivity=10:默认值 10,计算清理 compiled method 的阈值,具体可以看对应的代码:http://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/f22b5be95347/src/share/vm/runtime/sweeper.cpp#l588 ;值越大,在清理时会有越多的 compiled method 被清理,意味着回收会越快;
-
-XX:Tier3CompileThreshold=2000 and -XX:Tier3InvocationThreshold=200:开启分层编译后,C1 层编译和调用的阈值,值越小,越容易被 JIT 编译;
-
-XX:Tier4CompileThreshold=15000 and -XX:Tier4InvocationThreshold=5000:开启分层编译后,C2 层编译和调用的阈值,值越小,越容易被 JIT 编译;
* 以上四个参数,官方建议不要自行修改
04
参考资料
2.https://stackoverflow.com/questions/38173592/oracle-jvm-8-when-codecache-flushing-is-enabled-how-much-is-flushed